Arxiv Dives - Self-Rewarding Language Models

The goal of this paper is to see if we can create a self-improving feedback loop to achieve “superhuman agents”. Current language models are bottlenecked by labeled data from humans. Not only is the quantity of labels a bottleneck, but also the quality. If we are able to get the language model to generate it's own training data as well as learn how to reward itself in an iterative fashion, we may be able to escape the bottleneck of labeled data from humans.
Paper: https://arxiv.org/abs/2401.10020
Team: NYU & Meta
Publish Date: Jan 18th, 2024
ArXiv Dives
Every Friday at Oxen.ai we host a paper club called "ArXiv Dives" to make us smarter Oxen 🐂 🧠. We believe diving into the details of research papers is the best way to build fundamental knowledge, spot patterns and keep up with the bleeding edge.
If you would like to join live to ask questions or join the discussion we would love to have you! Sign up below 👇

The following are the notes from the live session. Many thanks to the community asking great questions along the way. Feel free to watch the video and follow along for the full context.
Self-Rewarding Language Models
Last week we went over DPO as a more stable and efficient way to optimize a model than RLHF. The problem is DPO requires that you have a substantial amount of labeled human preference data in order to train a model.
This paper introduces agents that can both:
- Act as an instruction following model, generating a response given a prompt
- Generate and evaluate new instruction following examples to add to their own training set.
Synthetic Data
It's common to be skeptical about the act of a model adding data to it's own training set. This is because using data generated from a pre-trained model in theory will not give any new information that the model does not already have encoded in its parameters, so how can it learn new information?
Although theoretically a self-improving language model seems like it wouldn't work, we are starting to see synthetic data be a successful technique in papers like this. I have been thinking why this is the case?
The best argument I have heard it is that with these large pre-trained models it is no longer about adding data from a new distribution, since in theory they have seen "all the distributions on the internet". It is more about “spiking” the distribution in different directions that you want to control, and guiding them on how to behave. It is one thing to have a model that can say in theory say anything it is another thing for a model to say what you want it to say.
Being able to have the model generate it's own synthetic data feels more like alignment or honing in skills than learning something new. The paper below stops after 3 iterations so it is hard to tell how far this particular technique can take us, but what it does show is that a language model can improve it's own skills by adding data to it's own training set.
Can a language model create brand new text that adds to the vast corpora of knowledge? Or will it just saturate with ideas we already know, simply filtered and reformulated? It’s an interesting thought experiment that is good to keep in the back of your mind as we dive in.
Self-Rewarding Language Models
If you’ve been following along with previous ArXiv Dives, the entire pipeline should be pretty intuitive to wrap your head around.
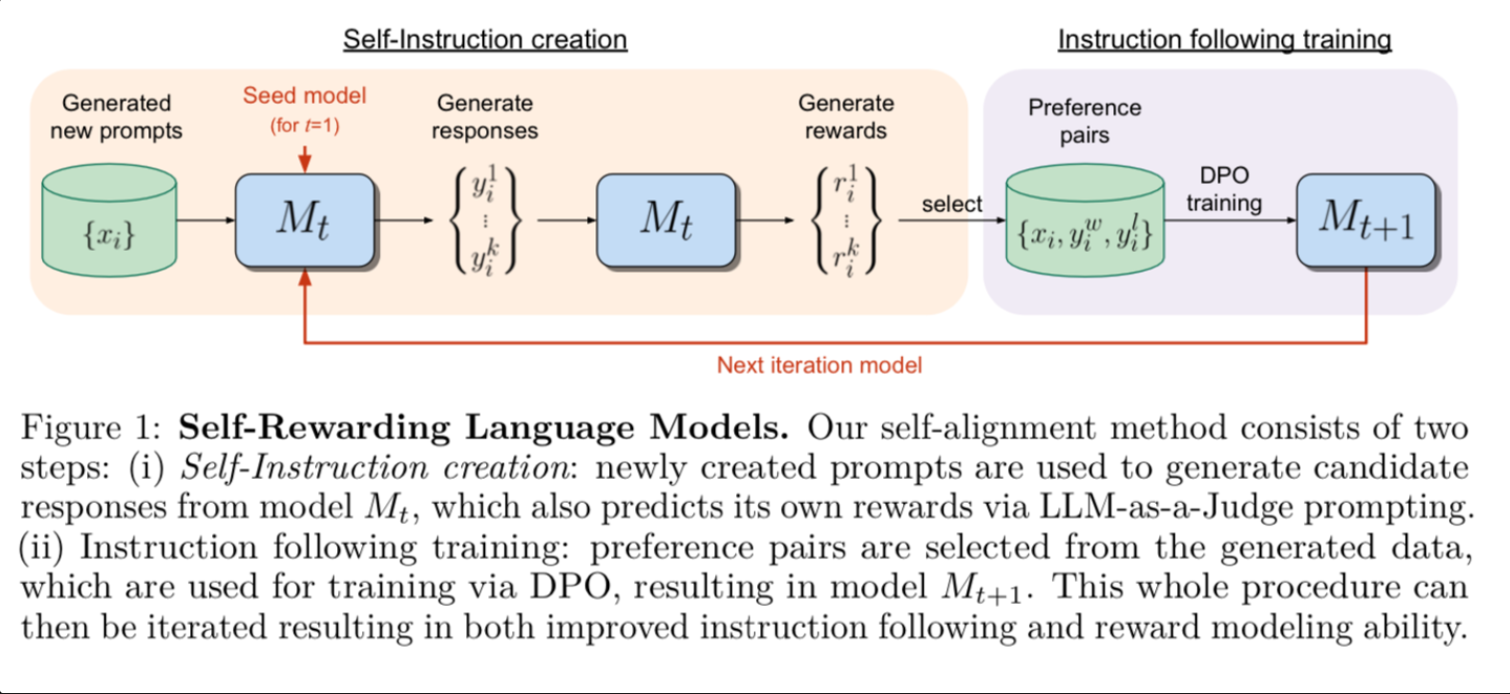
First we start with a set of prompts. Then we seed a supervised fine tuned (SFT) model to have two skills i) generate responses ii) evaluate responses. Then we use the SFT model to generate data both in the form of prompts and responses as well as ranked preference pairs. There are multiple potential completions for each prompt, so we need to generate multiple responses and then use the same model to rank which response is better.
They use a clever "LLM-as-a-Judge" prompt to help generate and filter the data that is added back into the training dataset, in turn improving the model in a positive feedback loop.
Skill 1) Instruction Following
Hopefully from the past dives (InstructGPT, DPO) you are familiar with supervised fine tuning to get your model to follow instructions, and align with preference pairs.
An example of a prompt for instruction following could look like:
[inst]
Make sure to output all data in json in the format:
{
"answer": "YOUR_ANSWER"
}
[prompt]
what does the team at Oxen.ai do?
[response]
{
"answer": "build open source tools to help manage machine learning datasets"
}It is nice to separate out an instruction or system message from the user prompt so that you can tailor the user experience or developer output. For example you could also have an instruction that said "always respond like a pirate", and now every response has a little humor if that is what you are going for.
In the case of Self-Rewarding Language models, we will want our model to follow instructions to generate new data to feed back into the model.
Skill 2) LLM-as-a-Judge
The second step after getting a model to follow instructions, is to align the model to human preferences. Since there are multiple valid responses for each prompt, learning which responses we prefer takes a language model from a basic instruction following machine to a more robust and aligned model. Techniques like DPO or RLHF have been shown to improve the language model further than simply instruction fine tuning.
In this case the second preference optimization step uses the same LLM as a judge of it's own outputs. For example you may have the start of a sentence with two valid completions, where one is more correct than the other.
Oxen.ai is ...
👍 fast and easy to use
👎 a tool for helping farmers with their cropsWe would prefer the model generate the first completion rather than the second, so we rank it higher. You can have humans label these pairs that are generated from the model, but this is time consuming and expensive. If the language model can judge it's own outputs and give a quality score, then we could feed the data back in a self-improving loop.
Prompting as the Judge
They use a well-crafted clever prompt in order to have the LLM judge it's own outputs.

The prompt is important to get working well for this entire pipeline to work. Later in the results section they cite other prompts that have been tried that only have a 26% pairwise accuracy when compared to humans, where-as this particular prompt has 65.1% as a starting point.
This is not the first time this approach for using LLM as a judge has been proposed. The paper “Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena” looks at how well LLMs can judge outputs of other LLMs their results are that:
Strong LLM judges like GPT-4 can match both controlled and crowdsourced human preferences well, achieving over 80% agreement, the same level of agreement between humans.
The interesting thing about this paper is that the initial LLM learns to be it's own judge. They are not using a separate, smarter language model like GPT-4 as the judge. So not only does the base model get better at instruction following, but it gets better at judging it's own outputs. This means as we iterate through training, we will each time we train a new model we will have a higher quality preference dataset than the previous iteration.
A few key things to note here:
- The initial model already needs to be able to generate reasonable responses for this to work
- The reward prompt must do a decent job scoring the outputs to kick off the feedback loop
If you don't meet these two conditions, you would be generating garbage, ranking garbage, and feeding garbage back into the model.
Initialization
First they are given a seed set of instructions that they supervise fine tune Llama-70B. The data they perform SFT with is a subset of the OASST dataset with 3200 examples from the English language that are high-quality, based on their human annotated rank. This is what they call the initial Instruction Fine Tuning (IFT) dataset
We helped clean up the OASST dataset following the same method and uploaded the subset here:
Then they create a second dataset called the Evaluation Fine Tuned (EFT) dataset. This dataset is prompts that do not overlap with the IFT dataset, but in the format of the LLM-as-a-judge prompt. The initial EFT dataset is 1775 training examples and 531 evaluation examples.
Example EFT data can be found here:
They mix these datasets together to train the initial supervised fine tuned model.
Self-Instruction Creation
The model itself can then modify it’s own training set by:
- Generate a new prompt, given few show prompting
- Generate N candidate responses, given each prompt
- Evaluate each candidate response, using the LLM-as-a-judge skill of the same instruct tuned model to evaluate it’s own responses
AI Feedback Training Data Creation (AIFT)
The data generated from the steps above is then added to the IFT+EFT data to create an AIFT dataset. When adding the new data to the AIFT training set, they consider two methods.
1) High and low pairs
Given a prompt x and responses y_i then they take the highest ranked winner and lowest ranked loser and add it to the preference pair dataset for DPO.
2) Positive examples only
Given a prompt x they only take responses with a perfect score from the evaluator of 5 and add this to the instruction following dataset.
They find that learning from the preference pairs (#1) and not just the positive examples gives superior performance in the end.
Iterative Training
The overall process trains a series of models M0..M1
M0: Start with a pre-trained Llama-70B with no fine tuning.
M1: Initialize with M0, then fine tune with the IFT+EFT seed data
M2: Initialize with M1, then trained with AIFT(M1) data using DPO
M3: Initialize with M2, then trained with AIFT(M2) data using DPO
They say that this procedure resembles other work such as the Pairwise Cringe Optimization and Iterative DPO papers, however the key difference is the reward model is also improving each iteration, since we use the same model to generate responses and rank responses in the pipeline.
When they train AIFT(M1) they add 3,964 preference pairs to the training set for DPO. When they trained AIFT(M2) they add 6,942 pairs to the training set to create M3.
Evaluation
They evaluate the model on two axes
- Ability to follow instructions
- Ability to evaluate responses (reward model)
Instruction Following
They use GPT-4 to evaluate performance of various models, using the AlpacaEval framework.
 tatsu-lab
tatsu-labThe idea here is that GPT-4 can check if the response follows the instruction accurately, and judge which response is better.
Reward Modeling
They evaluate the correlation with human rankings on the evaluation set from the Open Assistant dataset.
Each instruction has on average of 2.85 responses with given rankings. They compute a pairwise accuracy showing the model two responses and seeing if the ranking agrees from the model to the human label.
Instruction Following Results
They show that the first iteration M1 with the EFT+IFT data does not outperform the IFT data by much (30.5 vs 30.9). They say this is good because this means that adding a self-reward skill does not impact the instruction following skill.
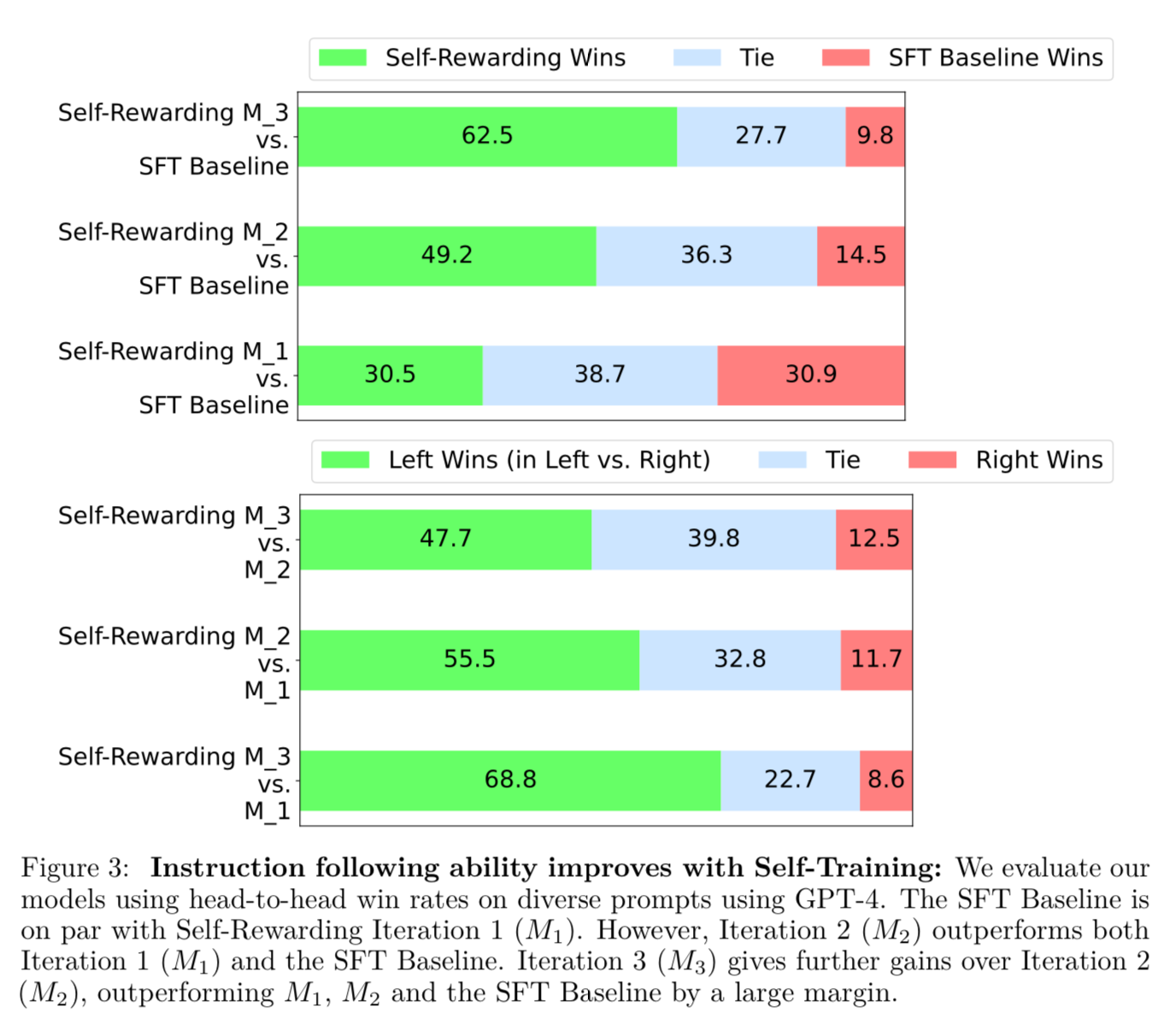
Then they show that the second iteration M2 provides superior instruction following to iteration 1. This is promising that adding this new AIFT(M1) preference data is adding to performance. Iteration 3 also improves over iteration 2 when evaluated against itself by GPT-4.
Not only does it win against it’s baselines, but each iteration starts to get a higher win rate over GPT-4 Turbo as evaluated by GPT-4.
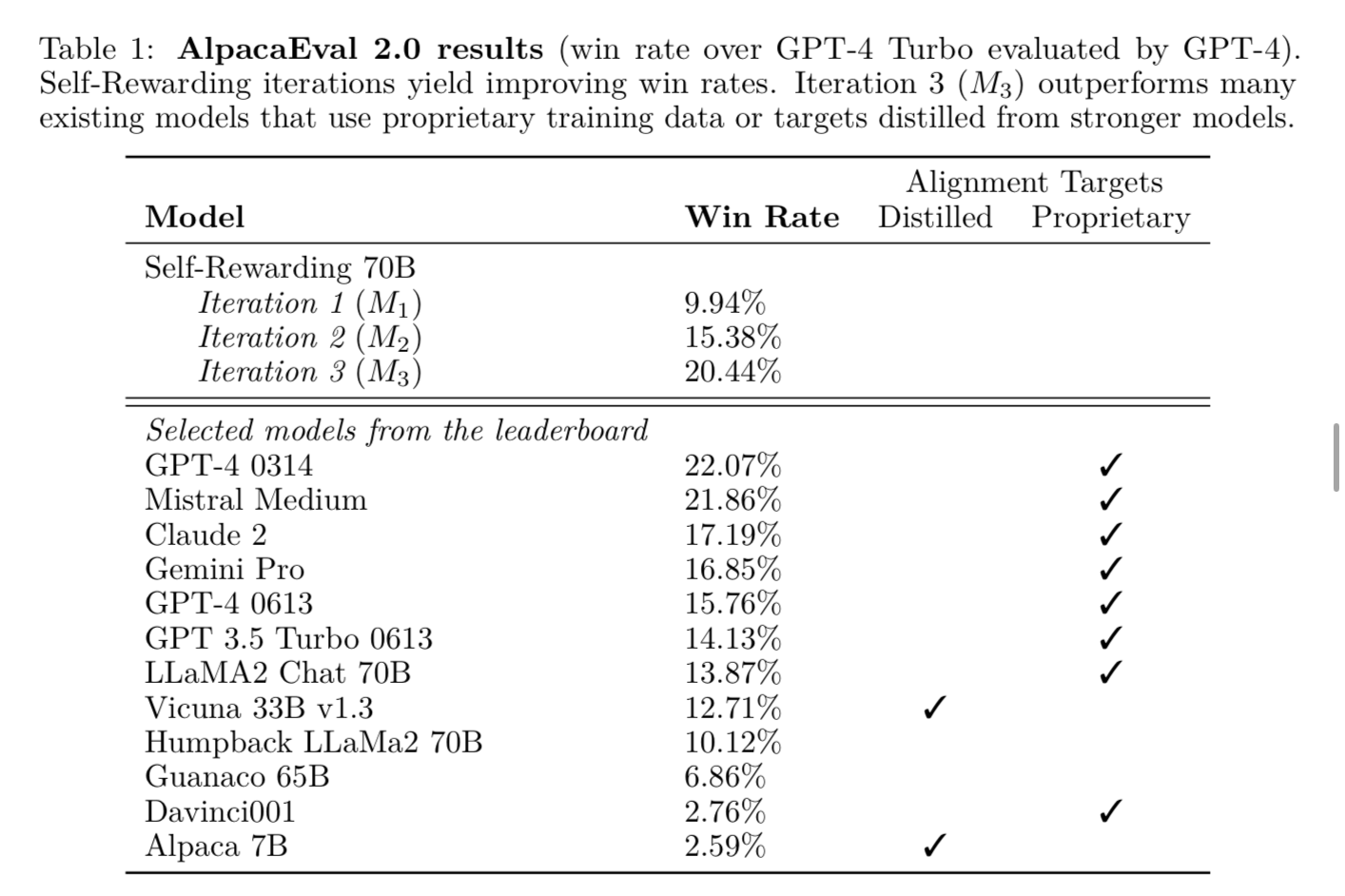
This is exciting because some of the models on the leaderboard here (Claude 2, Gemini Pro, GPT4 0314) typically contain a large dataset, sometimes over 1 million annotations, or use targets distilled from stronger models to generate the dataset. The self improving technique starts with a much smaller dataset, and does not use any external models to generate or rank the responses.
Reward Modeling Results
They also show quantitatively that the reward model gets more accurate over time. They compare the model's rankings to human rankings from the original human labeled dataset.
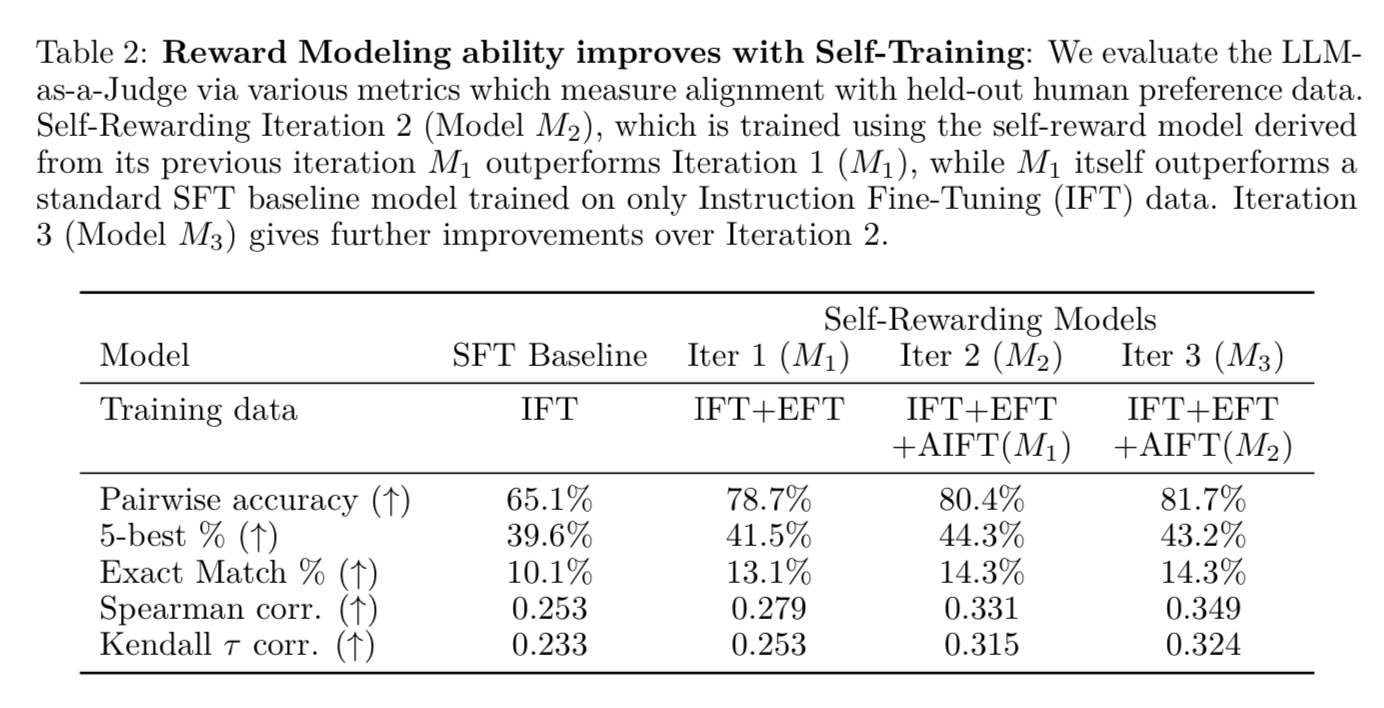
As mentioned before, the quality of the LLM-as-a-Judge prompt has a large impact on how well this iteration loop works. The below prompt gave a 26.6% pairwise accuracy, whereas the prompt they used in this paper gave 65.1%. Scroll up and see if you can find the differences, it is hard to tell just by quickly scanning, but shows the value of prompt engineering.

Conclusion
Overall this paper is interesting because of the size of the dataset needed. They start with only a couple thousand examples and can outperform models that were trained on millions using this iterative process. The fact that they see improving performance over time without any human in the loop is also encouraging. This virtual cycle is promising in this small setting, but is only a preliminary study.
A few things that would be interesting to see:
- When does this approach stop improving? Why did they stop at 3 steps?
- Would this method work with smaller (7B) models?
- What other prompts could we use in the LLM-as-a-judge step to direct the model in different directions? This has implications for safety as well as performance.
We have some community members in our Oxen.ai Discord working on a an implementation of this to see how well it works in practice with other models. Feel free to join us!

Next Up
If you enjoyed this dive, please join us next week live! We always save time for questions at the end, and always enjoy the live discussion where we can clarify and dive deeper as needed.
All the past dives can be found on the blog.


The live sessions are posted on YouTube if you want to watch at your own leisure.


Best & Moo,
~ The herd at Oxen.ai
Who is Oxen.ai?
Oxen.ai is an open source project aimed at solving some of the challenges with iterating on and curating machine learning datasets. At its core Oxen is a lightning fast data version control tool optimized for large unstructured datasets. We are currently working on collaboration workflows to enable the high quality, curated public and private data repositories to advance the field of AI, while keeping all the data accessible and auditable.
If you would like to learn more, star us on GitHub or head to Oxen.ai and create an account.
Oxen-AI