Arxiv Dives - A Mathematical Framework for Transformer Circuits - Part 2


Every Friday at Oxen.ai we host a paper club called "Arxiv Dives" to make us smarter Oxen 🐂 🧠. We believe diving into the details of research papers is the best way to build fundamental knowledge and keep up with the bleeding edge.
Our goal is to have done 50+ of these in a year. A lot of folks have shown up consistently for each, which has been a lot of fun. Imagine how much knowledge we'll have gained at the end of a year, and the pattern matching we’ll be able to do after a year full of deep dives.
If you would like to join the discussion live, sign up here. Every week there are great minds from companies like Amazon, Doordash, Google, MIT, NVIDIA, Tesla, and many more.

The following are the notes from the live session. Feel free to follow along with the video for the full context.
Mathematical Framework for Transformer Circuits
The paper can be found here:
Published: Dec 22, 2021
Team: Anthropic
If you did not follow along with last week’s dive, we went over the first half of the paper and are building off it today.
The full circuit looked like this:
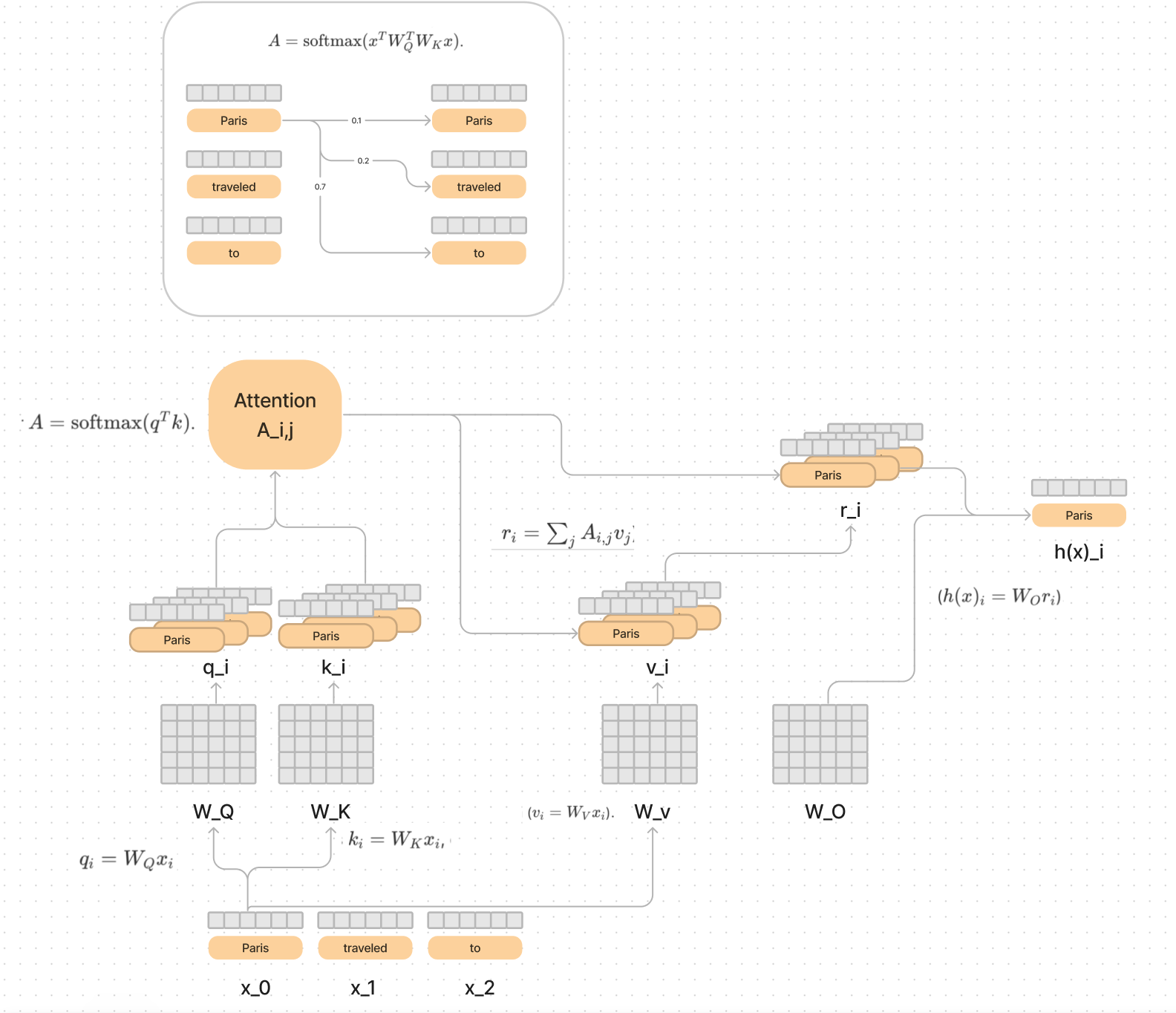
Feel free to go watch last weeks dive for the recap.
This week we are starting from the simplest version of a language model, and building the transformer model back up piece by piece.
We will move through:
- Zero Layer Transformers
- One Layer Attention Only Transformers
- Two Layer Attention Only Transformers
Working Example
In the paper they use the first paragraph of Harry Potter to build up some intuition of how different layers of attention work. So let’s pick an example sentence that can drive these ideas home.
“Potter can fly on a Nimbus 2000 to Hogwarts”
The word potter on its own could be a profession. The word can could be mean “food in a can” or “has the ability to” or “has permission to”. The word fly without context could be a “fly on the wall” or “fly by airplane”. Only with some pre-existing knowledge and all the words combined can we truly know the meaning of the sentence.
Key Takeaways from Part One
Attention heads can be understood as independent operations, that “read” and “write” information to the “residual stream” by updating the values of word vectors to understand the meaning of the sentence.
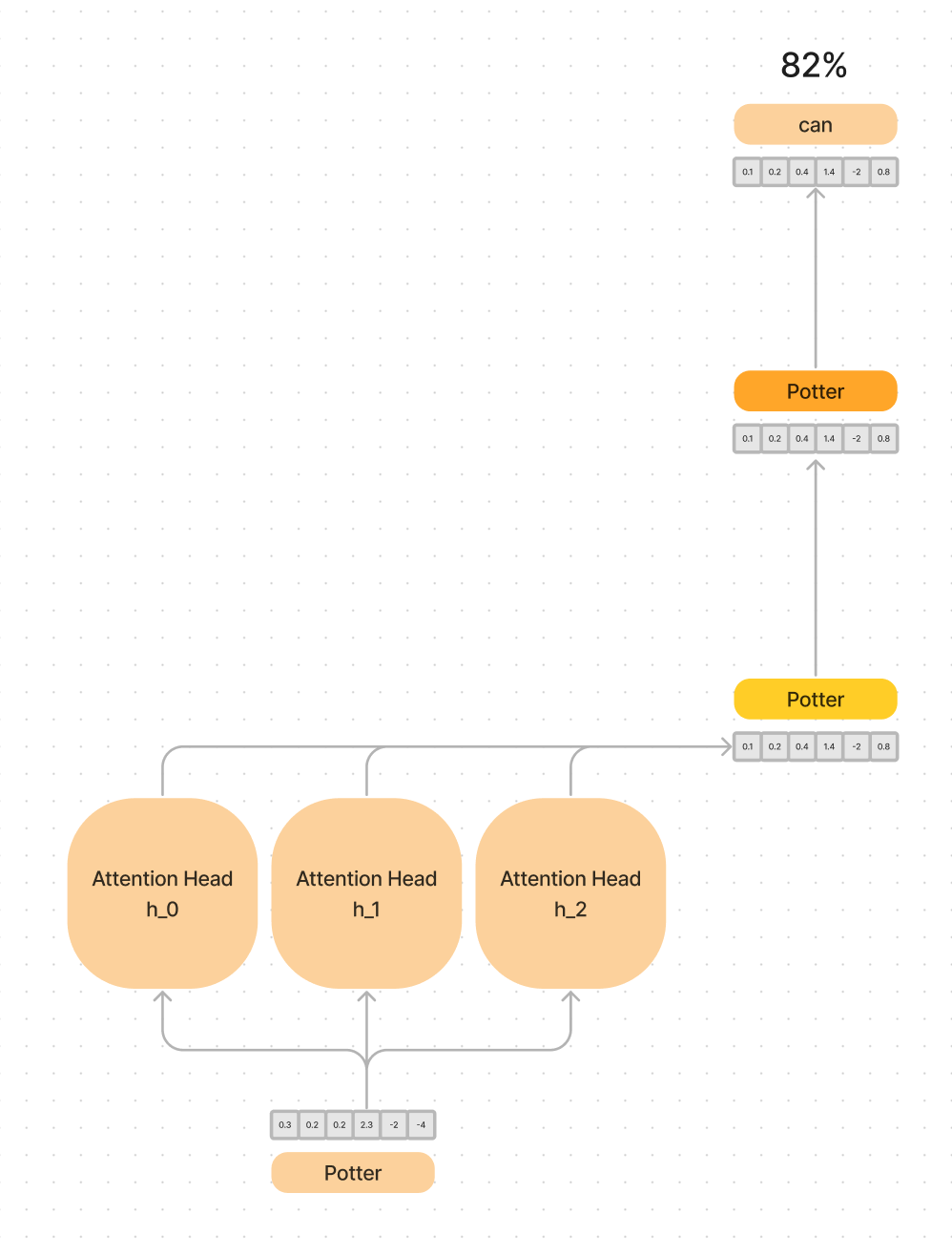
In this simplified diagram, each attention head is updating the meaning within the vector space of the word potter by looking at the words around it.
Attention-only models map tokens to logits (or predicted next tokens), and can be thought of as paths through the model.
Key, query, and value vectors can be thought of intermediate results of WQ*WK and WO*WV.
QK = A = softmax(WQ*WK) = the attention circuit, and determines what the new meaning of the words should be.
OV = WO*WV = the deciding on the output meaning of the word into the residual stream, to make the prediction.
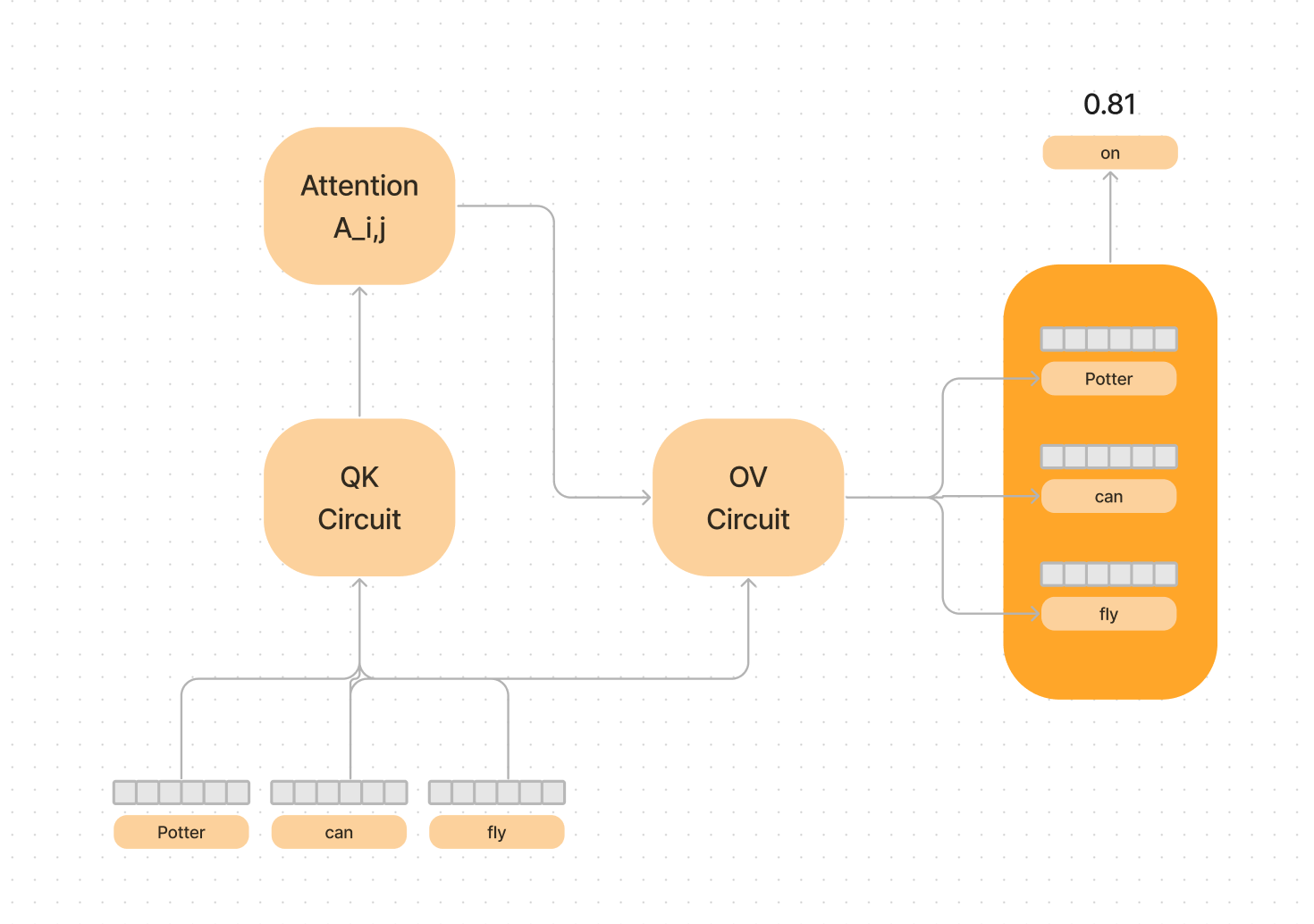
If all this is gibberish, Part One should help clear things up.
Now lets strip the transformer down to it’s simplest form, and build it back up piece by piece.
Zero Layer Transformers
They start by stripping away everything we just did above, and create a “Zero-Layer Transformer”.
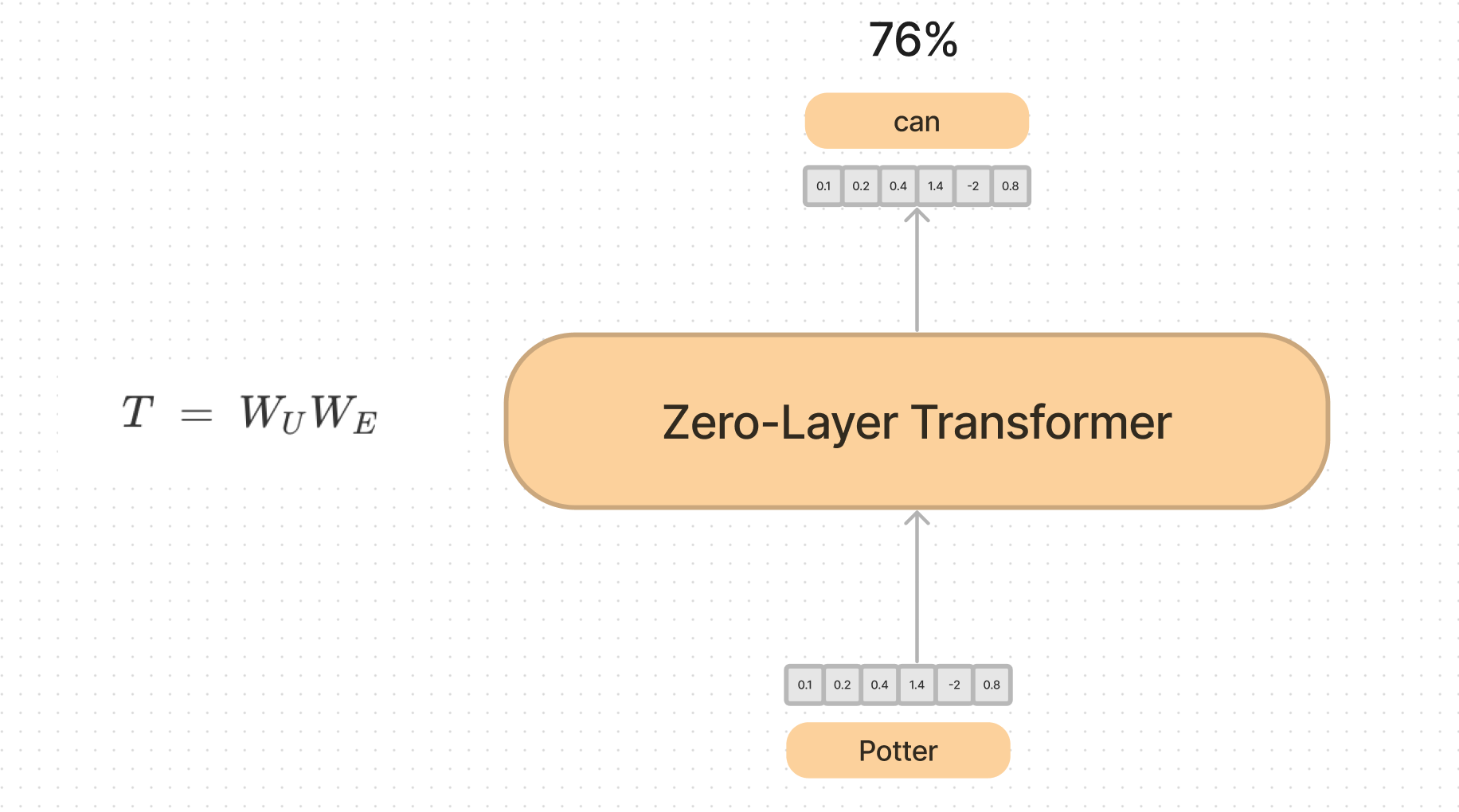
This is just one linear operation (matrix multiplicaion) to go from one embedding, to another embedding, and predict the next token. This is very similar to what the early word embedding papers did to simply learn the meanings of words.
This model has no way of the token learning information around surrounding tokens, so is approximating the statistics of bigrams, or the probability that pairs of words are seen together.
Bigram statistics can be thought of as how many times each pair of word shows up next to each other in the training data.
For example “Barack” is often seen before “Obama”.
”Lincoln” might appear before “Nebraska” or after “Abe”.
“Fly” can be seen with many different possible other words.
- “Fly” -> “on”. “Fly” -> “to”
- “The” -> “fly”
- “Fly” -> “buzzed”
- “Fly” -> “was”
- “His” -> “fly”
It is clear that you need more than bigram statistics to build coherent, creative sentences.
One-Layer Attention-Only Transformers
To go beyond bigram statistics, they introduce one layer of attention.

In this case, they strip out the feed forward layer
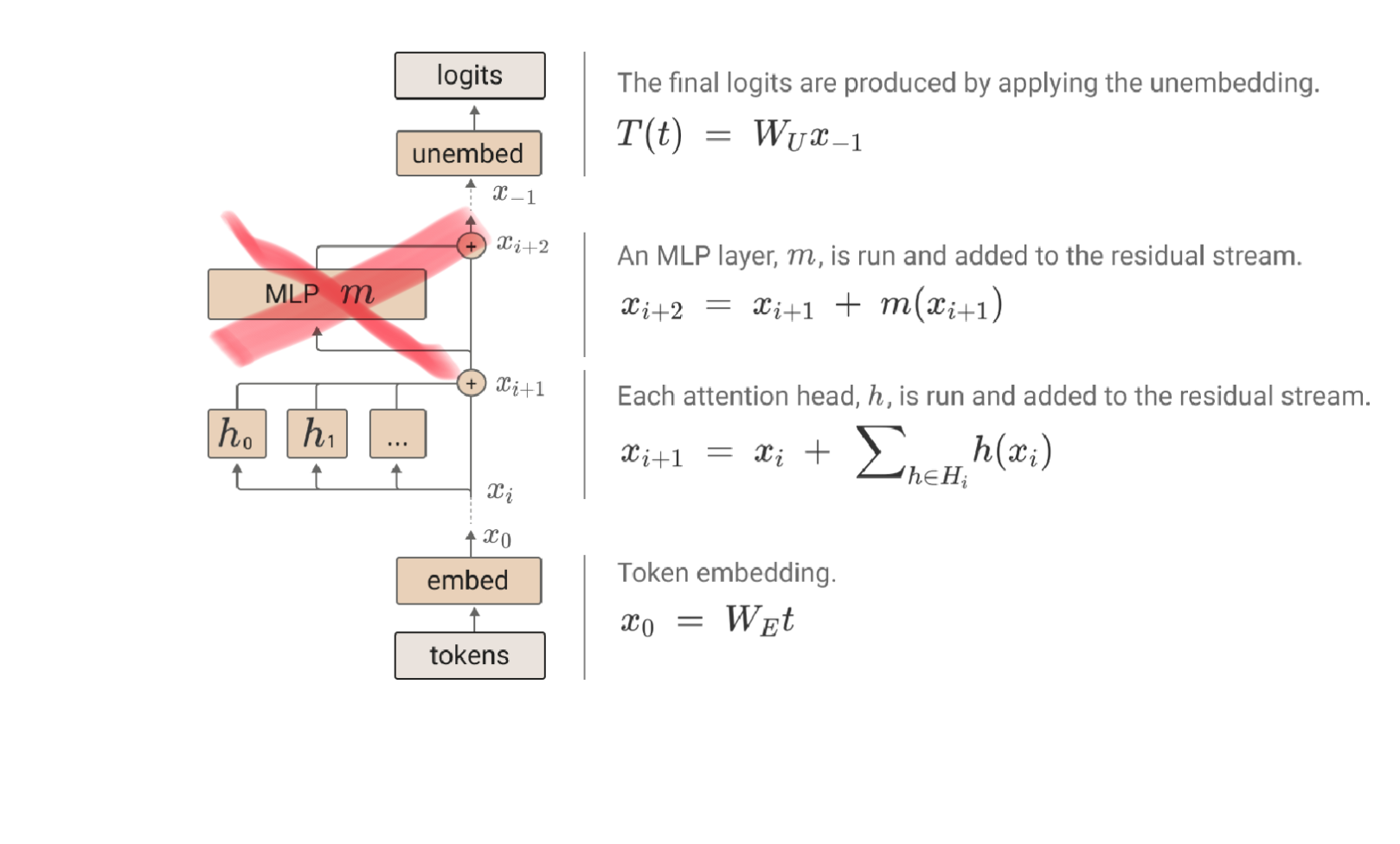
And are left with just the attention mechanism

A way to visualize this is that the bigram model still passes information through the residual stream and the attention mechanism is strapped on top to look at other words in the sentence for additional context.
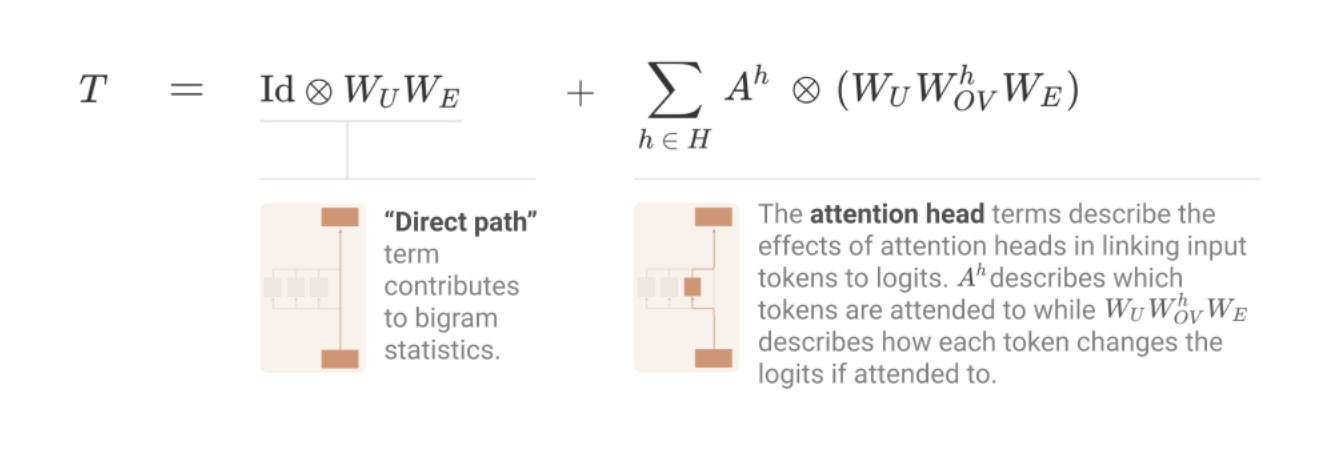
Attention helps the model make a more informed prediction about the output, given the other surrounding words.
For example, think of our first three words from before. “Potter can fly”. They are each represented by a word embedding that has a vector of numbers that correspond to different meanings the word could take on.
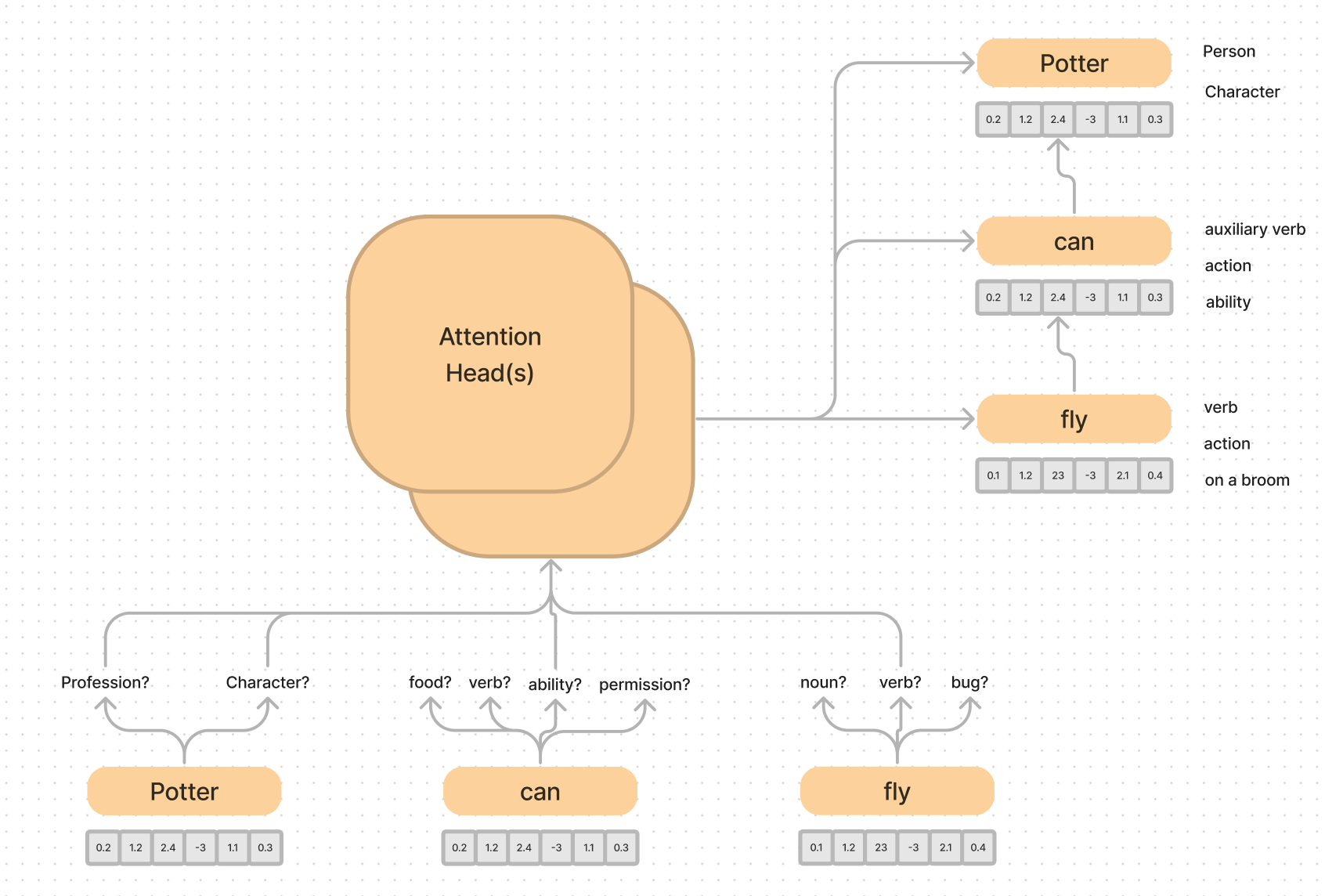
The attention heads call out from one word to another to pull in context and shape the vector into a more accurate meaning given the context.
Splitting Attention Head terms into Query-Key and Output-Value Circuits
Like we saw in our big diagram above, it is helpful to think of the queries and keys and the outputs and values as separate.
The query-key (QK) circuits job is call out from word to word and combine meanings in the sentence.

The output-value (OV) circuits job is to synthesize this information to make a prediction about the next word.

These diagrams and equations helps define some of the terms above.

You can think of it as information flowing through the two paths through the model.
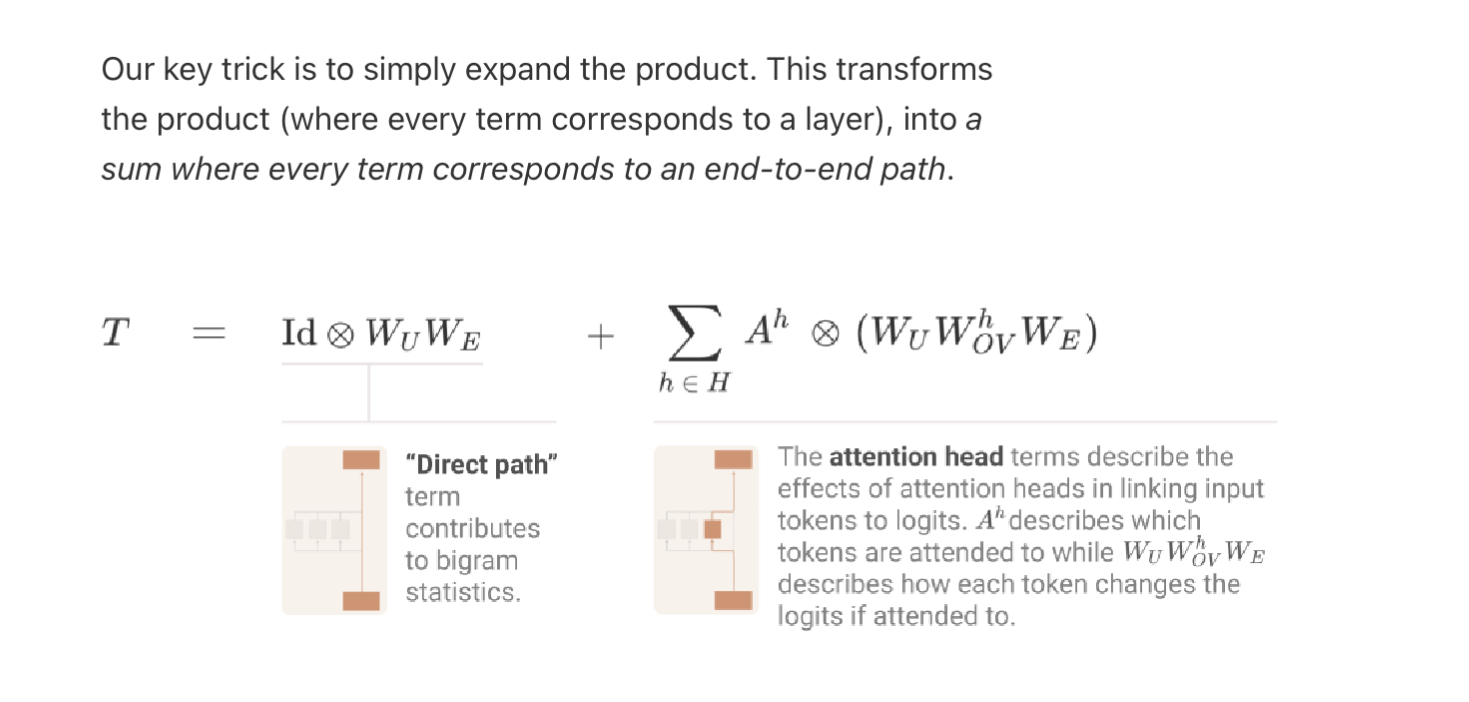
You can think of W_Q as allowing each token to say “I need context about ‘fly’”
You can think of W_K as each token to say “I can help with context, if you merge with me, I will make you more verb like”
They learn how to do this mapping from lots and lots of data and examples of similar words in similar situations. Similar meaning their token embeddings are similar.
Then OV circuit determines how much each “destination” token embedding affects the output.
Interpretation as Skip-Trigrams
You can think of these three steps above as:
[source]…[destination][out]
“Potter”_0 -> QK -> “can”-> OV -> “Potter”_1 -> Fly
Potter .. can -> fly
Potter attends to “can” helping predict “fly”.
In larger transformers Potter attends to all the words in the sentence, through many layers and attention heads, and then modifies itself to have a slightly different meaning, which affects the output.
In seems that in single-layer attention-only transformers, there is not enough capacity or paths for information to be passed to abstract farther than simple skip trigrams.
Simplifying down to skip trigrams does not mean the process is trivial.
The matrices we are dealing with are much larger than we can visualize in our head.
The vocabulary (or set of words/tokens we can choose from) is ~50,000, so a single expanded OV matrix has 2.5 billion entries. It’s really hard to see what’s going on inside.
If you are familiar with the Chinese room experiment, where a person is given a set of rules to translate English to Chinese perfectly, but the person inside does not actually speak Chinese. To an external observer, it looks as if the room “knows Chinese”. But does it really?

The one-layer attention-only module is simply a giant pile of cards that the models is choosing from and combining common skip-trigrams that it has seen before.
Interesting Skip Trigrams
They show some interesting skip-trigrams and how the embeddings come out of the QK/OV circuits.
QK/OV entries 12 heads, d_head=64 https://transformer-circuits.pub/2021/framework/head_dump/small_a.html
They plot out given a key, which queries prefer that key, and what they help predict when they are put together.
If you click the link above, you can see all the different attention heads and what they are attending to. Head 0:0 means the 0th head in the 0th layer of the network.


They note that it is hard to normalize the values before creating these tables because the softmax affects how much the word changes in each sentence, so sentence by sentence they aren’t comparable.
They select the interesting or important keys for queries to look at by doing:
QK.max(0) * OV.max(0) * token_prob ** 0.1
Which means they favor keys with queries that strongly prefer them, and have a large affect on the output.
They put the output tokens by looking at the tokens with the largest probabilities given the QK.
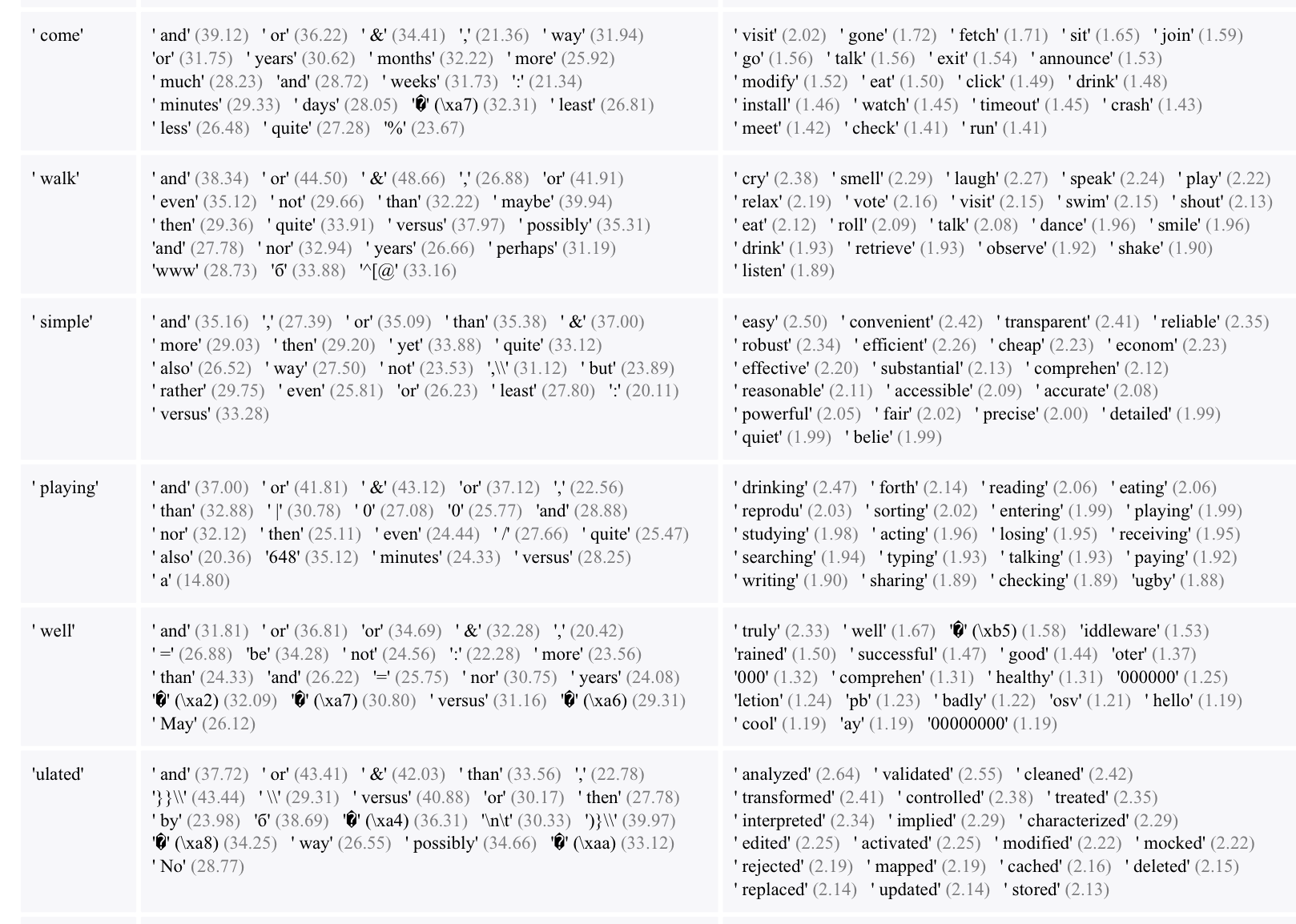
They do this head by head and you can see the first head is very interested in “and” or “or” or commas or any words that could join up with other words.
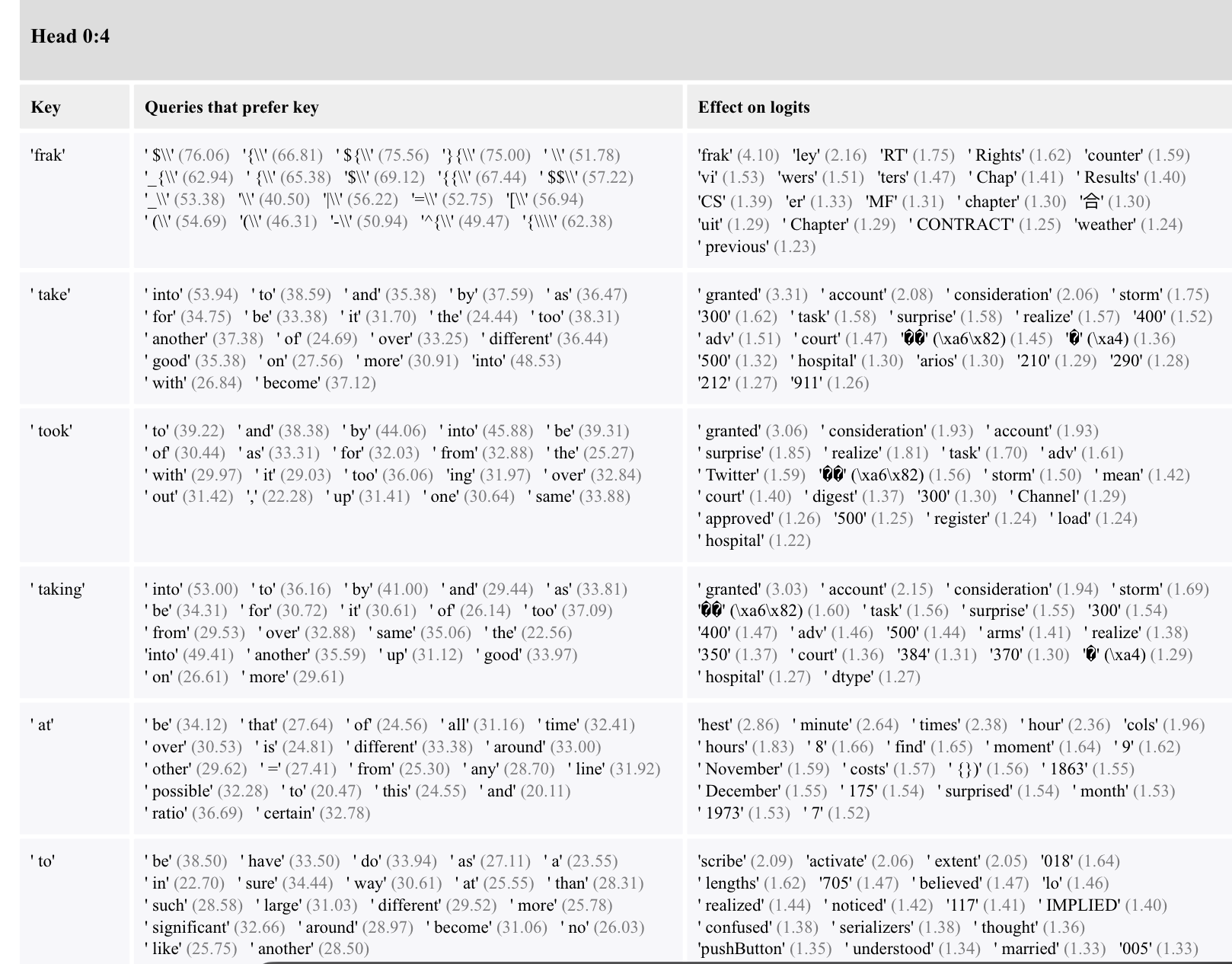
Head 0:4 is looking more at verbs and prepositions like: “be” and “to” and “in” and “over”
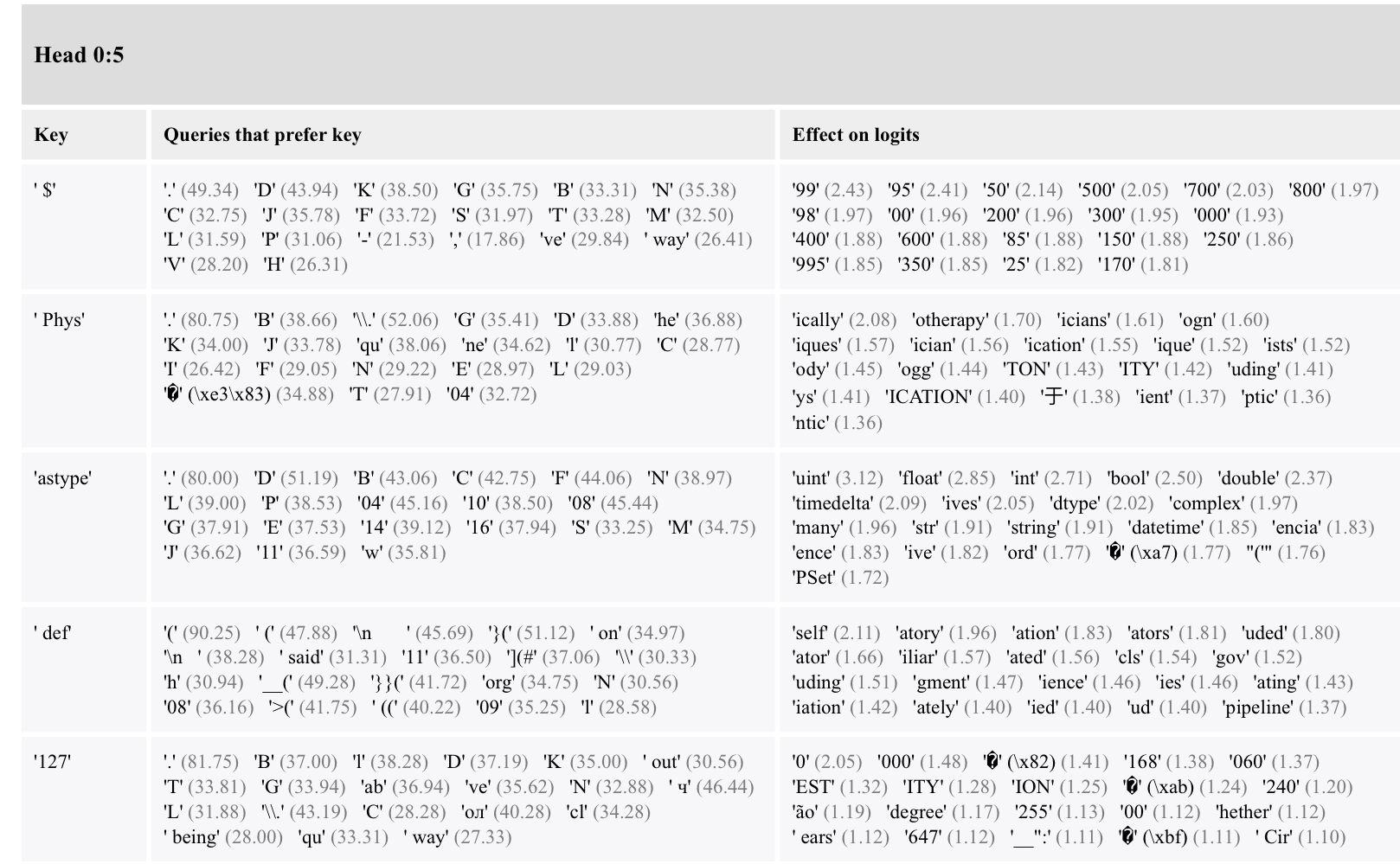
Head 0:5 is looking a lot at capital letters and numbers:
It is fun to go through and try to see why each head might have attended to different things, but you can see it is not straight forward to tell the exact cause of one token influencing another. It is the combination of all the heads together looking at tiny little nuances of the sentence that add up to the full prediction.
Also note we have been hand waving by saying “word vectors”, this is what tokens really look like in practice. Subwords and sequences.
Copying / Primitive In-Context Learning
One thing that stands out about these matrices is that a lot of attention heads in “one layer” models dedicate a lot of their capacity to copying.
The OV and QK circuits increases the probability that the token gets copied directly into the outputs stream, but only where bigram statistics make sense.
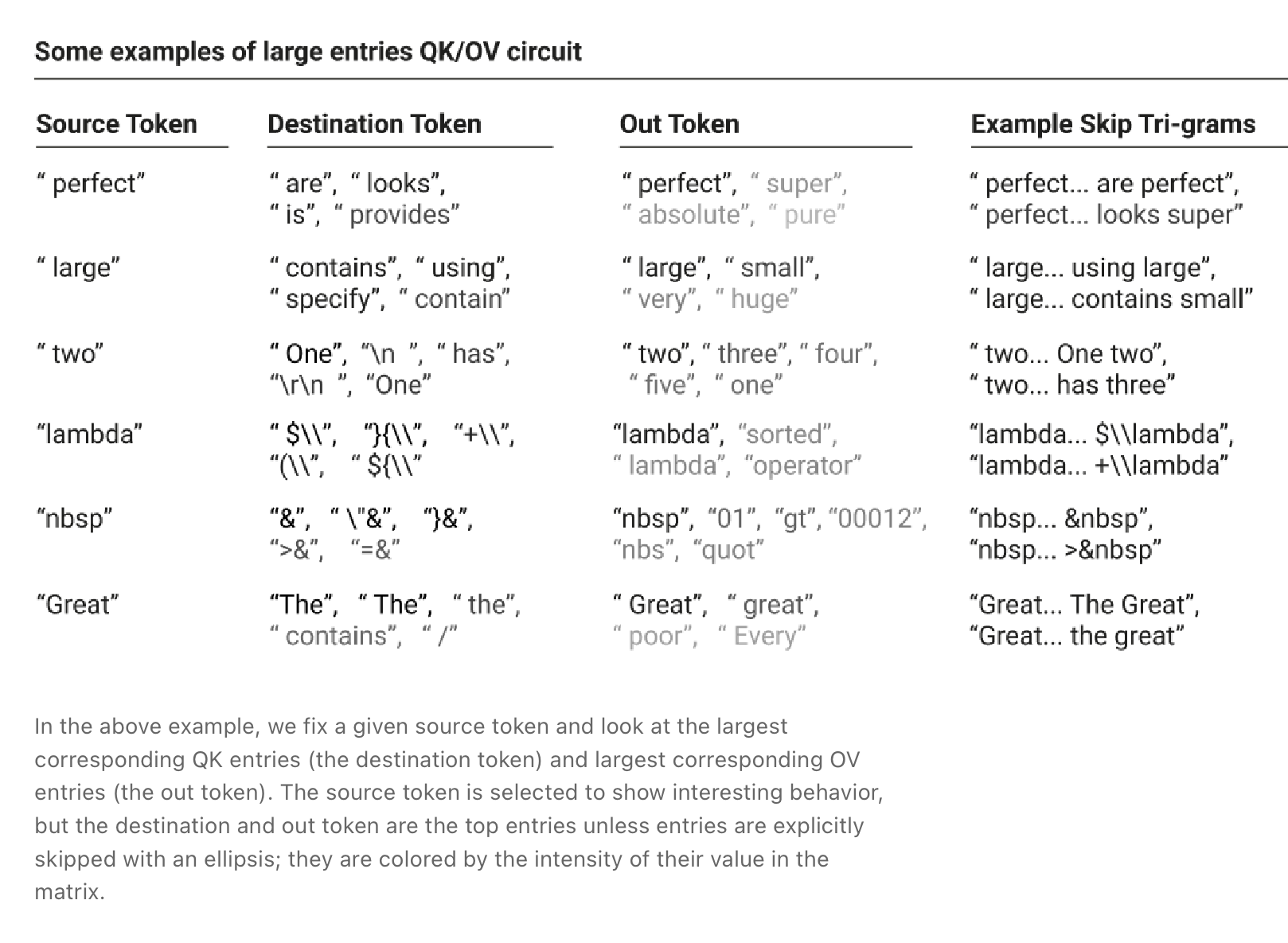
This makes sense intuitively because you do not want to lose information about the initial token. You might want to modify the vector values a little bit, but not too much.
When they say “out” token they mean “the largest corresponding OV entries” or the affect the given token have on the logits / predictions.
When they say “destination” token they mean “the largest corresponding QK entries” or what other tokens are we attending to in the sentence.
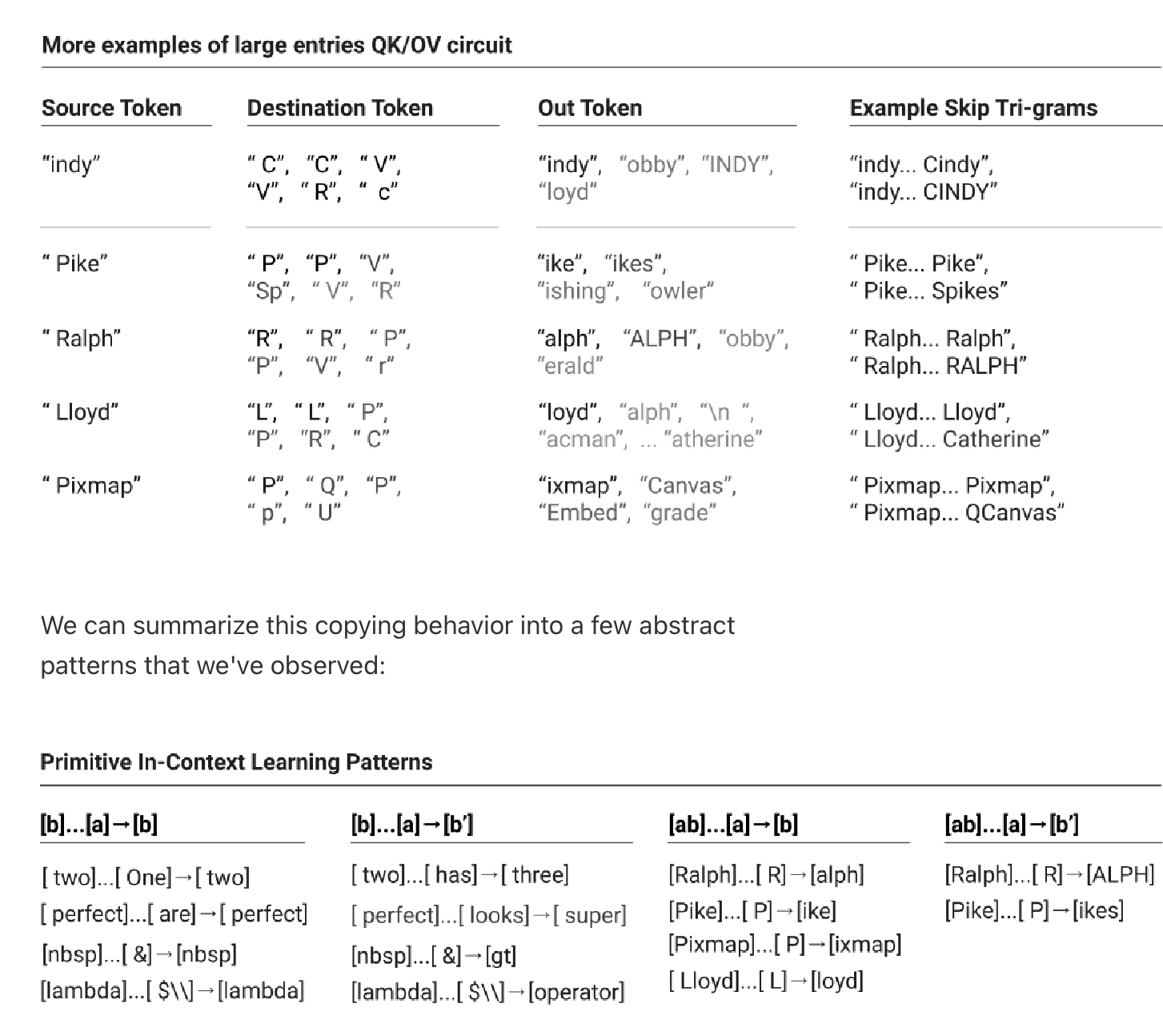
They state that copying is a very simple form of in-context learning, and starts to form patterns.
The two-layer transformers that we will look at next can pick up on much more interesting and powerful patterns.
Other Skip Trigrams
Python
Keywords that are more common after indentation.
- \n\t\t … \n\t -> else/elif/except
Predicting arguments for functions.
- `open` … `,` -> rb / wb / r / w
For example open(“abc.txt”, “r”)
HTML
Creating a table knows that tbody and td tags go together.
- <tbody> … < -> <td
English
Common phrases
- keep … in -> mind
- keep … at -> bay
- Back … and -> forth
- Past … and -> present
Note: these happen to all be next to each other, but “skip” means they don’t have to be. It just happens in the single layer these are easier patterns to learn.
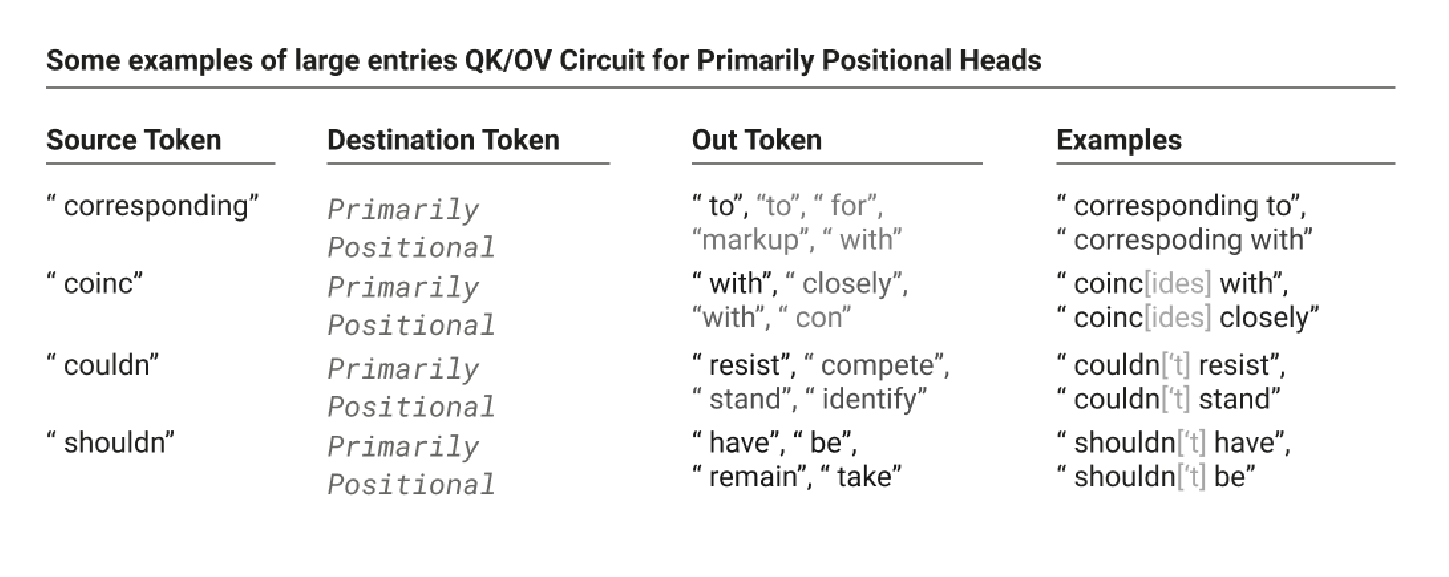
Primarily Positional Attention Heads
Aside from copying information through for bigrams and skip trigrams, there are attention heads that attend primarily to positions, strongly preferring to look at certain relative positions.
For example, always look at the token right after you to help figure out your meaning.
Two-Layer Attention-Only Transformers
It is called “deep learning” because you can stack these layers on top of each other.
An intuition is that depth allows composition, which creates expressiveness.
We saw with the single layer transformers some simple operations like copying, skip-trigrams, or looking at positions around you.
Two layer transformers allow you to take these primitives of copying and naively choosing where to look next, and composes them.
Kinds of Composition
The first layer head has a pretty simple attention pattern, it primarily attends to the previous token, the present token, and the token two back.
The second layer introduces what they call “Induction Heads”.
“Induction” in mathematics means proving a theorem by showing that if one case is true, then it should be true in the next case in the series, and on and on.
They note that it looks like most attention heads are not involved in any substantive composition, you can think of them roughly as a larger collection of skip-trigrams.
The two-layer model is quite the mystery, but they have some theories of what is going on.
There is an interactive diagram of the value weighted attention patterns of “Harry Potter and the Philosopher’s Stone”
They take what’s called the “Frobenius norm” of the product of the relative matrices to figure out how much a query, a key, or a value of the second layer reads in information from the first layer.
Highlighting attention heads from the first layer shows the attention pattern of words directly next to or around the current word.

Above, the head that is clicked on is 0:7 (layer 0 head 7) and below I clicked on 1:3 (layer 1 head 3) and you can see the “value weighted attention pattern” is much lower.

The “value-weighted attention pattern” is how big of a vector is moved from each position.

Induction Heads
In two-layer attention-only transformers the main form of composition is what they call “Induction Heads”
These heads are a more powerful mechanism for “in context learning” than simply the copying that is done from the first layer.
“In context learning” can be thought of as “prompting”.
Induction heads search over the context for previous examples of the present token, if they don’t find it, they attend to the first token and do nothing. If they do find it, they look at the next token and copy it. This allows them to repeat previous sequences both exactly and approximately.
If you look carefully below, you will see that I highlighted “leys”, and the attention mechanism looks back on the sentences and finds other instances of “leys” to help inform What this instance means.

This allows us to be much more confident in predictions if we have seen previous examples.
It’s also less likely that you will go down a random path you didn’t intend to because it can follow patterns from above.
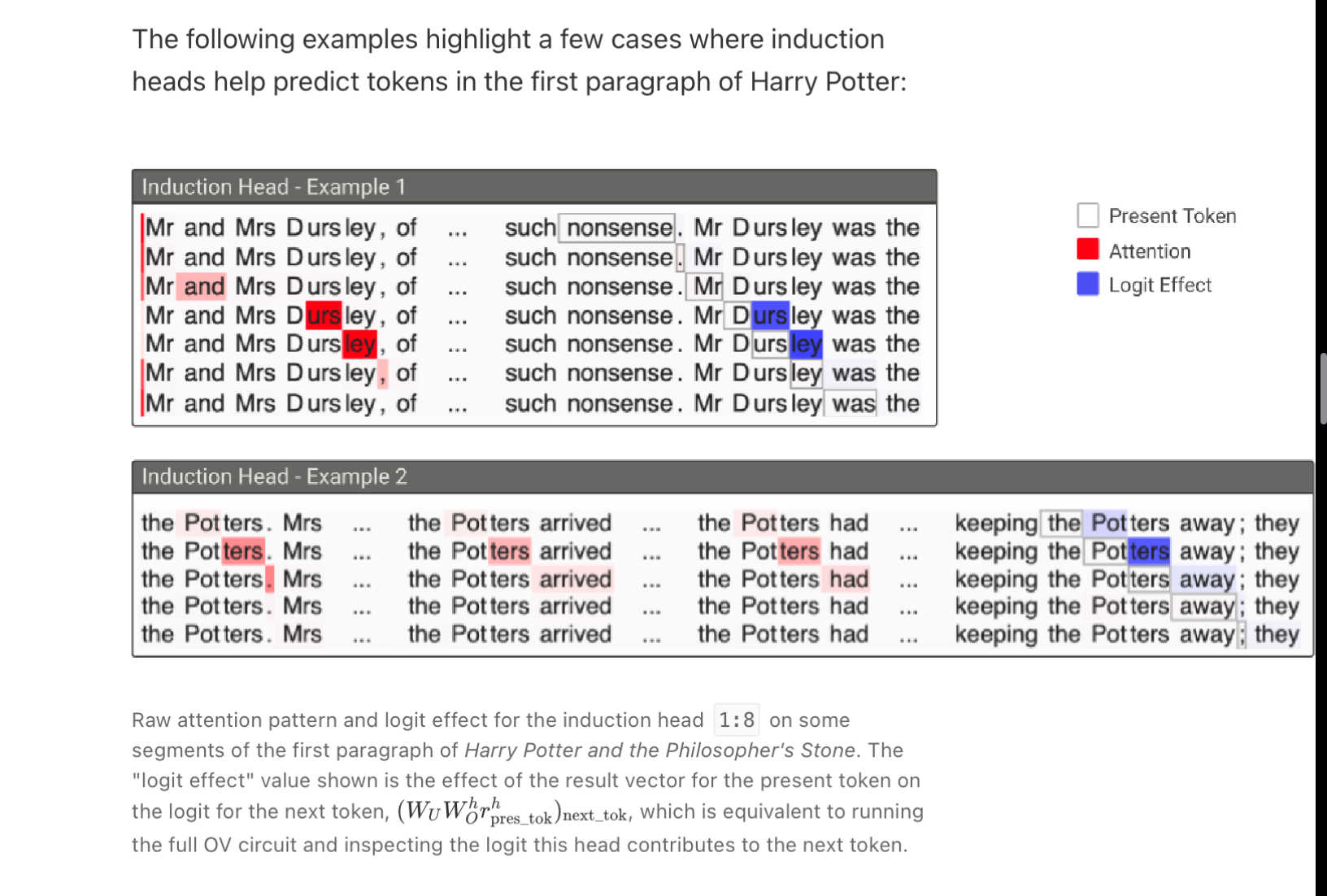
If a similar vector has not been seen before, the model tends to just look back at the start of the sequence.
Pay attention to the present token with the gray outline, look at where it “attends” to, and then look at how strongly this affects the “logit” or prediction.
Since “nonsense” has not been seen before it attends back to the start of the sentence. Then predicts a period. Then predicts Mr which looks back and sees “and” then predicts “D” and looks back and sees “ursly”.
To test out this theory, they state that induction heads should be able to run the same process on totally random repeated patterns.
This would require them to only rely on which tokens typically come before them, and not the statistics from the training data.
Below you can see I clicked on <7192> and it attended the previous example of that token in the sequence.
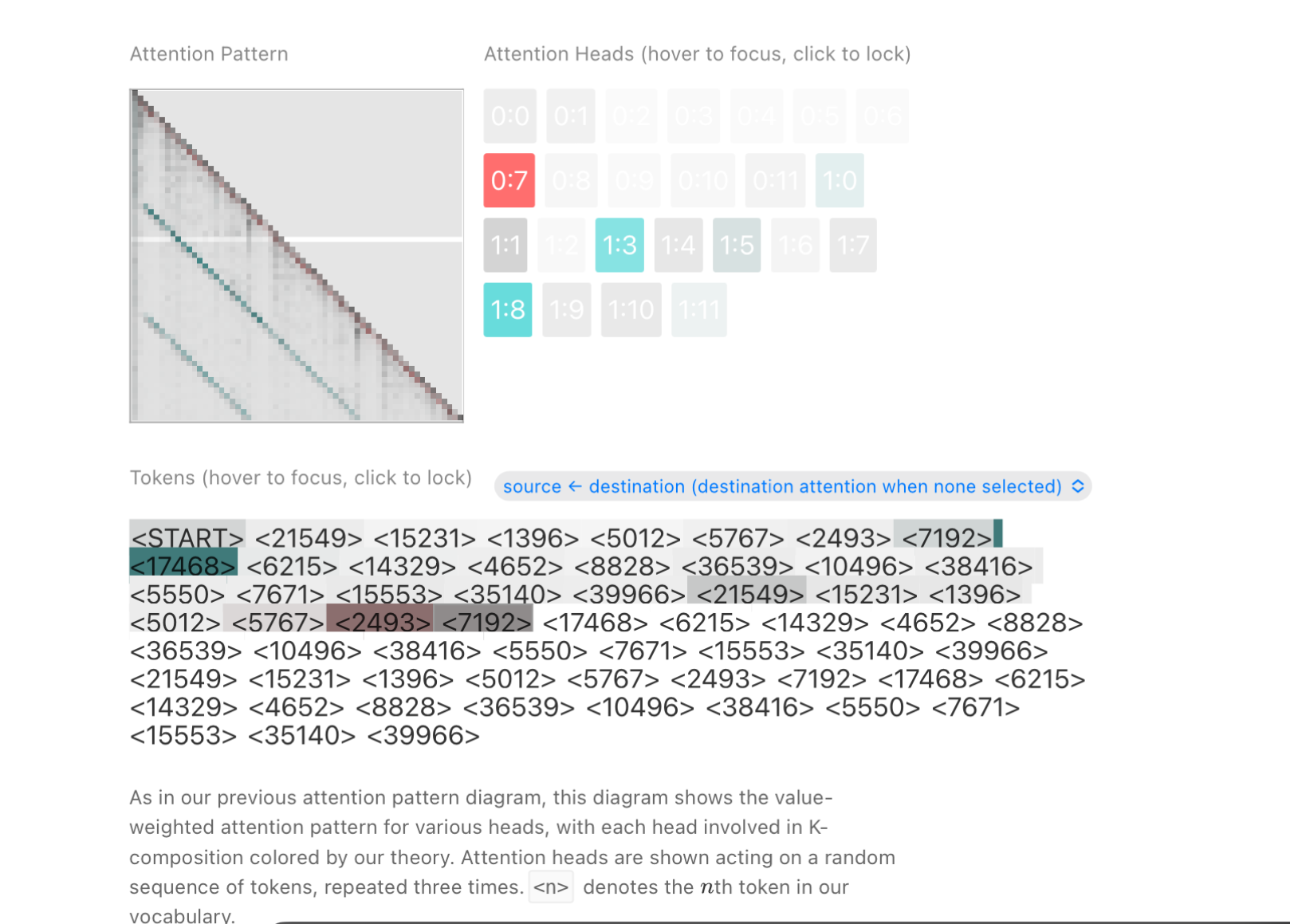
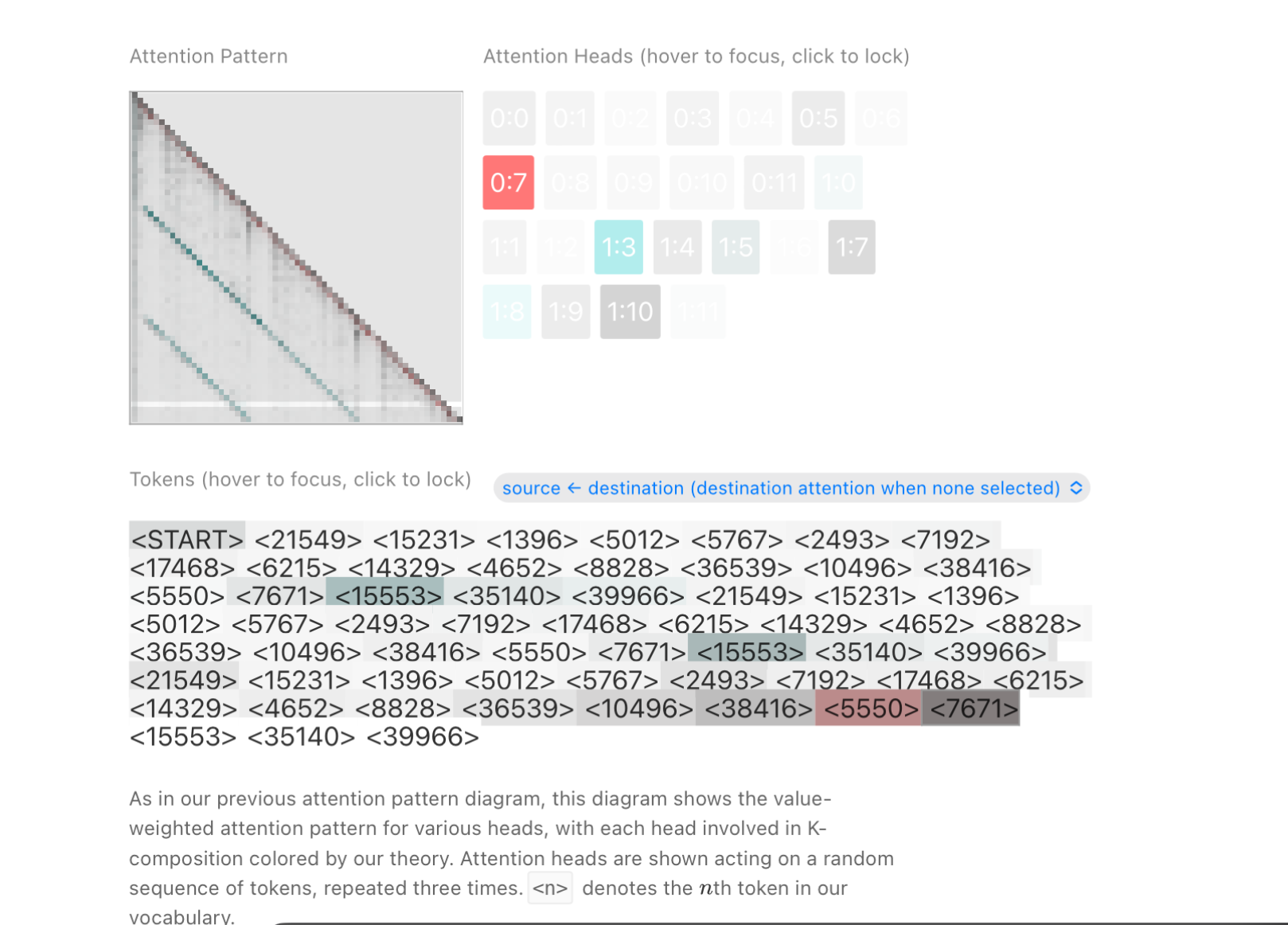
Since all the operations are in embedding space, this means it can also use similar tokens and still gain information about how the current token is used. It is not a hard and fast rule that you have to have seen the exact match of the token before in the context.
But how does it accomplish this?
How Induction Heads Work?
The trick to induction heads is that the key is computed from the token right behind the current. Then the query searches for “similar” key vectors, but since the keys are shifted, finds the next token.

The gray box is the current token we are on, you can see it looks back at where it was used before, the query is a combination of itself and some words around it, the key is a combination of what we are attending to and the words around it, and then the value is used to move this information together to predict the next word.
The rough algorithm is:
- Look at the current token you are on
- Look back to see where it was used before
- The query is a combination of the embedding itself and some words around it
- The key is a combination of what the query finds interesting, and the words around it
- The value then moves this information into the residual stream to make the prediction.
Term Importance Analysis
It is hard to observe any particular sub circuit and describe what it is doing purely with the equations we have defined above.
To test out some of the theories, they decided to run ablation studies on the activations to see what happens when you leave out certain operations or circuits.
The process was the following:
- Run the model and save all the attention patterns
- Run the model again with a zero tensor for the attention head you are interested in and see how it performs
- Run the model again but don’t add the attention head outputs to the residual stream and record the results.
First they found that individual attention heads in each layer are very important.

Then they break it down even further and see that the second layer attention heads have the most impact, so they focus on these.
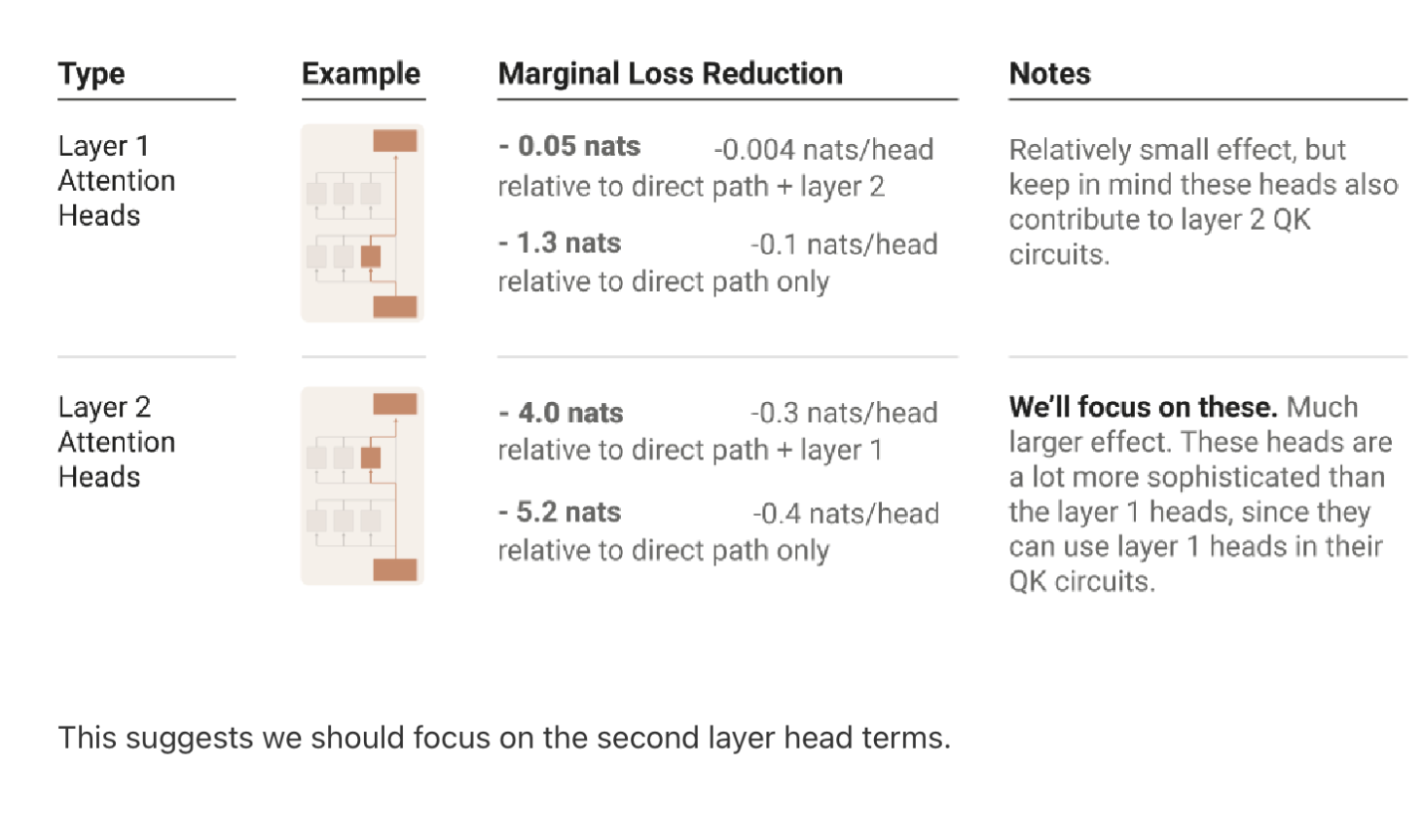
Ablating individual circuits is a cool way of looking at where to studying the transformer, and is much easier to do in these smaller models than large ones when training could take days or months.
Virtual Attention Heads
Remember, the model is constantly stacking these attention mechanisms on top of each other to update the meanings of the tokens and try to predict the next token.
Virtual attention heads are the combinations of all the heads below it, and you start to lose direct attribution because of the combinatorial nature of it all.
There are two things they note about the virtual heads in later layers.
- Composing these small attention patterns over and over and abstracting them higher and higher means that they can start to attend to more complex things farther away in the sentence. Such as: “Look at the subject of the sentence and attend to the subject of the previous clause”. Ex) Coreference resolution of pronouns through Subject-verb-object linking. "Harry flew to Hogwarts. He studied wizardry."
- There are a LOT of virtual attention heads. Especially as you add more and more layers. This means that there are a lot of different routes for passing different level of detail through the model. Maybe one head passes through how nouns interact with verbs. Maybe one passes through capitalization. One passes through pronouns and coreference resolution. It is hard to say what each one does, but it is clear that there are many of them, and we saw that they attend to different things with our small model.
Where Does This Leave Us?
We made some progress on 1 and 2 layer transformers, but then….things start to get a little hand wavy.
The main question Anthropic poses is "has this work brought us any closer to understand the transformer in its entirety?"
I believe the work gives clarity on how models can build up from bigram statistics, to skip-trigrams that link parts of the sentence, to higher level abstractions like subject-verb-object and coreference resolution.
Remember, this was research from December 2021, so almost two years old now. They have done future research to understand further, and even these small steps shed some light on what is happening under the hood.
Still a little mathematical magic if you ask me.
They do acknowledge that they stripped out the MLPs which make up 2/3rds of a standard transformers parameters, so there are behaviors we clearly left out with those.
The bottom 3rd of the paper is “Related Work” if you want to dive in more 🤿
If you enjoyed this dive, please join us next week!

All the past dives can be found on the blog.


The live sessions are posted on YouTube if you want to watch at your own leisure.


Best & Moo,
~ The herd at Oxen.ai
Who is Oxen.ai?
Oxen.ai is an open source project aimed at solving some of the challenges with iterating on and curating machine learning datasets. At its core Oxen is a lightning fast data version control tool optimized for large unstructured datasets. We are currently working on collaboration workflows to enable the high quality, curated public and private data repositories to advance the field of AI, while keeping all the data accessible and auditable.
If you would like to learn more, star us on GitHub or head to Oxen.ai and create an account.