How We're Building a “Tab Tab” Code Completion Model


Welcome to Fine-Tuning Fridays, where we share our learnings from fine-tuning open source models for real world tasks. We’ll walk you through what models work, what models don’t and the data we used to make them improve performance.
Today we will be going over how to fine-tune an LLM that understands the code that you are writing, and predicts the next edits. If you’ve ever wondered how the LLMs behind Cursor work under the hood, you are in the right place. If you want to join the community and discuss fine-tuning in general, feel free to hop in our Discord.
Want to try fine-tuning? Oxen.ai makes it simple. All you have to do upload your images, click run, and we handle the rest. Sign up and follow along by training your own model.
The Task: "Tab Tab"
Why is it called “tab tab”? If you’ve used Cursor before, you are likely very familiar with the “Tab” key to accept the next edit and then using the "tab" key again to go the next location in the file. Tab once, tab again.
We are partnering with Marimo to bring a similar experience to their notebooks. If you haven't used a Marimo notebook before, it's like a Jupyter Notebook, but better. You can spin one up on a GPU in Oxen.ai in seconds if you want to play around. In the spirit of building in public we will be documenting the results, code, models and datasets as we go along.
Oh yeah, and Marimo's going to be offering this model free...so not only will you learn how to fine-tune your own code-completion model here, but you can try it for free through our notebooks.
Use Case Specific Constraints
With the use case of Marimo notebooks, this gives us some nice constraints.
- Fast - Must keep up with typing, small enough to run locally
- Open Source - Allow anyone to download and run it
- Python Only - Limiting the scope to python notebooks
- Accurate - Must actually be useful in our day to day workflows
Our plan is to release a set of small models to the community that you can run via our API our locally through Ollama.
🧪 The Formula
Everyone wants to start with the training. But I’d say stop right there cowboy 🤠. No matter how confident you are, the chances that your data is properly prepared is low. It’s going to be more valuable to get some eval reps with existing models before you dive head first into fine-tuning. You want to have an eval dataset and a baseline with SOTA models so we have a clear number to improve on and a dataset to test your model against. I've made to many runs where I excitedly jump right into fine-tuning and always regret it when I have no clear way to evaluate the model or number to beat.
The ideal flow looks like this:
- Define your task (”Fill-in-the-middle” in this case)
- Collect a dataset (train and test sets)
- Evaluate closed source models to get a baseline
- Fine-tune the open source models
- Eval the fine-tuned models
- Declare a winner 🥇
We're evaluating and fine-tuning several Qwen, GPT, Llama, Claude, and Kimi models and will show the results at the end.
Vibing with a SOTA Model
First we gave the foundation models the following prompt and chatted with them just to play around with them and get a vibe of their performance using our chat feature.
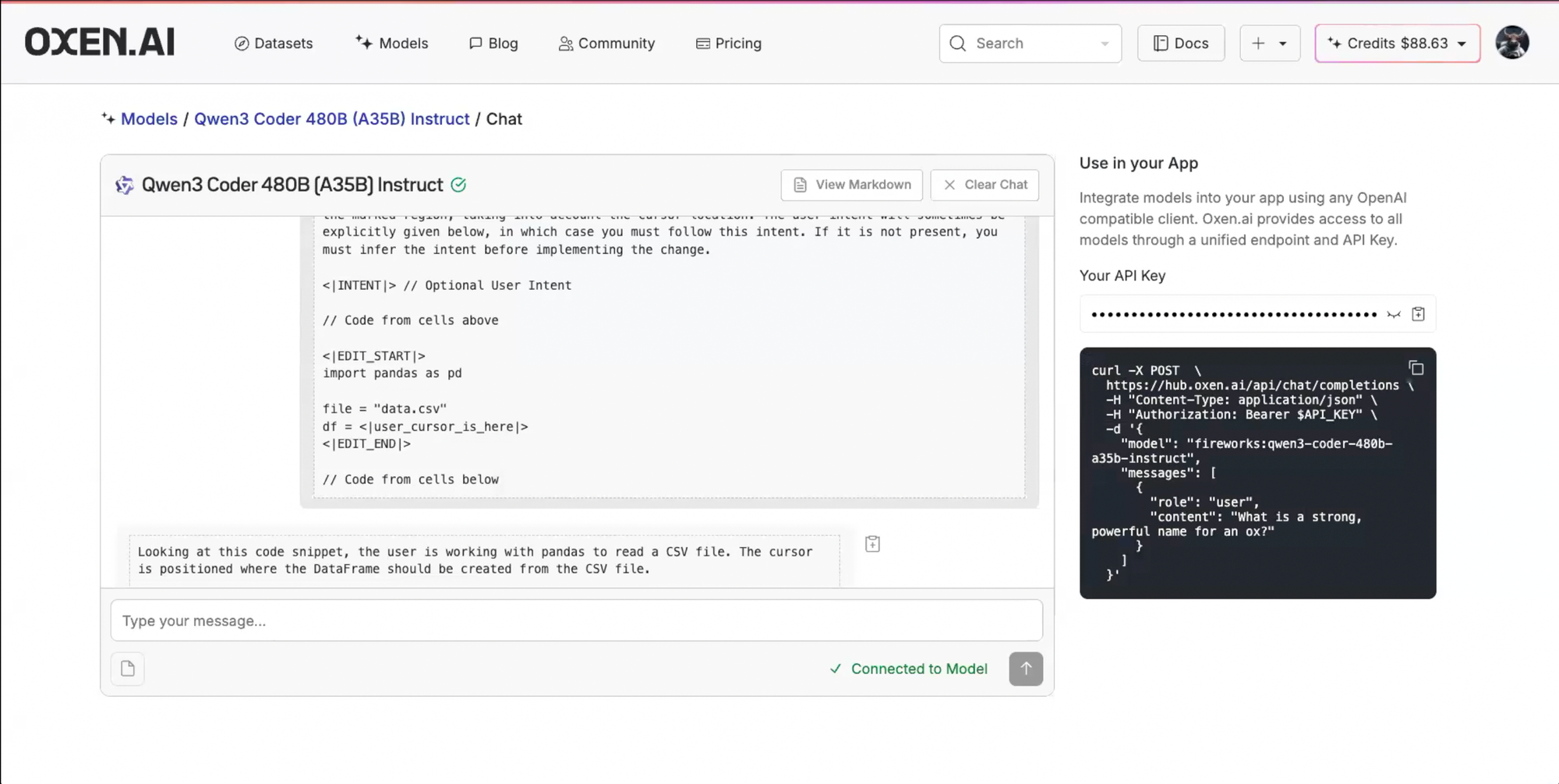
You are a code completion assistant and your task is to analyze user edits and then rewrite the marked region, taking into account the cursor location. The user intent will sometimes be explicitly given below, in which case you must follow this intent. If it is not present, you must infer the intent before implementing the change.
<|INTENT|> // Optional User Intent
<|EDIT_START|>
import pandas as pd
file = "data.csv"
df = <|user_cursor_is_here|>
<|EDIT_END|>
// Code from cells below
<|INTENT|> Read in a csv file using pandas
<|EDIT_START|>
import pandas as pd
file = "data.csv"
df = pd.read_csv(file)<|user_cursor_is_here|>
<|EDIT_END|>
There are a few important pieces of our raw prompt and response. First we have an optional <|INTENT|> block in the input that allows the user to put in their intent for the edit. This is nice for "Command K" style edits of a code block. You will also see the <|INTENT|> block in the output. The model is explicitly trained to output it's intent before responding. This can be thought of as "think" tokens so that the model can plan a little before making the edit. It also makes the edit a little more debuggable. The idea is that the intent that the model predicts can also be show to the user and the user can help course correct.
Second, you will notice the <|user_cursor_is_here|> token. This is provided in the input to specify where the user wants to make the edit, and in the output to place the cursor for the next edit.
Datasets
We make the Fine-Tuning half easy so preparing the data is where you’ll spend most of your time (which is where it should be spend tbh).
Eval Datasets
Let’s start with a dataset that a lot of folks use for evaluating coding models: Mostly Basic Python Programming or MBPP.

This data looks like a prompt, a python function, and unit tests that the function must pass.
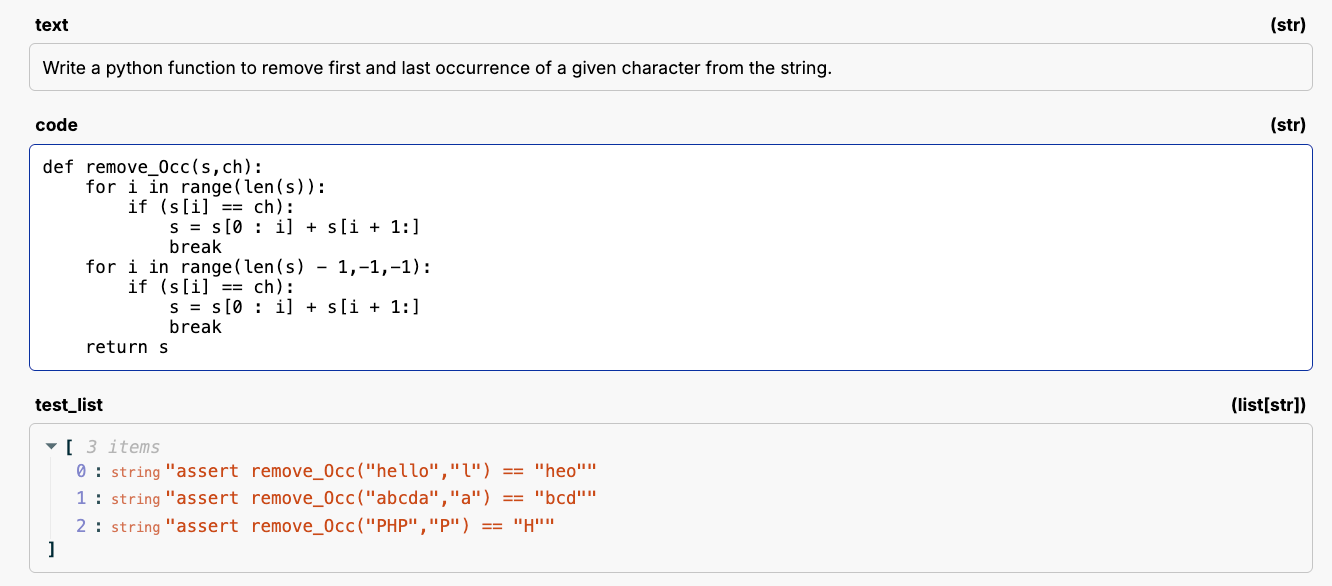
For this specific eval, we corrupted all the functions by removing random pieces of code, and placing the <|user_cursor_is_here|> token at the start of the removal.
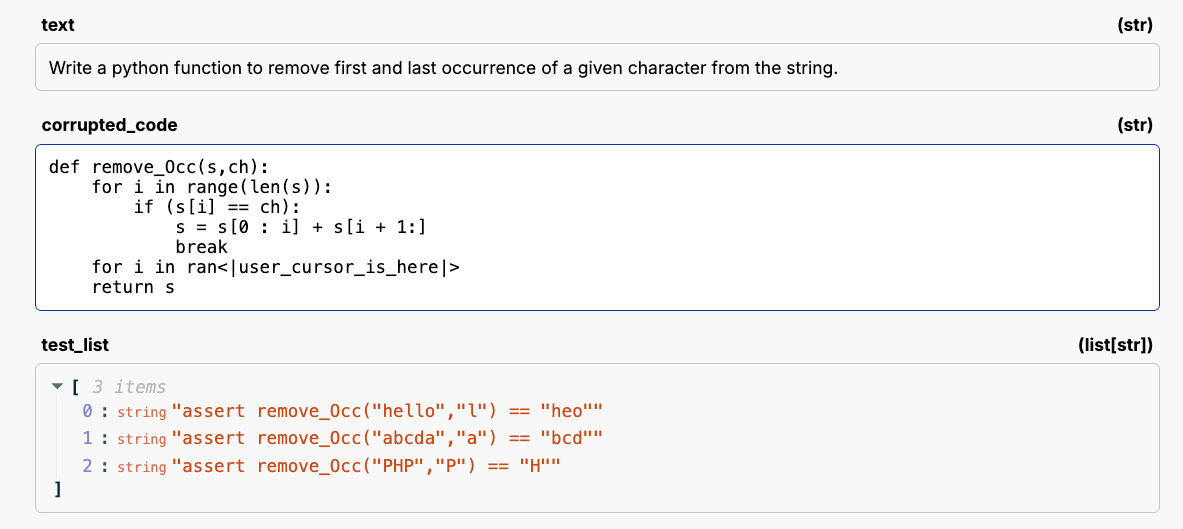
The LLM's job is then to fill in the function, given the cursor position, and pass the unit tests. When this eval we found these models performed perfectly/almost perfectly…which always makes me skeptical.
- Claude 4 Sonnet: 100%
- Llama 4 Scout: 97%
Especially considering the functions had a funky naming convention...a mix of snake_case and camelCase:

After looking a little deeper into the input outputs we found the model had just memorized the answers.
To combat this, I had an LLM rewrite all of the variable and function names. I used GPT-4o to simply rename the function and variable names, then ran all the unit tests again to verify the LLM didn't hallucinate. Here is an example of before and after the renaming.
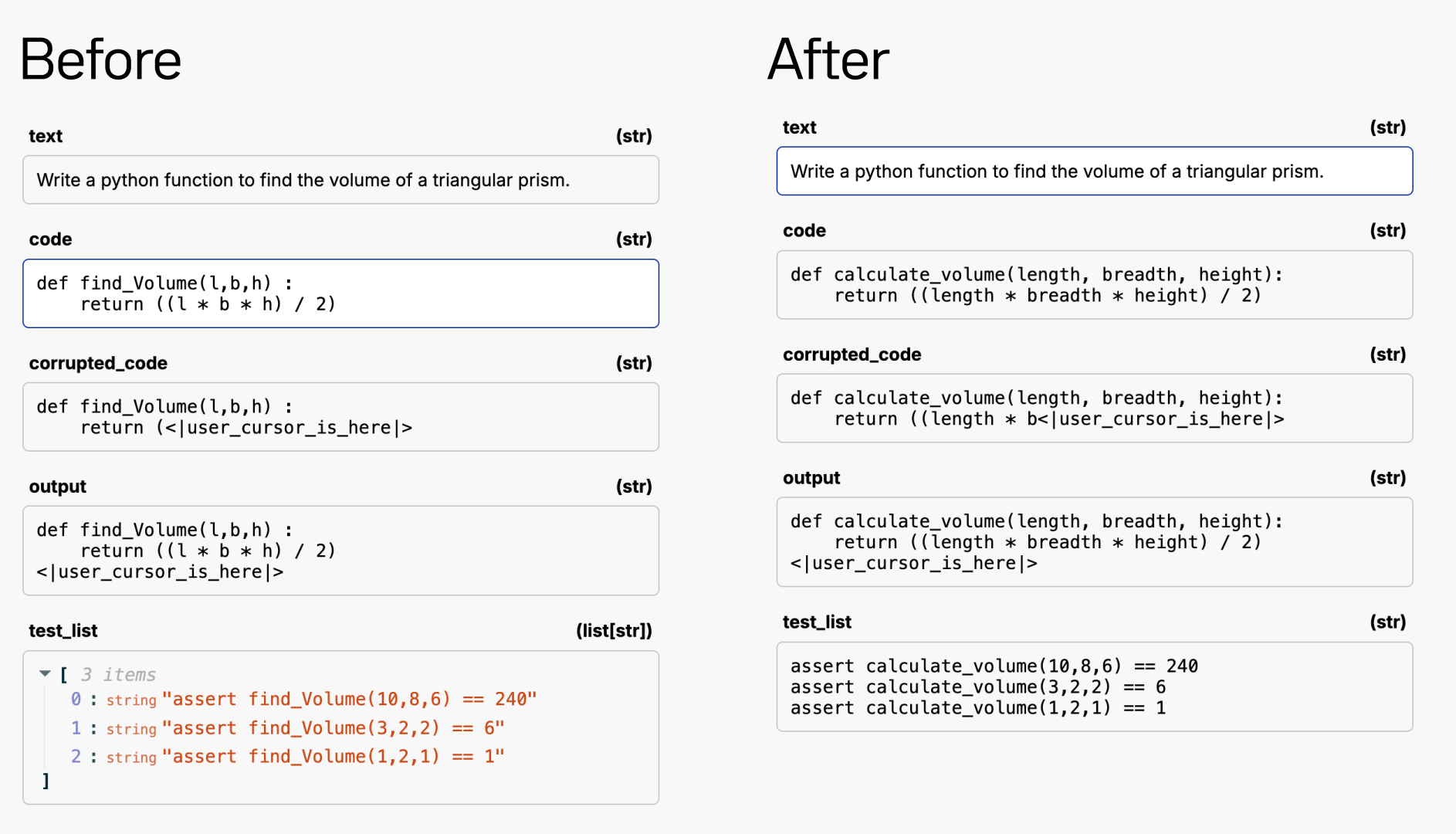
After verifying all the unit tests still passed, I reran Claude and Llama through the dataset and the results were very different:
- Claude 4 Sonnet: 100% → 82%
- Llama 4 Scout: 97% → 68%
Claude dropped 18% and Llama 29%! ~30% is a big drop in performance. To be fair to the labs, if the dataset is out there, the models have probably been trained on it and they can't check everything thats in the pre-training data. So be careful with the data your are evaluating on. The best data is a private dataset and benchmark that you own and never leaks to the internet.
Training Data
Between GitHub and Common Crawl there is no lack of code out there for us to collect a training dataset. The main question is how do we get realistic looking edits? The most simple baseline we could think of was to apply the same corruption we did for evaluation to random chunks of code, then have the model reconstruct them from the ground truth.
We ran the corruption on three different datasets: the MBPP dataset, python instructions 18k Alpaca, and the Marimo codebase itself. The Marimo codebase was the most interesting to gather. We went though their PRs and took the code in the diffs, took that, corrupted a bit of it, and put the PR comment as the intent:
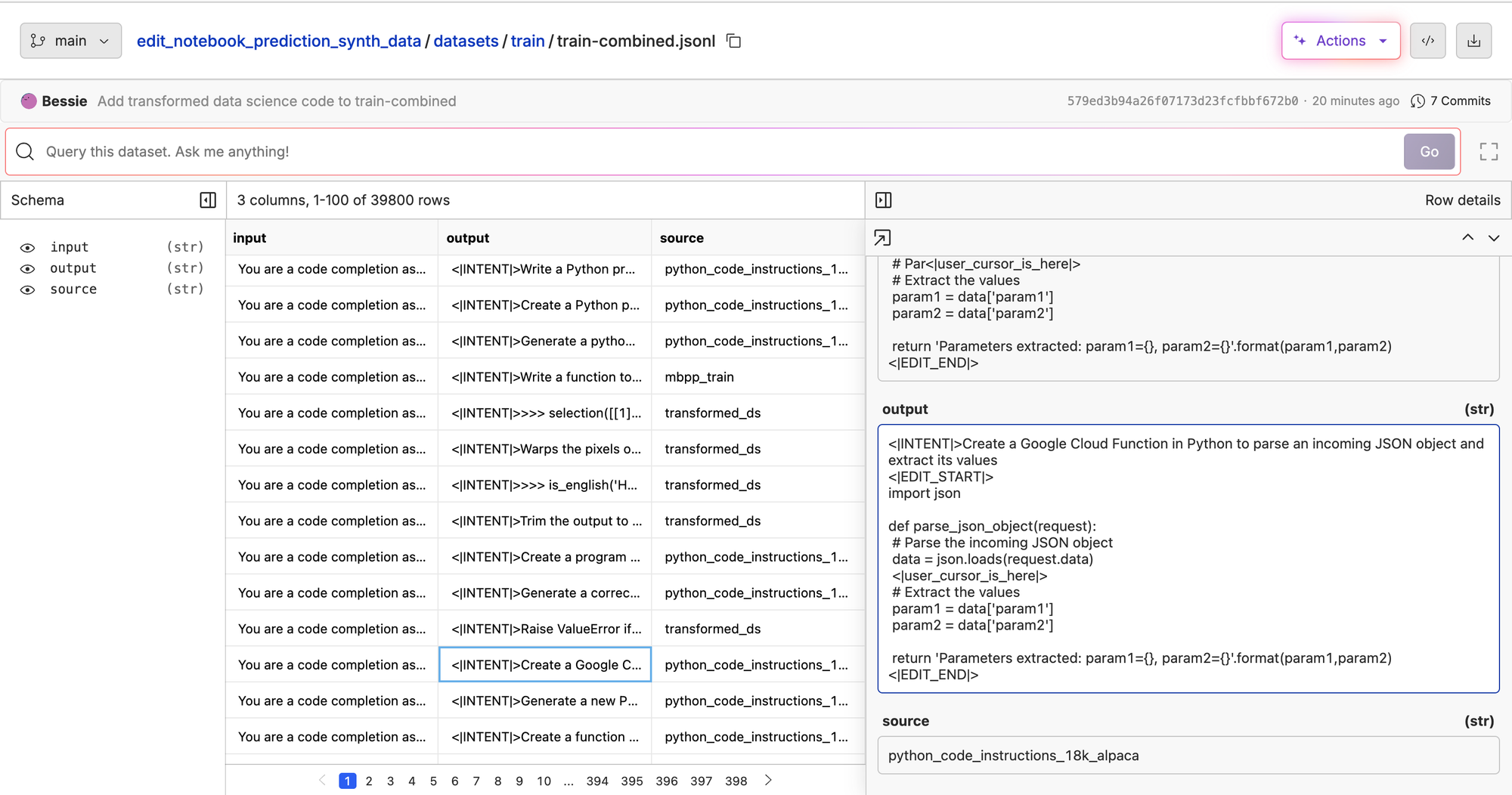
This will give us a good baseline we can report numbers against, but we plan on extending this data by using more advanced data corruption pipelines. Techniques like looking at the abstract syntax tree of a code snippet, renaming variables, refactoring comments, or using a larger LLM to create synthetic edits.
Fine-Tuning
With the data prepared, and our eval setup, we have 99% of the work down. Now all we have to do is run a run our fine-tune in Oxen.ai. This can be done from the dataset, by clicking "Actions", then "Fine-Tune a model".
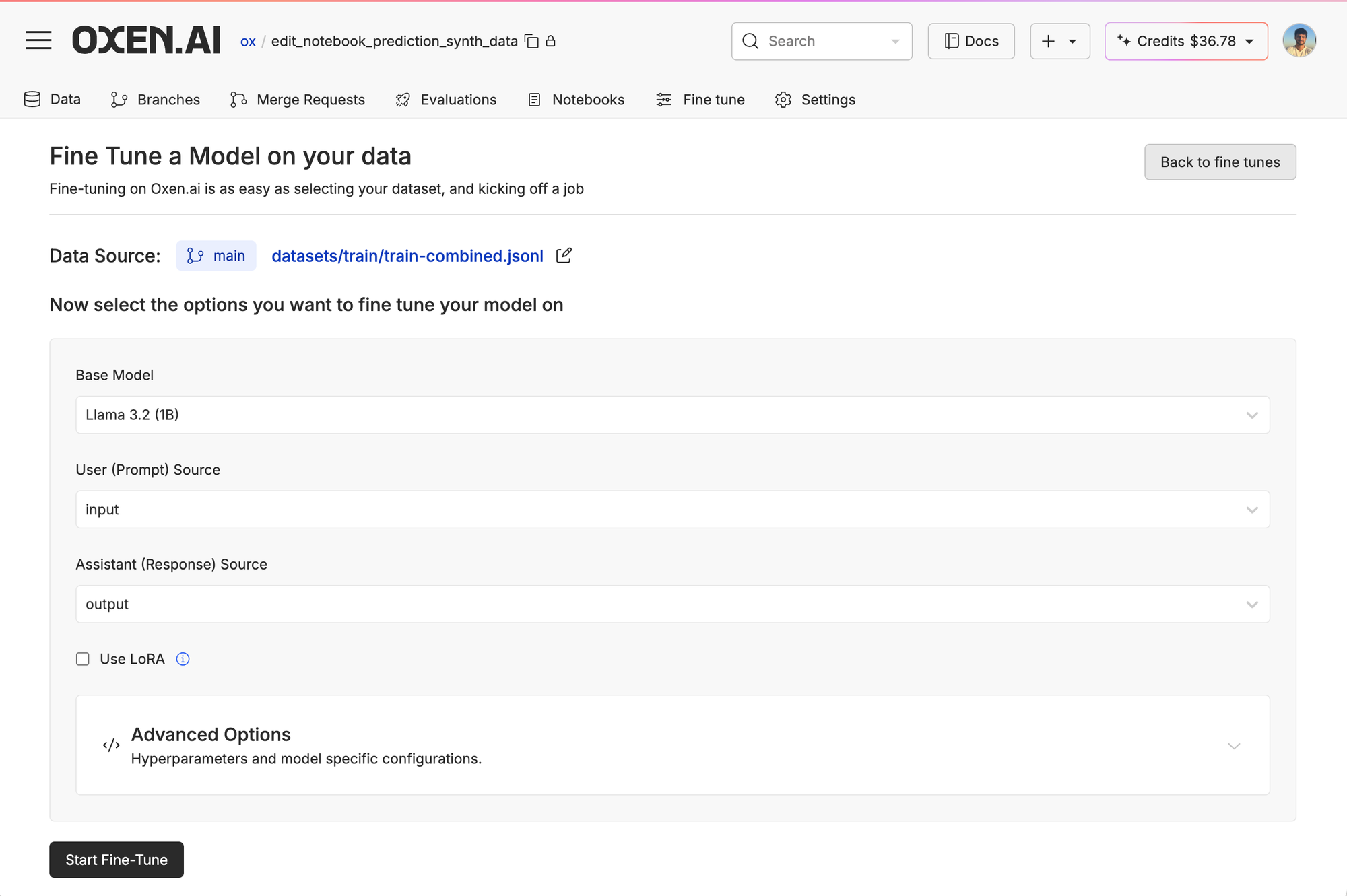
We chose our model, input and output columns, and whether we want to use LoRA or tweak other hyperparameters.
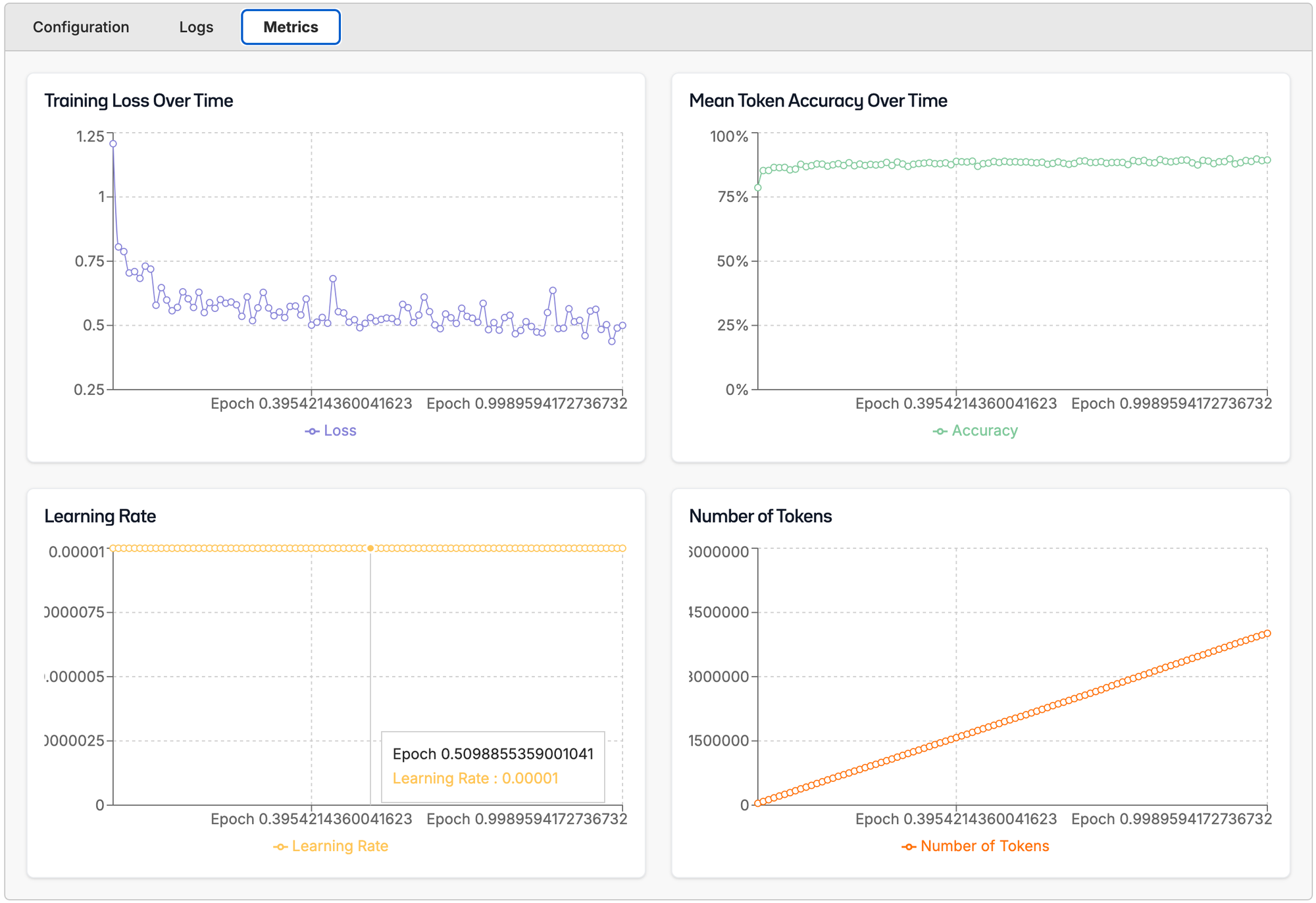
Then as the model is training, we'll be able to see our metrics, logs, and config!
When the training completes, you can deploy the model to an OpenAI compatible inference endpoint or chat with it directly in the UI.
Results
We then trained and evaluated a suite of models and created a leaderboard. Qwen3 continues to impress me on all fronts when it comes to coding.
| Model | Accuracy |
|---|---|
| Claude 4 Sonnet | 82.60% |
| Qwen3 Coder 480B | 80.60% |
| Kimi-2 | 78.80% |
| Llama 4 Maverick | 74.40% |
| GPT 4o | 74.40% |
| GPT 4.1 | 73.00% |
Qwen 3 - 4B (acute-chocolate-anteater) | 68.60% |
| Llama 4 Scout | 68.00% |
Qwen 3 - 1.7B (ox-ordinary-red-cow) | 61.80% |
| GPT 4o Mini | 60.20% |
Llama 3.2 - 3B (ox-awful-crimson-salamander) | 52.80% |
Llama 3.1 - 8B (ox-sufficient-tan-alligator) | 50.80% |
Qwen 3 - 0.6B (ox-continental-blush-guppy) | 47.80% |
Llama 3.2 - 1B (dgonz-successful-amaranth-raven) | 36.00% |
Remember, this was simply on corrupting random code snippets and having the model reconstruct them in our specific format. There is much work to be done on scaling up the training data collection. This is an encouraging start.
Next Steps
We will be building this model in public, showing you how it progresses as we go. The plan is to scale up training data collection, release a V1 and start collecting feedback from the community. In parallel we are going to experiment with GRPO and DPO to improve the performance of the model in preparation to release a V2. And thats it for now! Stay tuned for the model launch 🚀
If you want some free credits to try fine-tuning yourself, join our discord community of AI engineers, researchers, and enthusiasts and ask us :) Hope to see you next time!