Arxiv Dives - How Segment Anything Works


Every Friday at Oxen.ai we host a public paper club called "Arxiv Dives" to make us smarter Oxen 🐂 🧠. These are the notes from the group session for reference. If you would like to join us live, sign up here.
The following are the notes from the live session. Feel free to follow along with the video for the full context.
Arxiv: https://arxiv.org/abs/2304.02643
Published: April 2023
Demo
Source: https://github.com/YavorGIvanov/sam.cpp
Background Knowledge
Segmentation is an important task in computer vision and can be applied for many different use cases.
You can think of it as using the lasso/brush/eraser tools in photoshop, zooming in really close, and selecting each individual pixel around the object of interest.

Segmentation Use Cases
Meetings
Blurring the background
Self Driving Cars
Knowing where the road vs sidewalk other cars vs trees are in each frame of a video.

Image Editing
Software like photoshop or RunwayML can automatically segment out parts of an image (or now-a-days re-generate a portion of an image)
Sports / Live TV
Segmenting the players or actors in real time allows you to place digital objects on the field (first down line in football, clock in basketball)

Augmented Reality
Allows you to place digital objects in the physical world with occlusion. Might be a big driving for for Meta putting in the effort here.


Inventory Management
Identify all products on shelves.

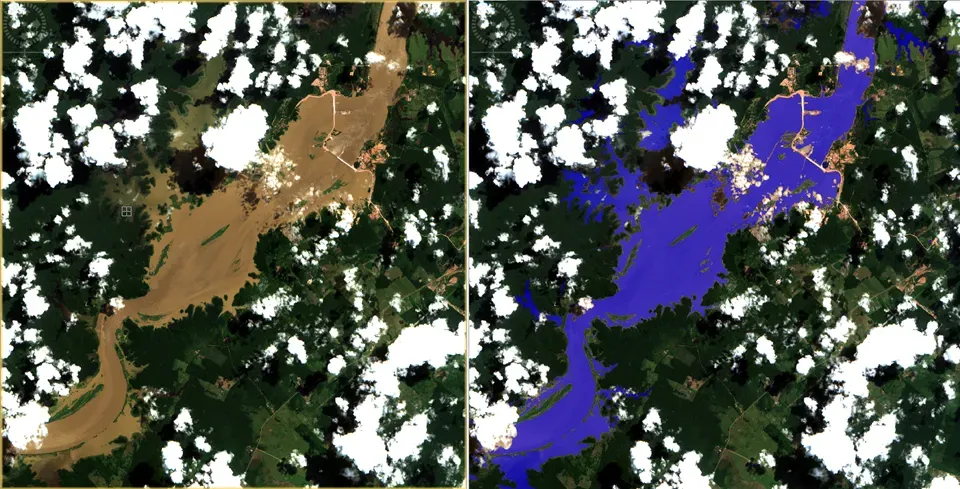
Satellite Imagery
Understand flooding, wildfires, land vs water, weather patterns.
Introduction
Meta introduces a model called “Segment Anything” (SA) along with a dataset of 1 billion mask on 11 million licensed and privacy respecting images.
The model is meant to be "promptable" so that it makes it easy to interact with for a user. Prompt in this setting can be confusing if you are coming from the LLM perspective. They use clicks and bounding boxes as prompts to generate masks. You could also train a system to take a text prompt as well.
Computer vision has foundation models such as CLIP and ALIGN that were used to train models such as DALLE and Stable Diffusion to align text and images. These models were trained off of image->text pairs (extracted from alt text in images on the web) but beyond that, for other tasks, abundant training data does not exist.
Three Key Components
- Task - promptable segmentation
- Model - architecture that supports prompting and outputs masks in realtime for interactive use
- Data - build a web scale dataset and “data engine” to collect more data.

The “prompt” in this case may just be clicking a point on an image, and may be ambiguous. For example - clicking a point on a shirt, do you want to segment out the shirt? Or the full person wearing the shirt? They handle this by allowing the model to predict multiple masks and let the user choose.
The “prompt” could also be free-form text, or a bounding box around the thing to segment.
The Model
- an image encoder (to convert the image to an embedding)
- A prompt encoder (prompt embedding)
- A mask decoder that takes 1 & 2 as inputs and generates a segmentation mask.
Separating the image encoder from the prompt encoder and the mask decoder means we can compute an embedding one time (and have this step be more expensive) then reuse it for different prompts with the decoder.
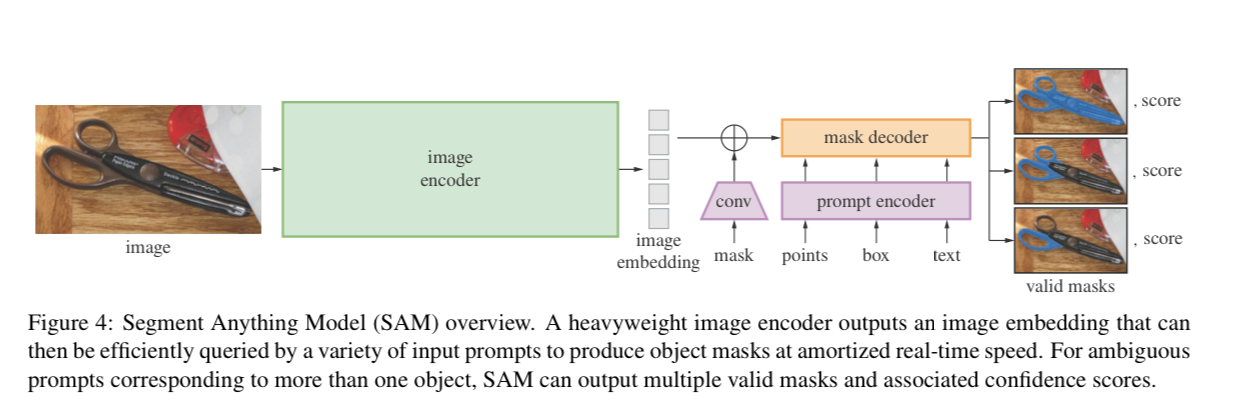
If you think of a user’s workflow, if decoding a mask from a prompt is about ~50ms then it feels real time to try and change different masks.
Data Engine
The dataset was collected from what they call their “data engine”. This consists of three stages
- Assisted manual - SAM assists annotators in creating the masks. Think of this like photoshop suggesting how to use the Lasso tool, then a human fixing it
- Semi automatic - prompt the model with likely object locations (from a known subset) and annotators help annotate the rest
- Fully automatic - prompt SAM with a regular grid of foreground points, yielding ~100 masks per image
Below you can see different examples of images with increasing number of masks.

The Segment Anything Task
Input: prompt (point, box, text)
Output: mask (which pixels does that object consist of)
Original Dataset
Image -> bounding box, mask, label
Generated Dataset
Image, point_1 -> mask
Image, point_2 -> mask
Image, point_3 -> mask
….
Image, bounding box -> mask
Image, text_1 -> mask
Image, text_2 -> mask
Segment Anything Model
They go over more details in the appendix of the paper on each one of these components.
The image encoder is a masked auto encoder (MAE) from a 2022 paper pre-trained vision transformer (ViT).
The prompt encoder represents the points and boxes by positional encodings, and the text prompts with the off the shelf CLIP model (which has also been used in many image generation tasks such as stable diffusion)
The mask decoder takes in the image and prompt embeddings, and runs it through a Transformer decoder block, and a mask prediction network.
Resolving ambiguity - since each point could be ambiguous, they setup the network to always output 3 masks (which they find is a rule of thumb that covers most cases) then the model predicts a confidence score for each mask it produces.
Training - The objective/loss functions they use are called focal loss and dice loss, and they simulate an interactive setup by randomly sampling 11 rounds per mask.
Segment Anything Data Engine
I really want you to appreciate how much effort went into each one of these stages, to collect this much data. A lot of human + computer assisted back and forth.
At the end of the process, we now have this super powerful model, that many people can leverage, and a massive dataset that many people can leverage.
Assisted Manual Stage
They have a team of professional annotators click foreground and background points in a browser based tool. These foreground and background points give an initial model some hints to what the mask should be. The annotators then use “brush” and “eraser” tools to improve the mask.
The annotators were given no restriction for the object classes, for example could freely label an object as “stuff” or “things”.
They were asked to label objects in order of prominence, and the tool prompted them to move on if it was taking over 30 seconds to annotate a single image.
SAM was initially trained on public segmentation datasets, and was incrementally retrained as more data was collected.
They don’t say how big the original dataset was, what it consisted of, or how often they retrained…but at the end of this stage they collected 4.3 million masks from 120k images.
They do go into a little more detail in the Dataset card in the appendix.
This leads me to believe it was some superset of MSCOCO or other public datasets, which has 123k images with 80 classes of objects labeled, and about ~1 million masks. But they are labeling everything in the image and 4x the number of labels if true. They don’t say the specifics…I am just painting between the lines and making assumptions.
Screenshots from https://oxen.ai
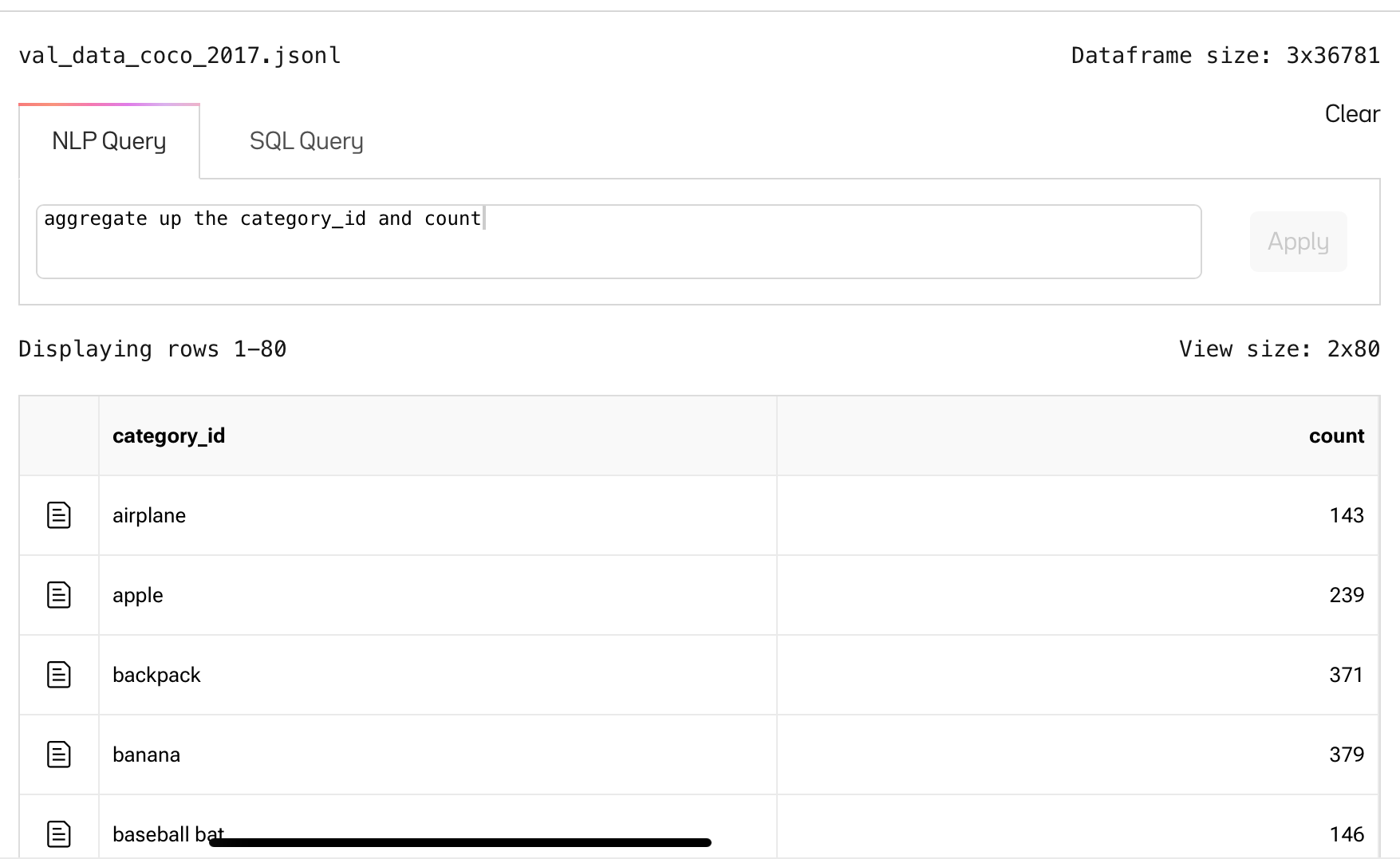
Semi-Automatic Stage
This stage aims to increase the diversity of masks, so that the model can segment “anything” not just the 80 classes above.
They loop the annotators back in, after automatically detecting confident masks, and ask them to annotate any additional unannotated objects. They use a generic bounding box detector trained on the first round of data just to detect any object.
During this stage, they collect an additional 5.9 million masks on 180k images. For a total of 10.2 million masks.
Again they periodically retrain the model 5 times during the collection stage. The average number of masks per image went from 44 to 72 in this stage.
Fully Automatic Stage
The final stage is fully automatic annotation.
They prompt the model with a 32x32 regular grid of points, and for each point they predict a set of masks that correspond to valid objects.
They then calculate how confident the model is, and what the overlap is in the masks they predicted. They then filter out what they call “stable” masks, or ones that have a high probability.
This process is applied to 11million images, producing 1.1 billion high quality masks.
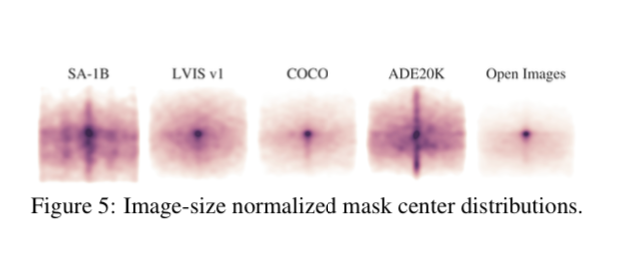
This is kind of cool, they look at if you average the mask centers over different datasets, where most of the masks lie. You can see the segment anything dataset (and the ADE20k dataset) are by far the most diverse. Others could easily overfit to just predicting masks in the center of the image.
Segment Anything Dataset
They note that the 11M images are diverse, high resolution, licensed, and privacy protected.
Things like faces and license plates are blurred out of the dataset they release.
They release the dataset to aid in future development of foundation models for computer vision.
The images are 3300x4950 pixels on average, which makes the dataset quite large. Therefore they downsampled the images to 1500 pixels on their shortest side. (Coco images are ~480x640 on average)
99% of the 1.1 billion masks were generated in the last step, automatically.
To estimate mask quality, they randomly sampled 500 images (~50k masks) and ask the professional annotators to validate the quality by annotating them. They then computed the overlap between the annotators and the model to see how well the model did.
Here are some interesting graphs on data distributions vs other datasets while performing a “Responsible AI analysis”
They try to represent a fair geographic and income representation of the sourced images, but note that in general Africa is underrepresented as well as other low income countries.
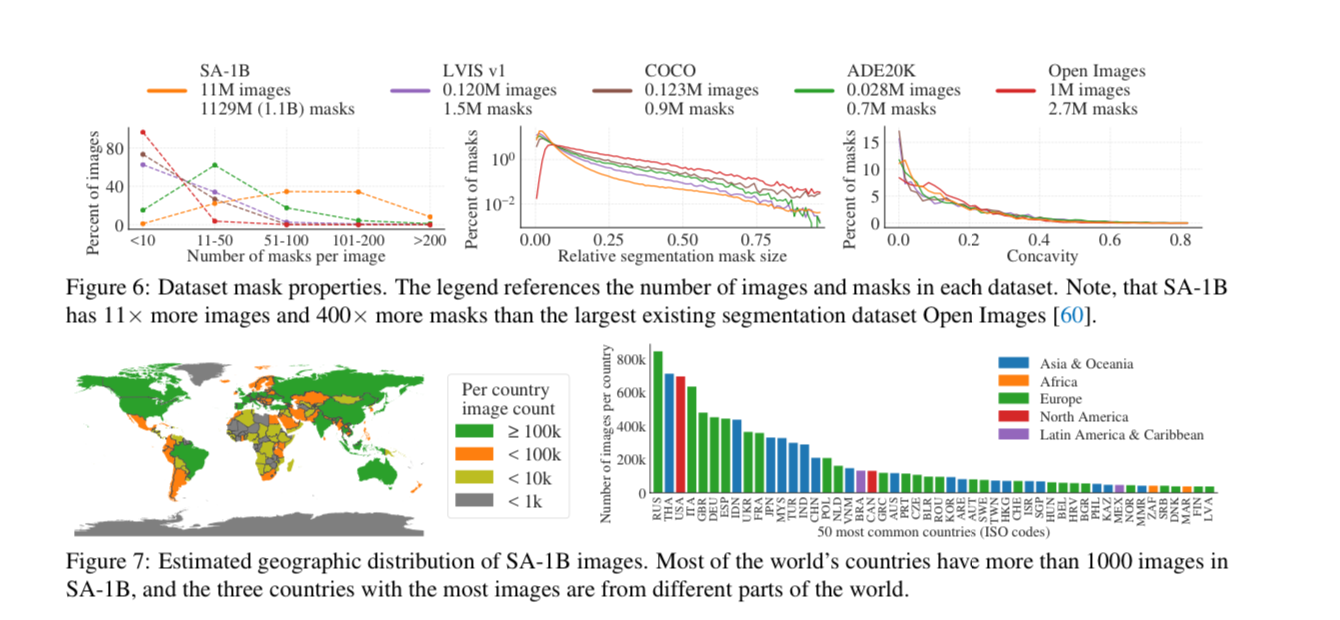
They also do some analysis on the segmentation of people to address fairness concerns across perceived gender, skin tone, and age group.

They evaluate on 23 other datasets and note that SAM is state of the art with “zero shot” performance. Meaning you can just click a random point the mask and they will segment it.
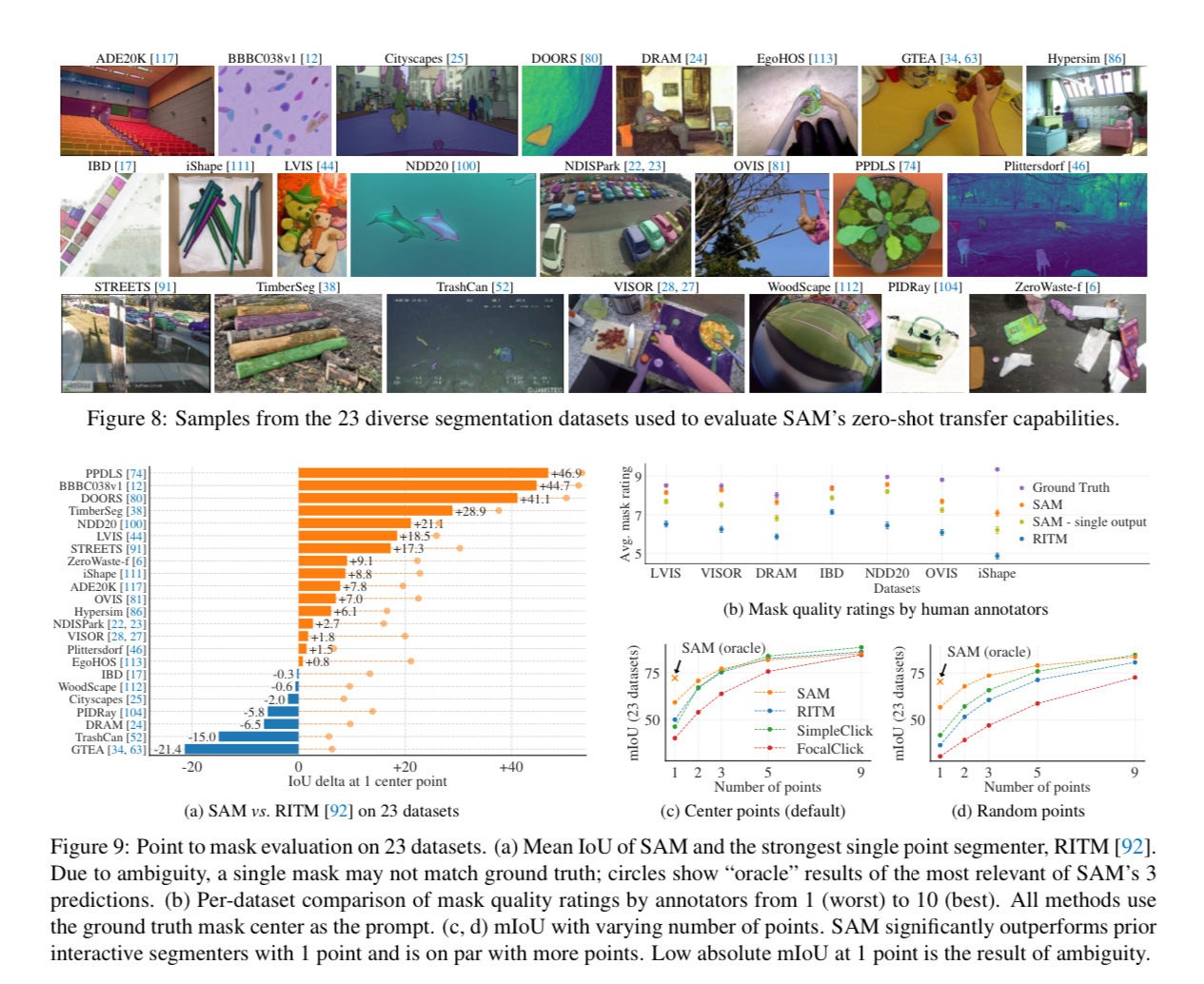
Conclusion
Props to Meta for doing all this work then open sourcing it. It is not a trivial amount of work to collect this data and train these models. Now more specific applications can be built on top of this foundational model.
They note that these models and datasets are very composable, and can be used to generate a new class of models.
For example, if you want the entire pipeline to run realtime on video, well you have a massive dataset of labeled images, you could distill down and train a much smaller model, to just detect and segment one object class, but with a much smaller model.
The second half of this model runs in 50ms (which still is only 20 fps on video, which is borderline realtime) but the first image encoder step probably still takes a second or two if I had to guess. Which means the entire pipeline cannot run realtime on video yet.
We are already seeing this model built into products under the hood, and it just feel likes like magic to the end user. Excited to see what people will build next.
If you enjoyed this dive, please join us next week!

All the past dives can be found on the blog.


The live sessions are posted on YouTube if you want to watch at your own leisure.


Best & Moo,
~ The herd at Oxen.ai
Who is Oxen.ai?
Oxen.ai is an open source project aimed at solving some of the challenges with iterating on and curating machine learning datasets. At its core Oxen is a lightning fast data version control tool optimized for large unstructured datasets. We are currently working on collaboration workflows to enable the high quality, curated public and private data repositories to advance the field of AI, while keeping all the data accessible and auditable.
If you would like to learn more, star us on GitHub or head to Oxen.ai and create an account.