ArXiv Dives: The Era of 1-bit LLMs, All Large Language Models are in 1.58 Bits
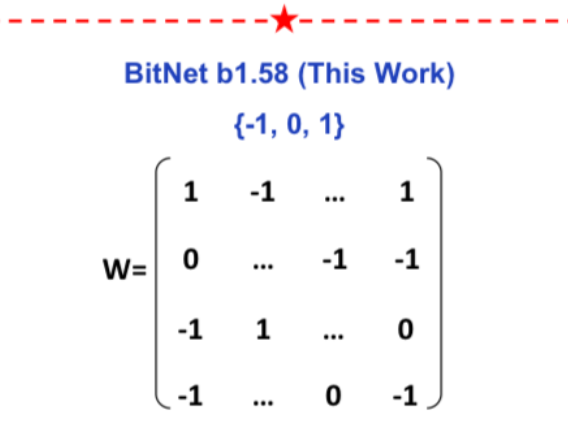

This paper presents BitNet b1.58 where every weight in a Transformer can be represented as a {-1, 0, 1} instead of a floating point number. The model matches full precision transformer performance with the same model size and training tokens in terms of perplexity.
Recently some code was released showing that these 1-Bit LLMs can be competitive with full floating point Transformers. We will be diving both into what a BitNet is and how it can be implemented in code.
Why 1.58?
Before the BitNet 1.58 paper, there was a paper on representing weights as simply {-1, 1}
It is a good paper to get some background knowledge on BitNets because the BitNet 1.58 paper is rather short.
Instead of a binary representation, BitNet 1.58 uses a ternary representation of {-1, 0, 1} which gives the model a little more flexibility in what it can represent. From an information theoretical perspective, if you have 3 values you are representing, you can take log2(x) to figure out how many bits are needed to represent those values. Hence log2(3) = 1.58.
Why should I care?
The reason this is a big deal is it has significant implications for latency, memory, throughput and energy consumption.
Neural network architectures such as Transformers and LLMs are built on top of massive matrix multiplications. These operations are expensive and require specialized hardware like GPUs to run in prod. In theory if we could get models to run on a binary or ternary representation, we could run them much faster for much cheaper.
Who wouldn't like a faster LLM that they could run locally?
What makes it so fast?
Traditional LLMs (or Neural Networks broadly) store all of their weights in floating point numbers, usually represented by 16-bit numbers.
What if we could cut this down to only use 1s, 0s, and -1s?
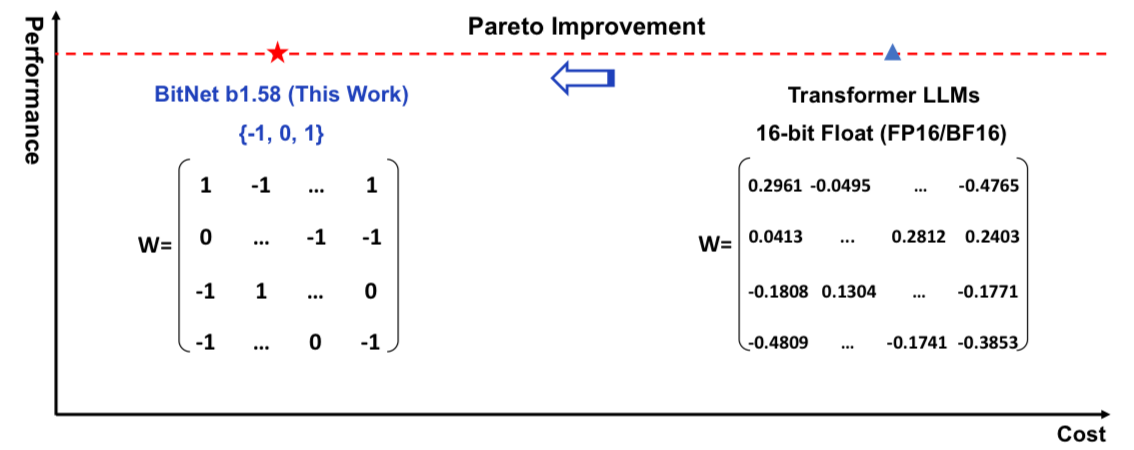
This means the main operation in forward passes can be much more efficient.
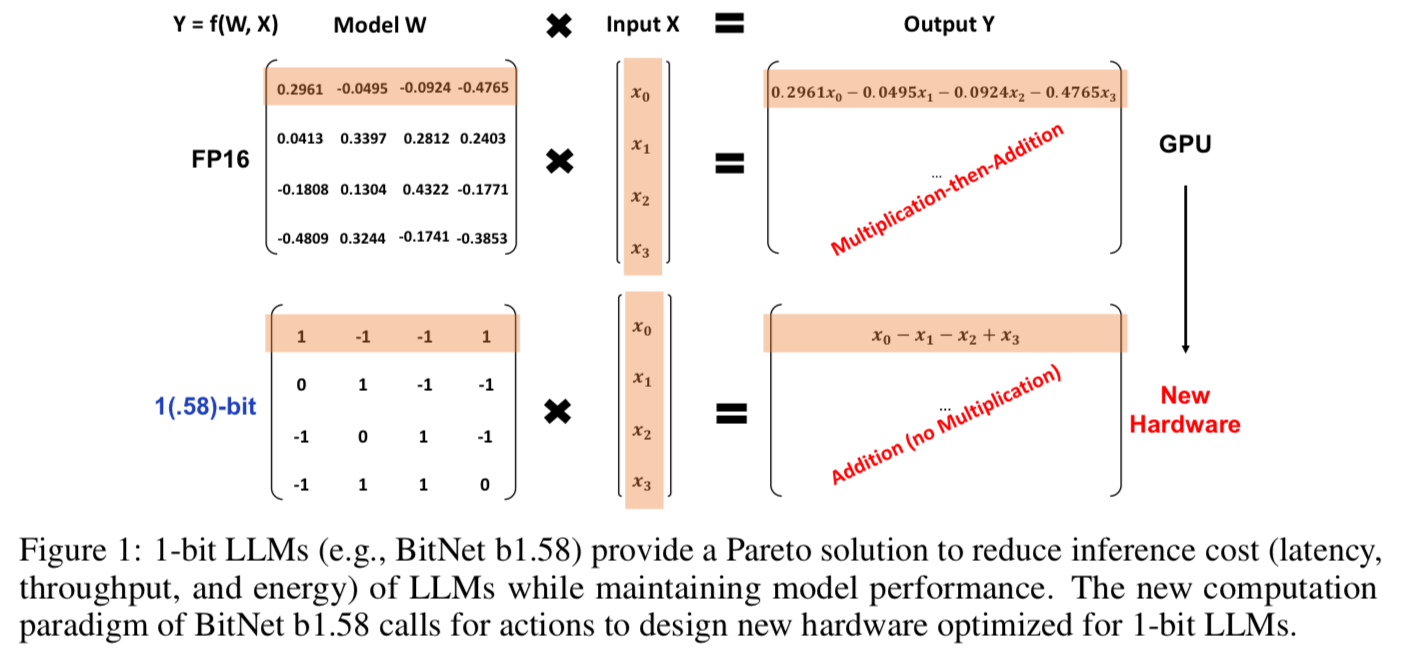
Instead of doing multiplication then division on FP16, you can simply do addition. Multiplying by 1 is just the identity. Multiplying by 0 is always zero. Multiplying by -1 just flips the sign. Then you are just down to addition.
Quantization without BitNet
BitNet is not the only way to speed up inference. There are different levels of quantization that can be applied to the weights to reduce their memory footprint. The problem with quantization after the fact is that you start to lose the precision that may be needed for accuracy.
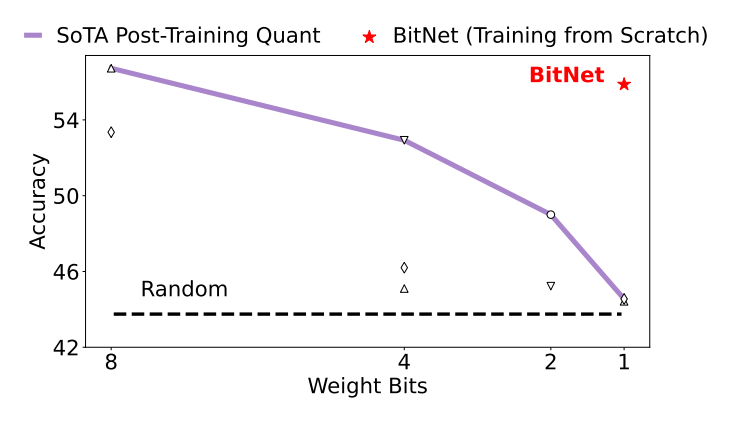
In the BitNet paper they show how quantization down to 1 bit decreases accuracy significantly.
The hope is that if you can have the model learn these ternary representations on it’s own, the accuracy will stay competitive while improving throughput of the model.
BitNet Architecture
BitNet sits on top of a Transformer architecture for LLMs. We won’t cover transformers here, but we covered them in detail in the past. My personal favorite was a Mathematical Framework for Transformer Circuits.
Most of the computation is in the feed-forward network layers that sits on top of the attention heads. The larger the model, typically the larger these layers are.
All you need to do for a BitNet is replace you standard nn.Linear ops in PyTorch with a custom BitLinear layer and voila! You have a BitNet.
BitLinear Layer
The quantization functions for a BitNet or BitNet 1.58 layer are pretty simple.

In the case of the binary encoding, you simply check if the weight is greater than zero or less than zero and binarize it.
In the case of the ternary encoding, you simply need to round the value to the nearest integer of -1, 0, 1.
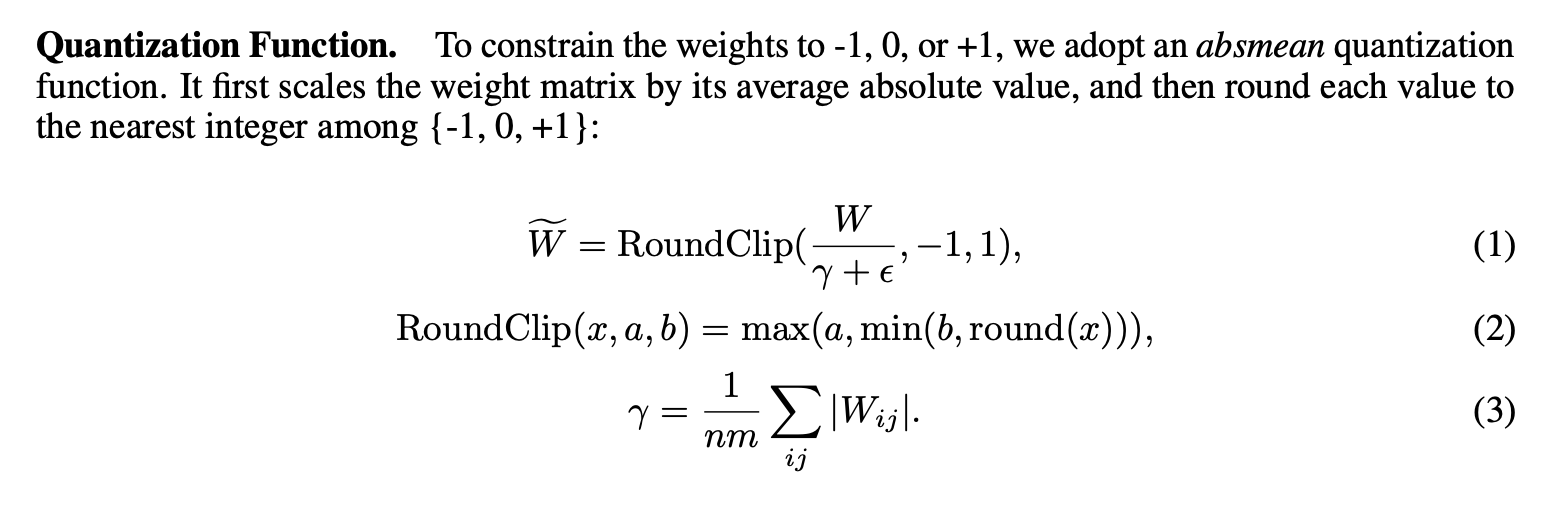
What about backprop?
Trick: keep the high precision floating point weights / gradients during training on the side.

This means that training still requires all the floating point numbers in memory so that we can have continuous values to run backprop against, but we can drop them during inference time.
What are the gainz?
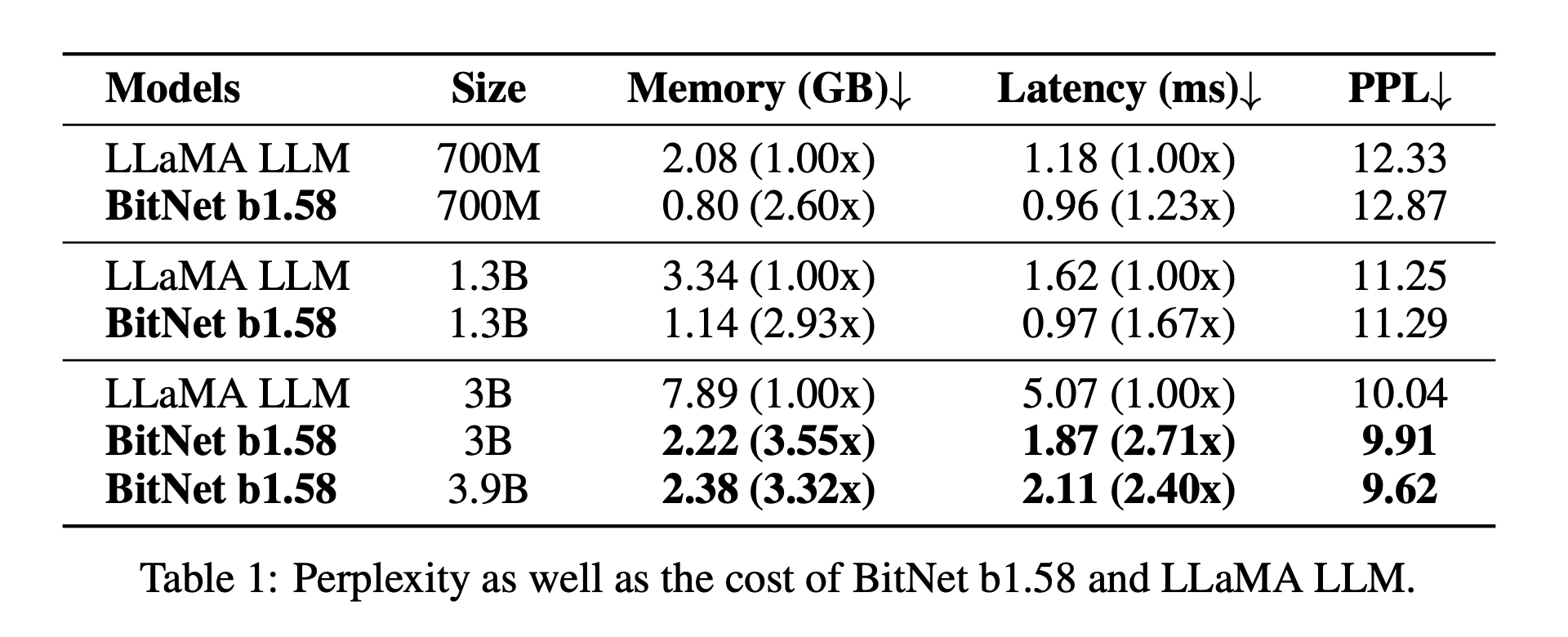
Bessie the BitNet 🐂
We have some internal use cases at Oxen.ai for a speedy LLM that could potentially run on CPU after this quantization trick, so we kicked off a fine-tune. We started with the 1bitLLM/bitnet_b1_58-large model which has 700m parameters.
All the code for training and eval can be found here:
 Oxen-AI
Oxen-AITesting the Base Model
First to make sure the base model worked at all, we tried a 5 shot prompt for the SQuAD question answering task.
You can see all the results here:
We get about 17% accuracy on SQuAD with a 5 shot prompt. Not great. But also not garbage. It's encouraging if a base model has some useful knowledge encoded, even if it hallucinates and answers questions incorrectly some amount of the time.
There is also a script included to kick the tires on the model if you'd like.
python scripts/prompt.py -m 1bitLLM/bitnet_b1_58-largeFine-Tuning for Instruction Following
For fine tuning, we started with a mix of SQuAD_v2 style questions and instruction following data.
The full dataset can be found on Oxen.ai here:
In order to kick off a train on this data you can simply download the data with the oxen cli
oxen download ox/BitNet train.jsonland kick off the train with this script
python scripts/train.py -m 1bitLLM/bitnet_b1_58-large -d train.jsonl -o outputKicked off a train on Tuesday night. Took about ~8hrs to go through 1 epoch of 100k instruct-tuning examples. Batch size of 1 because I have a relatively smol GPU (A10, 24GB VRAM).
The full train bumps the accuracy up to 55% for the same dev questions! We can peek under the hood a little at how the models performed compared to each other.
https://www.oxen.ai/ox/BitNet/compare/3
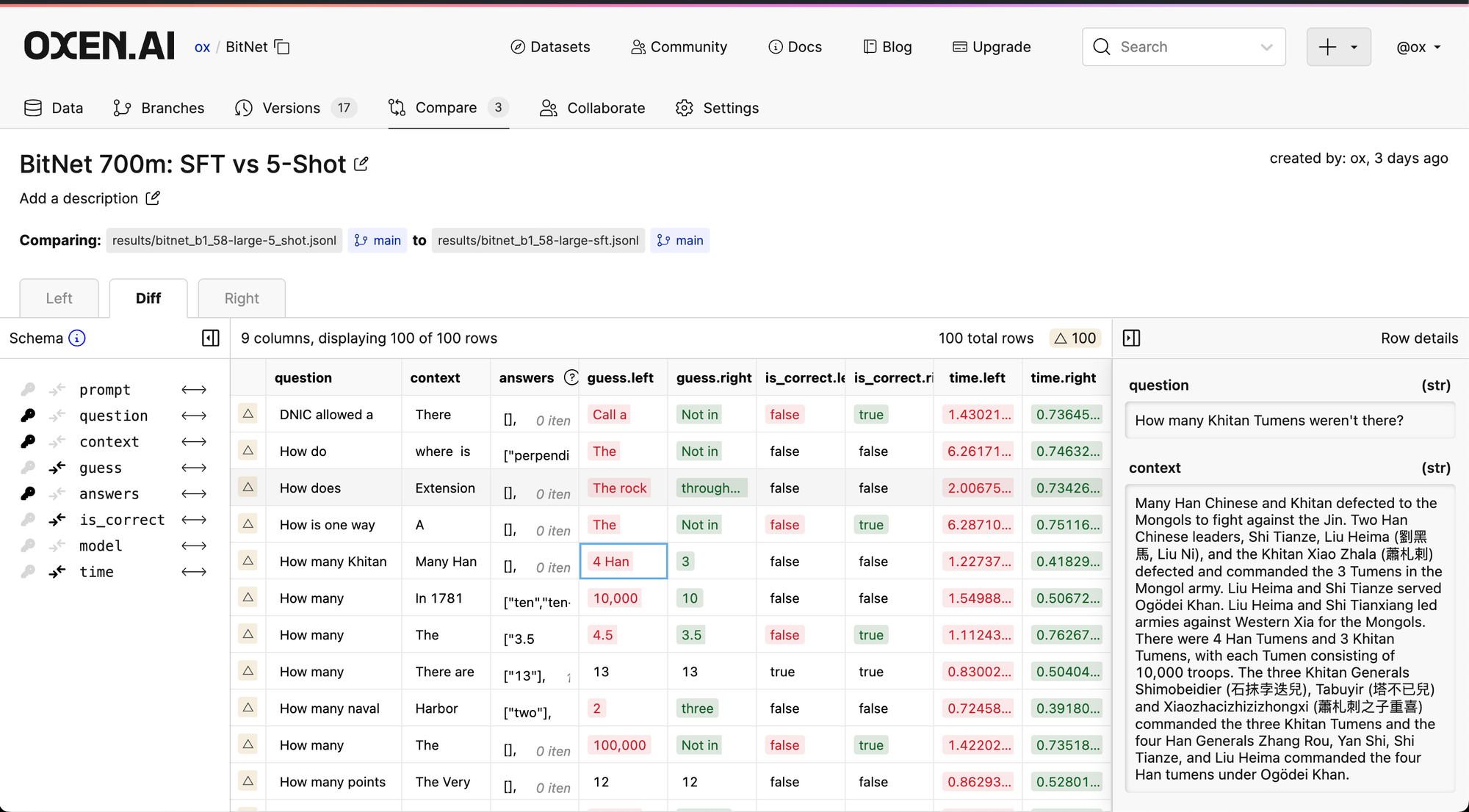
Clicking through the comparison, you can see which questions the 5 shot prompt got incorrect that the fine tune model fixed.
🤿 The Code
I personally learn the best when I look at play with the actual code then mapping them to the equations in the paper.
Diving into the Quantization
The most important thing here is that we get the ternary representation out to speed up the matrix multiplications. In theory then we could run a process similar to the GGML project to get this 700m model running.
This was a fun one to track down the code. Microsoft Research initially released their implementation as a PDF.
microsoftHere’s the function for quantizing the weights into a ternary representation from the PDF:

Nous Research also has an impl I used to sanity check:

Inspecting the inputs and outputs
Using everyone’s favorite debug tool….printf I found it odd that the value returned from weight_quant was not actually {-1, 0, 1}.
python scripts/bit_linear.pyThe first time I ran it, with a print statement after the quantization of the weights, I was a bit confused.

The numbers that came out of w_quant were floating point values, and definitely not {-1, 0, 1}.
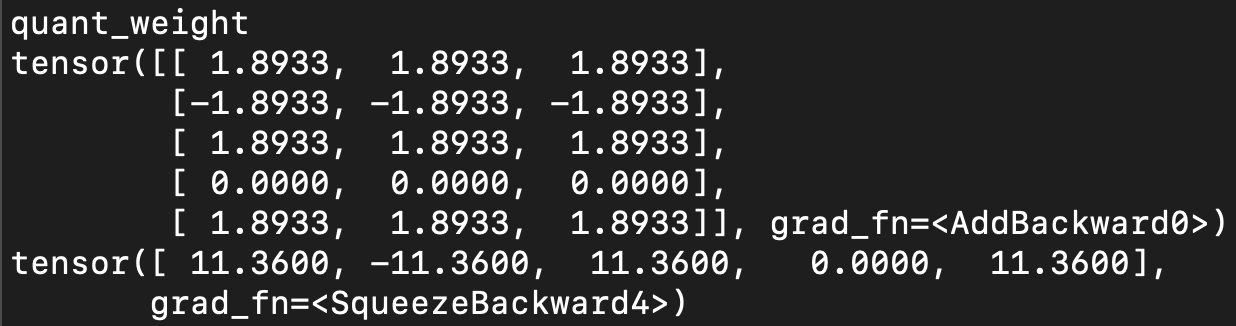
This is odd because the whole point of this paper is to optimize the nn.linear layer operation to take advantage of the quantized values.
Looking a little deeper, you'll notice that the code divides by scale.

This is causing the outputs to still be in floating point space.
If we are every going to optimize this code to take advantage of the mat mul optimization we need to refactor the scaling out of this function and apply it after the linear layer.

This is mathematically equivalent but now we have the added benefit that the nn.functional.linear layer takes in the quantized weights. In theory this means we could re-write and optimized version of this function to take advantage of the ternary representation.

If you rerun the prompting code after these tweaks you should get the same output 😄 and hopefully understand what is going on under the hood of the BitNet and BitLinearLayer better.
Good News and Bad News
The good news is that the model trains, and seems to learn the task at hand fairly well! This is promising and we are excited to apply it to more tasks.
The bad news is all of the inference code is still run with floating point operations and your traditional linear layer running mat mul. It will take some additional engineering to run inference optimized for 1.58bit and really take advantage of the quantization.
What’s Next?
Wait for GGML to support BitLinear layers? Implement our own? Hit us up if you are working on this problem / want to contribute.
Main Takeaways
- Read the code. Learn.
- This was not that much code
- This was not that much compute
- Let’s hack on the shoulders of giants (foundation models, ml libraries)
Hopefully you enjoyed and learned something new today 🤓