Arxiv Dives - Vision Transformers (ViT)
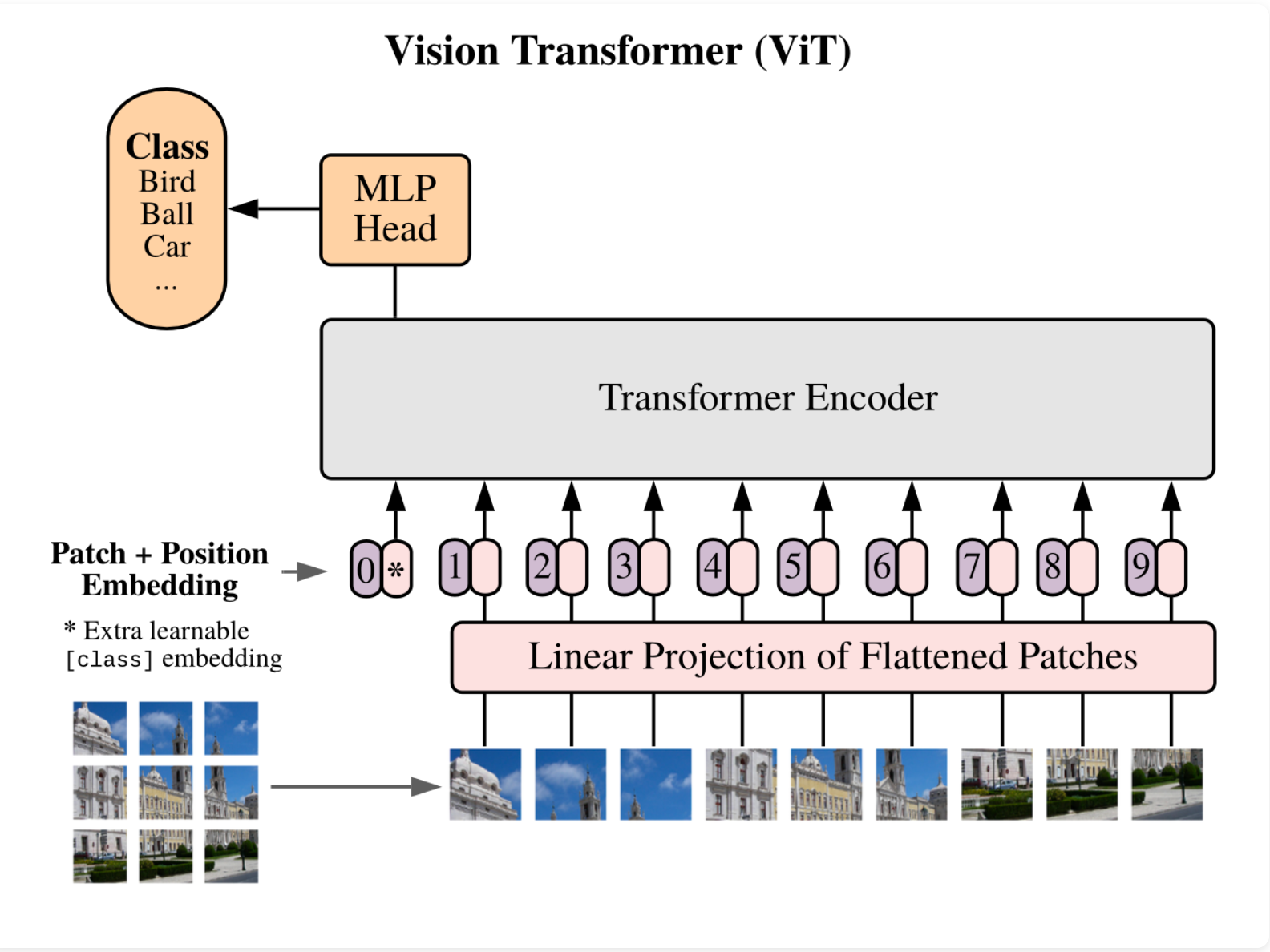

With all of the hype around Transformers for natural language processing and text, the authors of this paper beg the question - can we apply self-attention and Transformers to images as well? This post dives into how it works and will give you an intuition on why it's useful, and how it can be applied in your own work.
TLDR ~ Transformers work just as well on images, given enough data 😎.
What is Arxiv Dives?
Every Friday at Oxen.ai we host a paper club called "Arxiv Dives" to make us smarter Oxen 🐂 🧠. We believe diving into the details of research papers is the best way to build fundamental knowledge and keep up with the bleeding edge.
If you would like to join the discussion live, sign up here. Every week there are great minds from companies like Amazon Alexa, Google, Meta, MIT, NVIDIA, Stability.ai, Tesla, and many more.

The following are the notes from the live session. Feel free to watch the video and follow along for the full context.
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Transformers have become the standard in the natural language processing world, which begs the question - can they be applied in computer vision?
Paper: https://arxiv.org/abs/2010.11929
Team: Google Research, Brain Team
Date: June 3rd, 2021
The Task
In this paper they will be performing the “Image Classification” task on classic computer vision datasets like ImageNet.
Here is an example of a subset of ImageNet called ImageNet-1k. The full ImageNet is 14 million images with 21K categories. This one is 1.4 million images with 1000 categories.

The subset of ImageNet is still fairly large, 56 GB of data with over 1 million images.
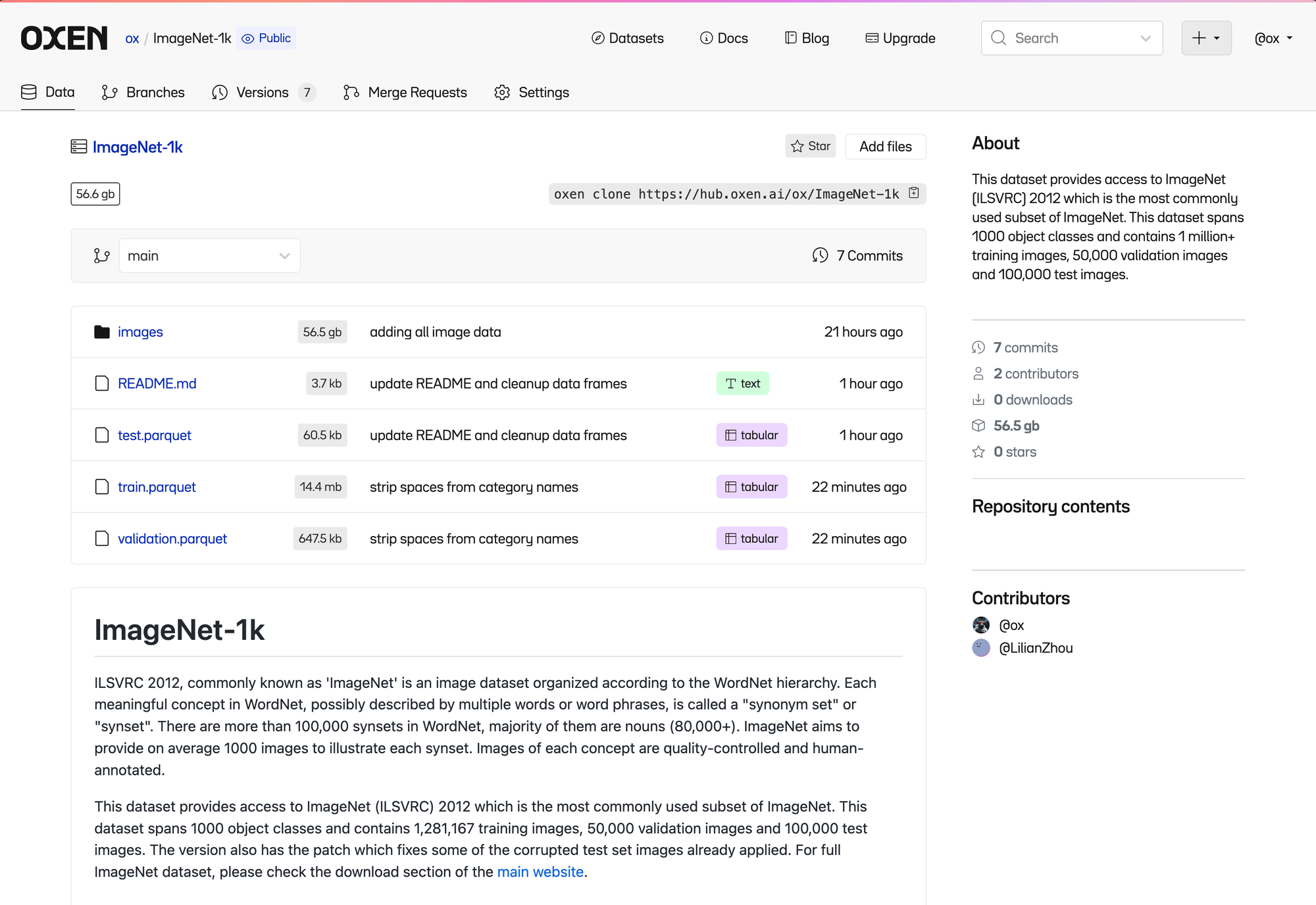
If you have never looked at ImageNet or an Image Classification task, it is pretty simple. There are 1.2 million images in the training set all labeled with the dominant object in the image.
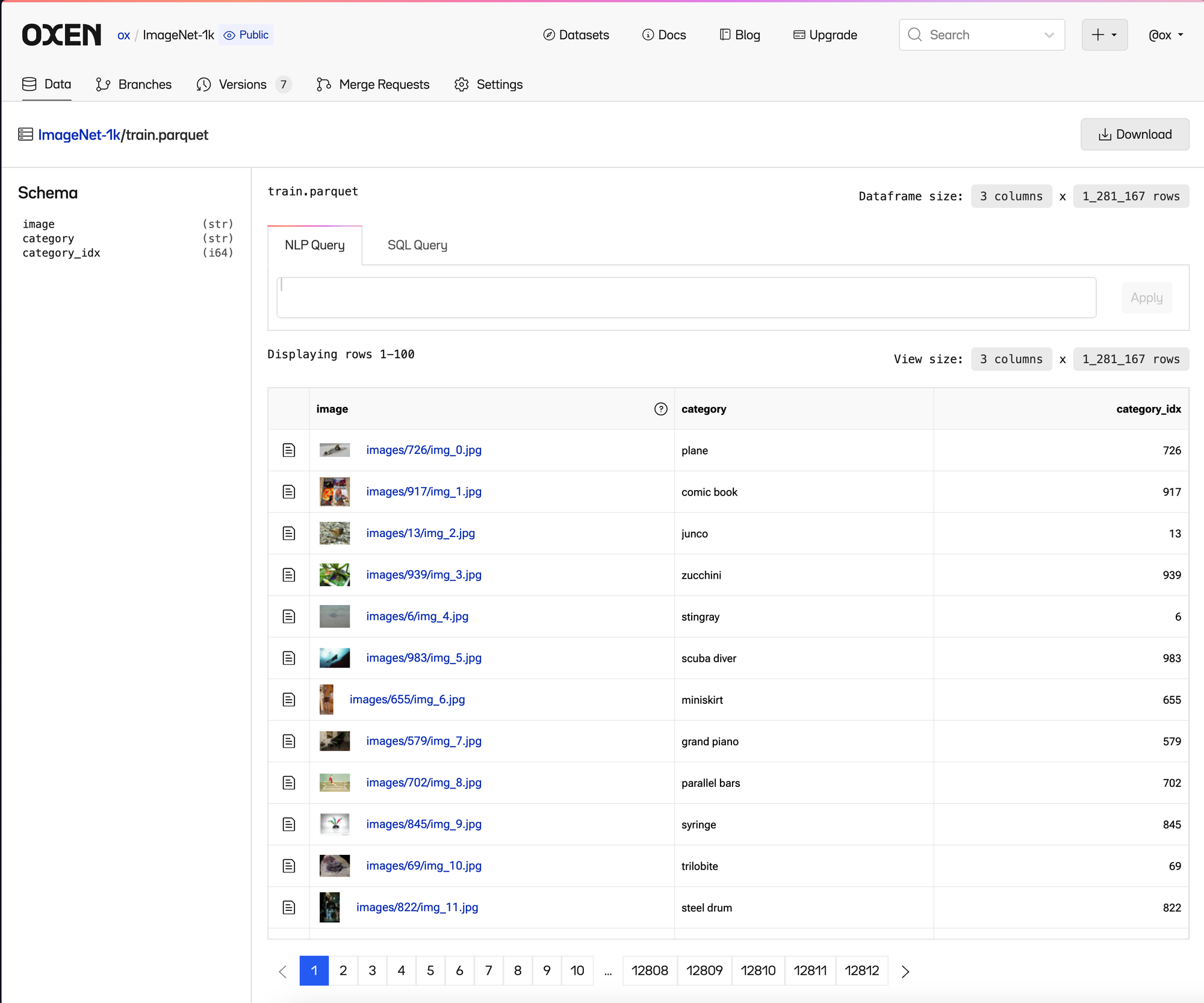
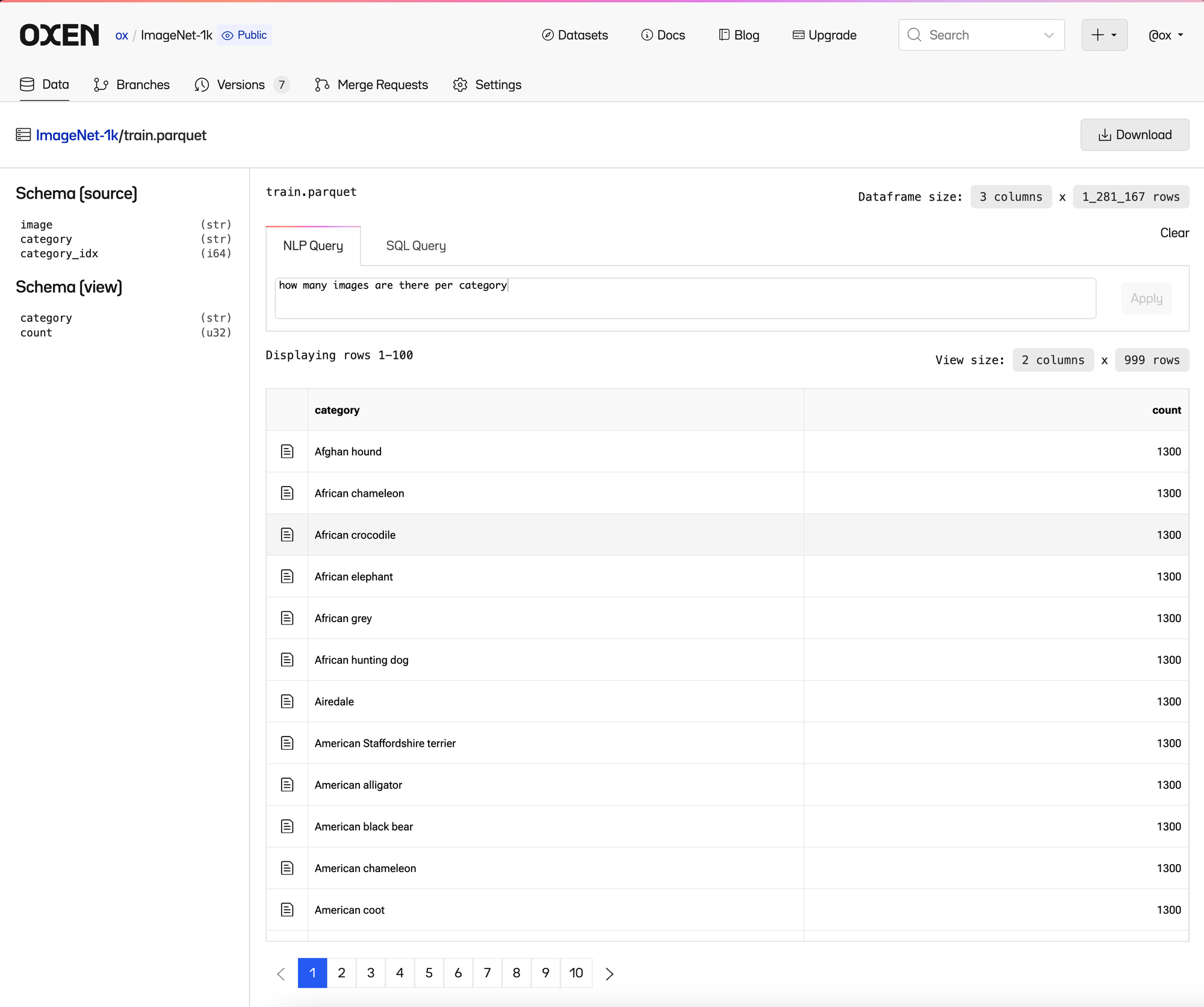
In this dataset there are ~1300 images per category, with 1000 categories.
Convolution vs Transformers
Before we dive into Transformers, it is good to note what they are comparing them to. When they compare results in the paper they are comparing to ResNet’s, which are Convolutional Neural Networks with Residual Layers.
ResNet paper: https://arxiv.org/abs/1512.03385
Traditionally convolutional neural networks have been the most successful in image tasks, because their inherent structure is very similar to an image filter.
A good visual for what convolutions are doing can be found here:

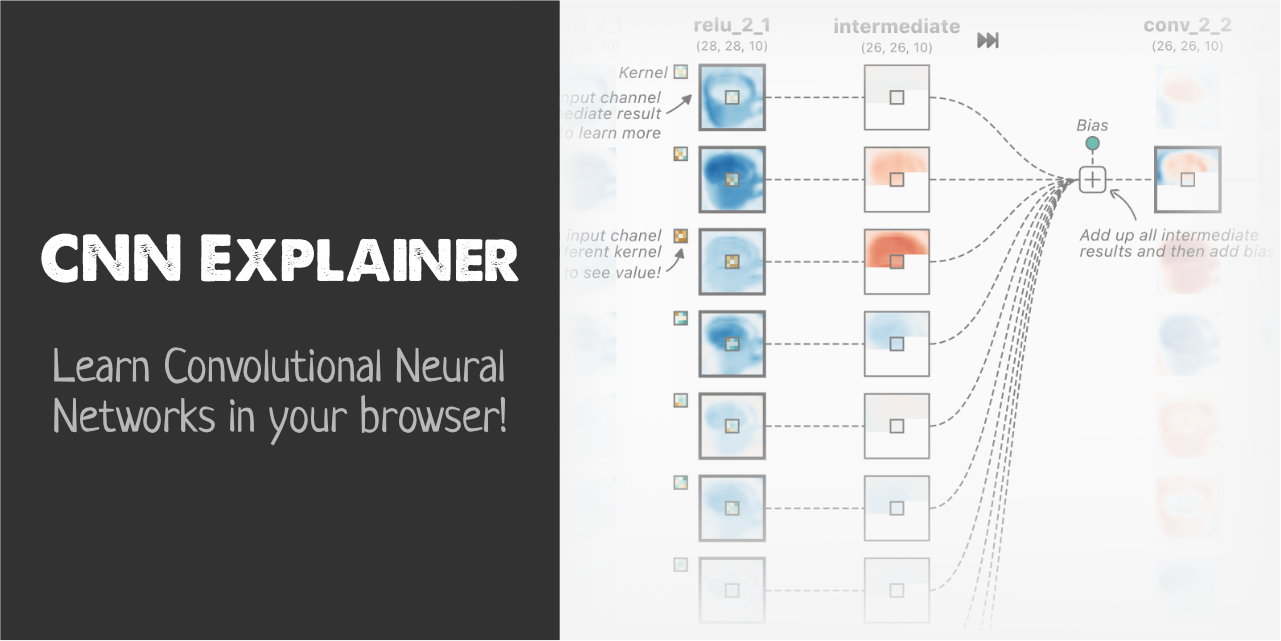
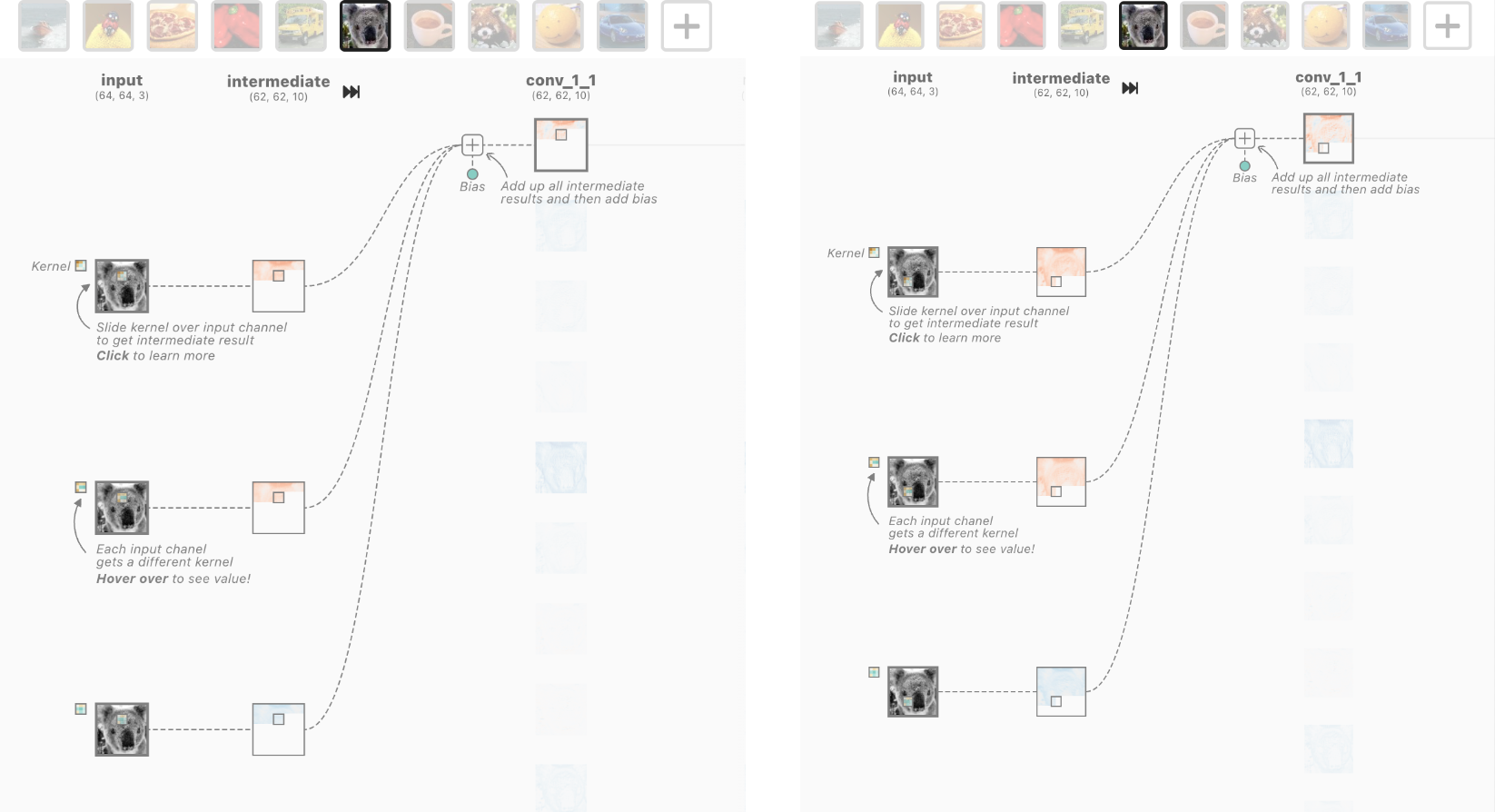
Convolutional layers run a learned filter across the image, and stack many filters of different sizes up until you get your final classification.
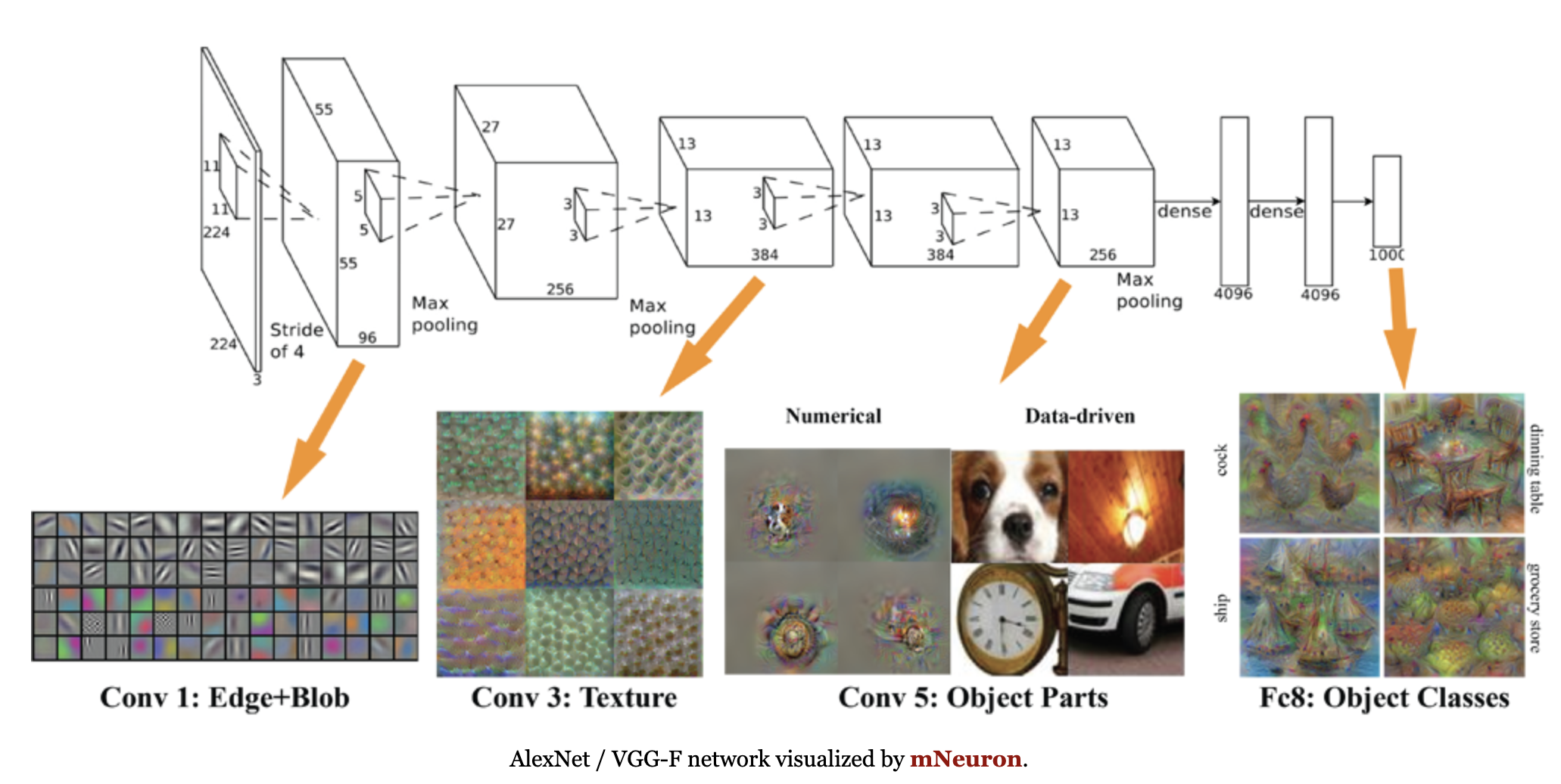
You can see that lower convolutional filters learn to find edges, then build up to textures, objects, and finally object classes.
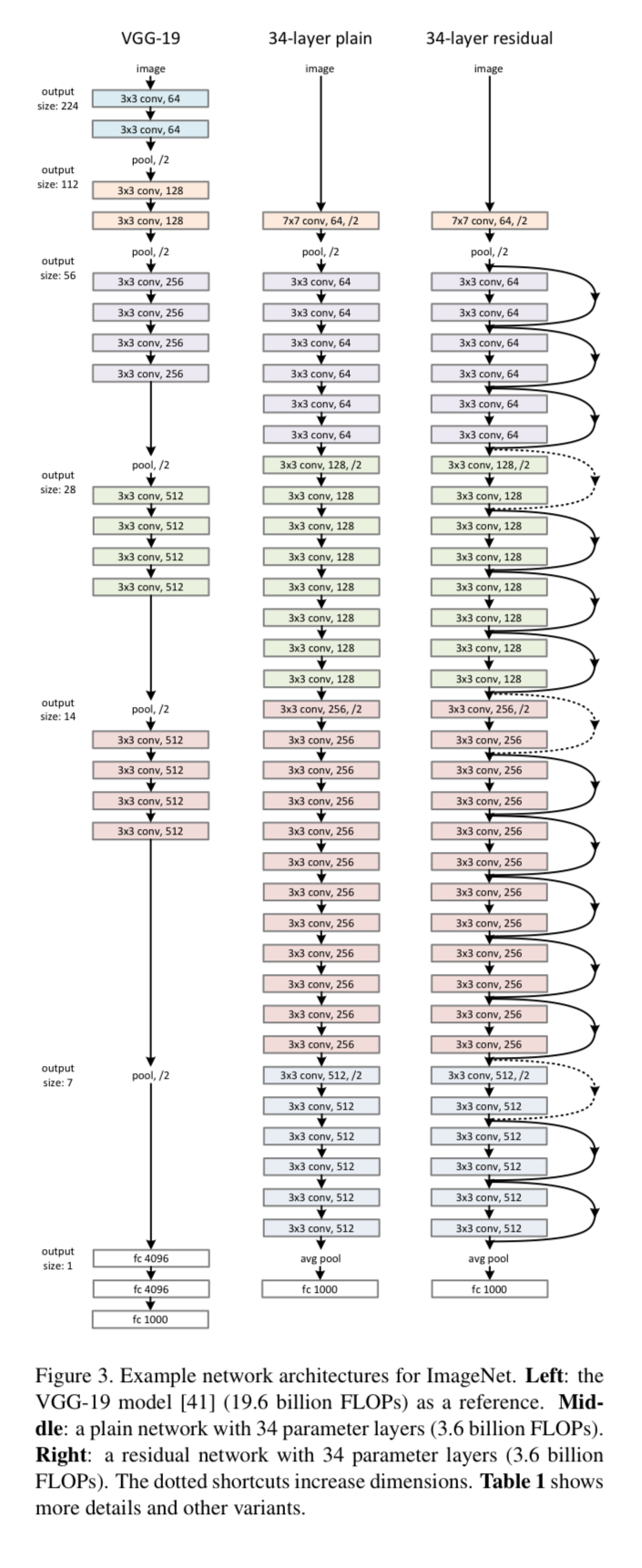
ResNet's can be very deep. For example ResNet152 has 152 layers. For a visual of what a 34 layer version looks like, see the ResNet Paper referenced above.
Replacing Convolution with Self Attention
Instead of convolution, in this paper they use the self-attention mechanism described in the “Attention is all you need” paper.
Note: Convolution can be used in combination with attention, but this paper explores what happens if you apply the full self attention transformer architecture, with as little modifications as possible, to image classification.
Vision Transformers chop images up into a grid. For example 16x16 pixel squares. Instead of sliding a shared convolutional filter across the image, they flatten all the 16x16 pixel grids into a sequence that can be fed into a transformer.
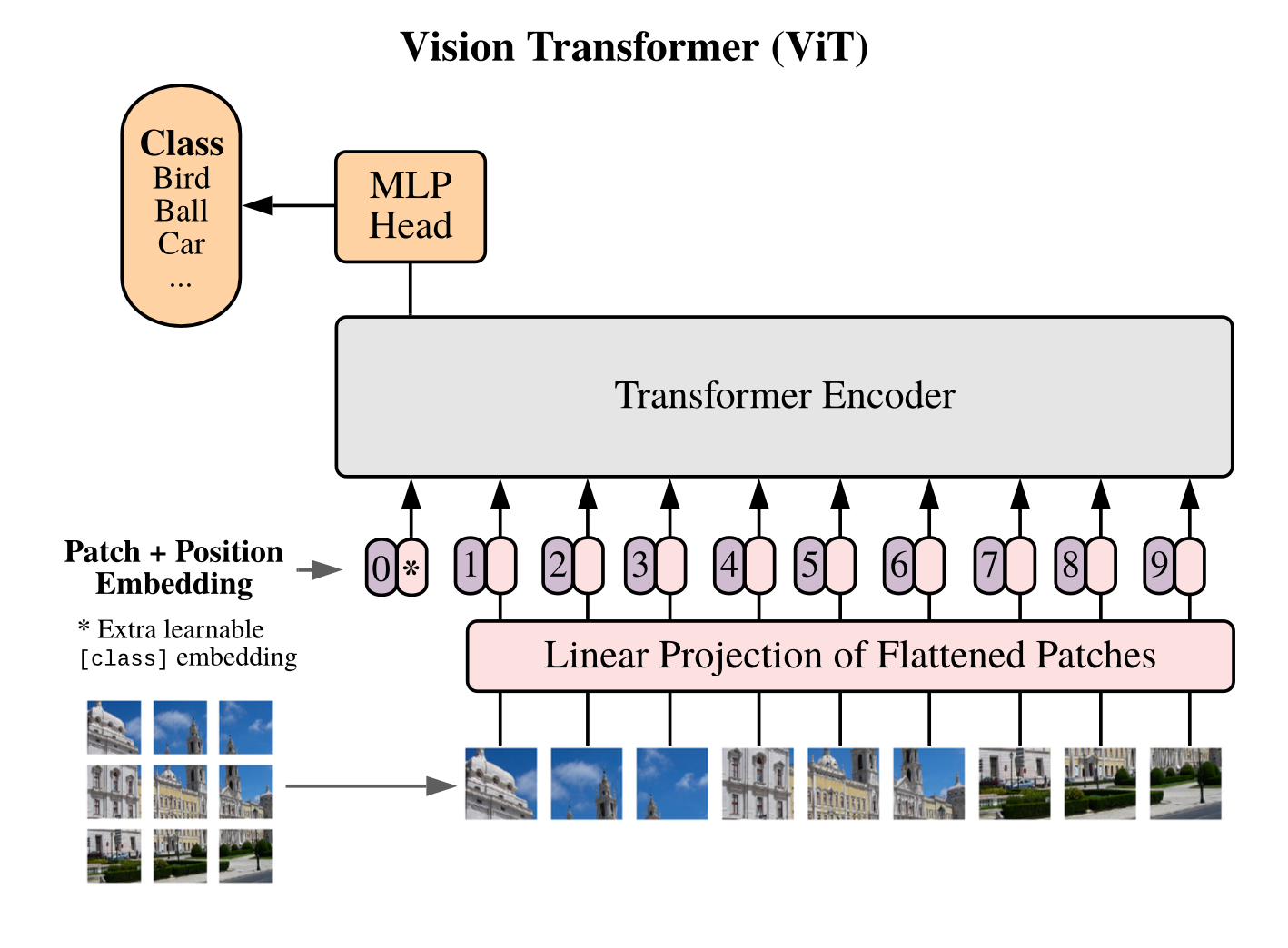
They then use self-attention and multilayer attention heads to connect and abstract the parts of image.
For example, take the image below. It is 256x256, and I have overlaid a grid of 16x16 patches.

If you think back to what self attention does from our dives in the NLP space, you can think of self attention as giving each patch the ability to call out to each other patch through the key, query and value circuits.
The communication in self attention of images (anthropomorphized) may sound like:
“Hey I am furry and ear like, any other patches that look like ears?”
“I am also furry! But more like a mouth and a tongue, does that help?”

The query and key matrices can combine what they know through the value matrix and then into the residual stream and pass through information that may help you classify the image as a dog (in a sweatshirt) instead of a human.
This paper is not the first attempt at applying a transformer to vision, but they do it at a “Google scale”.
When trained on “medium sized” datasets such as ImageNet (1-14 million images) Transformers perform a few percentage points below ResNets of comparable size.
This outcome may seem discouraging, but should be expected since Convolutions inherently are designed to work with properties of images such as translation invariance and locality. They call this “Inductive Bias” of CNNs.
The architecture of CNNs inherently encodes things like the 2D structure of the image and the filters learn to be spatially invariant to changes. Meaning it doesn’t matter if the ears are in the middle of the image or the side or turned slightly, we can still capture that information and pass it on to higher layers.
However, if these models are trained on larger datasets of 14M-300M images, Vision Transformers show similar properties as large language models in a transfer learning setting. Large pre-training then fine tuning shows performance on tasks with fewer datapoints.
This process is called “Transfer Learning”, where you learn the lower lever features of the data on a large dataset, and then fine tune to your specific use case. The fine tuning datasets may be in the 10,000-100,000 example range. Or in the best case you can get decent classification results by just showing the network 5-10 examples, and it has a good enough representation that it can extrapolate.
Biggest Takeaway
The biggest takeaway from this paper in my opinion is….
Vision Transformers work better than ResNets if and only if you train them on larger datasets. This is because the inductive biases built into convolutional network architectures require less data to be seen. Vision transformers are a more efficient architecture in terms of FLOPs or compute, so can see more data faster.
They run experiments on ImageNet-1k, ImageNet-21k or an in-house JFT-300M dataset.
The best model they train (ViT-H/14 trained in JFT) reaches state of the art on multiple image recognition benchmarks.
Method
They try not to modify the architecture of NLP transformers too much, so that they can use the same libraries and efficient implementations.
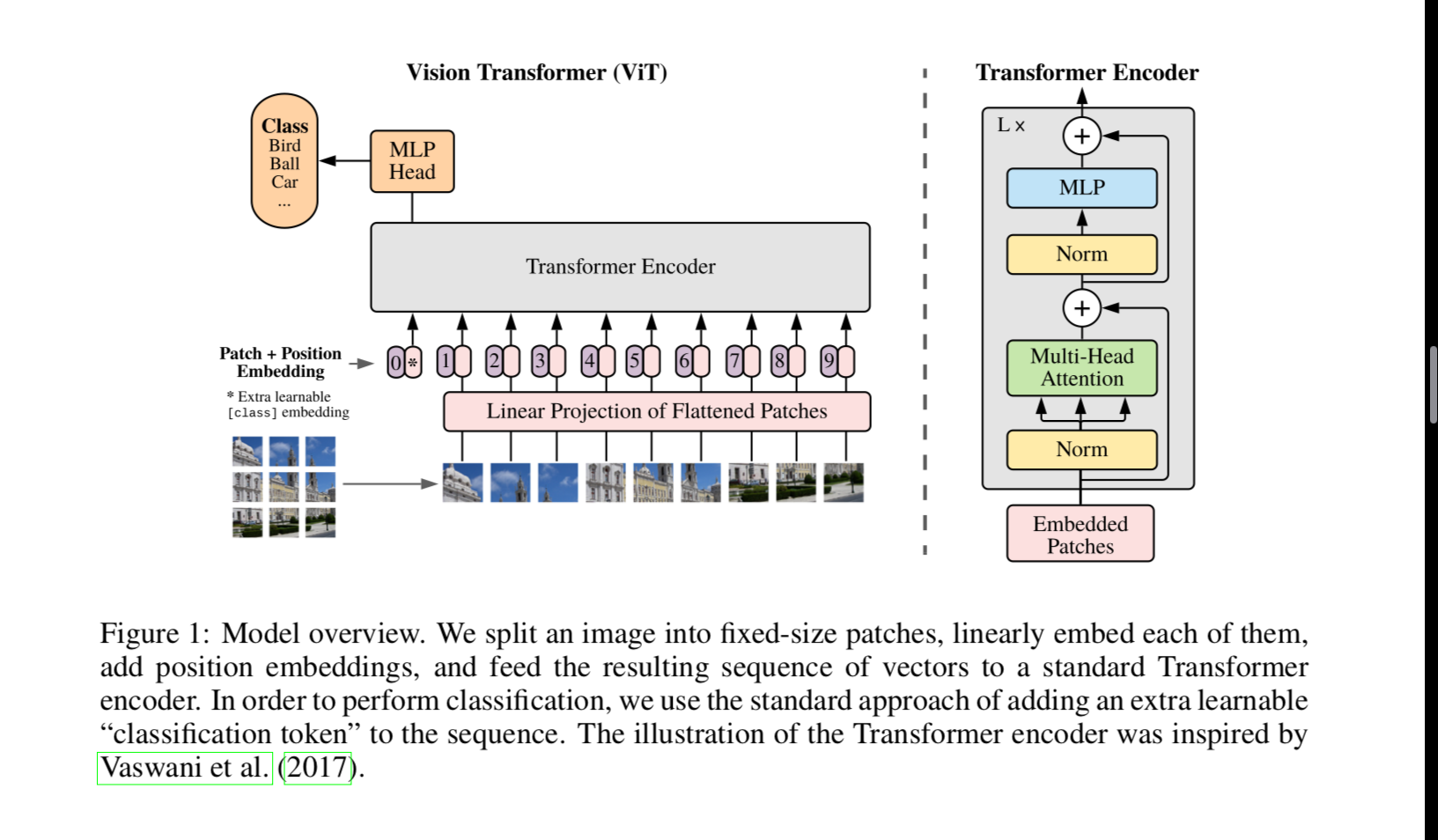
Let’s follow the diagram above, taking what we learned from our work diving into transformers.
Instead of feeding in a sequence of tokens embeddings, they chop the image into a sequence of patches.
So for an image that is 512x512 and patch size 16 you would have a sequence length of 512/16=32.
They use a consistent latent vector size D through all the layers, so the patches are flattened and mapped to D dimensions with a linear layer.
Each patch flattened is 16 * 16 * 3 = 768, so they flatten it down and run it through a linear layer to dimension D which could be larger than 768, depending on your hyper parameters. In the paper they choose a few configurations from 768 to 1024 to 1280.
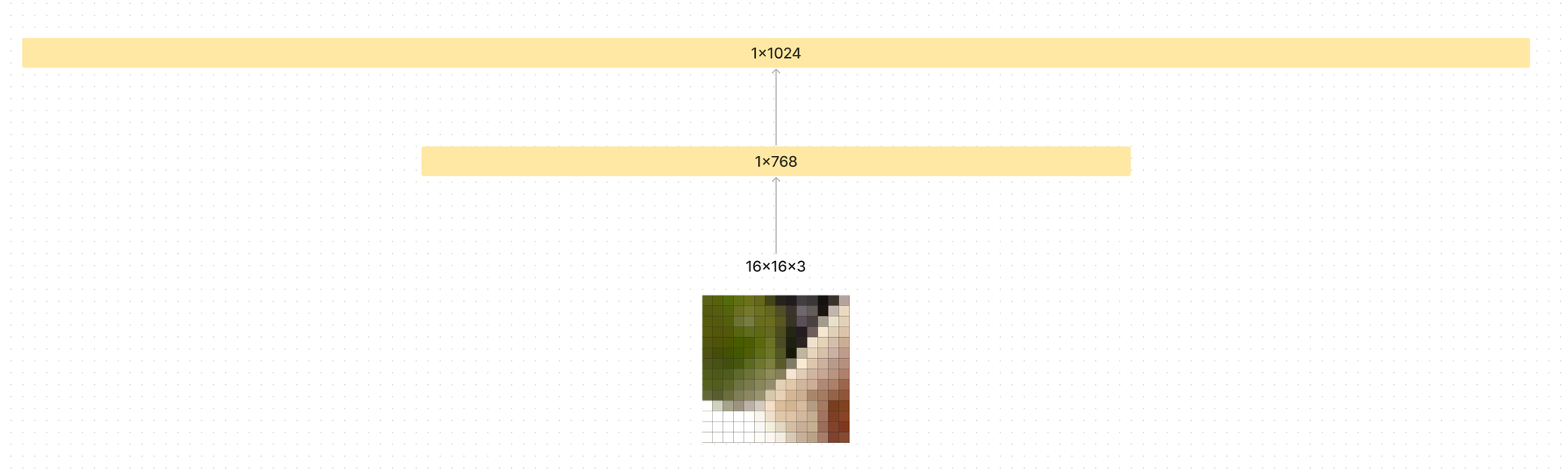
They call the output of this initial linear layer that is fed into the model the “patch embeddings”.
They also prepend a learnable embedding with a fixed token [CLASS] at the start of the sequence that is not tied to a patch, for the model to learn a representation of the class of the image.
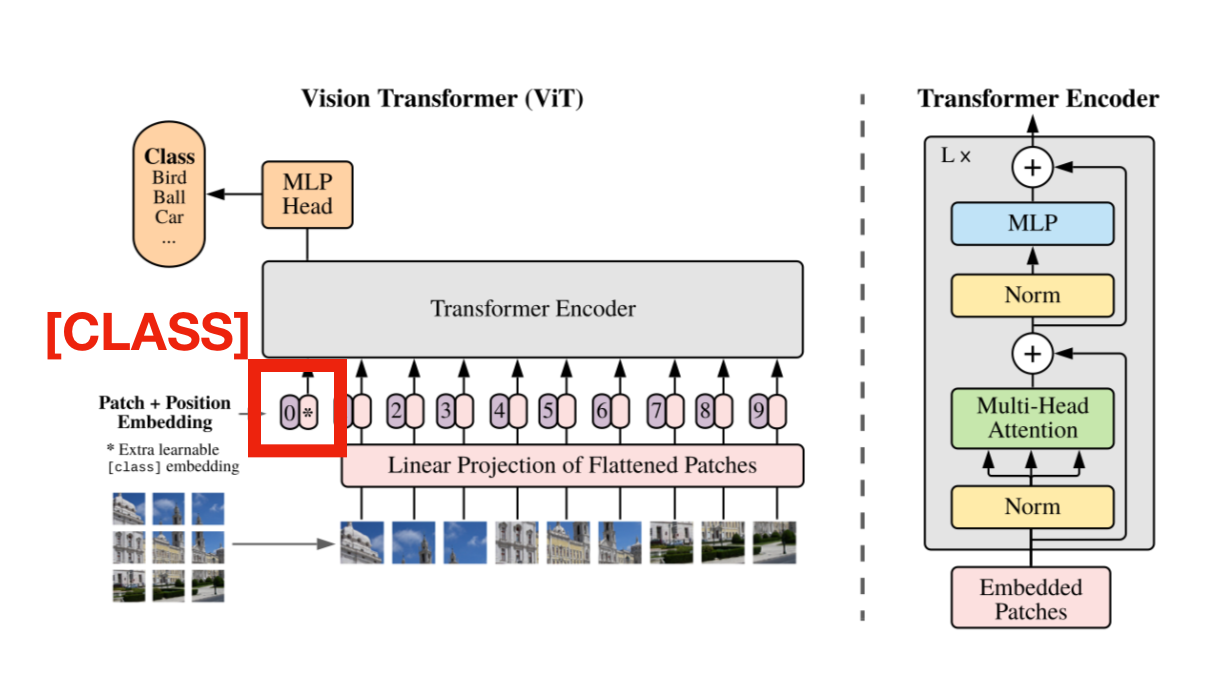
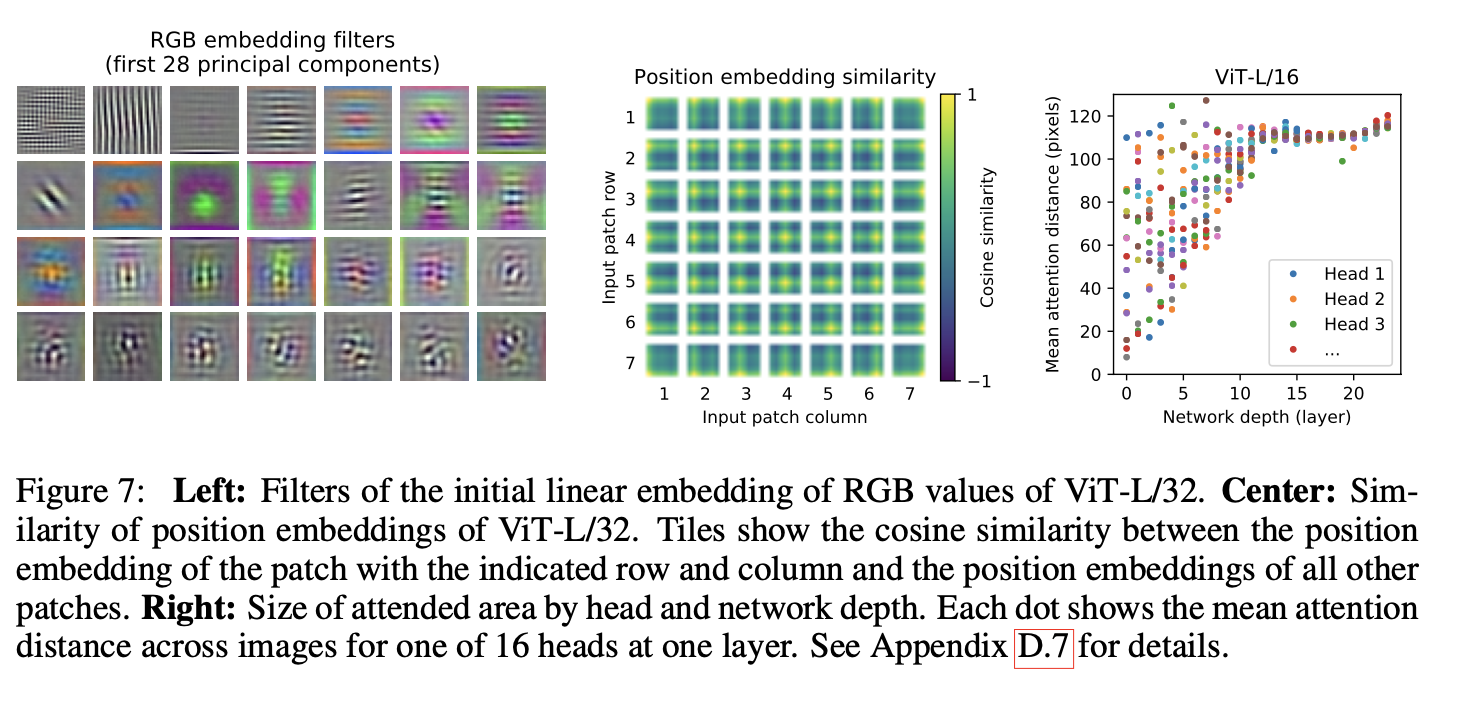
Positional embeddings are also used, and they say that encoding a 1D position works just fine, they had not seen any gains from trying to represent the position as 2D. Maybe this is because you can infer 2D position from 1D representation…row*width.
They did some analysis on what the linear patch embeddings learn and what the positional encodings learn later in the paper.
Other than the inputs being image patches, they use the same Transformer encoder model we have seen in language. They feed the patches through multi head attention, then a MLP, and finally predict a class with a MLP head.
Inductive Bias
There are a couple types of inductive bias that convolutional neural networks have:
- Locality - two-dimensional structure
- Translation invariance
In a ViT the self-attention mechanism is global, and the MLP laters are local and translationally invariant. The spatial relations between patches has to be learned from scratch, and the two dimensional nature is only encoded by cutting the image into patches.
Hybrid Architecture
There is no reason you couldn’t have a hybrid architecture that uses the feature maps from a convolutional neural network as inputs instead of the raw image patches.
They do this in a few comparisons later in the paper.
Fine Tuning and Higher Resolution
They do a similar pre-training and fine-tuning stages to LLM work. Pre-training is done on the large dataset, fine-tuning is done on a smaller downstream task.
If you want to feed images at a higher resolution, they keep the patch size the same, but now the positional embeddings are no longer useful.
Therefore they do a 2D interpolation of the pre-trained position embeddings according to their location in the original image.
Note: the resolution adjustment and the patch extraction are the only areas of inductive bias about the 2D structure of an image.
Experiments
They evaluate 3 models:
- ResNet
- Vision Transformer (ViT)
- Hybrid
ViT performs favorably given computational cost of pre-training.
Datasets
They explore model scalability with a few datasets.
- ILSVRC-2012 ImageNet with 1k classes and 1.3M images
- ImageNet-21k with 21k classes and 14 million images
- JFT with 18k classes and 303M high resolution images
They de-duplicate the pre-training datasets with respect to the test sets of the downstream tasks. They found that there were about 50k of the 300M images in their JFT training set that were duplicates according to this paper they reference. They didn’t say how they deduped, maybe just exact or fuzzy image match.
They test on the following datasets:
- ImageNet validation labels
- Cleaned-up ReaL labels
- Cifar-10/100
- Oxford-111T Pets
- Oxford Flowers-102
- 19-Task VTAB Classification Suite
They use a few model variants:
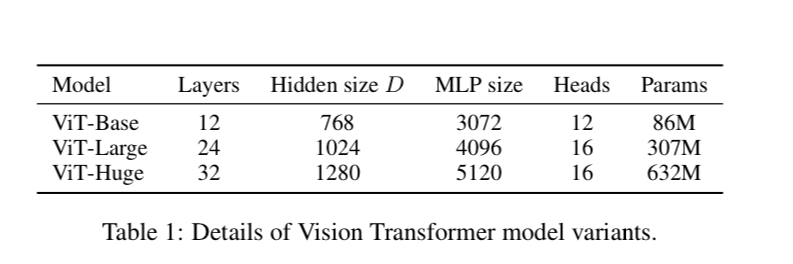
They also use a patch size of 14 or 16 depending on the model, denoted as ViT-L/16 for the patch size of 16 and the large model. The resolution of the images is 512x512 for ViT/16 and 518x518 for ViT/14.
It is good to note that the transformers sequence length is inversely proportional to the patch size. Bigger patch size, shorter sequence.
For the baseline model they use ResNet with some subtle modifications to improve transfer learning. The modified model is called BiT-L (ResNet152x4) above.
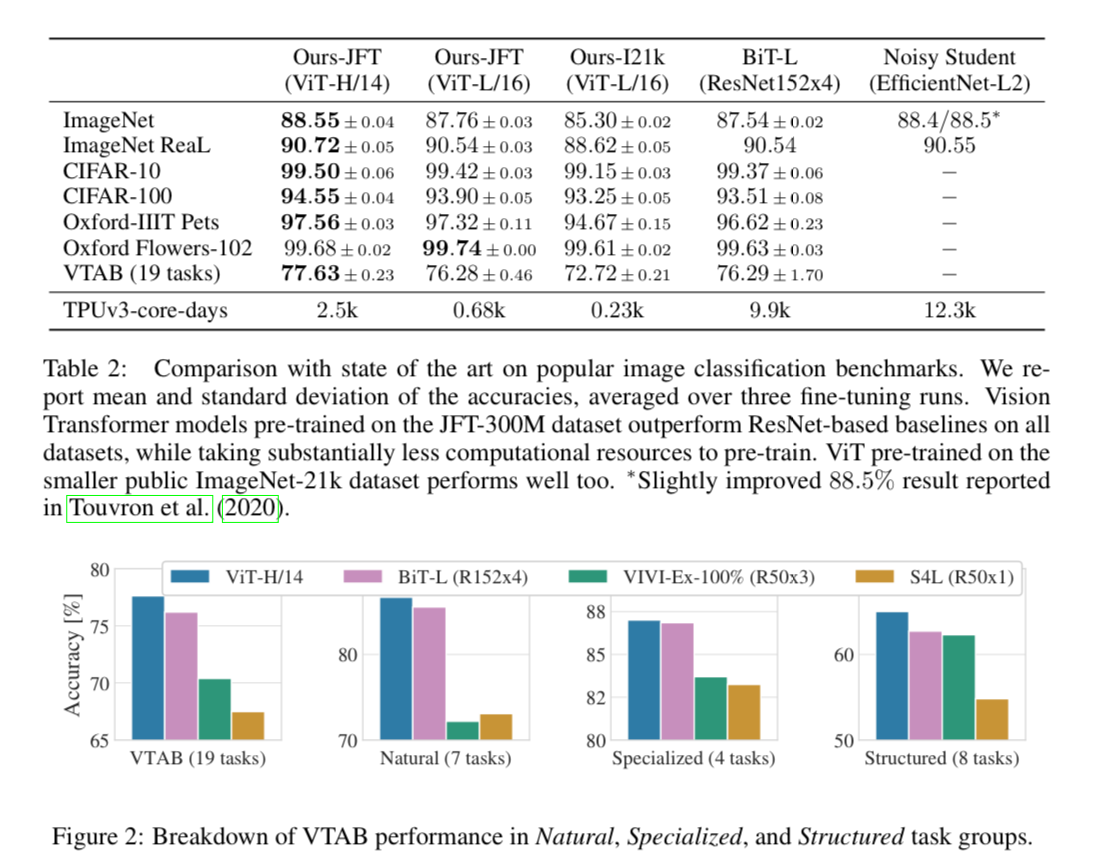
When it comes to performance you can see the ViT-H/14 which was pre-trained on the JFT-300M dataset outperforms ResNet baselines on all datasets, while taking less computational resources to pre-train.
The ViT-L/16 model pre-trained on the public ImageNet-21k dataset performs well on most datasets too, while taking fewer resources to pre-train:
It could be trained using a standard cloud TPUv3 with 8 cores in approximately 30 days.
Just to give you a sense of the scale of these models and datasets, ImageNet 21K is 14 Million Images, and took 30 days to train. JFT-300M, which obtained state of the art is 21x larger than that…so in theory would take two years to train on the same setup? But knowing Google they just threw more compute at it. I didn’t see details on how long this took or if they used more TPUs, but they do show you the raw FLOPs which you could probably back calculate from.
With ImageNet-21k pre-training, their performances are similar. Only with JFT-300M, do we see the full benefit of larger models.
You can see the scaling below for number of exaFLOPs used in the pre-training step vs accuracy of each of the models.
Vision Transformers generally outperform ResNets with the same computational budget.
If you are wondering why these graphs differ, it’s because showing the model N images is not the same as computational budget. You can think of it as, you can show the ViT more images per second than the ConvNet.
So while the ConvNet may perform better per image shown, the ViT performs better per floating point operation of compute used.
A couple reasons transformers are more computationally efficient than ConvNets:
- Parallelization: Transformers process entire sequences simultaneously rather than sequentially, making them highly parallelizable. This contrasts with CNNs, where the convolution operations often depend on the outcomes of previous layers.
- Global Context: Transformers capture global dependencies in the data through attention mechanisms. CNNs, with their local receptive fields, might require more layers to understand global contexts, increasing computation. For a convolutional neural network to communicate between two far apart regions in the image, you need to stack many layers increasing the receptive field for each one.
The paper notes:
“This result reinforces the intuition that the convolutional inductive bias is useful for smaller datasets, but for larger ones, learning the relevant patterns directly from data is sufficient, even beneficial.”
Scaling Studies
- Vision Transformers dominate ResNets on the performance/compute trade-off. ViT uses approximately 2 − 4× less compute to attain the same performance (average over 5 datasets)
- Hybrids slightly outperform ViT at small computational budgets, but the difference vanishes for larger models. This result is somewhat surprising, since one might expect convolutional local feature processing to assist ViT at any size.
- Vision Transformers appear not to saturate within the range tried, motivating future scaling efforts.
What is the Vision Transformer doing under the hood?
Self-attention allows ViT to integrate information across the entire image even in the lowest layers.
Some attention heads attend to small regions nearby (like the dog ears nose and mouth above) and others can attend to most of the image, even in the lowest of layers.
They can use the attention weights and map them directly back to the image to see exactly what the network finds most interesting when classifying an image.

Self Supervision
They also say there is a lot of opportunities for self supervision where you are masking out patches of the image and trying to predict them. Similar to word embeddings or BERT in NLP.
Conclusion
Unlike prior works using self-attention in computer vision, the do not introduce image-specific inductive biases into the architecture apart from the initial patch extraction step. Instead, the interpret an image as a sequence of patches and process it by a standard Transformer encoder as used in NLP.
This strategy works surprisingly well given a certain scale of dataset. Further scaling of ViT is a promising area of research for many computer vision tasks.
Next Up
To find out what paper we are covering next, join our Discord!

If you enjoyed this dive, please join us next week!

All the past dives can be found on the blog.


The live sessions are posted on YouTube if you want to watch at your own leisure.


Best & Moo,
~ The herd at Oxen.ai
Who is Oxen.ai?
Oxen.ai is an open source project aimed at solving some of the challenges with iterating on and curating machine learning datasets. At its core Oxen is a lightning fast data version control tool optimized for large unstructured datasets. We are currently working on collaboration workflows to enable the high quality, curated public and private data repositories to advance the field of AI, while keeping all the data accessible and auditable.
If you would like to learn more, star us on GitHub or head to Oxen.ai and create an account.
 Oxen-AI
Oxen-AI