
As data scientists or machine learning engineers data is the key to what makes our products succeed. We are constantly running experiments, and the world that is constantly changing, this means we should be versioning our data. I covered this is a previous post "We version our code, why not our data?".
The problem is most "data version control" systems piggy back off of legacy technology or straight up don't work for the size of data we need in modern machine learning systems.
At Oxen, we decided to tackle this problem by building from the ground up. We built command tooling that mirrors git, but is built for the kind of data used in machine learning work flows.

We did some benchmarking against other solutions in the market today. Taking the CelebA dataset which contains 200,000+ images of celebrity faces. We did the equivalent of an "add", "commit" and "push" to see how long it would take to sync all the images.
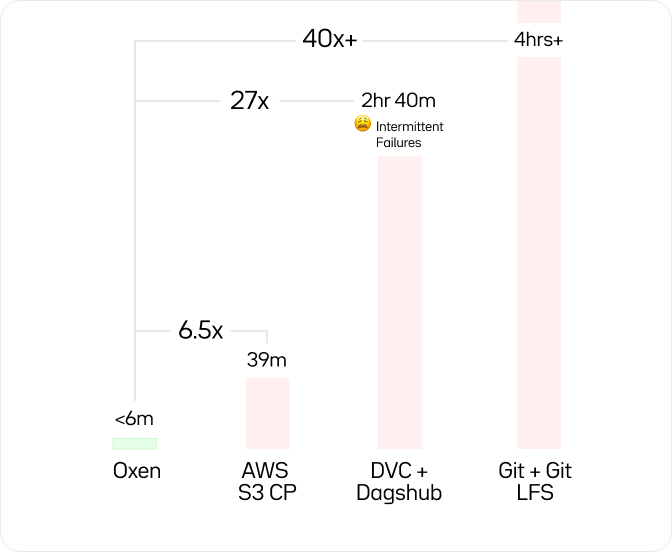
We are 40x faster than git-lfs and even 6.5x faster than a simple S3 copy. Full performance documentation can be found in our GitHub docs.
Oxen's speed comes from a combination of factors:
- Modern Hashing Algorithms
- Smart Network Protocols
- Fast Data Structures
- Takes Advantage of Parallelism
- Written in Rust
At Oxen we are excited to take the grunt work out of building out robust data pipelines.
If you have struggled with versioning datasets in the past, hopefully this is music to your ears. We hope to also expand our web hub at https://oxen.ai to have community driven #OpenData repositories.
Feel free to check out our developer documentation at https://github.com/Oxen-AI/oxen-release or sign up for an account to push data to our Hub at https://www.oxen.ai/register.
And for every star on GitHub ⭐️ an Ox gets it's wings.

Sign up for Oxen today. http://oxen.ai/register