Arxiv Dives - How Mixture of Experts works with Mixtral 8x7B


Mixtral 8x7B is an open source mixture of experts large language model released by the team at Mistral.ai that outperforms Llama-2 70B and GPT-3.5 on a variety natural language understanding tasks.
The magic of the model is that it only uses 13B parameters during inference, which makes it fast, but has access to a total of 47B parameters at its finger tips for higher accuracy. The model is open source for the community to experiment with.
Paper: https://arxiv.org/abs/2401.04088
Team: Mistral.ai
Paper Date: January 8th, 2024
Arxiv Dives
Every Friday at Oxen.ai we host a paper club called "Arxiv Dives" to make us smarter Oxen 🐂 🧠. We believe diving into the details of research papers is the best way to build fundamental knowledge, spot patterns and keep up with the bleeding edge.
If you would like to join live to ask questions or join the discussion we would love to have you! Sign up below 👇

The following are the notes from the live session. Feel free to watch the video and follow along for the full context.
MOE Before Mixtral
Mixture of Experts (MOE) is by no means not a new concept. The application of MOE to the Transformer architecture what is getting attention right now. If you want to learn a bit of the recent history of Mixture of Experts applied to Transformers the following papers are helpful.
- GShard - https://arxiv.org/abs/2006.16668
- Switch Transformers - https://arxiv.org/abs/2101.03961
- A Review of Sparse Experts Models in Deep Learning - https://arxiv.org/abs/2209.01667
Mixtral takes this research above and applies it to their 7B parameter language model and extends its parameters to a sparse 47B parameter Sparse Mixture of Experts (SMoE).
What is MOE?
The mechanism of MOE is quite simple and is applied inside the transformer block of the LLM. A standard transformer block contains the self attention mechanism, as well as a feed forward layer.
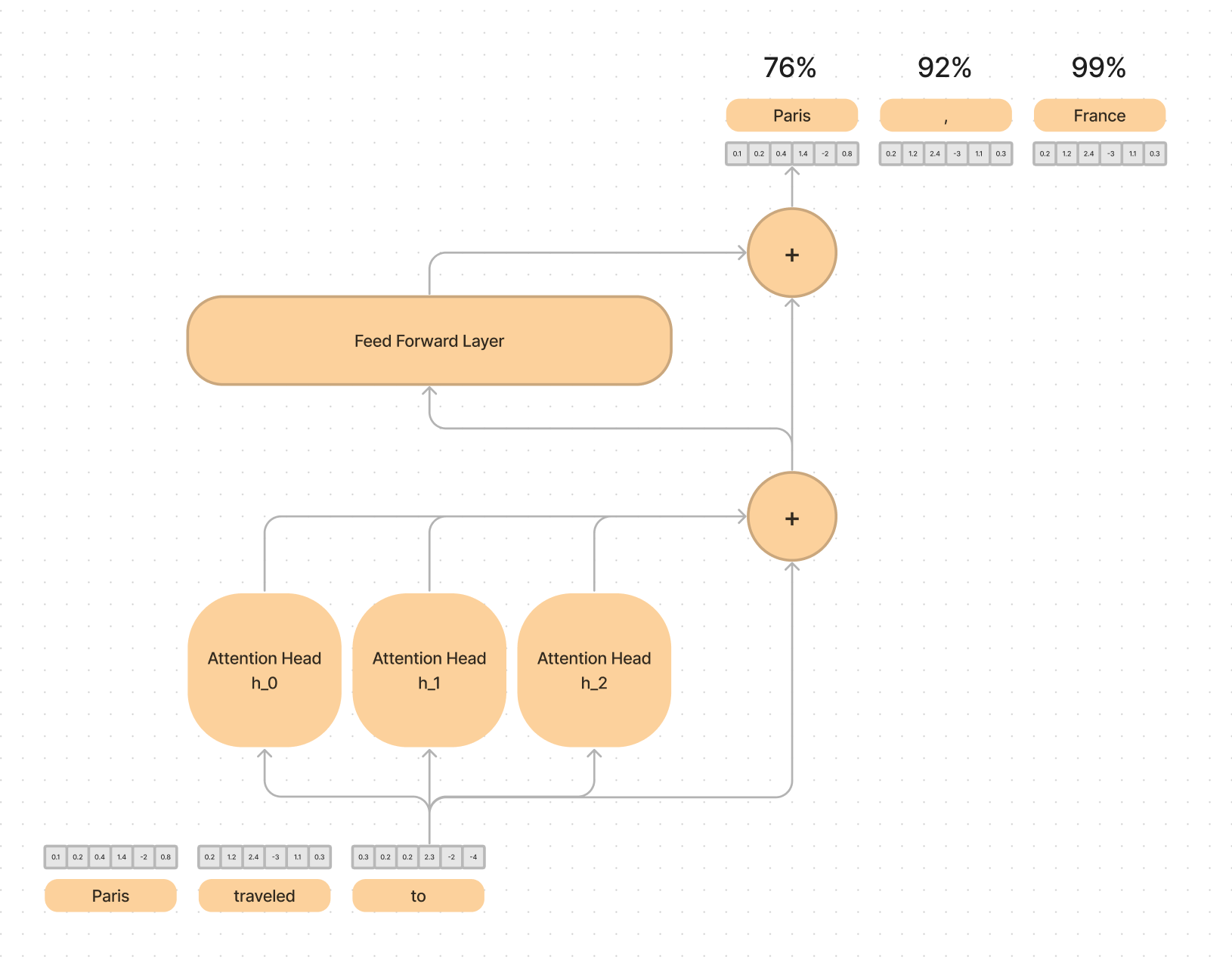
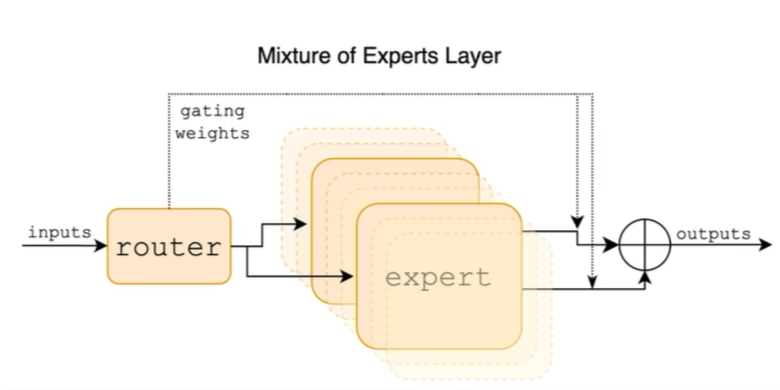
Within this transformer block, Mixtral 8x7B simply replaces the single feed forward layer with a set of N feed forward layers and adds a router in front of them.
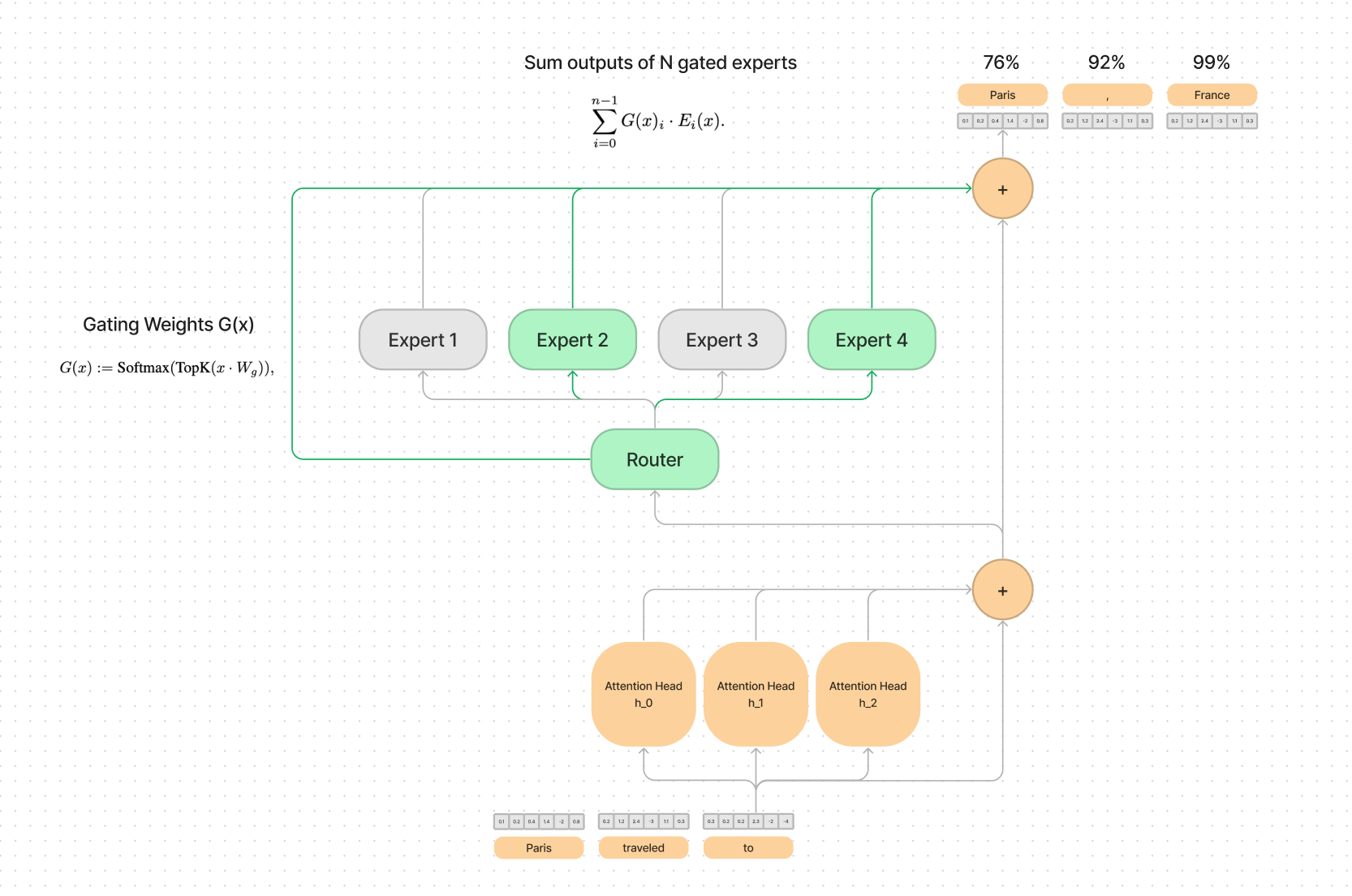
The number of experts is a configurable parameter that is fixed before training. In the case of Mixtral 8x7B they have 8 feed forward layers that can be routed to after the attention heads.
The router then choses 2 of the experts based on the current context to help predict the next word.
Motivation
The intuition for why we would want a mixture of experts is that this allows for certain experts to specialize in different domains. For example - one expert could focus on math. Another could be great at biology. The third could focus on philosophy.

How do the experts work?
There are a few things you have to wrap your head around when thinking of MOE in the context of Language Modeling and Transformers.
- The experts help predict one token at a time
- The router decides which expert is active at each token
- Experts are combined through a gated linear combination to predict the next token
Token By Token
Since the experts are within a transformer block, the routing happens on a token by token basis. As token X comes in, the transformer block’s job is to predict the next token Y. The transformer block has access to all of the previous context through the self attention mechanism. The output of the self attention mechanism then says to the router:
Looks like are talking about physics, which one of you is going to help me predict the next token?
The router has learned which experts help the most with physics problems, and decides to delegate the information to the top K experts.
How does the routing work?
If you are familiar with standard classification tasks in machine learning, this part will look very familiar. The routing is simply a softmax layer sitting between the attention heads and the set of K experts. This layer learns which expert is best for which type of tokens.
Here’s a visualization of the routing from the Review of Sparse Expert Models paper
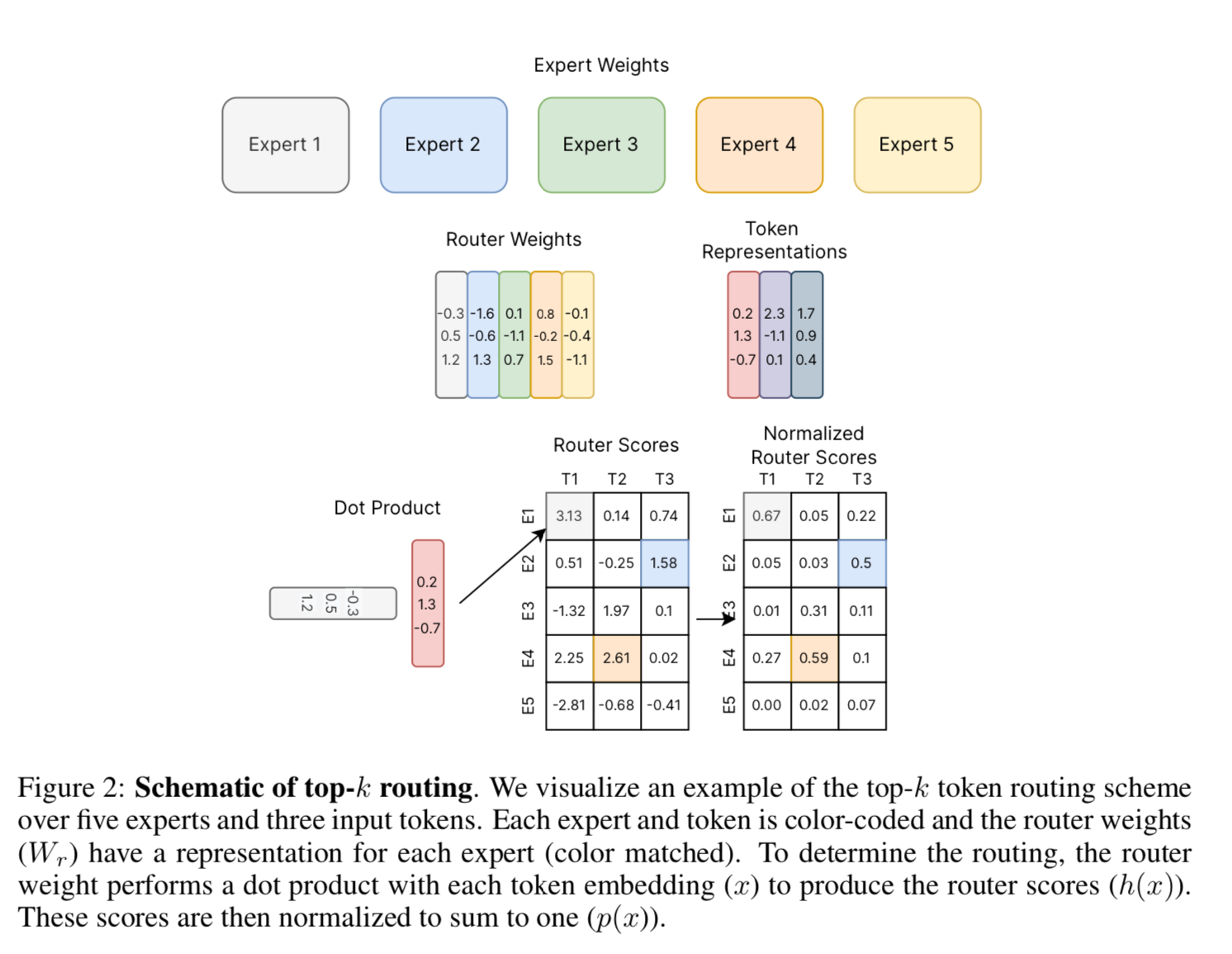
To make it even more efficient, Mixtral 8x7B only takes the top 2 experts based on the logits of the router to feed through to predict the next token.
You may hear people refer to the “sparse parameter count” vs the “active parameter count”. The sparse count is the full count + all the experts, whereas the active count is only the parameter count of the model with the subset of K experts.
How are the experts combined?
The outputs of the experts are then computed by a weighted linear combination of each expert given the token multiplied by the softmax gated value.
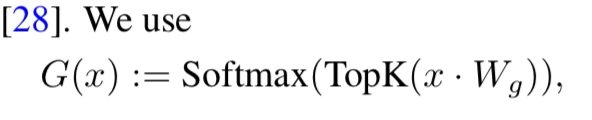
Again, K is a hyper parameter you can choose from. It would be interesting to see what the performance in Mixtral would be with K=1 vs K=4 and not just K=2.
That’s it. MOE only runs a subset of the experts per token so although you may have 47B parameters loaded into VRAM for efficiency we only perform floating point operations on 13B of them.
Latency vs Throughput vs Memory consumption
Although the model has less parameters to run at inference time, that does not mean it is easy to scale up on any type of hardware. You still need all the weights loaded into GPU memory if you want the GPU to go brrr. It is also more difficult to batch inputs on this type of architecture since you are not guaranteed that the experts are going to be routed to equally.
If you’re interested in these optimizations, I’d recommend reading “A Review of Sparse Expert Models in Deep Learning”. In this paper Jeff Dean and his colleagues talk about efficient ways to implement MOEs as well as the history in general.
So while Mixtral 8x7B is smaller than Llama-2 70B, it still takes 47GB of memory and integrated engineering to run. While you could page the experts in and out of memory, the time to copy between devices would slow the whole system down.
What is exciting is we are already seeing people apply MOE to even smaller models like Microsoft’s Phi 2.7B model.

I think this area of research is promising for getting powerful local models, but there is still plenty of engineering and experimentation to be done to get them to work well.
Routing Analysis
How do we know if each expert network is learning something different or specializing?
In order to evaluate this, they look at how often individual experts are selected for different subsets of The Pile validation set.
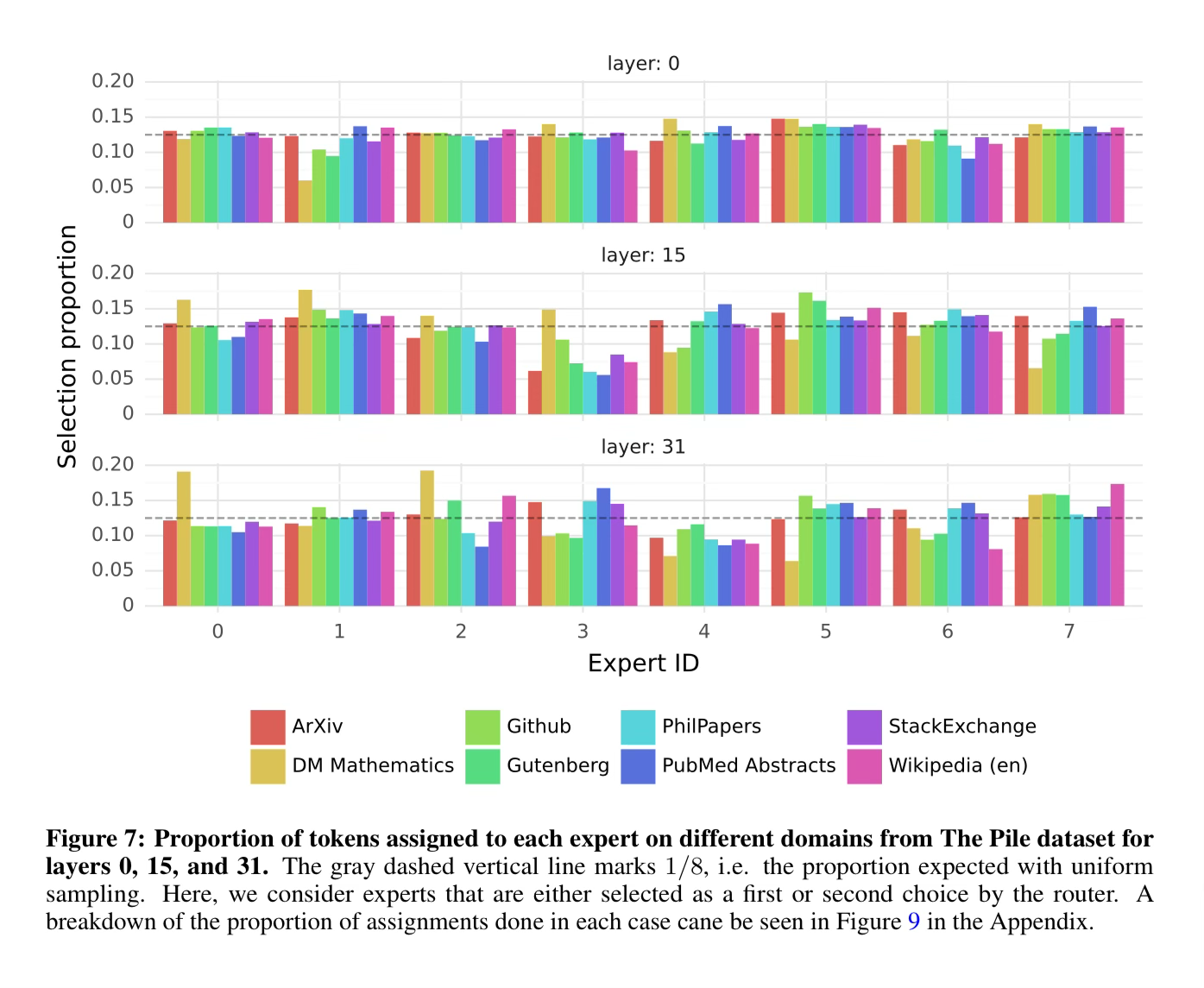
Surprisingly, they do not observe any obvious patterns of experts per topic. The text talking about Biology vs Philosophy vs Machine Learning all seemingly route to all experts.
The only topic that seems to have a strong difference in distribution is DM Mathematics. They state this may be because the dataset was synthetically generated and doesn’t cover that wide of a range of natural language.
This suggests that the router does exhibit preference to certain experts for structured syntactic behavior. You can really see this as they highlight the experts that are active in very syntactic tasks like writing code.

For example in the far right image, it seems like the yellow expert is quite good at white space and the dark red may be the best at punctuation and opening and closing parentheses.
It is still relatively a black box as to how the experts work, but interesting nonetheless.
Instruction Fine Tuning
The chat version of the model was fine-tuned to follow instructions using
supervised fine-tuning and Direct Preference Optimization on a paired feedback dataset.
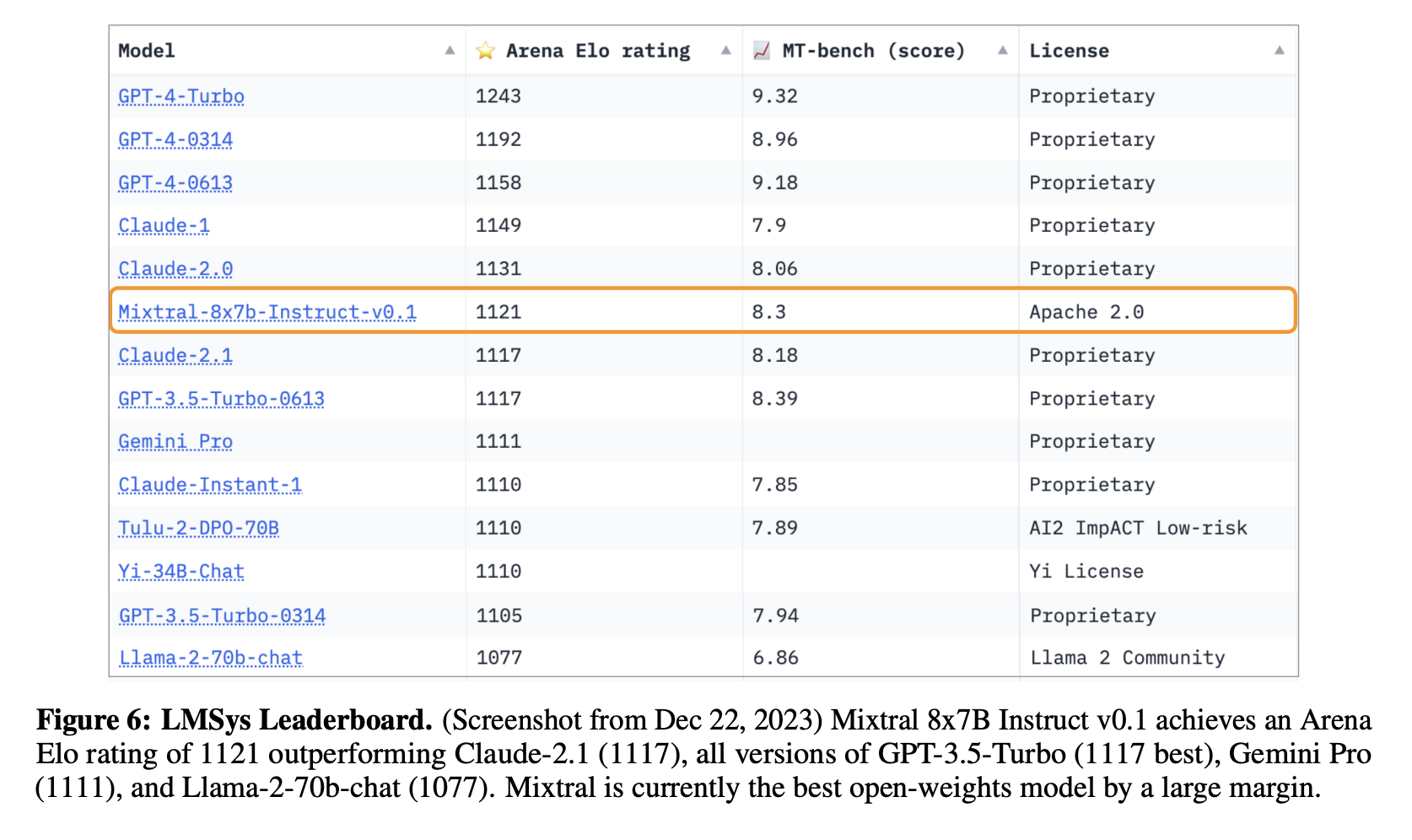
They do not share what dataset they used, but they do report human evaluation results conducted by LMSys. The evaluation shows a higher ELO rating than GPT 3.5 Turbo and Claude-2.1. Starting to approach GPT-4. So far it is the highest ranked open source Apache 2.0 model on the leaderboard.
Performance on QA Benchmarks
They evaluate Mixtral 8x7B on all the traditional QA benchmarks. If you want to look at benchmarks in more detail, check them out on Oxen.ai
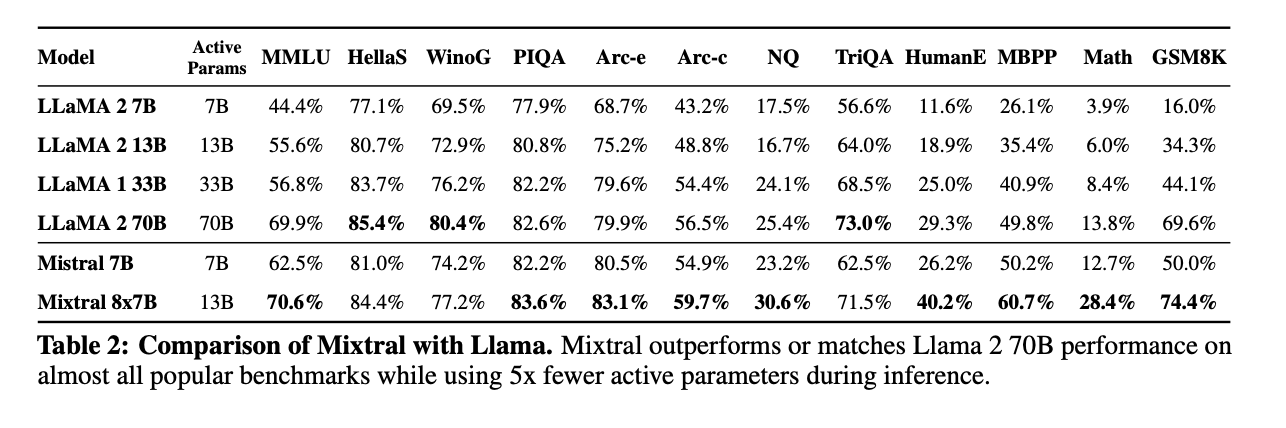
I personally don’t love just staring at number blocks in these papers, and love to look at actual examples.
Running Mixtral in the Wild
If you’ve been following the Practical ML Dives with Oxen.ai, we have been playing around with RAG on the SQuAD Question Answering task hidden in a dataset of 1 million documents. We decided to throw Mixtral into the mix for the generation half of the problem 👨🍳.
 Oxen-AI
Oxen-AIOur full results sets can be found here:
Mixtral 8x7B: https://www.oxen.ai/ox/SQuAD-Context/file/main/experiments/dev-mixtral-8x7B-recall-1-precision-0-shot-1m-docs.jsonl
~ TLDR ~ Llama 70B slightly outperforms on the task in terms of precision, but it is close.

I am a big fan of trying these models yourself on a task you are interested in, and not just taking the papers word for it. It is relatively easy to try out a lot of these open source models these days thanks to Together.ai and their API that mirrors the OpenAI interface.


def run_together_ai(model, question, context, n_shot=0):
import openai
import os
client = openai.OpenAI(
api_key=os.environ.get("TOGETHER_API_KEY"),
base_url='https://api.together.xyz',
)
prompt = construct_prompt(question, context, n=n_shot)
messages = [
{"role": "user", "content": prompt}
]
chat_completion = client.chat.completions.create(
messages=messages,
model=model, # "mistralai/Mixtral-8x7B-Instruct-v0.1",
max_tokens=1024
)
answer = chat_completion.choices[0].message.content
return answerFeel free to try it on your own data!
Conclusion
MOE is a relatively simple technique that can be applied to any neural network architecture. They add additional feed forward layers within the transformer block that are selected and run at inference time with a router. The router classifies which feed forward network would be best to handle the current context.
This technique can help scale up the number of parameters in a model with minimally impacting the runtime. There is always the tradeoff of latency vs throughput vs memory consumption when optimizing a model for your use case. It will be exciting to see the developments in the coming months as the open source community applies MOE to a variety of models and architectures.
Another fun one that came out this week is MoE-Mamba (not to be confused with Mo Bamba 🪇)
Next Up
To find out what paper we are covering next and join the discussion at large, checkout our Discord 👇

If you enjoyed this dive, please join us next week!
All the past dives can be found on the blog.


The live sessions are posted on YouTube if you want to watch at your own leisure.


Best & Moo,
~ The herd at Oxen.ai
Who is Oxen.ai?
Oxen.ai is an open source project aimed at solving some of the challenges with iterating on and curating machine learning datasets. At its core Oxen is a lightning fast data version control tool optimized for large unstructured datasets. We are currently working on collaboration workflows to enable the high quality, curated public and private data repositories to advance the field of AI, while keeping all the data accessible and auditable.
If you would like to learn more, star us on GitHub or head to Oxen.ai and create an account.
Oxen-AI