Arxiv Dives - Zero-shot Image Classification with CLIP

CLIP explores the efficacy of learning image representations from scratch with 400 million image-text pairs, showcasing zero-shot transfer capabilities across diverse computer vision tasks. This post dives into how it works and will give you an intuition on why it's useful, and how it can be applied in your own work.
What is Arxiv Dives?
Every Friday at Oxen.ai we host a paper club called "Arxiv Dives" to make us smarter Oxen 🐂 🧠. We believe diving into the details of research papers is the best way to build fundamental knowledge, spot patterns and keep up with the bleeding edge.
If you would like to join the discussion live, sign up here. Every week there are great minds from companies like Amazon Alexa, Google, Meta, MIT, NVIDIA, Stability.ai, Tesla, and many more.

The following are the notes from the live session. Feel free to watch the video and follow along for the full context.
Intro
This week we are going over CLIP paper which stands for “Contrastive Language-Image Pre-training”. It is an interesting one, because while it talks a lot about “zero shot image classification” it is also the backbone for a lot of the many of the generative image and video systems we see out there today like Dalle or Stable Diffusion.
Paper: https://arxiv.org/abs/2103.00020
GitHub: https://github.com/OpenAI/CLIP
Paper Published: Feb 26, 2021
Team: OpenAI
CLIP + Image Classification
The CLIP model consists of a Language Transformer and a Vision Transformer. We have covered how Transformers work in past dives, so will not dive into them much here. If you want to learn more about Transformers check out our dive into the Attention Is All You Need paper or Vision Transformers. They are both building blocks for CLIP.
 Greg Schoeninger
Greg Schoeninger Greg Schoeninger
Greg SchoeningerIn this paper, they apply CLIP to the task of image classification.
Image classification can be used for many use cases such as automatically tagging and sorting through large sets of images. Filtering out content based off of a class. Recommending Ads based on user generated data. Analyzing video frame by frame to find interesting sections.
The problem with a lot of image classification models is they are limited to a fixed set of categories. If you want to detect an object that is not in the original training data, you have to retrain the model and teach it about the new category.
The main takeaway of the CLIP paper is: The CLIP allows you to predict without a fixed set of categories and is only limited by what a language model knows about the world.
Comparing to ViT
To make the benefits of not having a fixed set of categories concrete, I posted some results from evaluating CLIP and evaluating a Vision Transformer here:

I tried Google’s Vision Transformer from last week’s dive on the Oxford Pets dataset from the paper.
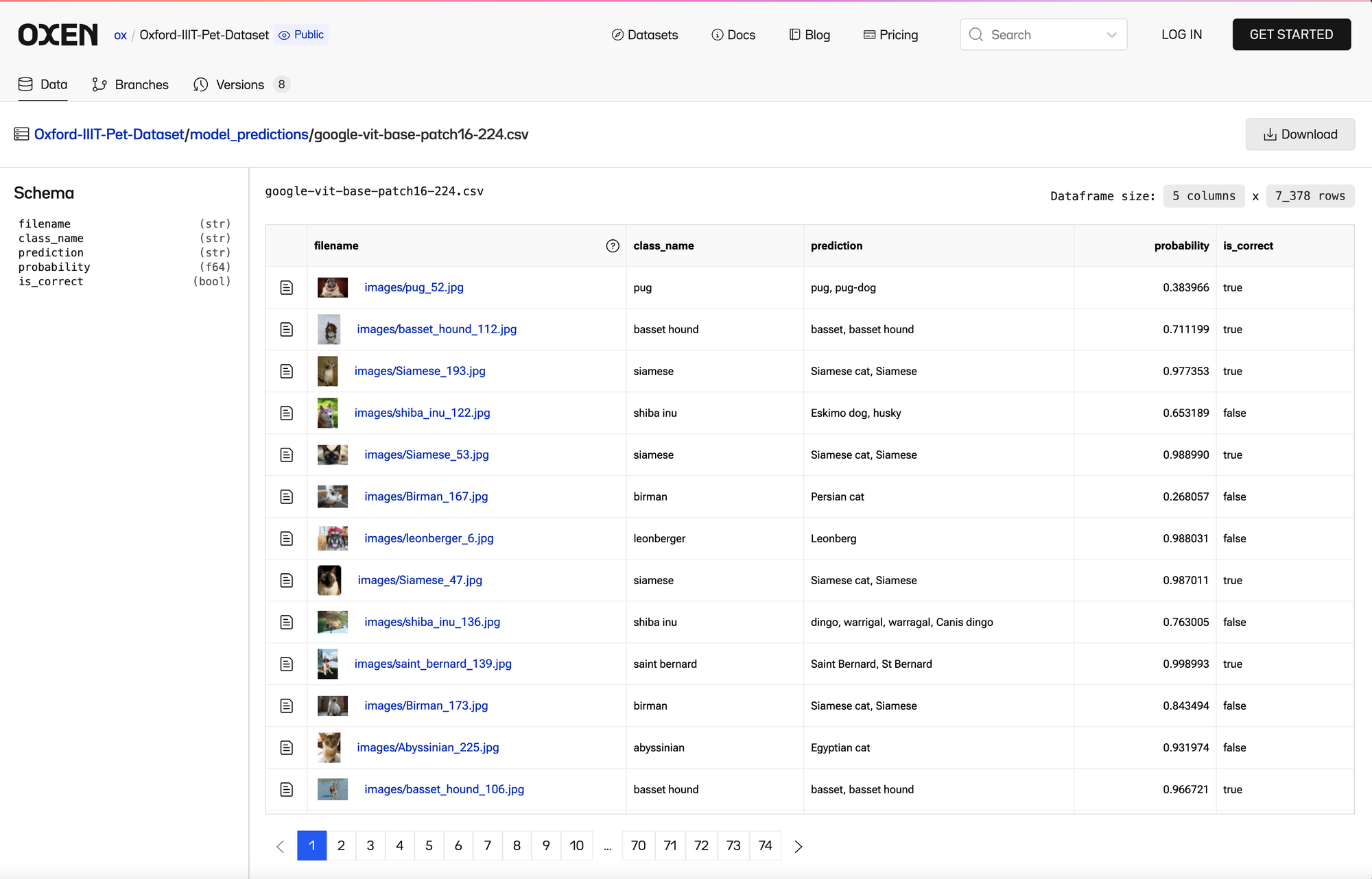
If you look closely at the prediction column, you can see how the ViT does not have the correct set of classes and gets a pretty low accuracy. For example: "birman" != "siamese cat" and "shiba inu" != "dingo". ViT was trained on ImageNet which has thousands of classes, but they might not be the exact classes of objects you are interested in.
Granted, there are some pretty obvious things we could do to fix some of these, like a dictionary of mapping terms, but if you do a raw case insensitive string compare on the output classes trained on image net the accuracy of ViT on this dataset is only 3204/(3204+4174)=43%.
CLIP Evaluation
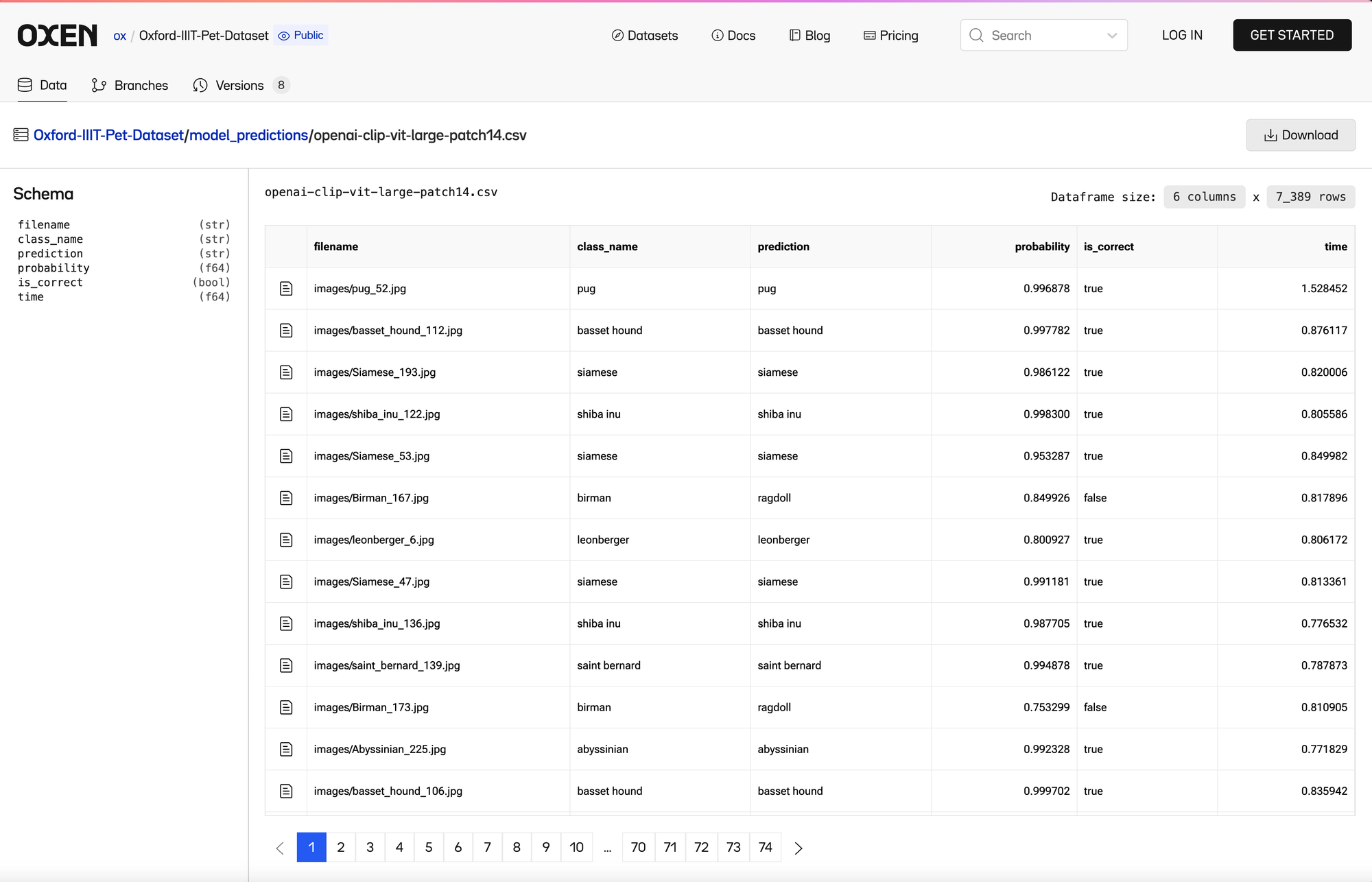
CLIP let's you as the user define the labels. Instead of being locked into a fixed set of categories, you could use any words in the english language you can think of as class labels.
I ran the same dataset with CLIP where I put in all the 37 class labels manually, you can see it bumped the accuracy up to 91%! This is remarkable because you could do this in theory with any set of categories and not have to collect data or retrain the model.
6786/(6786+603)=91% CLIP
Practical Dive
If this all still sounds abstract, next week in a more practical dive. We will show you how to write the code to actually run these models on your own datasets, and play around with them live. You can join us live with the link below:

We can talk about the models all we want, but seeing them run on actual data is where the practical insights are. How many frames per second can be processed, how accurate is it for my particular use case? These are the topics we will dive into in Practical ML Dives.
Large Pre-training Datasets
Inspiration was taken from GPT-3 to do a large pre-training and see if the model can be applied to downstream tasks with N-shot learning. They use a simple pre-training task of predicting which caption goes with which image to learn image representations.
They create a dataset of 400 million image->text pairs crawled from the internet for this pre training task.
You can think of these as the “alt” text on HTML image tags, but they don’t go too deep into the data collection process itself.
https://www.amazon.com/Generative-Deep-Learning-Teaching-Machines/dp/1098134184
After pre-training this model (CLIP) can then generalize to over 30 different computer vision tasks.
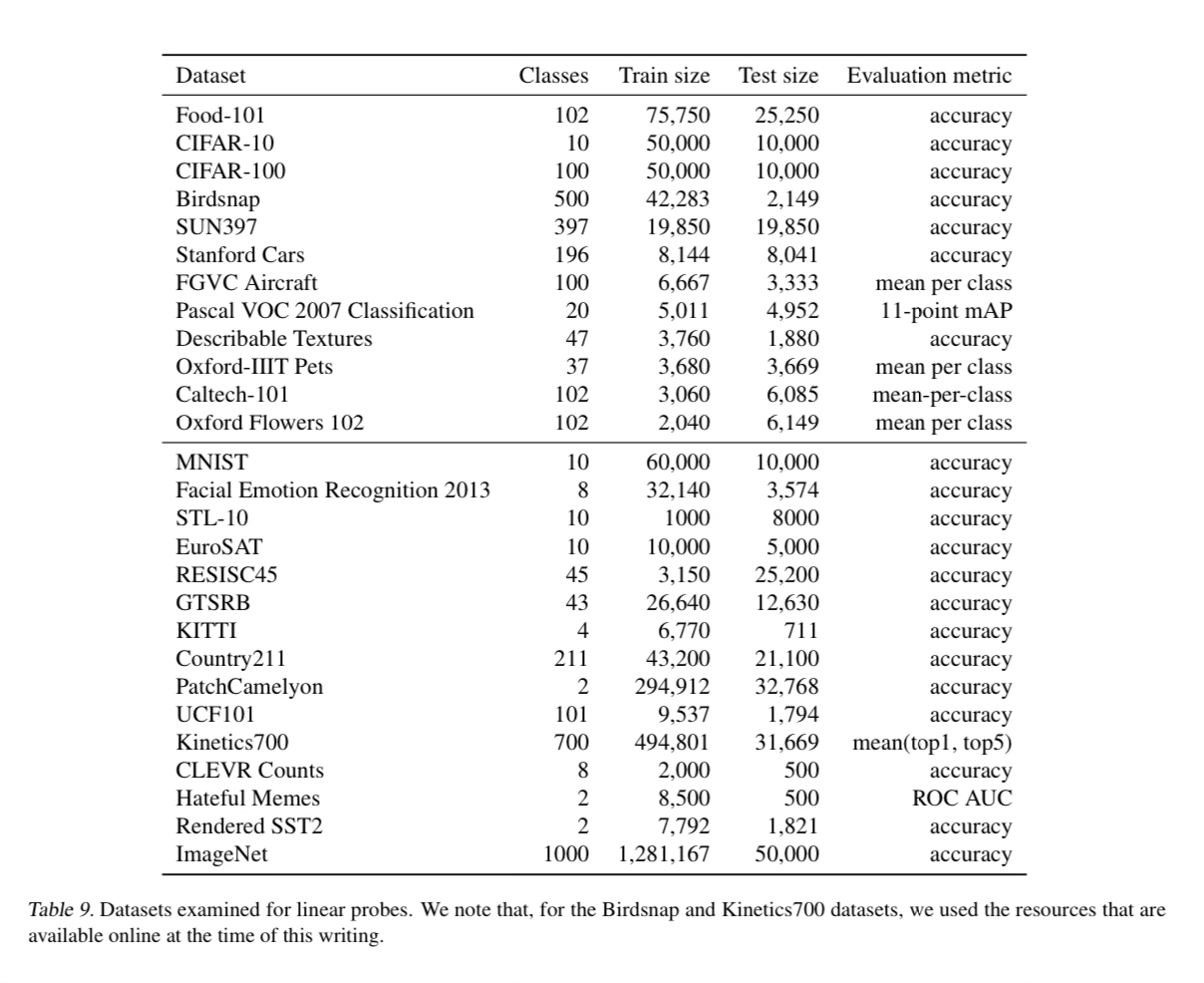
They match the accuracy of ResNet-50 on ImageNet with zero shot without using any of the 1.28 million images it was trained on.
Approach
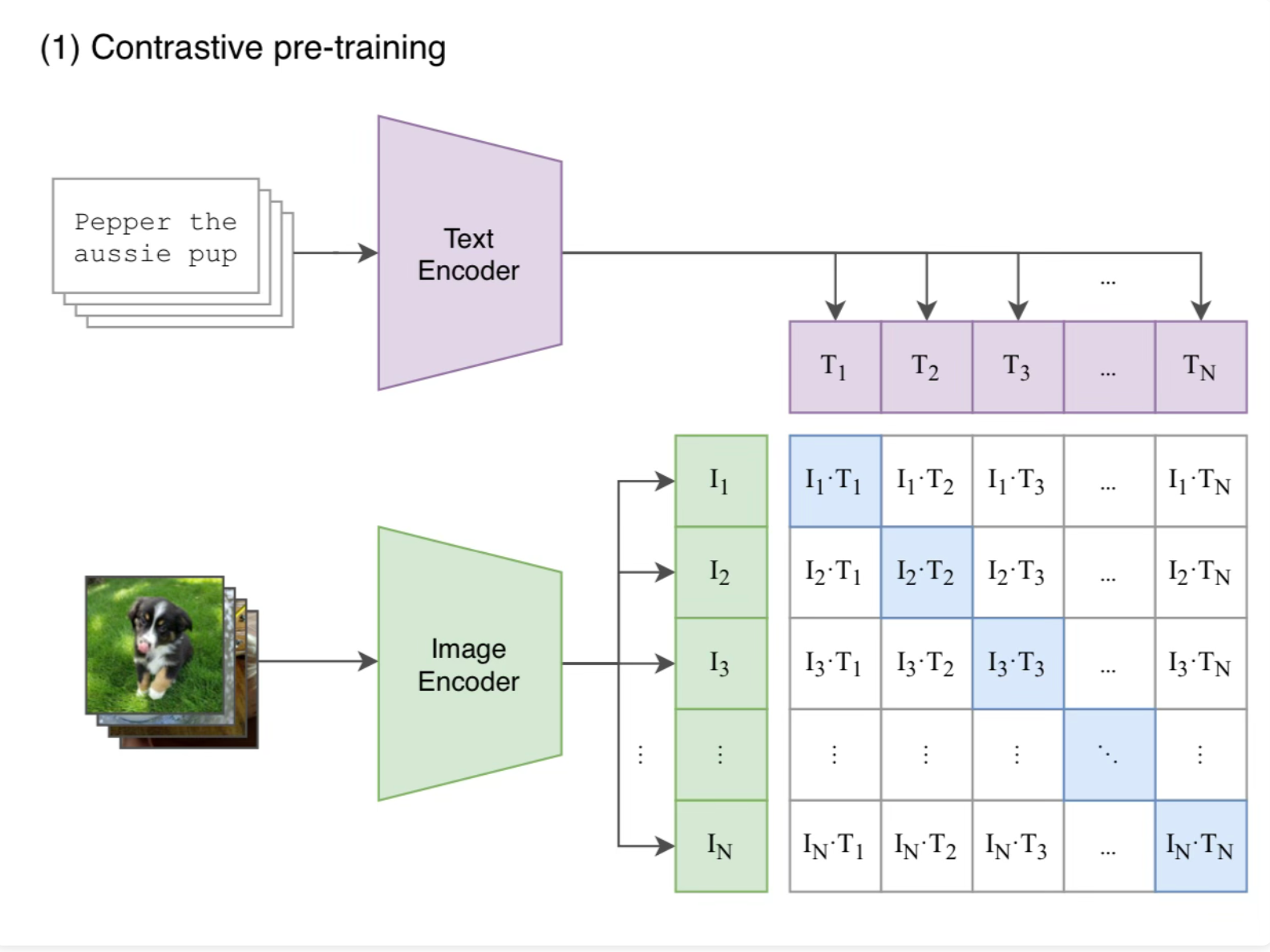
Jointly train an image encoder and a text encoder to predict correct pairings of a batch of text and images.
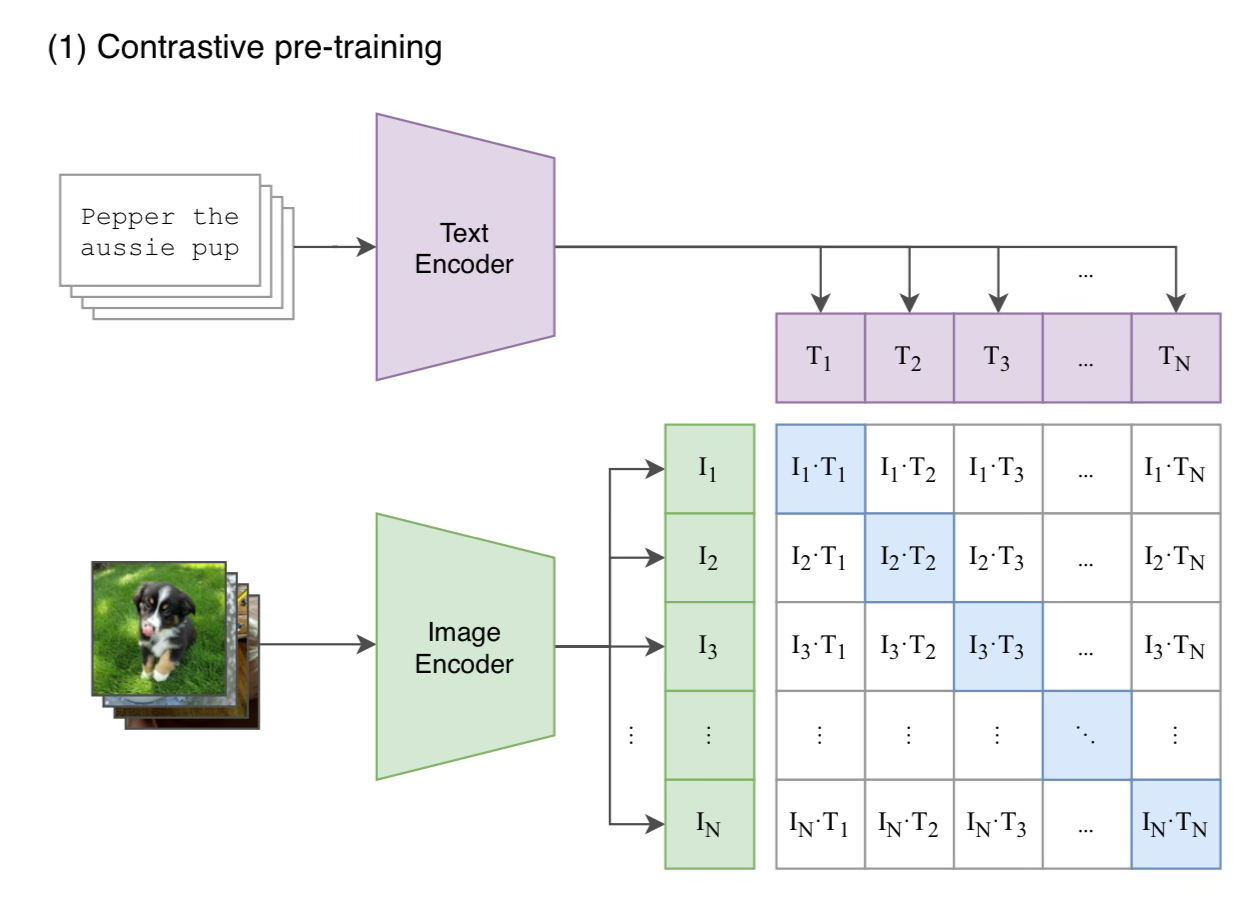
The Training Objective
This is a key insight into how the model works. Given a set of NxN image and text pairs, they jointly train the two models to maximize the cosine similarity of the N image-text pairs that match. They minimize the cosine similarity between the N^2 - N incorrect pairings.
Look at the blue diagonal, those are the correct pairings, we are optimizing for a cosine similarity of 1.0. They then use a symmetric cross entropy loss over each batch.
This is where the name “CLIP” comes from. Contrastive Language-Image Pre-training. They are contrasting image and text pairs.
Note: you are counting on randomness in the dataset to assume all the other images in a set do not line up with the text. There is a very low chance that if you take a random image and a random piece of text, they will align to each other.
Inference
Then at test or inference time, you take the text encoder and have it encode N sentences depending on your N classes you want to choose.
“A photo of a dog”, “A photo of a plane”, “A photo of a car”
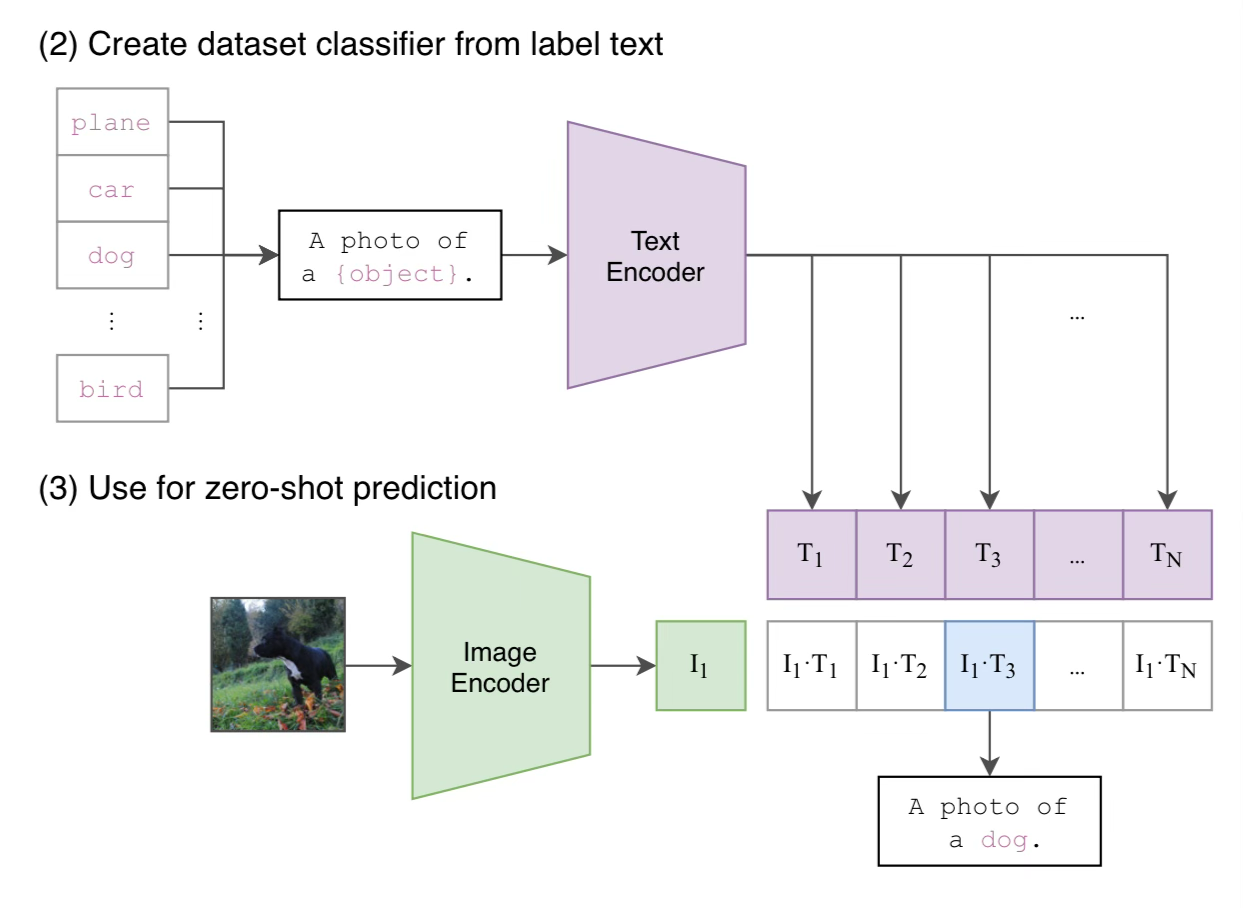
Then the image encoder encodes the image, and you take the cosine similarity between each encoded piece of text, and the image.
The encoded piece of text with the highest cosine similarity to the image embedding, is the classification.
They claim that learning from natural language captions has the benefits of scaling the dataset without requiring gold standard data, as well as the fact that now the data has more nuanced examples of language within it.
Creating a Sufficiently Large Dataset
To create this dataset, they generate 500,000 queries and require the text to include some of the query. The queries were generated from the English version of Wikipedia, with words or bigrams that appeared at least 100 times.
They try to balance the dataset by making sure there are 20,000 image, text pairs per query.
Overall, they don’t go into much details about the full dataset creation process, but the dataset is called WIT for WebImageText. It is another example of a dataset that is not open, so it is hard to reproduce or tell exactly how they collected the data.
Image and Text Models
Image Encoders
They try two different image encoders
- ResNet-50
- ViT
They end up training 5 ResNets and 3 Vision Transformers.

Text Encoder
For the text encoder they use a 63M parameter 12-layer transformer with 8 attention heads and 512 dimensional representation.
They use a vocab size of 49,152 lower cased byte pair encodings (BPE) and for computational efficiency cap the sequence length at 76.
The largest ResNet model took 18 days to train on 592 V100 GPUs while the largest Vision Transformer took 12 days on 256 V100 GPUs.
They say the best CLIP model used ViT-L/14@336px. For more info on what all this notation means, check out the ViT Arxiv Dive.
Experiments
When they say “zero-shot” they mean having the model generalize to unseen object categories in image classification.
They even broaden the term to mean how well does it generalize to “unseen datasets”. For example, CLIP can generalize to sketches of bananas far better than a ResNet101 just trained on ImageNet.

In their setup, in order to perform zero-shot classification, they use the names of all the classes in the dataset as the set of potential text pairings given each image.
CLIP blows previous attempts at zero shot classification out of the water.
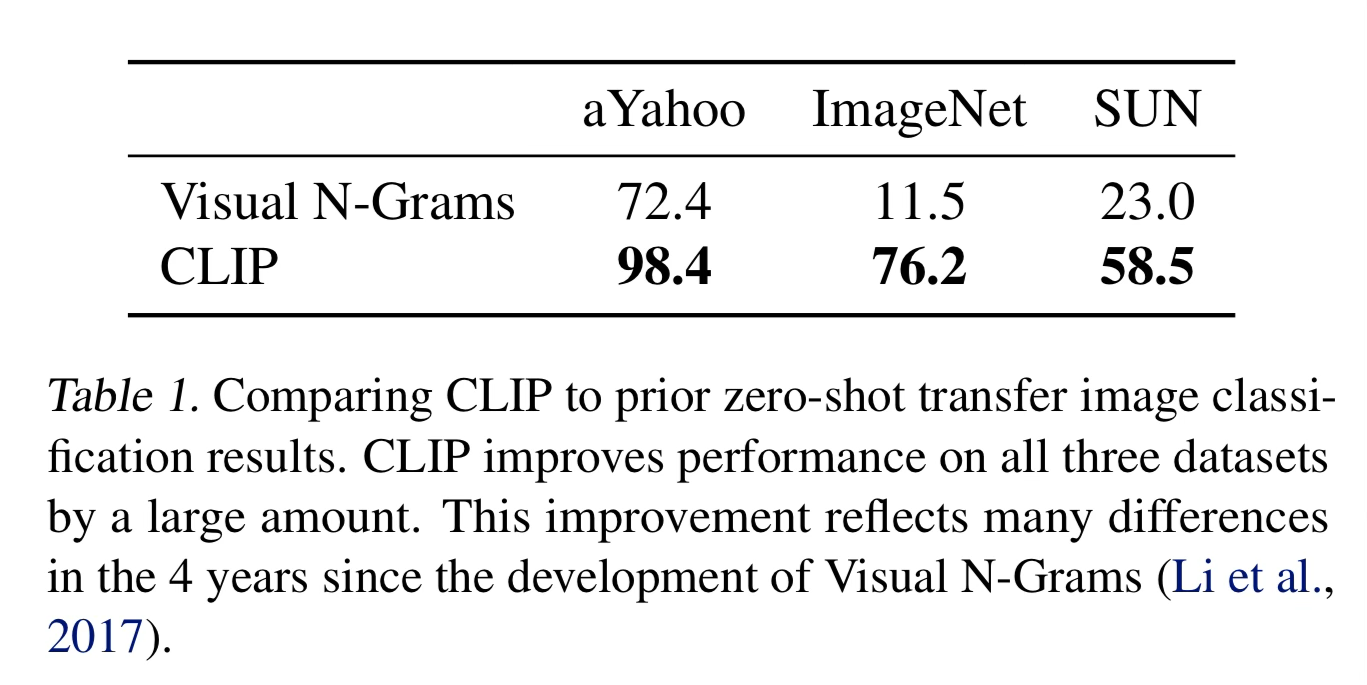
They state that part of the reason for the giant leap in performance that is not controlled for in these numbers is:
- 10x larger dataset
- 100x more compute per prediction (model parameters)
- 1000x more compute during training
Best footnote of the paper award goes to:

Polysemy
A common issue with zero-shot transfer is called “polysemy” which we may recognize from our NLP research.
Since we did not train on this dataset, the text encoder does not have context into what a word might mean given this dataset.
In ImageNet, multiple meanings of the same word might be included as different classes in the same dataset.
For example construction “cranes” and “cranes” that fly. Or in the Oxford-IIIT Pet dataset where the word “boxer” is, from context of the dataset, clearly a dog. But the text encoder lacking context could just as likely refer to a type of athlete.
Prompting Engineering a Label
Specifically they classify the image by creating a short sentence with the label, rather than just the label itself. This alone improved accuracy 1.3%.

For some datasets they help disambiguate the zero-shot task even further with more context in the prompt.
For example with the Oxford-IIIT dataset of pets, to solve the problem of Boxer 🥊 != Boxer 🐶 they change the prompt to:
“A photo of a {label}, a type of pet”
For satellite image datasets they said “a satellite photo of a {label}” and for OCR they put quotes around the text or number to be recognized.
You can also create an ensemble of zero-shot classifiers by having multiple prompts and average the embeddings.
“A photo of a small {label}”
“A photo of a large {label}”
On ImageNet, we ensemble 80 different context prompts and this improves performance by an additional 3.5% over the single default prompt discussed above.
Comparison to Logistic Regression
They compare zero-shot CLIP to a logistic regression on ResNet features and find it outperforms ResNet when ResNet is fine-tuned with a linear layer on the dataset.
If you are not familiar with adding a linear layer and classification on top of a model, it is a very small amount of code to do so, it’s just adding a sequential Linear layer on top of the one of the final layers of output.
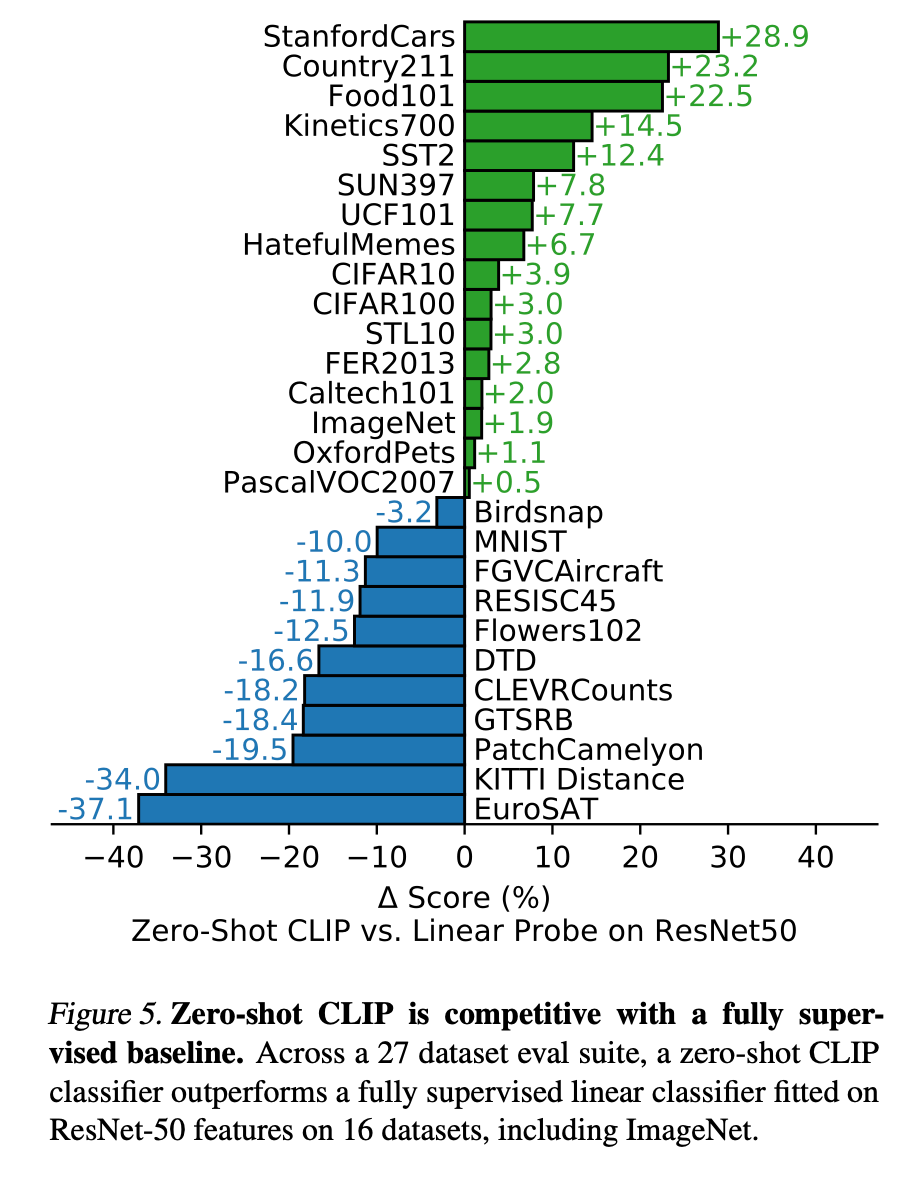
CLIP does better on datasets like Kinetics700 and UFC101 due to natural language providing wider supervision for visual concepts involving verbs, compared to the noun-centric object supervision in ImageNet.
CLIP is quite weak on several specialized, complex, or abstract tasks such as satellite image classification (EuroSAT and RESISC45), lymph node tumor detection (PatchCamelyon), counting objects in synthetic scenes (CLEVRCounts), self-driving related tasks such as German traffic sign recognition (GTSRB), recognizing distance to the nearest car (KITTI Distance).
This makes sense if you think of how the “Web Image Text” WIT dataset was created. There are just less examples out there of lymph node tumor detection and satellite images with nice alt text labels on the web than of generic object categories or of humans performing actions.
The fact that it performs the best on cars probably says something about people sharing photos car of their cars online with great descriptions.
Zero-shot clip out performs few-shot with many architectures. Surprisingly zero-shot CLIP is even better than a 1,2,3 shot logistic regression on the feature space from CLIP itself.
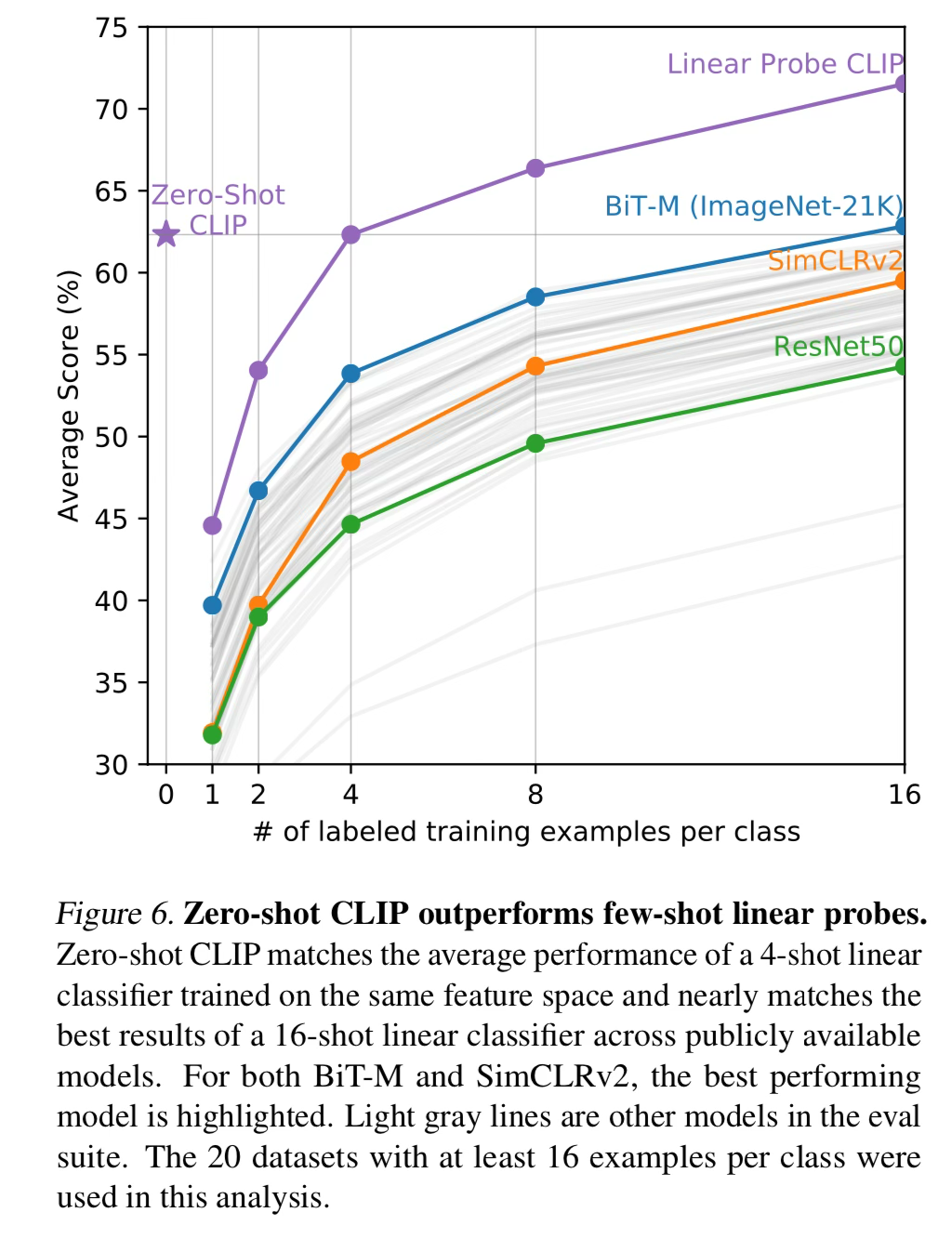
It is wild that Zero-Shot clip out performs few shot examples with a linear layer.
They hypothesize this is because you can add extra information in a zero-shot prompt via natural language to disambiguate categories. As far as I understand it, the zero shot classifier has the benefit of using the language model as well as the vision model, whereas few shot only uses a logistic regression on the image model.
Also the fact that a single image often contains many different visual concepts means you need to pick a very good representative example image without many other objects that could confuse the classifier.
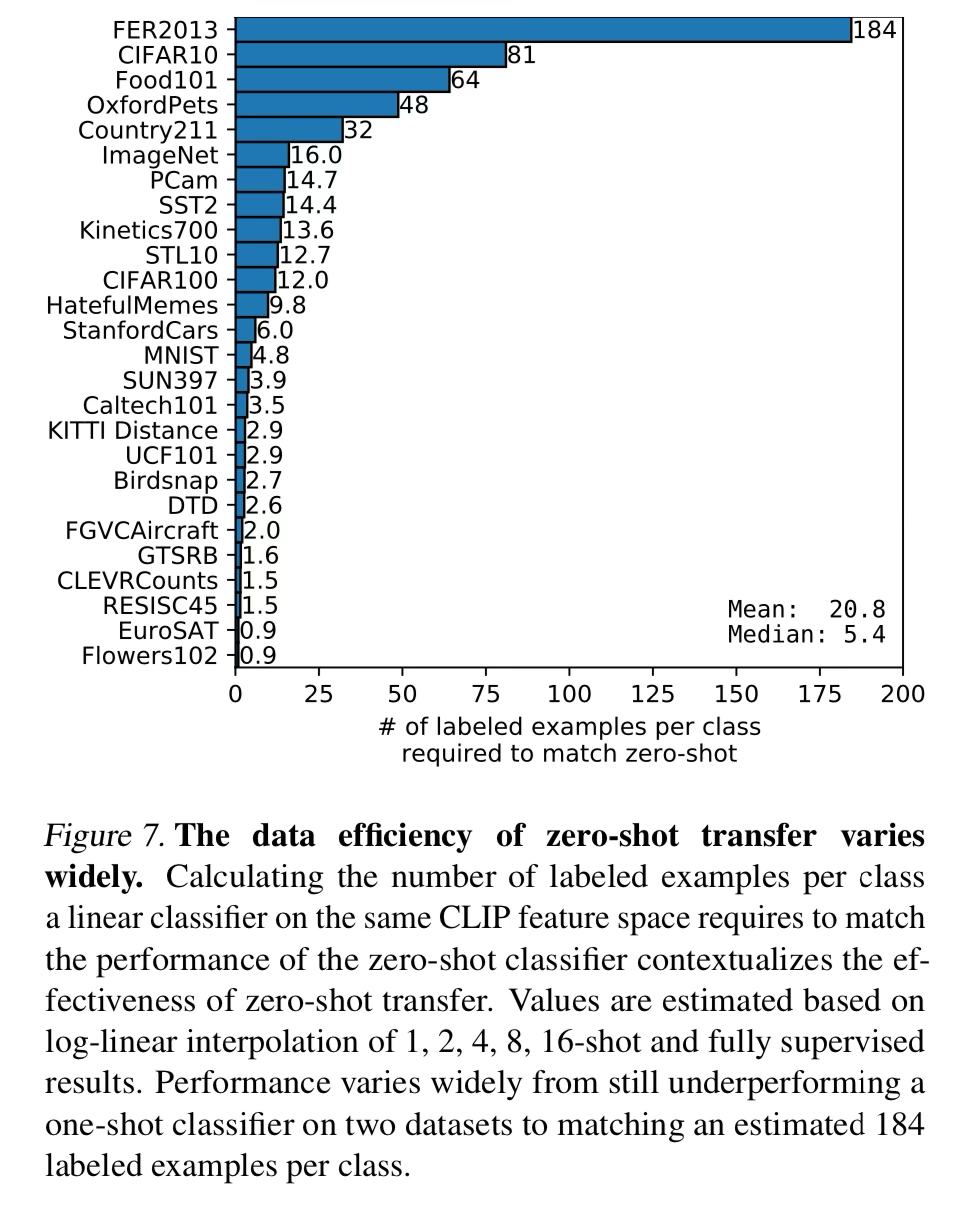
The number of examples needed to match performance of the zero shot classifier.
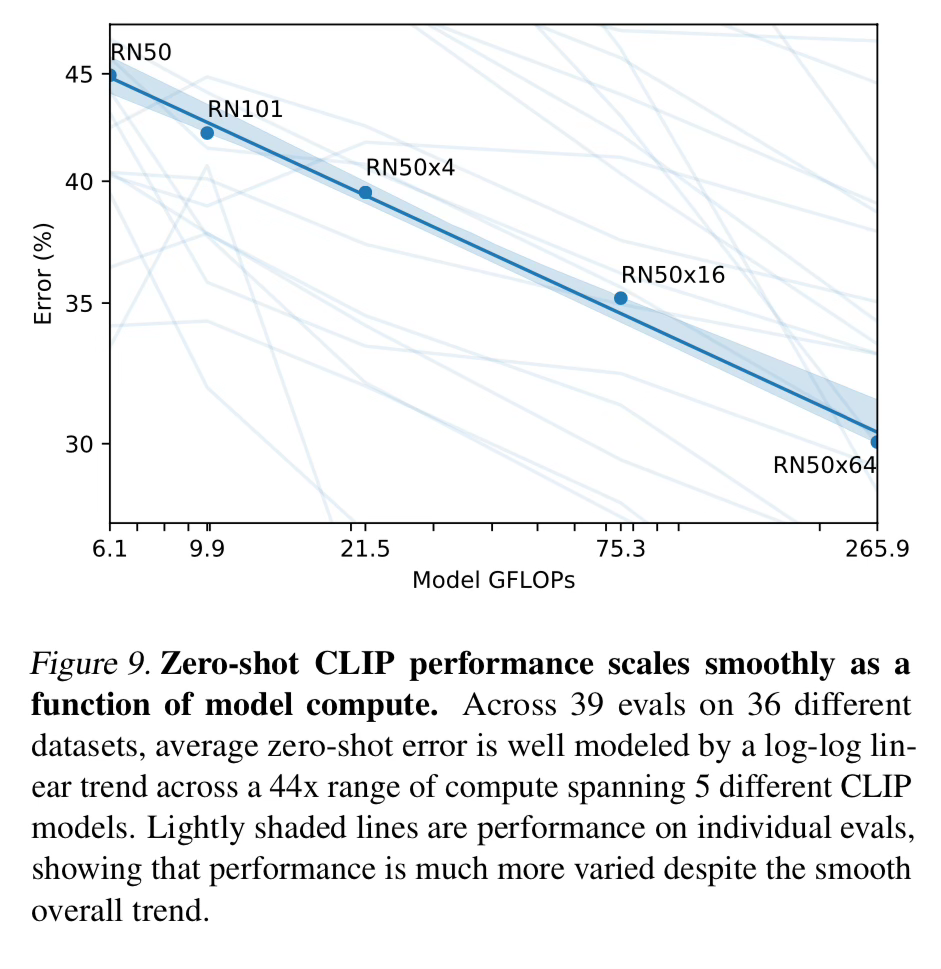
They also show that there is a predictable function of performance of the zero shot CLIP model given more compute. The performance on individual evaluations can be noisy but if you average them out, the more compute the lower the error rate.
Comparison Against Human Performance
They look at human performance on the oxford pets dataset and show that CLIP outperforms humans.
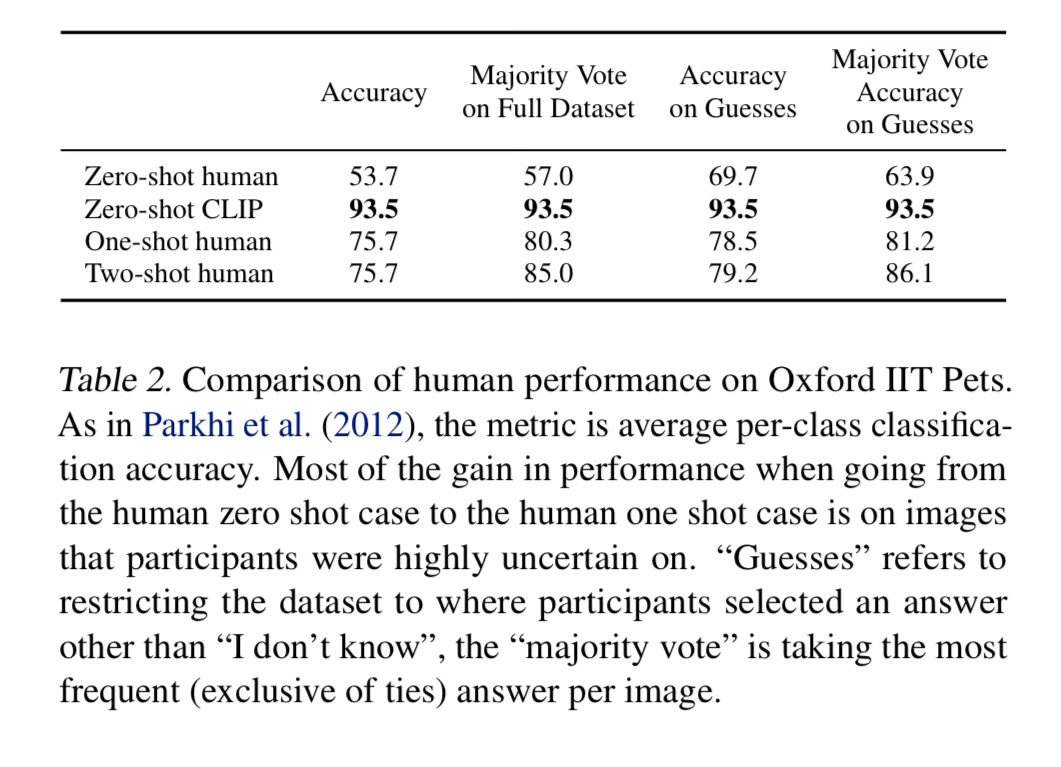
It crushes us humans given the same task. To be honest I don’t know if you could show me one example per class and I could do it, I don’t have enough background knowledge of cats breeds.
It’s also not completely fair because who knows how many times the CLIP model saw that cat breed in pre-training. I would love to do a quick grep on it, if we had access to the pre-training dataset.
Broader Impacts
CLIP makes it easy to create your own classes for categorization or “roll your own classifier”.
This is great news for quickly building downstream applications, such as action recognition, object classification, facial emotion recognition, etc, but has implications for surveillance and privacy and fairness.
There are interesting diagrams and studies on race, gender, and social harmful labels such as comparing humans to animals or what demographics are more associated with crimes given the data at the end of the paper if you want to dive in more.
Conclusion
While we talked a lot today about classification, remember CLIP is the backbone for many of the generative image techniques.
Being able to embed images and language into the same embedding space, where the cosine similarity of a sentence and an image are very close, allows us to translate between the text domain and image domain smoothly, which is very important when thinking about how to build Multi-Modal models.
Next Up
Thanks for sticking around this far! To find out what paper we are covering next and join the discussion at large, checkout our Discord:

If you enjoyed this dive, please join us next week!

All the past dives can be found on the blog.

The live sessions are posted on YouTube if you want to watch at your own leisure.


Best & Moo,
~ The herd at Oxen.ai
Who is Oxen.ai?
Oxen.ai is an open source project aimed at solving some of the challenges with iterating on and curating machine learning datasets. At its core Oxen is a lightning fast data version control tool optimized for large unstructured datasets. We are currently working on collaboration workflows to enable the high quality, curated public and private data repositories to advance the field of AI, while keeping all the data accessible and auditable.
If you would like to learn more, star us on GitHub or head to Oxen.ai and create an account.
 Oxen-AI
Oxen-AI