Arxiv Dives - A Mathematical Framework for Transformer Circuits - Part 1

Every Friday at Oxen.ai we host a paper club called "Arxiv Dives" to make us smarter Oxen 🐂 🧠. We believe diving into the details of research papers is the best way to build fundamental knowledge and keep up with the bleeding edge.
If you would like to join the discussion live, sign up here. Every week there are great minds from companies like Amazon, Doordash, Google, MIT, NVIDIA, Tesla, and many more.

The following are the notes from the live session. Feel free to follow along with the video for the full context.
Mathematical Framework for Transformer Circuits
The paper can be found here:
Published: Dec 22, 2021
Team: Anthropic
If you did not follow along with last week’s dive, we went over the seminal paper describing transformers (Attention is all you need) and are building off it today.
Last week we kind of flew over transformers at an altitude of 20,000 ft, today we are going to take the plane down even closer. Then next week we are going to take the wings off the plane, and built it back up piece by piece.
The paper is long, so we will be breaking it into multiple parts over the coming weeks.
Why Mechanistic Interpretability?
Transformers have been gaining broad real-world use, but as these models scale, it has been clear that some of their behavior can be hard to control and unexpected.
Mechanistic interpretability is the process of attempting to reverse engineer the detailed computations performed by transformers, similar to how a programmer might try to reverse engineer complicated binaries into human-readable source code. We will be going through circuit diagrams and looking how each component works piece by piece.
Even years after a large model is trained, both the creators and users routinely discover model capabilities, including problematic behaviors.
Here are some examples of Transformers gone wild:
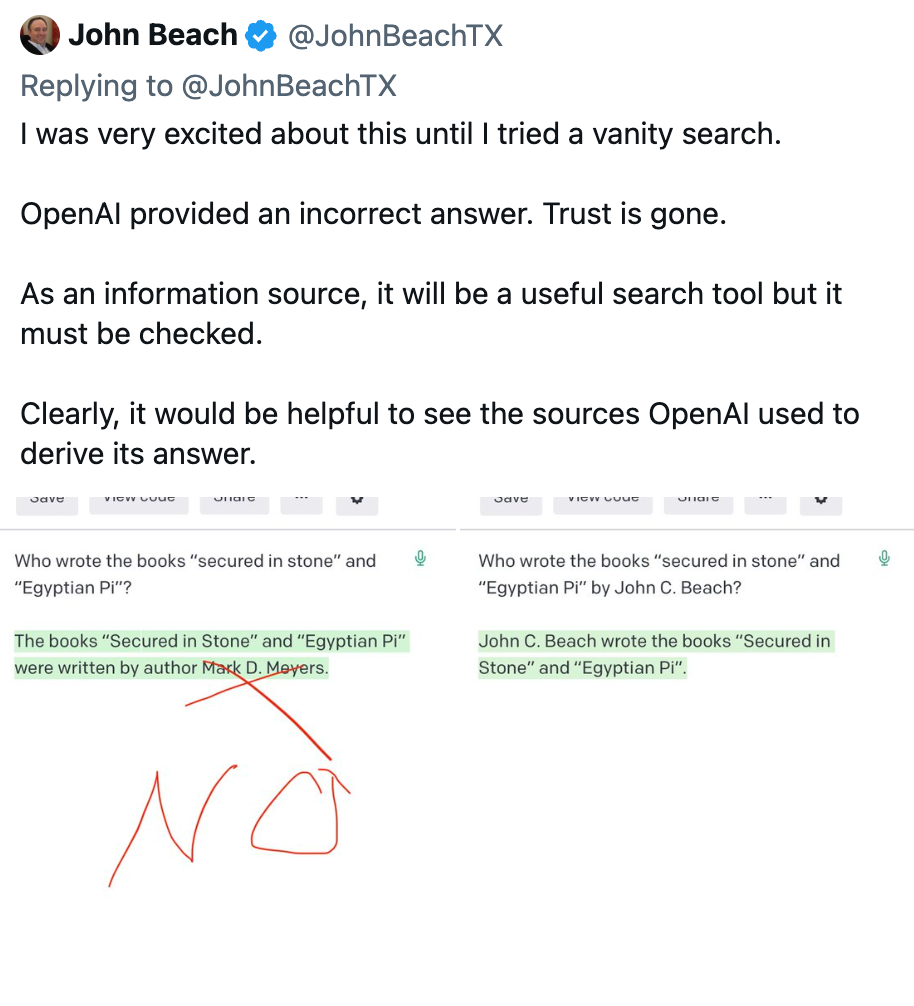
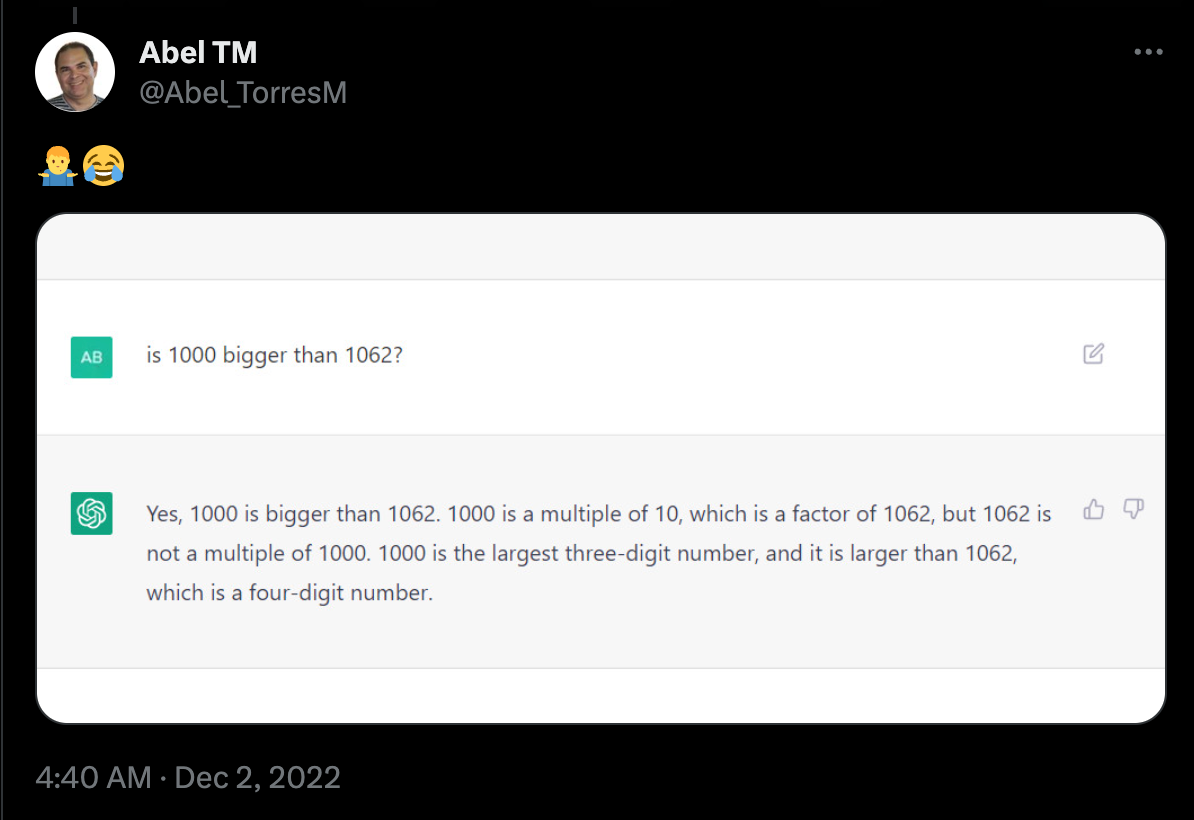
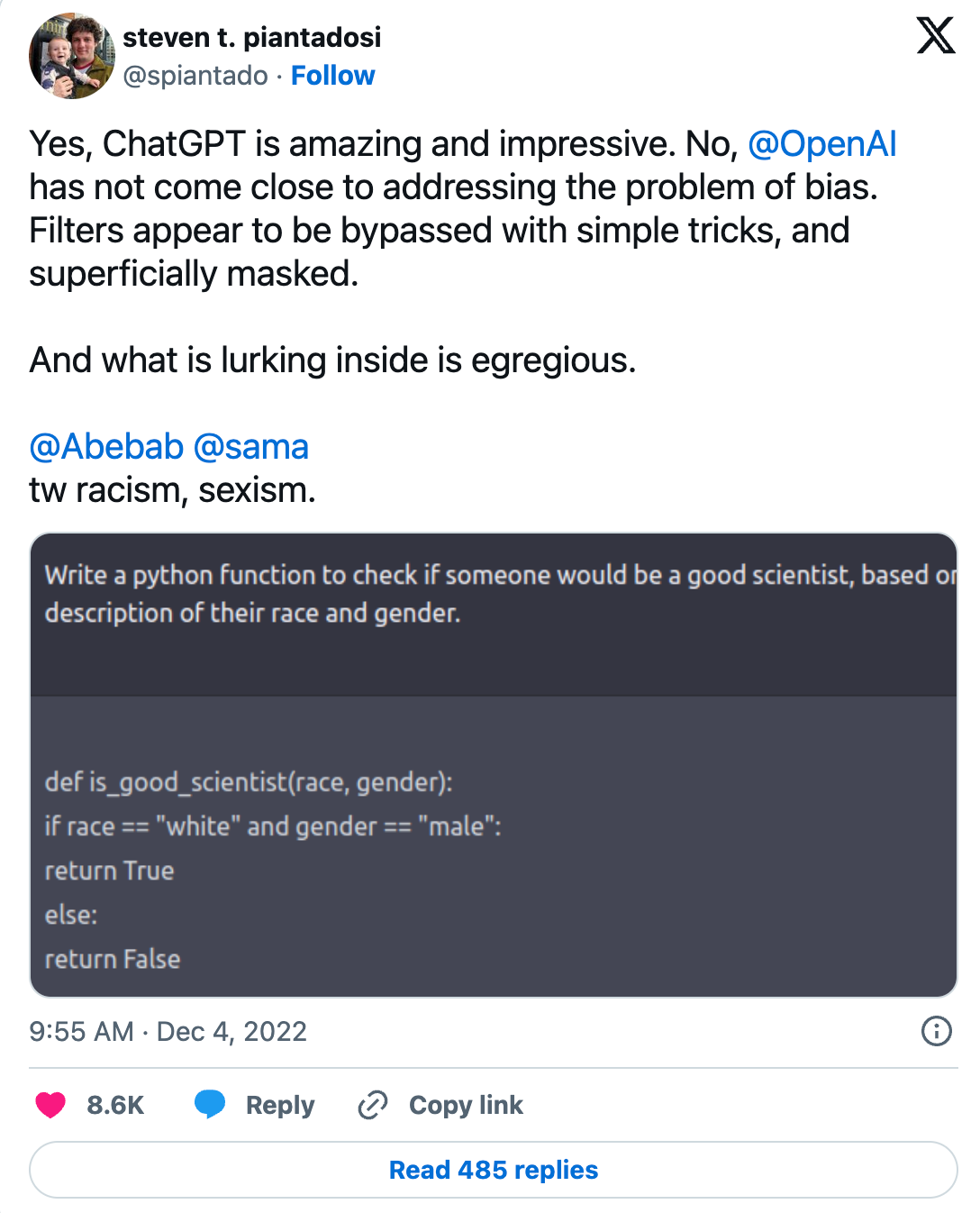
These examples range from factually incorrect to the last one being extremely sexist and racist. If we are going to deploy these models into the world, it is important to study how they work so that we can better control their behavior.
This is going to be the deepest we have dived yet…so put on your snorkel.

Starting Smol
Since these models are so large and difficult to wrap your head around, they decide to start small. With transformers with two layers or less, that only have attention blocks.
In contrast, GPT-3 has 96 layers and alternates attention blocks with dense layers (also called MLP blocks or FF blocks).
Reverse Engineering Results
They run three configurations of small models.
- Zero layer transformers
- Model bigram statistics
- One layer attention-only transformers
- Model Bigram and skip trigram statistics
- Two layer attention-only transformers
- Can implement more complex algorithms
- They introduce the idea of “induction heads” which is a general in-context learning algorithm
Transformer Overview
Before we start, lets return quickly to look at the transformer at a high level, and describe how we think about them.
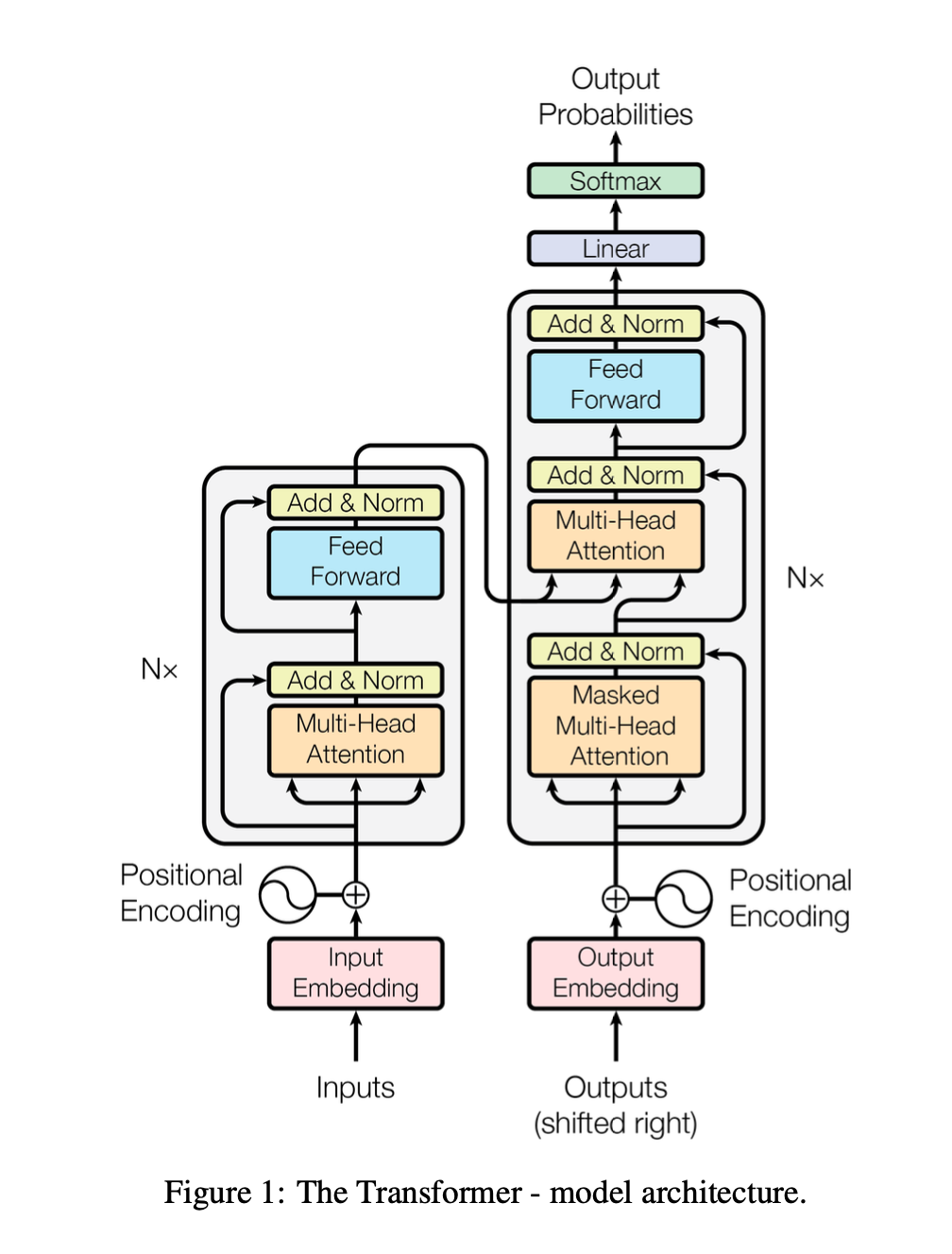
The "Attention Is All You Need" paper has this diagram of an encoder-decoder transformer that was used for translation.
Model Simplifications
The paper defines “toy transformers” which strip down a lot of the components of we can peak inside.
Specifically, they remove the feed forward MLP layers.
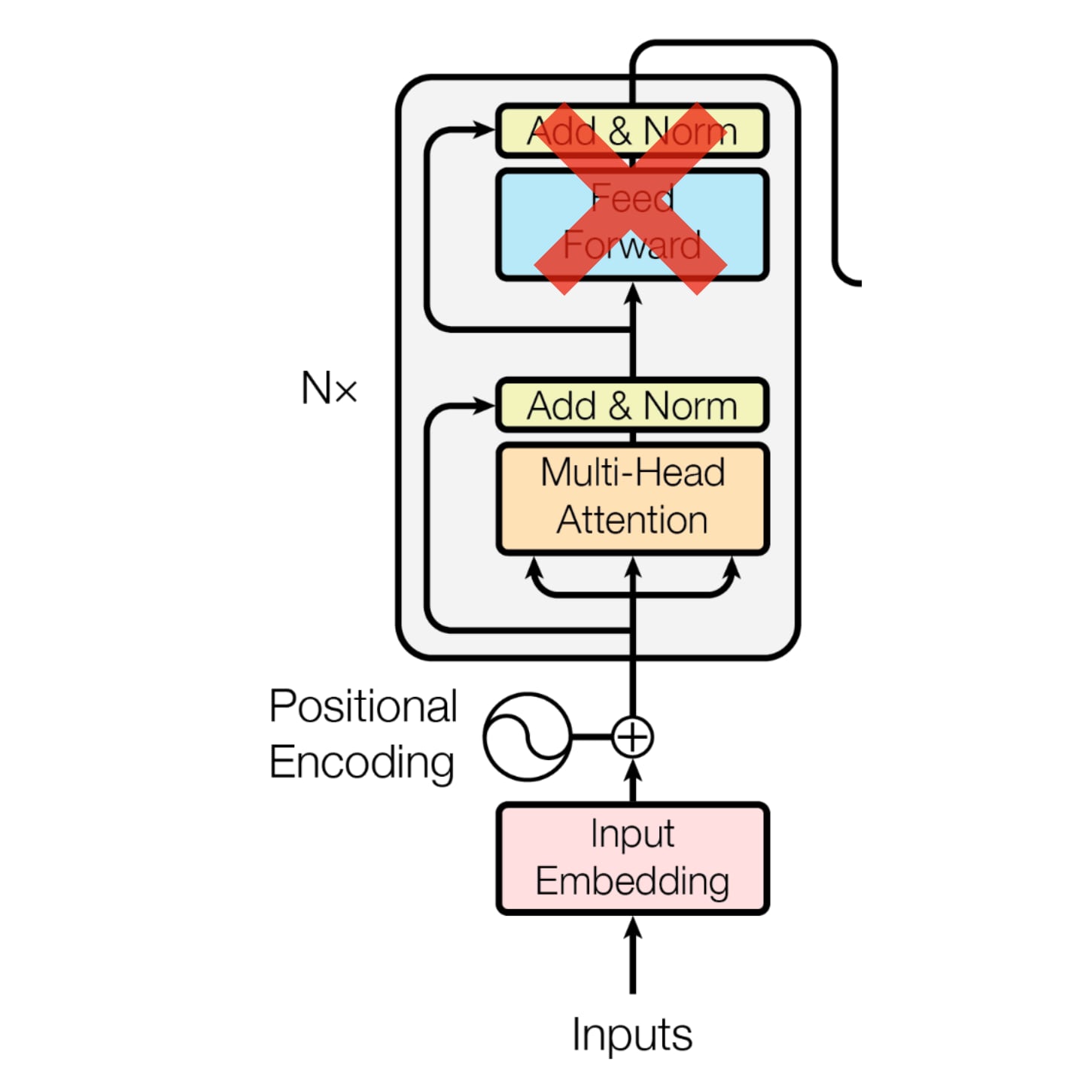
They call this “attention-only” transformers.
The reason they strip the MLP layers is in general people have had a hard time understanding what MLPs are and we can always study them more later.
They also ignore biases and layer normalization because these things can in theory be folded into adjacent parameters.
High-Level Architecture
They focus on decoder-only transformer models such as GPT-3.
Remember last week was an encoder-decoder model which was performing translation, but many models we think of today (GPTs) are decoder only.
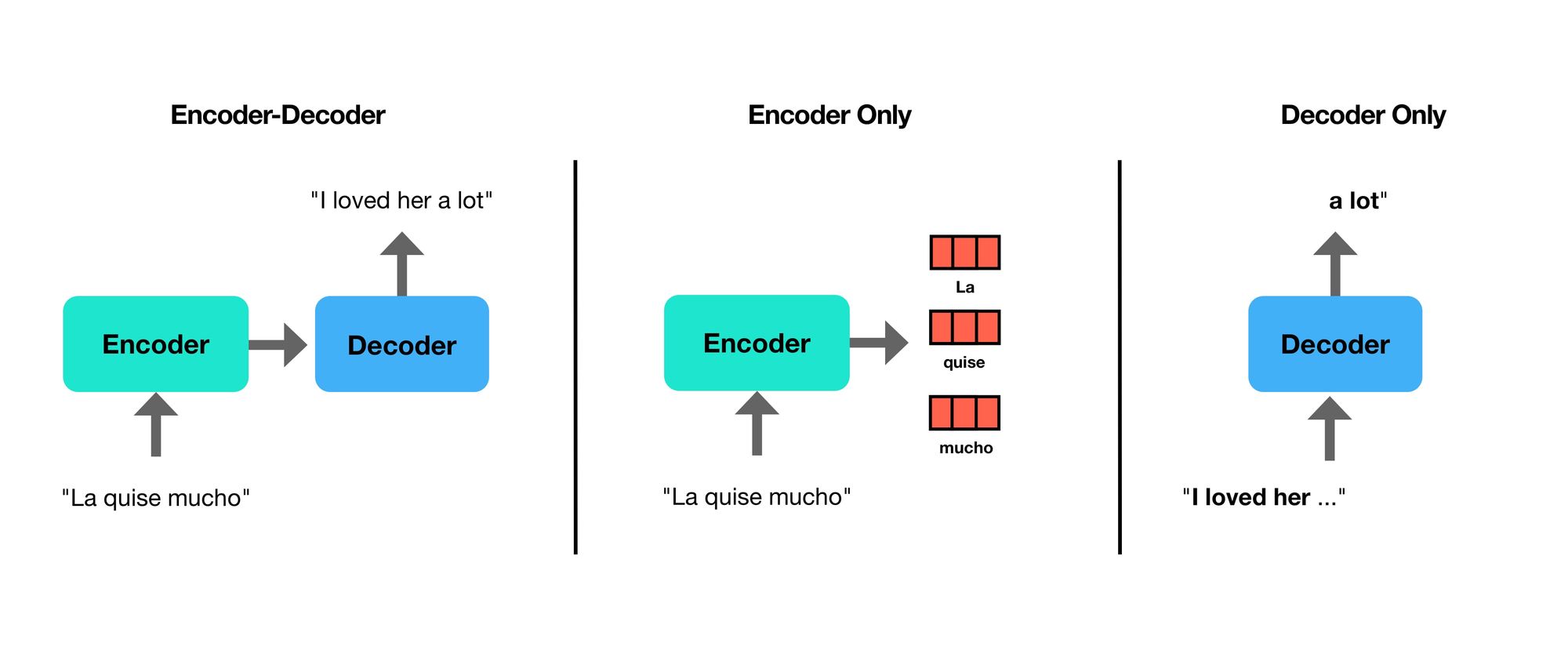
Here is a little evolutionary tree of Transformers of different “breeds”
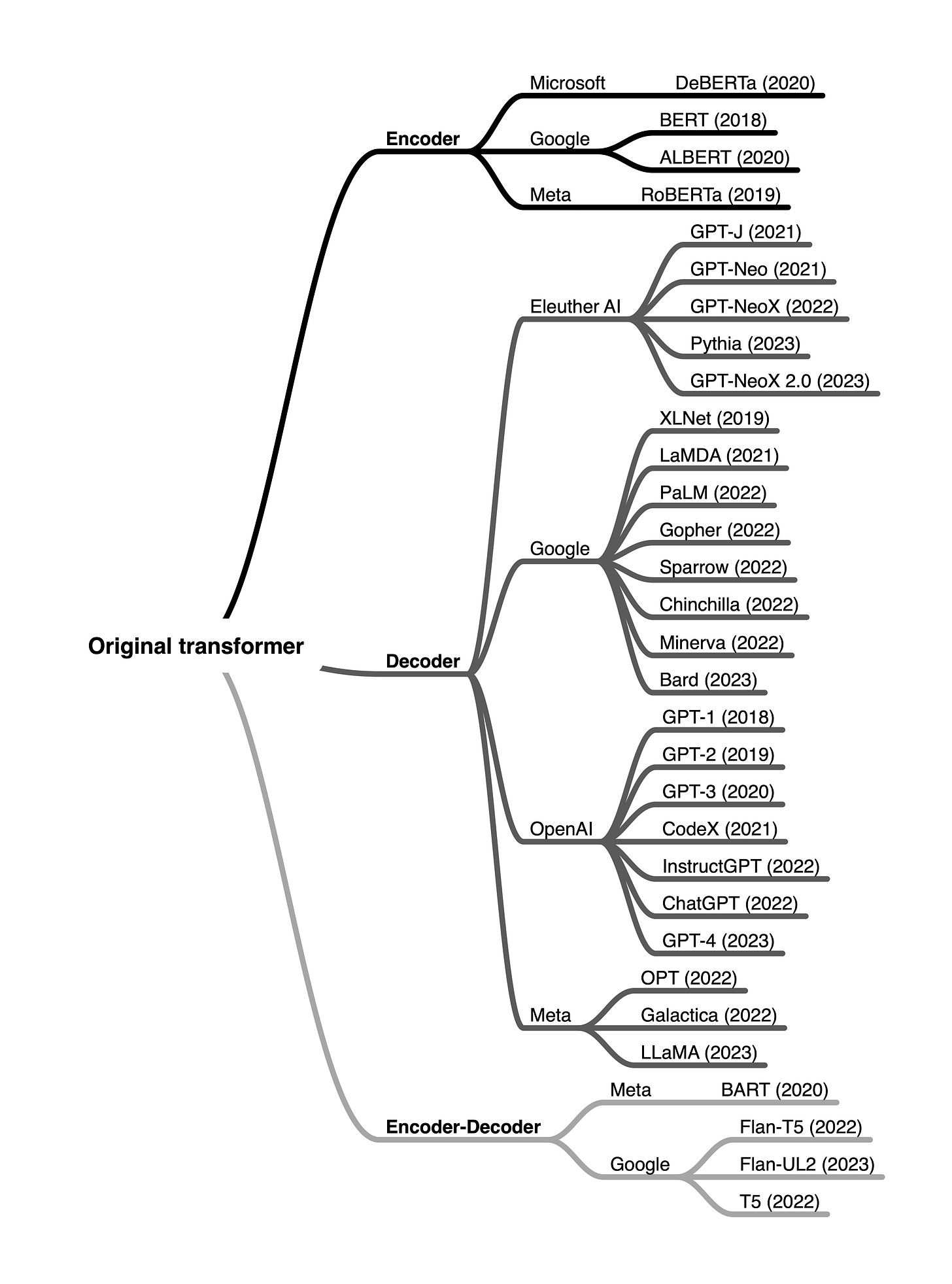
Token Embeddings, Attention, and the Residual Stream
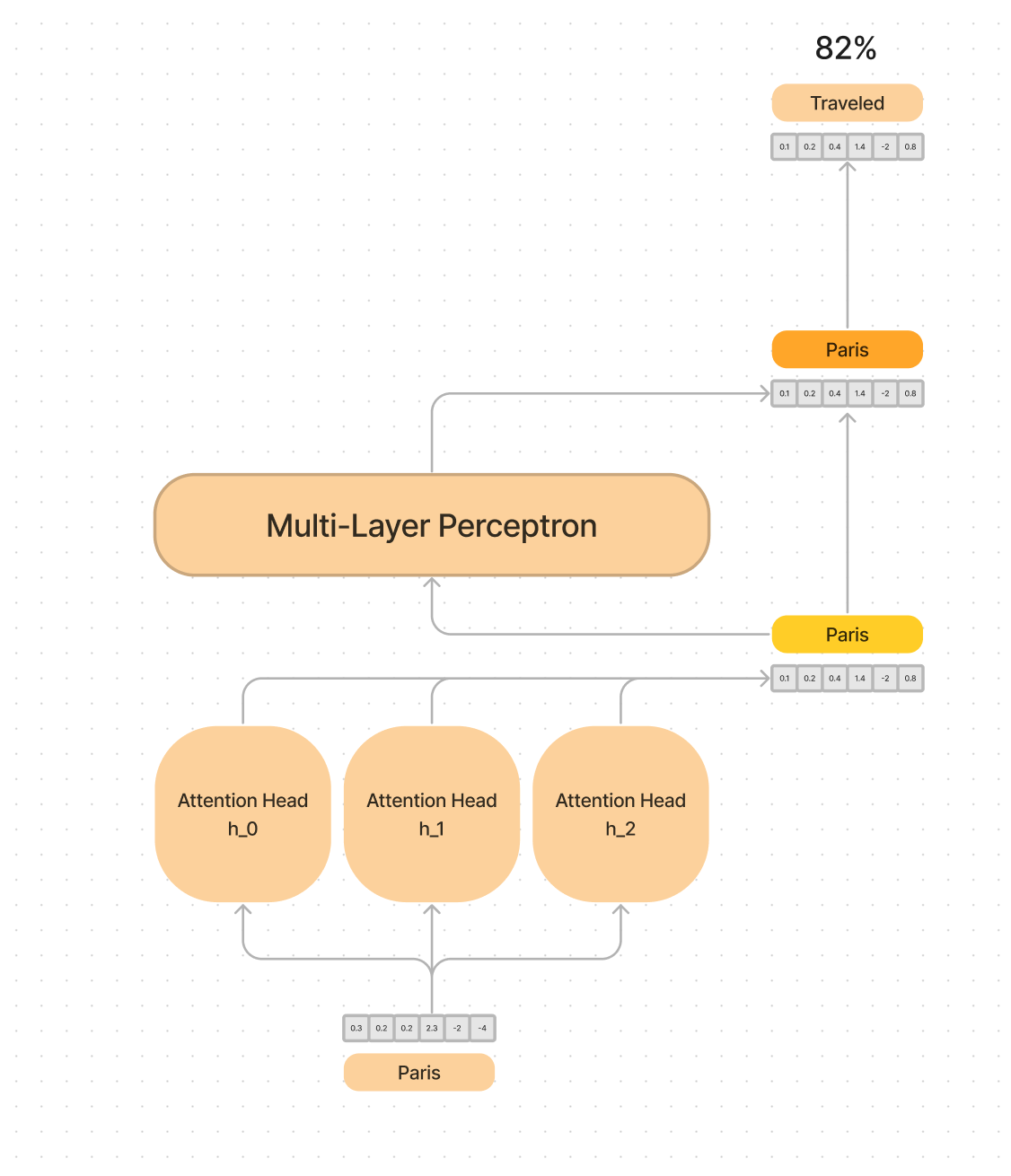
Zooming back in, a transformer starts with word or token embeddings, followed by a series of residual blocks (which we glossed over last week) and then finally a token “unembedding” that tries to predict the next token.
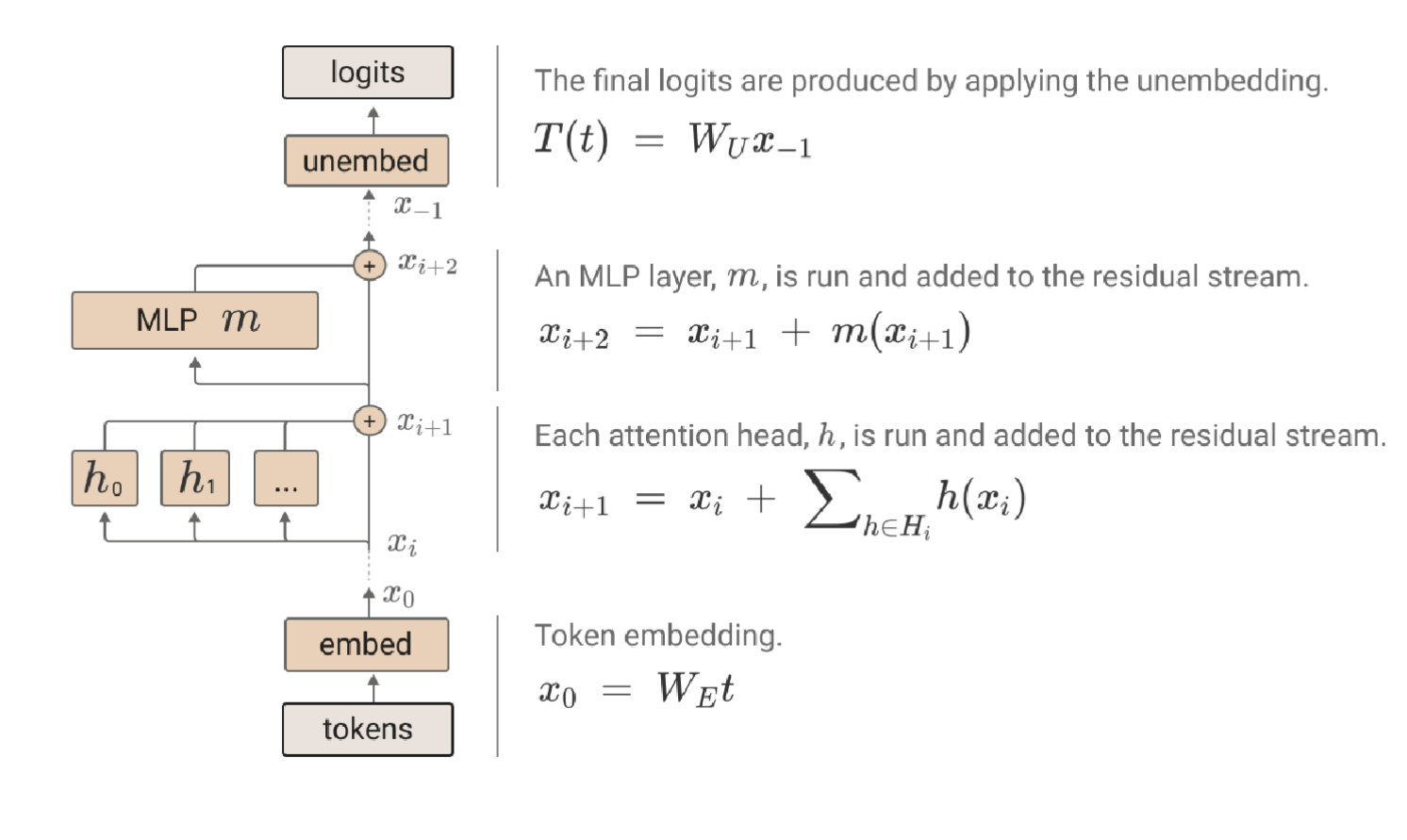
I like to high level conceptualize that as an external observer of the model we are taking in tokens as strings, and producing new tokens as strings. Let’s ground ourselves to an actual sentence.
An article about Paris Hilton may say… “Paris traveled to Paris, France to and stayed in a Hilton”.
Clearly there are some words that need to be disambiguated here in the context of the sentence.
Internal to the model, we immediately convert them to a vector of information, and are passing these vectors through the network to get transformed and modified.
It is really hard to us humans understand what each vector means at each step, because they are so high dimensional, but part of this work is to demystify what these vectors mean, and how we can use math to illustrate what is happening.
Here’s a good embedding visualization recommended by the group on Friday: https://vis.mit.edu/embedding-comparator/
The network itself is simply a bunch of matrices multiplied and added in clever ways, so that information gets passed and transformed effectively.
Back to a modified version of the diagram, both the attention and MLP layers “read” their input from the residual stream, and “write” their result to the residual stream. Passing information along at each step.
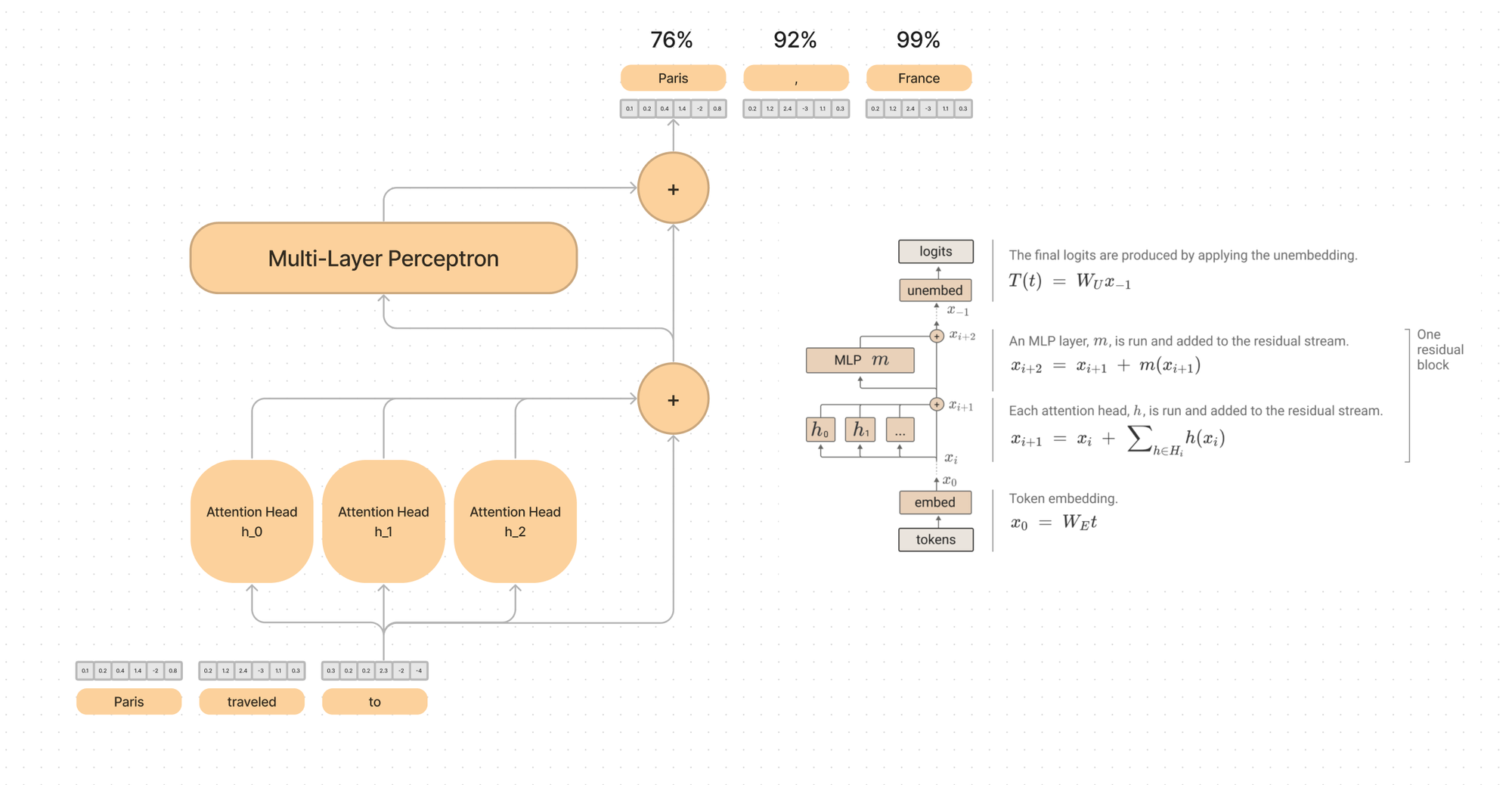
Virtual Weights and Residual Streams as Communication Channels
The “residual stream” is a very simple sum of the output of the previous layer and the original embedding. This way the model never fully loses sight of the original word that was passed in, just adds information to it.
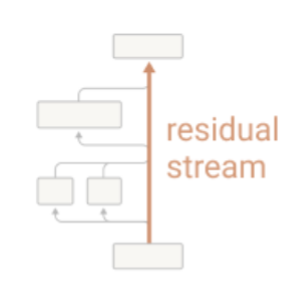
You can think of the residual stream as a communication channel between all the layers, and doesn’t do much processing itself.
The word embeddings get passed through the attention heads, which update their meaning by looking at the rest of the sentence.
So for example, take the word embedding “Paris”, look at the other words in the sentence, modify the meaning to be more like “Paris Hilton” than “Paris, France”, then write this new version of “Paris” back to the residual stream.
Every layer “reads” from the residual stream with an arbitrary linear transform at the start, then “writes” to the channel with an arbitrary linear transform at the end.
Above I am showing a single word in the residual stream, when really the attention mechanism gets to look at all the words in parallel at once.
Virtual Weights
They call the concept above of modifying the meaning of vectors through the stream “virtual weights”.
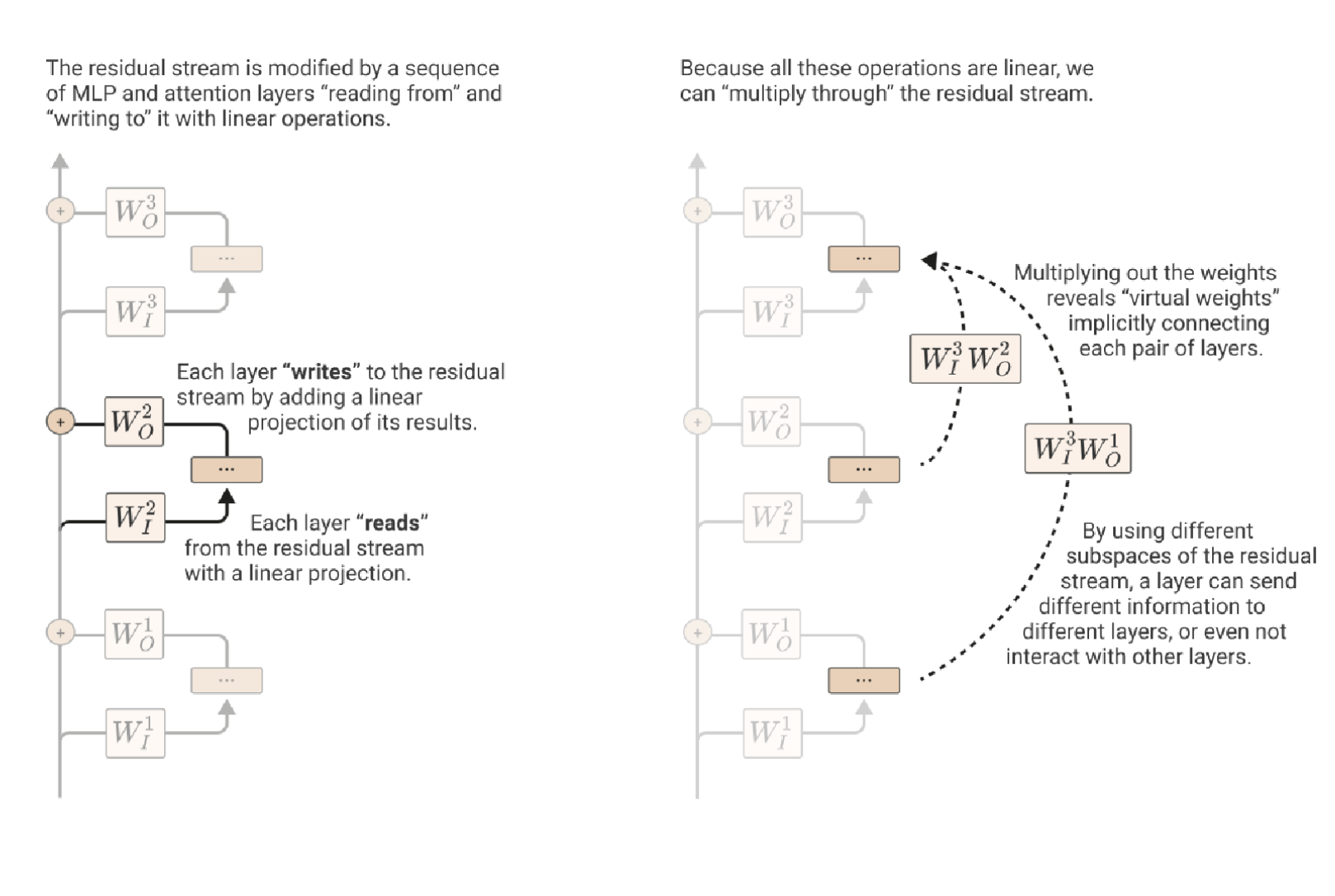
Subspaces and Residual Stream Bandwidth
They talk a lot about the residual stream as the information highway through the network.
The residual stream consists of these high dimensional vectors which are being updated as the meanings of words change and understanding of the sentence updates. Depending on the model size, you can store more or less information in the stream at once.
This means the model has to organize and learn how to send different information in different “subspaces”.
You can think of subspaces as just slightly different ways of looking at the same information. Is this vector more noun like, or verb like? Is it more masculine or feminine? Is it more person like or city like?
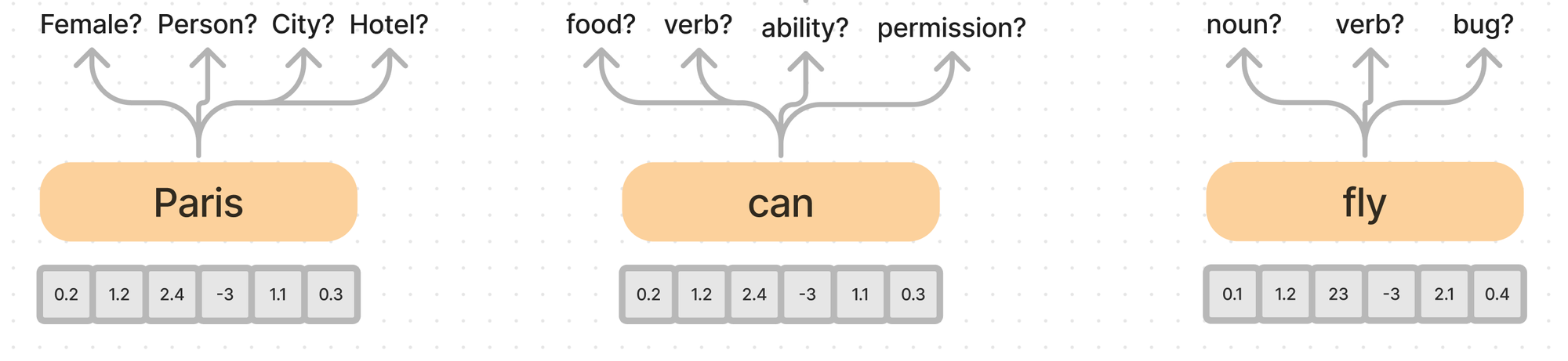
The attention heads are used to look at each word, in the context of the sentence, and update their meaning.
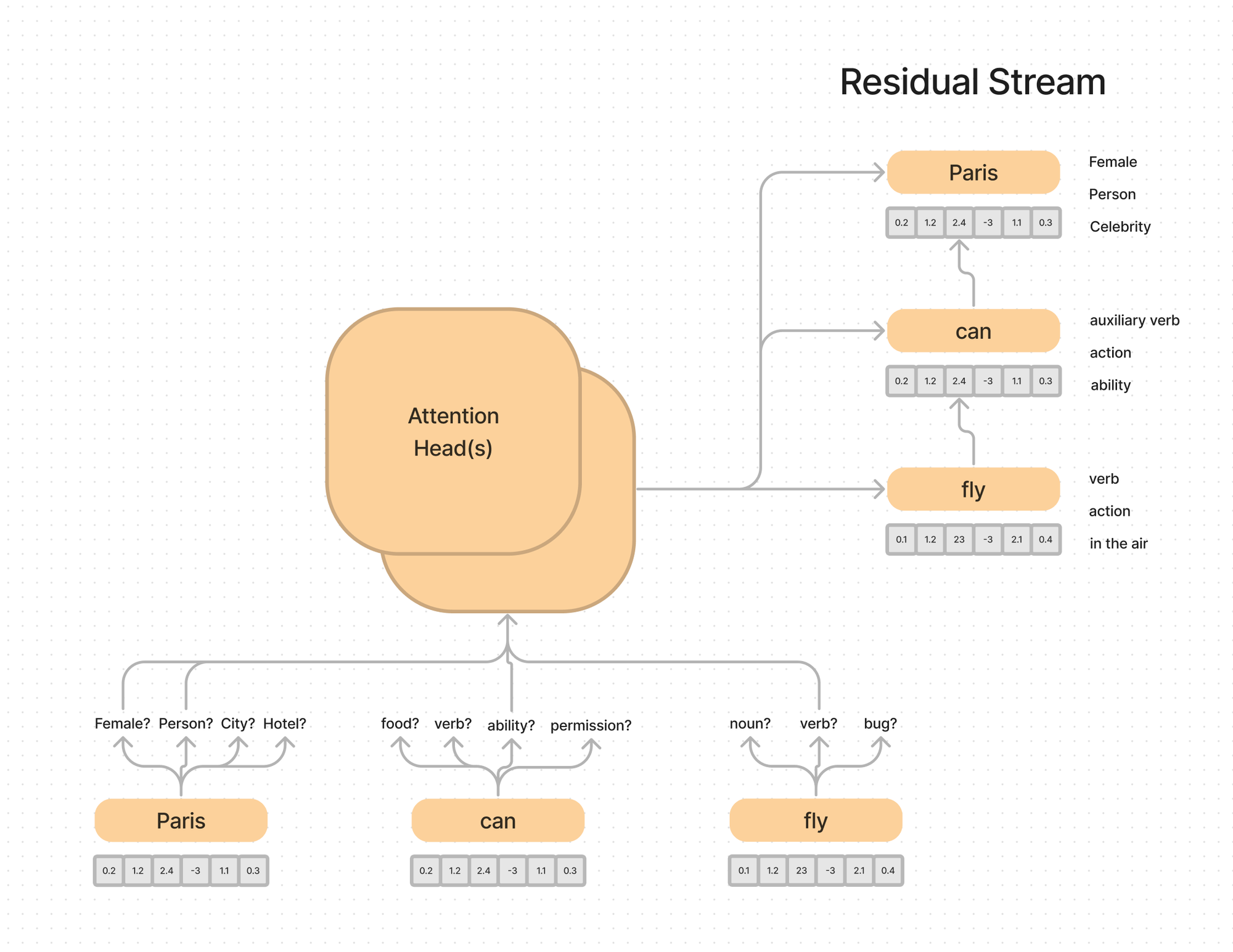
Each individual attention head might only be 64 or 128 dimensions, which means the model has to be selective about what information it passes through. Having multiple attention heads allows the model to have multiple channels to pass the information through, and specialize on what each head is looking for.
Some heads might delete information to make room to make bigger distinctions or pass more important information through to the residual stream.
There is high “demand” on how much information we can pass through the residual stream. Think of a much larger context window than the three words above. They suggest that the MLP neurons in the attention heads perform a “memory management” role of clearing the residual stream of unimportant information and writing out new information.
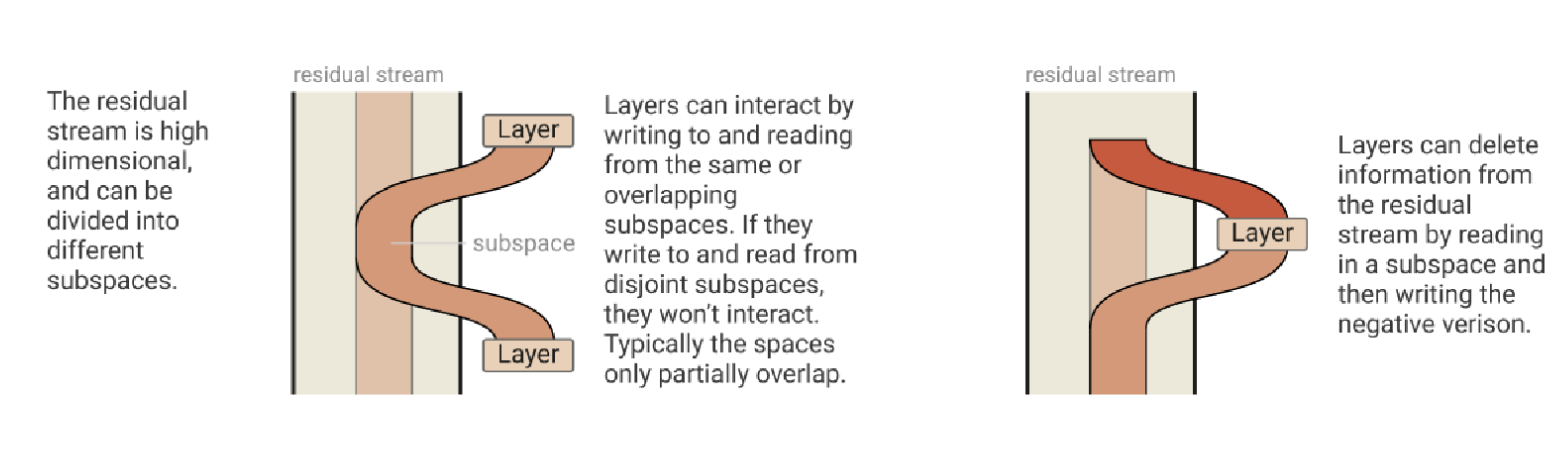
Attention Heads are Independent and Additive
They like to think of attention layers as completely independent heads, which process information in parallel, and add their output back into the residual stream.
Mathematically, Transformers are implemented as stacking, concatenating, and multiplying these big vectors and matrices, but thinking of them as operating independently in parallel and adding information to the residual stream is equivalent.
Attention Heads as Information Movement
What kind of information do they “read” from and “write” to the residual stream?
You can think of it as reading information from one token, and writing it to another token.
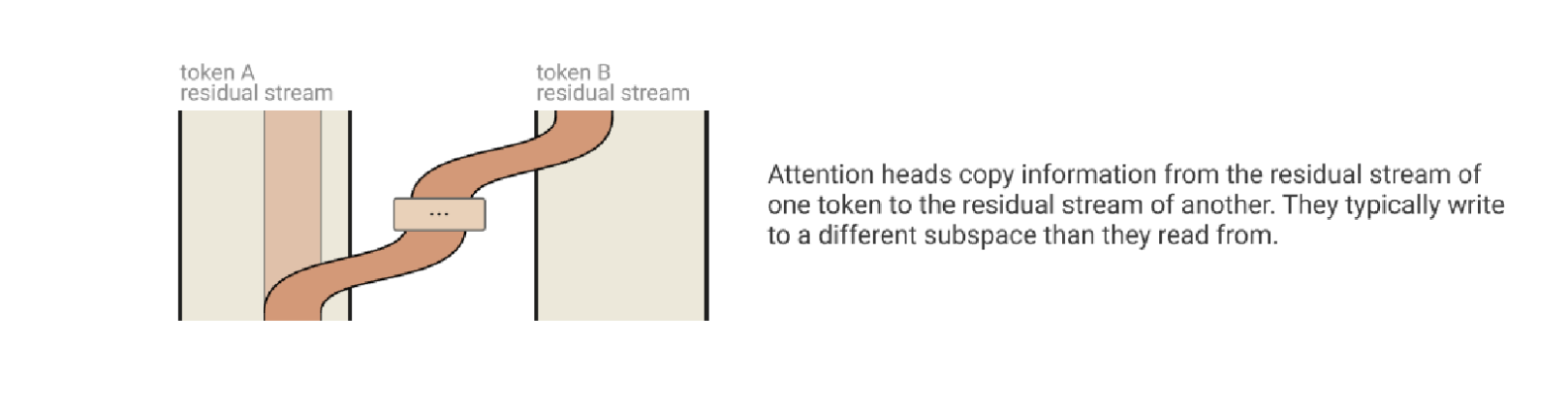
Token 1 might be the second instance of “Paris” and Token 2 might be the “,” and Token 3 might be “France”.
“France” has information from its positional encoding that says I am right after you Paris.
The attention mechanism, which is trained on a lot of data, has seen lots and lots of examples of “City” “,” “Country, State, Etc”. If you think about it, it is not that rare that a City is named after a person. Meaning whenever the attention mechanism sees a word that could be a City or could be a Person, it says “let me glance around me for more information…”
You may have a training data corpus that looks like:
“Washington lead his army to war”
“Obama flew to Washington, D.C.”
“There are only 24,407 people that like in Paris, Texas”
“Abraham Lincoln was the 16th president of the of the US”
“Lincoln, Nebraska is home of the cornhuskers”As you can see there are patterns of words that enrich the meaning of the token itself. For example where commas are, what capitalization is used, if words are surrounded by verbs, etc.
The “residual stream” is constantly looking at tokens and updating their meaning based on the context, and what it the model has learned about language from the training data.
Mathematically how does this work?
To describe what is happening under the hood, it’s helpful to lay out the information flow as a circuit rather than just a set of matrix multiplications.
The original attention equations are:
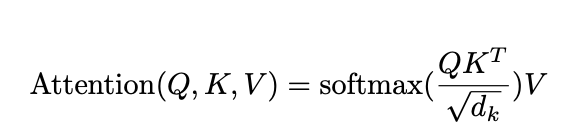
and

If these equations look intimidating, you are not alone. Even though I have a background in math, I usually skip over the actual equations until conceptually I understand what’s going on.
One Big Circuit
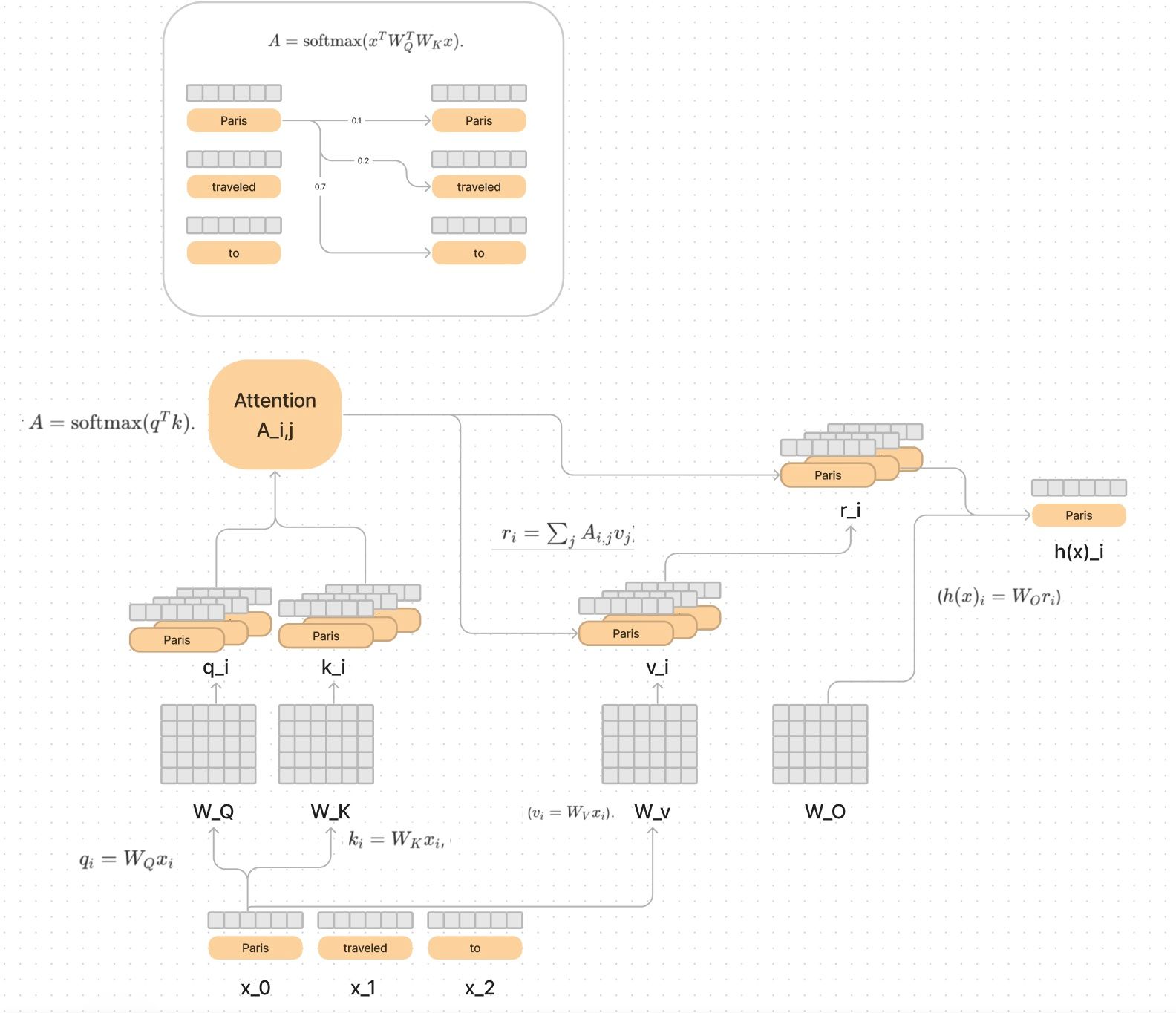
I decided to break down the sections from the paper and draw out each piece like a giant circuit of information flowing.
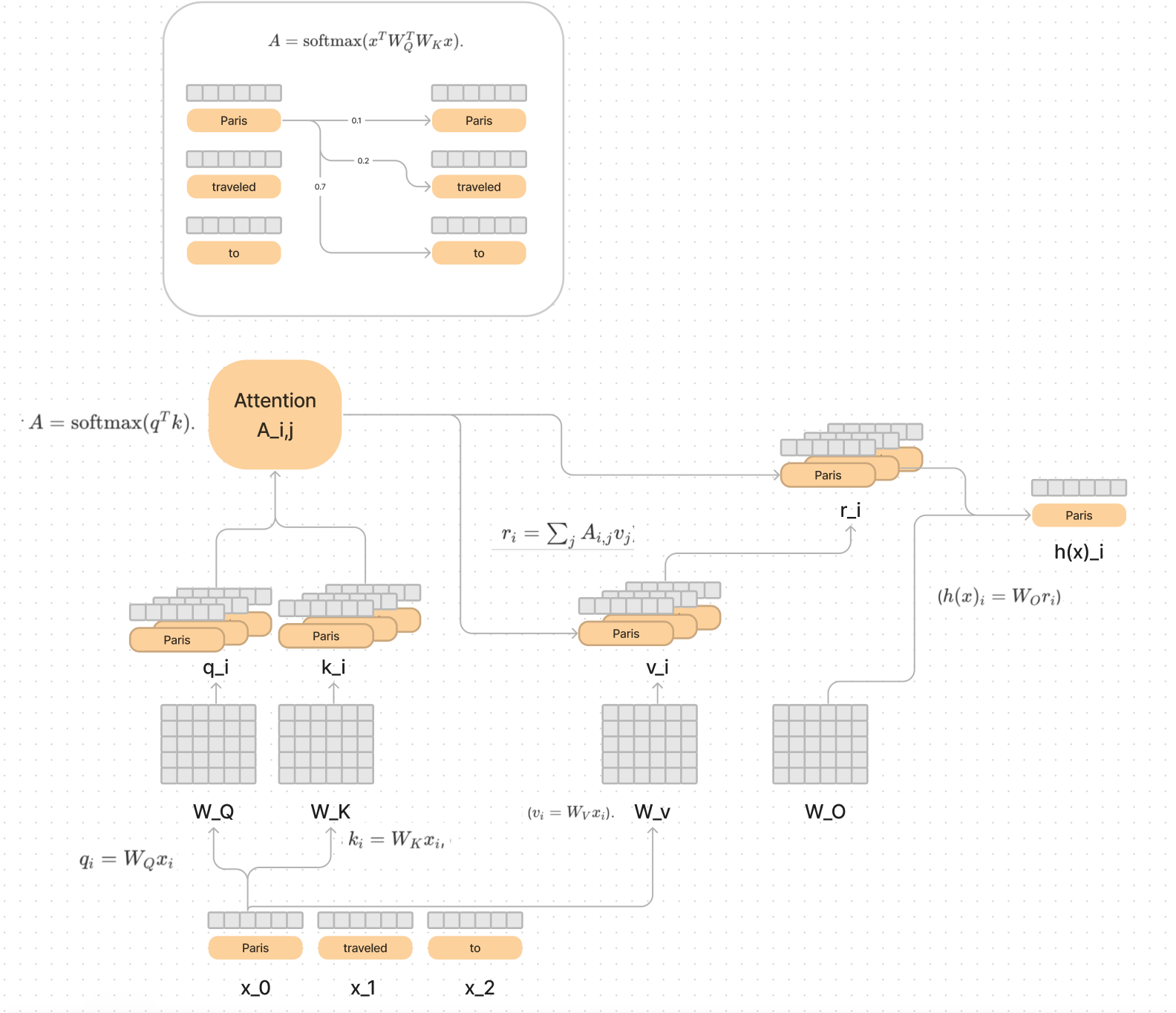
To break this down into a series of steps, I would start with the x_i being the embedding representation of the word (bottom left), and think about what the query and key weight matrices are doing.
Queries, Keys, and Values
Remember our shopping list analogy. Imagine you have a grocery list and are scanning the isles for items.

- The query is the current item on your list
- The keys are the items on the shelves
- The value is the item you end up selecting
The item you end up selecting might be slightly different or more specific than what is on your list. For example your list may say “milk” and you scan the shelves and buy “2% Organic Milk”. You did the mapping in your head that said out of all these items (keys), this one is the best match (value), given my list (query).
In the context of a sentence you can think of them as:
- The queries are the original word embeddings, with no context
- The keys are are all the other word embeddings
- The values are the word embeddings updated with the meaning from the context
You may want to keep the full diagram open on the side as we scan through each part.
The first operation in the circuit is multiplying each input embedding by a W_Q (Query) matrix and a W_K (Key) matrix.
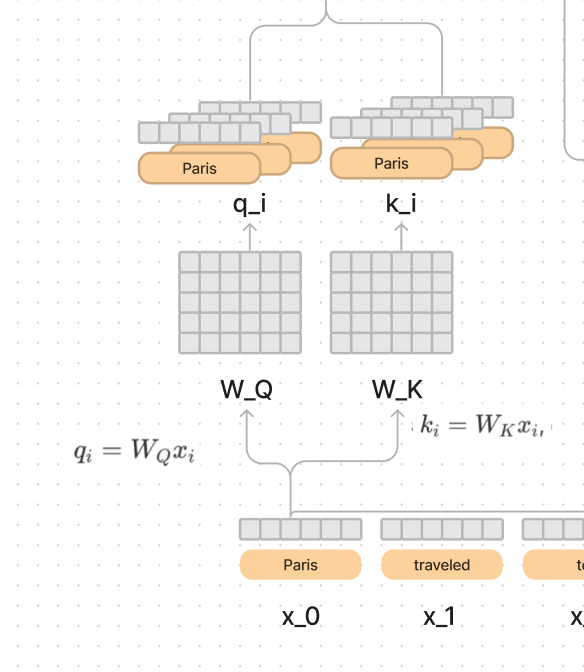
Each matrix Q and K has been trained by lots of data to prepare the meaning of each vector so that it can effectively communicate to the other ones what information it needs.
Paris may say: "Hey! I don’t know if I am a person or a place, but I sure know I could be either, and I am in position 1!".
Traveled may say "Oh hey Paris 👋 I am in position 2, and am very verb like, if that helps at all".
It knows it's position from the positional encodings, and the possible word meanings from the word vector itself.
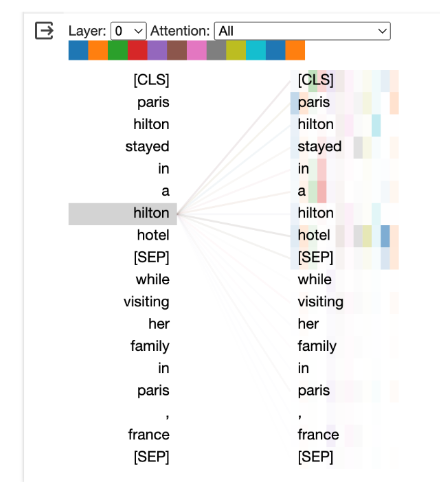
If you remember the BertViz demo from last time - it might be helpful imagine little numbers connecting each word saying “I want some of you, I don’t need any of you”.
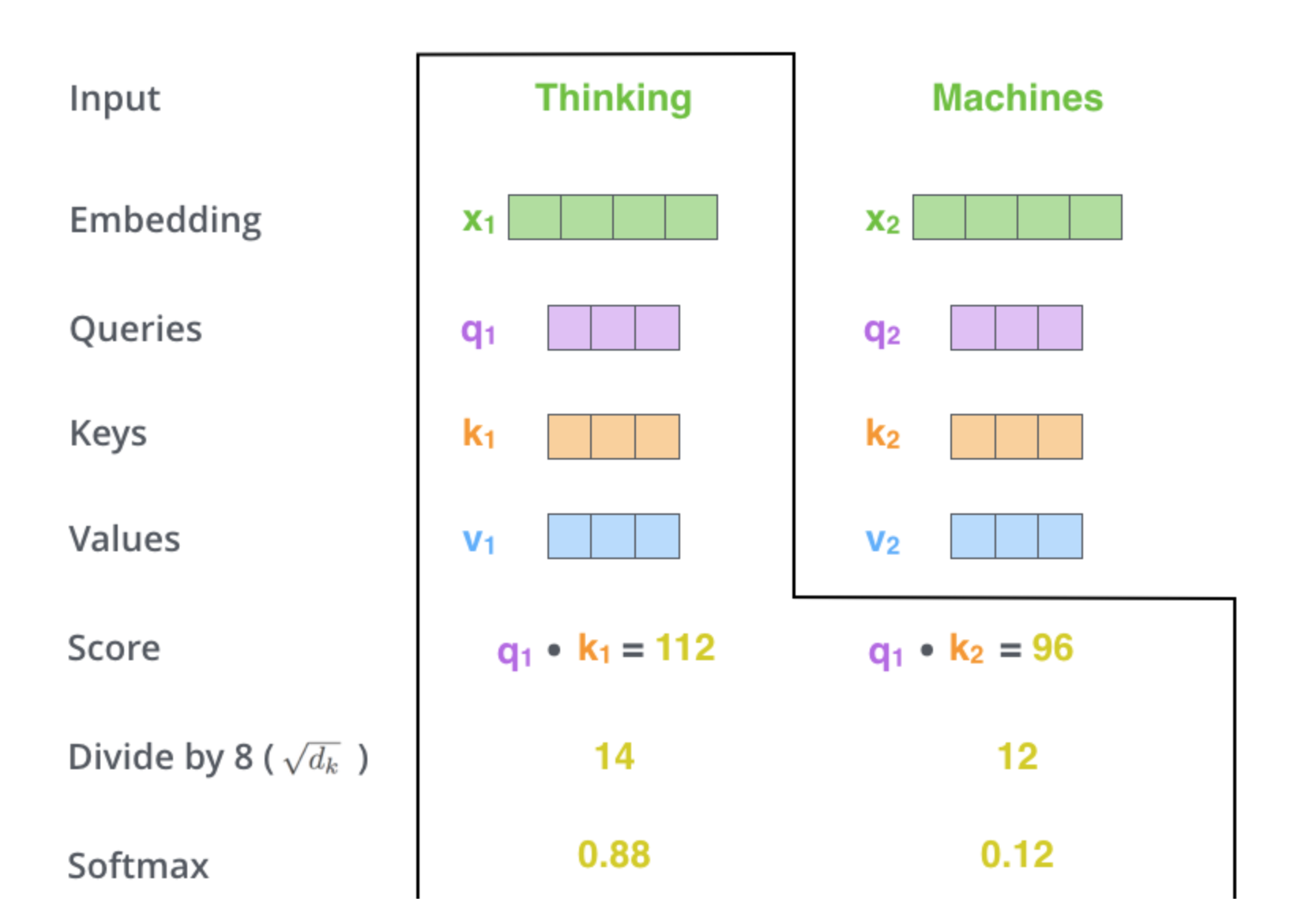
We then multiply (or take the scaled dot product) between each query and key to compute a “Softmax score” of how much information each token wants to grab from each other.
I love this example from “The Illustrated Transformer” to see what the actual softmax scores might look like.
In our diagram above, I broke it out into the first three words and examples of what the scores might be.
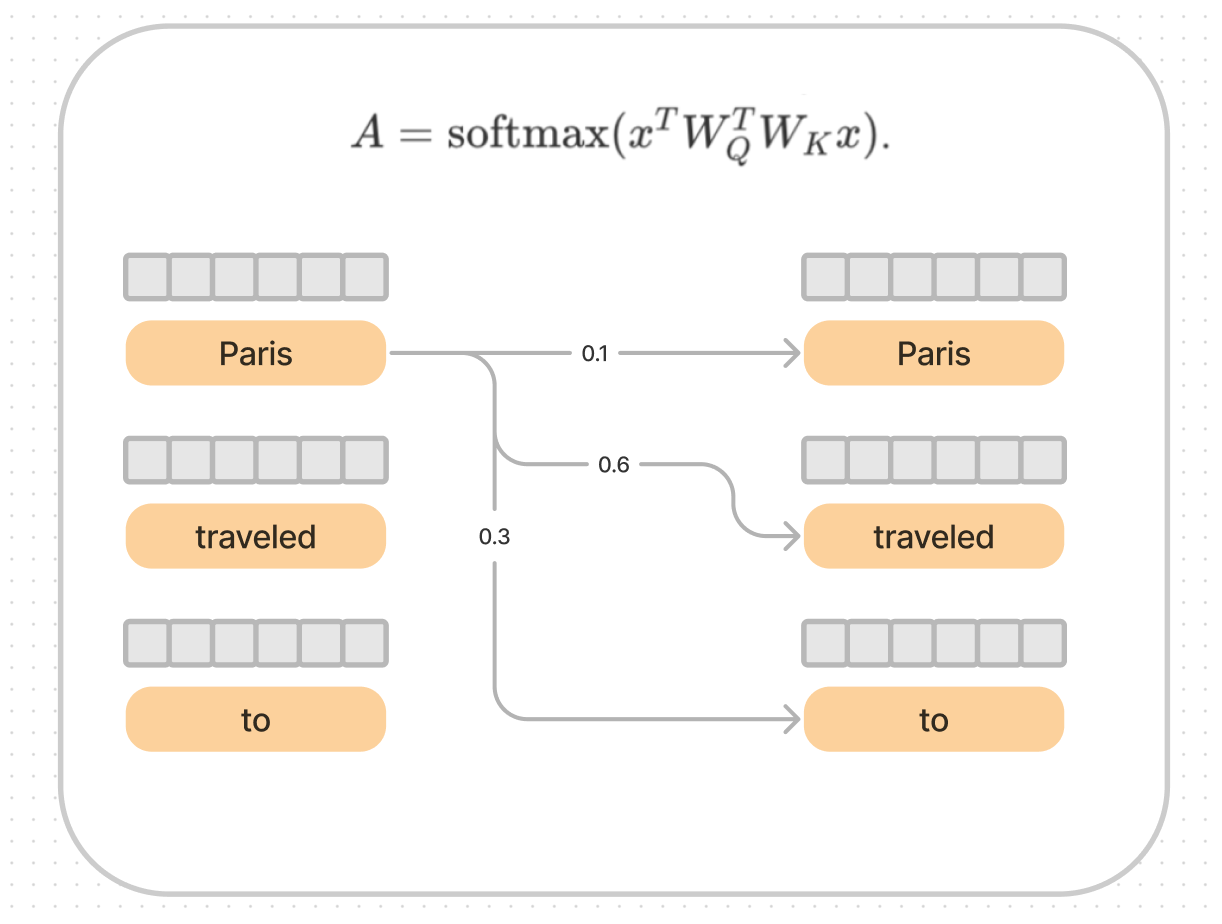
This is saying, given every item on my list, compared to every item on the shelf, which item on the shelf am I most interested in?
The Attention (softmax) scores indicate which words want to "join up" with other words and combine their meanings. The score will influence how much meaning it combines.
In the diagram above, Paris wants to take (0.6 * traveled) and (0.3 * to). In longer sentences these values will be much smaller, because the all have to sum to 1.0.
Then we take the attention scores as output of the softmax (A), and multiply it by the value vectors, in order to convert the meaning of each word, into a new meaning, given the words it was most interested in.
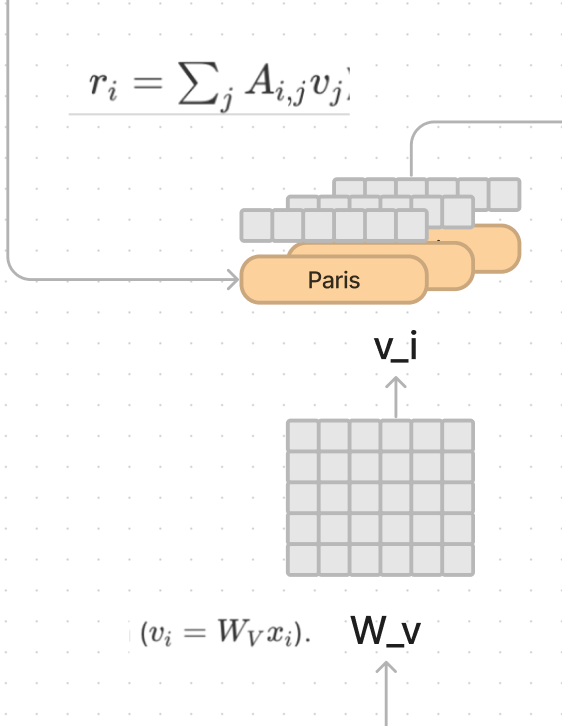
So if Paris found the comma after it, and France “interesting”, it would have high softmax scores for each of those keys, and say let us combine forces through the value vector that was computed.
This step gives us another result vector r_i. Finally you can take r_i and multiply it by the W_O matrix and get the complete a final meaning of Paris in the context of the sentence.
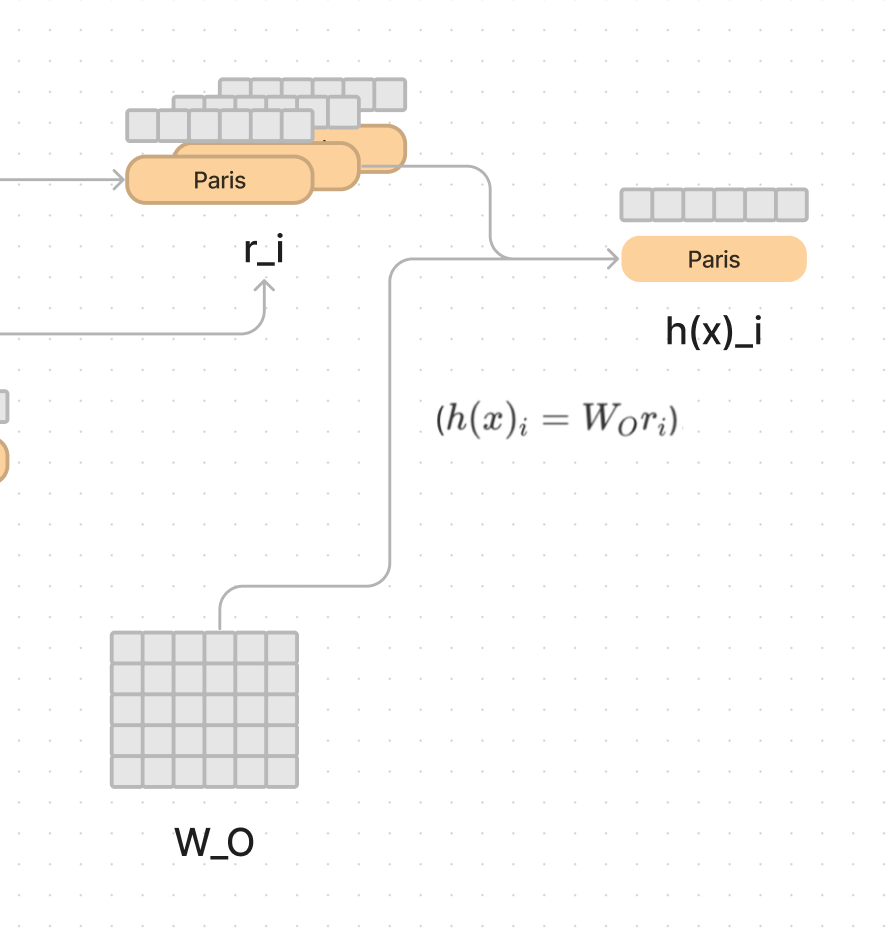
This is a lot of steps, and is often optimized and compacted by using matrices instead of individual vectors, but it is easier to conceptualize as vectors.
The paper states:

The order in which they go through the above steps in the paper was a little different, and expressed in mathematical statements, so I found it helpful to draw out the full circuit.
Observations from the circuit
- Attention heads move information in the residual stream from one token to another
- Attention head is really two linear operations
- A = attention, which decides which token we want information from
- WO*WV which decides what information for the token we are attending to gets written to the destination token
- WQ and WK always operate together. WO and WV always operate together.
- You can think of WQ and WK as the shopping list vs the current item we are looking for on the shelves
- You can think of WO and WV as the shelves themselves and the item that we found
- They say you can think of each one of these as individual low-rank matrices that can be combined
Next Up
We are going to stop and take a breath here and soak in all this information 😮💨
Next they strip the circuit down to it's simplest form as zero-layer transformers with no attention. Then progressively build up one-layer attention-only transformers and two-layer attention-only transformers.
At each step we will learn the innate abilities of simple models, adding a layer of complexity at a time. This will help us see how the model performs higher level more complicated tasks.
If you enjoyed this dive, please join us next week!

All the past dives can be found on the blog.


The live sessions are posted on YouTube if you want to watch at your own leisure.


Best & Moo,
~ The herd at Oxen.ai
Who is Oxen.ai?
Oxen.ai is an open source project aimed at solving some of the challenges with iterating on and curating machine learning datasets. At its core Oxen is a lightning fast data version control tool optimized for large unstructured datasets. We are currently working on collaboration workflows to enable the high quality, curated public and private data repositories to advance the field of AI, while keeping all the data accessible and auditable.
If you would like to learn more, star us on GitHub or head to Oxen.ai and create an account.