How to Train Diffusion for Text from Scratch

This is part two of a series on Diffusion for Text with Score Entropy Discrete Diffusion (SEDD) models. Today we will be diving into the code for diffusion models for text, and see how they work from the inputs to the outputs to the intermediate representations of the diffusion process itself. By the end of it you will be able to train an end to end diffusion model for text and have a better understanding of the benefits and current limitations.
We do this series of ArXiv Dives live on Fridays with the Oxen.ai community. We believe that it is not only important to read the papers, but dive into the code that comes along with them to truly understand the implications, impact, and be able to apply the learnings to your own work.
The following are notes from our live session, feel free to follow along with the video below.
Paper & Code
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution by the teams at Stanford and Pika Labs.
Big shout out to @louaaron and team for the initial code implementation that was released along side the paper. For this dive, we stripped down the original code base and simplified for optimized for my own clarity and understanding. The modified codebase can run on a single A10 GPU depending on the model and batch sizes and tokenizer you use.
 Oxen-AI
Oxen-AIQuick Refresher on Diffusion for Text
We went over the math and paper in detail last week, but to set context the end goal is a generative LLM that instead of generating text token by token, can generate the entire sequence at once.

Just like diffusion for images or video, the idea is we start with a noisy random text sequence and slowly de-noise text into a coherent passage. You should be able to trade off compute (time steps) for text quality and coherence.
Why diffusion for text?
The paper cites a few reasons that diffusion is appealing for text. The first is pure performance when measured by perplexity (how “perplexed” is the model to see the next word given a dataset and the model's predicted probabilities).
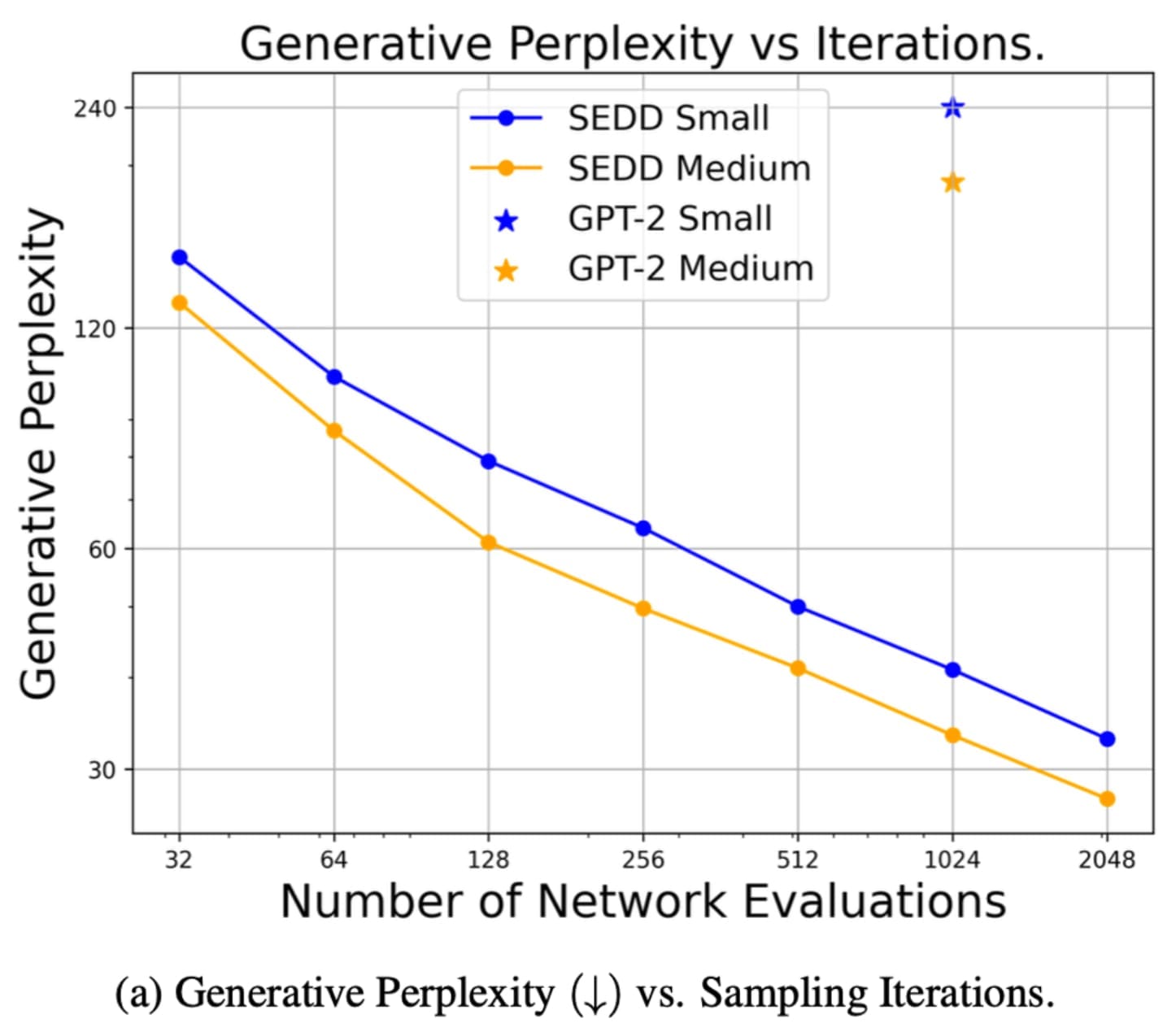
SEDD Outperforms GPT-2 model of same size trained on the same amount of data.
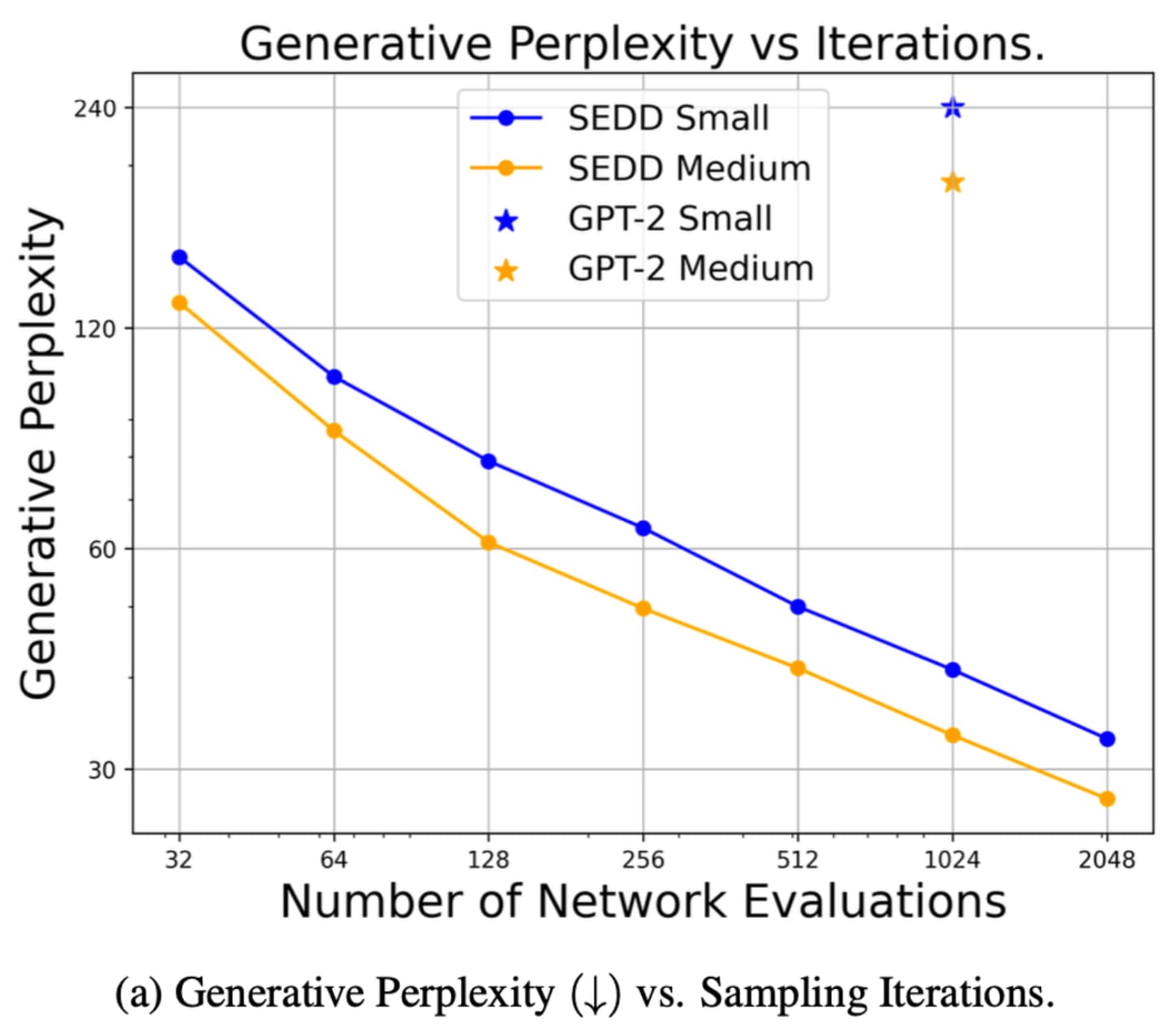
You may be thinking…but GPT-2 is old? Yes but we must start research somewhere. What’s nice is you don’t need too much compute to reproduce at least this size of a model, and you can trade off compute for quality during inference which is harder to do with standard auto-regressive modeling.
The second reason is that diffusion models are more optimized for parallel compute, and can take advantage of modern hardware like GPUs better than auto-regressive models. Auto-regressive models predict the next token one by one given the previous context. This means we must process the text sequentially instead of dividing and conquering in parallel.
The third reason is the fact that if an auto-regressive model makes a mistake, the errors can cascade. Yann Lecun calls this a “generation drifts” from the data distribution and causes the model to diverge during sampling. Diffusion has the benefit of using the complete global context during generation, resulting in better overall generation.
Finally, diffusion enables prompting from any position, or multiple positions, enabling use cases such as infilling or completing a prefix before a suffix.

Let’s put these reasons to the test…
Diving into training details 🤿
Before starting any model training, you need a dataset. To reproduce results similar to GPT-2, we need a dataset of text from the web. Luckily people have re-created such a dataset called OpenWebText. We took the time to index it into Oxen.ai if you want to reproduce the full paper results. Feel free to download it from here the link below.
If you are not familiar with Oxen.ai, it is a hub for large multi-modal machine learning datasets. Files of the scale and size that you would never check into git seamlessly index into Oxen.
The models cited in the paper are the same sizes as GPT-2. They also have the same tokenizer which contains a vocab of 50256 tokens.
Pre-Trained SEDD Demo
The first thing to do when trying out any model’s codebase is to test out any pre-trained models they have and see how it performs.
You can download the pre-trained model from Oxen.ai by using the oxen clone command.
oxen clone https://hub.oxen.ai/models/SEDD-largeThen run the script from the GitHub Repo to sample from it.
python scripts/run_sample.py --model /path/to/SEDD-large/ --steps 1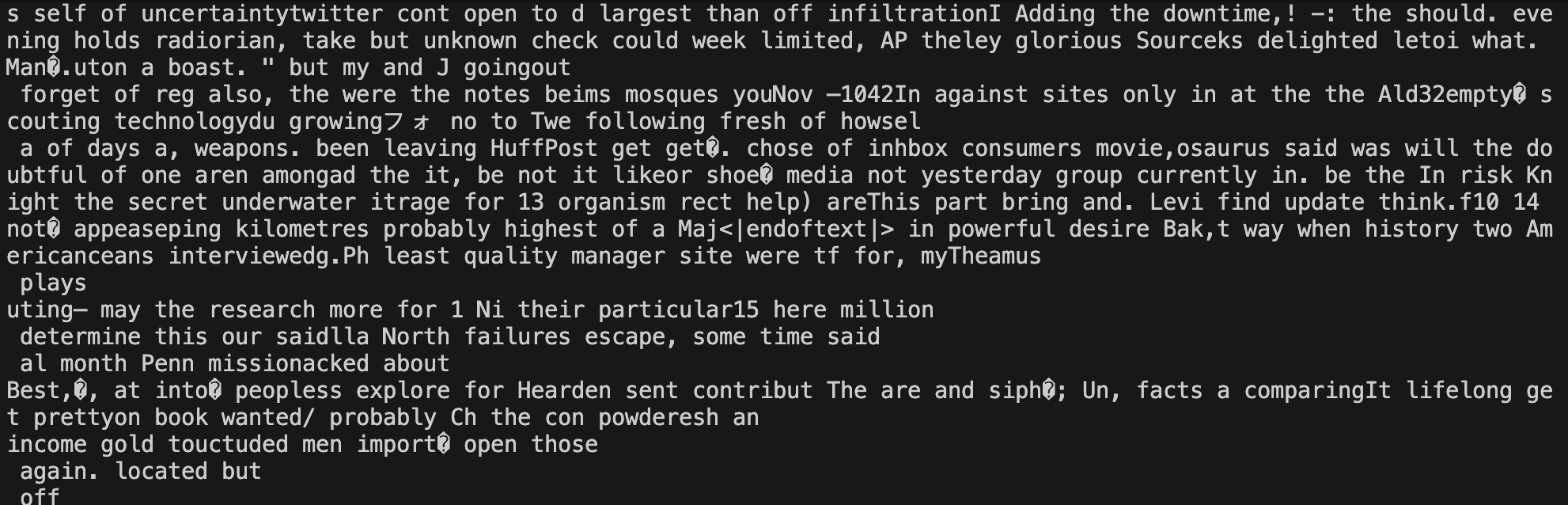
You will see text that does not look very coherent with a single step. Some english words, some invalid UTF-8. But promising start given it is supposed to start with noise. Let’s crank up the number of diffusion steps and see if it improves.
python scripts/run_sample.py --model /path/to/SEDD-large/ --steps 10A little better…
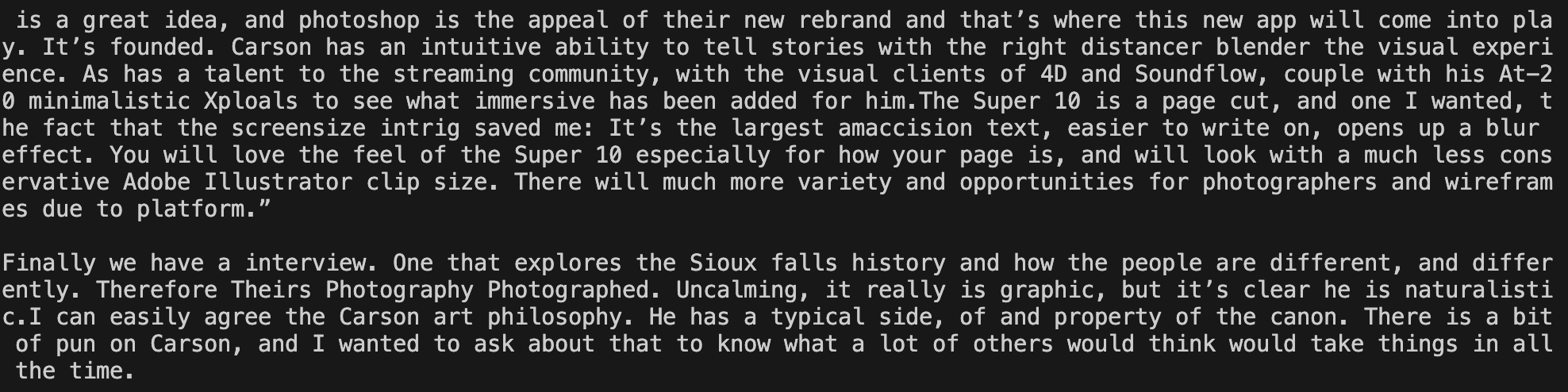
We can see we have more valid english words, and some phrases that are definitely coherent. Now crank it up to 1024 and see what the output looks like.
python scripts/run_sample.py --model /path/to/SEDD-large/ --steps 1024
This time the entire context is rather coherent, and talking about the same subject the whole time - race cars.
Each time you run the script, it with sample randomly so it is hard to see how the text actually changes step by step. You can pass in a --show_intermediate flag to the script to print out the intermediate outputs and see how it slowly diffuses the text.
python scripts/run_sample.py --model /path/to/SEDD-large/ --steps 10 --show_intermediate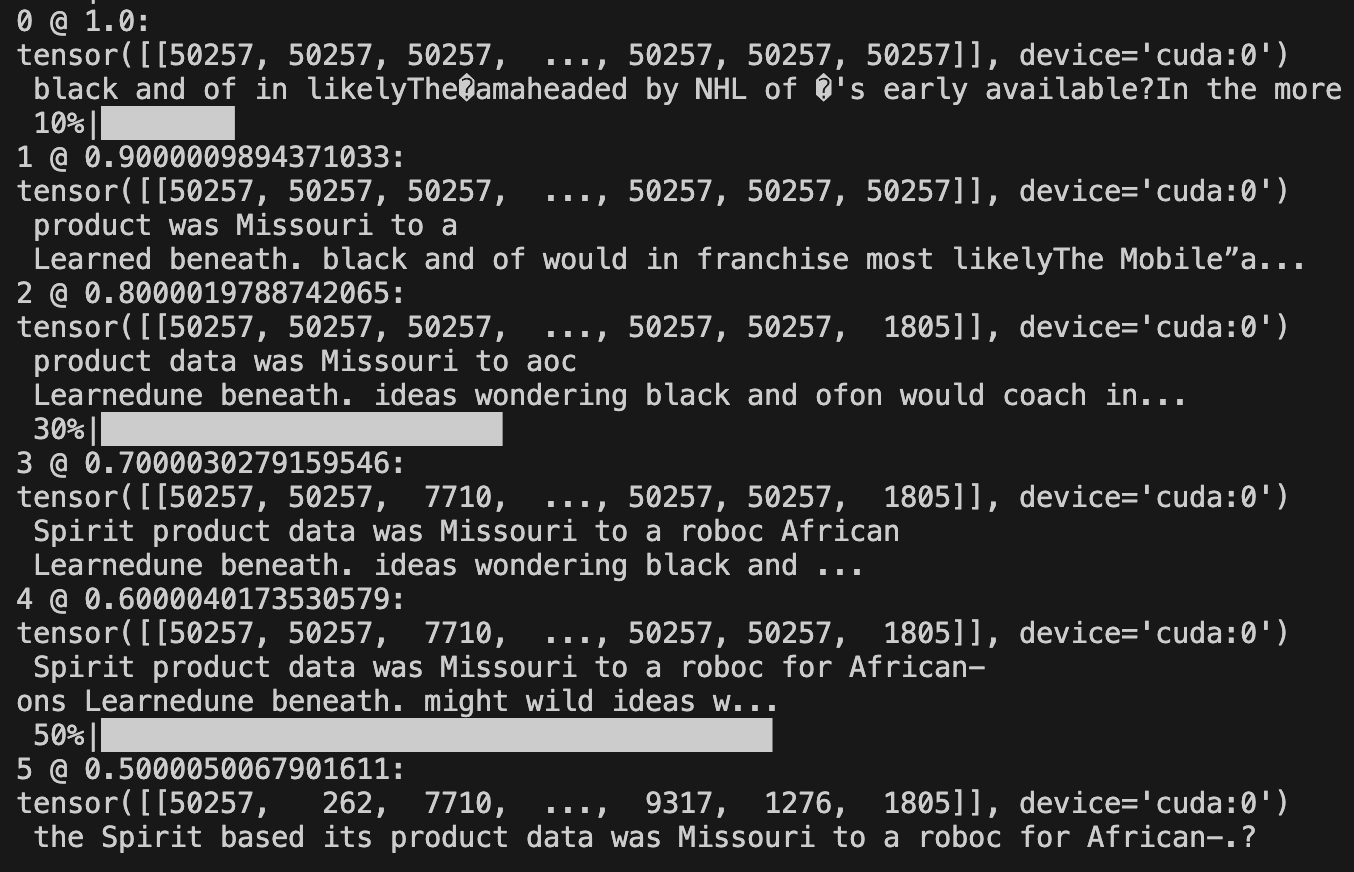
We can see we are progressively swapping tokens as we go along, to eventually arrive at something more and more! That’s great.
Now how does it actually work under the hood?
Sampling with Model, Graph, and Noise
If you recall from our dive last week, it is infeasible to add/remove noise every token at once within the sequence. Unlike images, text is represented by discrete values. Where small perturbations in pixel values result in an almost identical image, this is not the case with text.
Take for instance a simple Caesar Cipher. Remember, text is usually represented by tokens, which map to indices in a lookup table. If we change the index by just adding +1 to each value, we turn a coherent sentence into garbage in one fell swoop.
python scripts/caeser_cipher.py "Uploading large datasets with Oxen.ai is a satisfying 😌"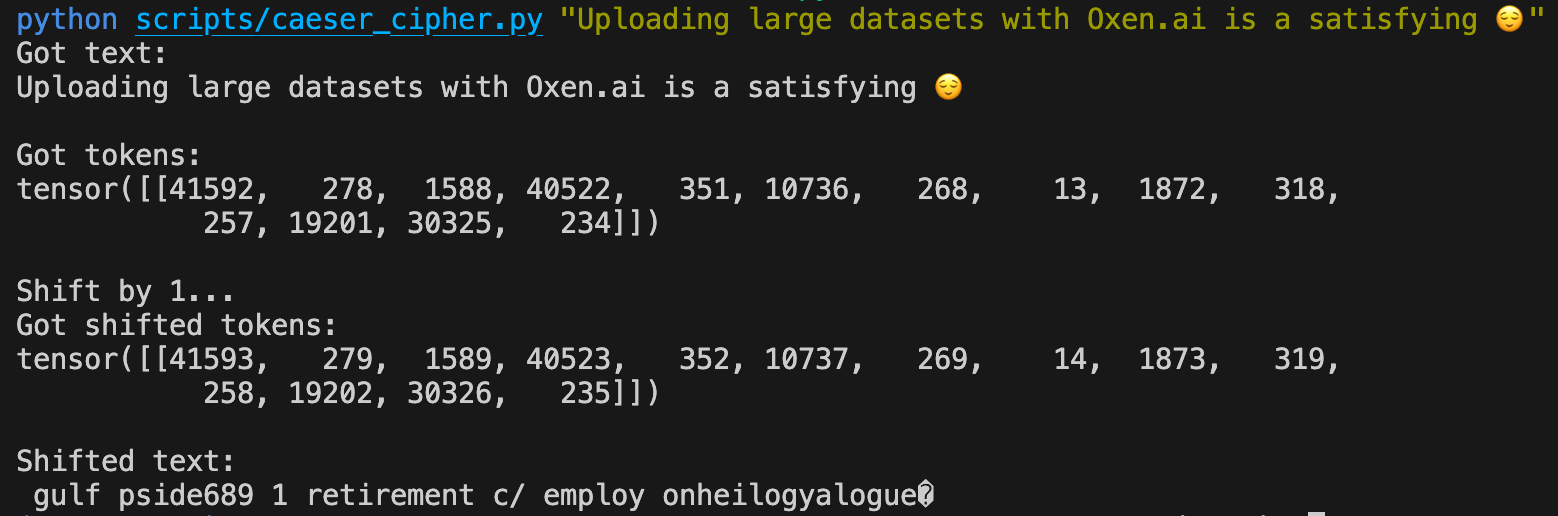
The Graph
This means the diffusion process cannot add noise by simply adding a small number to the text indices. This paper addresses this problem by instead only modifying a subset of token indices at each step, progressively flipping more and more. The number of tokens we flip is called the “hamming distance”. If you only flip one token in a phrase, this would be a hamming distance of one.
In theory, we can have a noise parameter that is passed into the model that represents roughly the hamming distance to the original text as context, then ask the model to predict which tokens to flip to make the text more coherent.
In the code, the component that does the flipping is called the AbsorbingGraph . The component that generates the noise is called LogLinearNoise . Together they can be used during model training and inference to corrupt text with noise and then de-noise it.
Let’s demo the AbsorbingGraph in action with a script that flips a random amount of tokens at given time step values.
python scripts/demo_perturb.py "Applying diffusion to text is kind of crazy" -t 0.35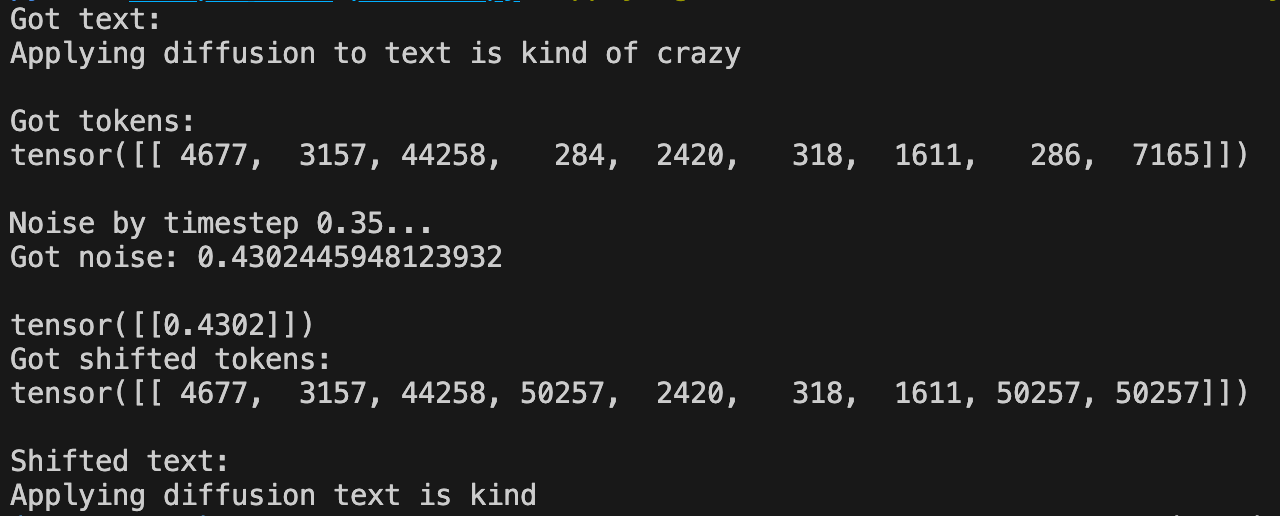
In the case above, we passed in a time step value of 0.35 , tokenized the text, and then flipped a subset of tokens to the value 50257. If you recall, the tokenizer for GPT-2 has 50256 tokens, so this flipped value is an extra token that we can "absorb" and replace with '' (an empty string).
The text was perturbed from “Applying diffusion to text is kind of crazy” → “Applying diffusion text is kind”. The idea is that at training time we will randomly noise the training data with different known values and the models job is to figure out which tokens to flip back given the current text and the known noise level.
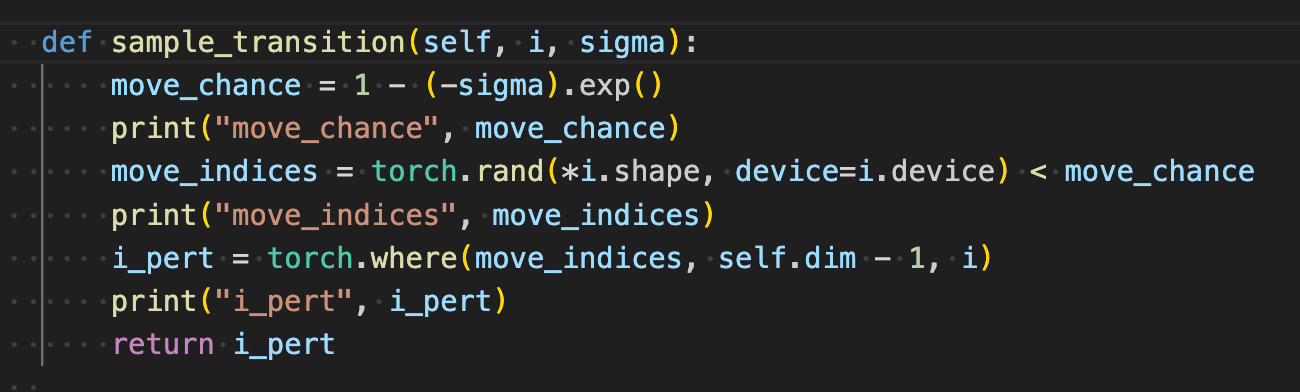
The code that actually does the flipping is in sedd/models/graph.py under the AbsorbingGraph.sample_transition function. Let's add some print statements to see how this works in practice.
Let's run the same script again and see what these intermediate values are.
python scripts/demo_perturb.py "Applying diffusion to text is kind of crazy" -t 0.35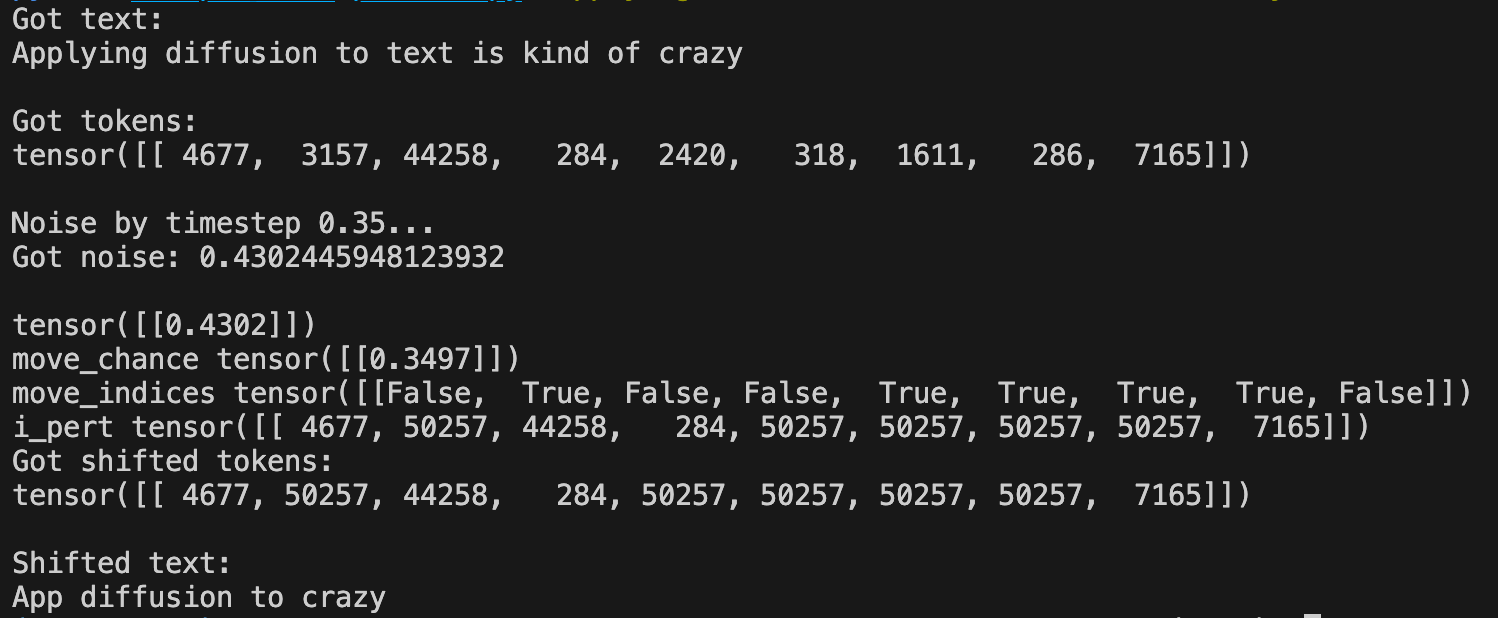
For one, you can see the randomness because we now perturbed the text to be “App diffusion to crazy”. The move chance represents how likely we are to swap any individual token to 20257 and then we get our a mask to swap those tokens appropriately.
Loss Function
If you look at the loss function, we sample a random t and noise, perturb the tokens, have the model look at the perturbed sentence, the noise, and the original sentence to compute our loss value.
sedd/trainer/loss.py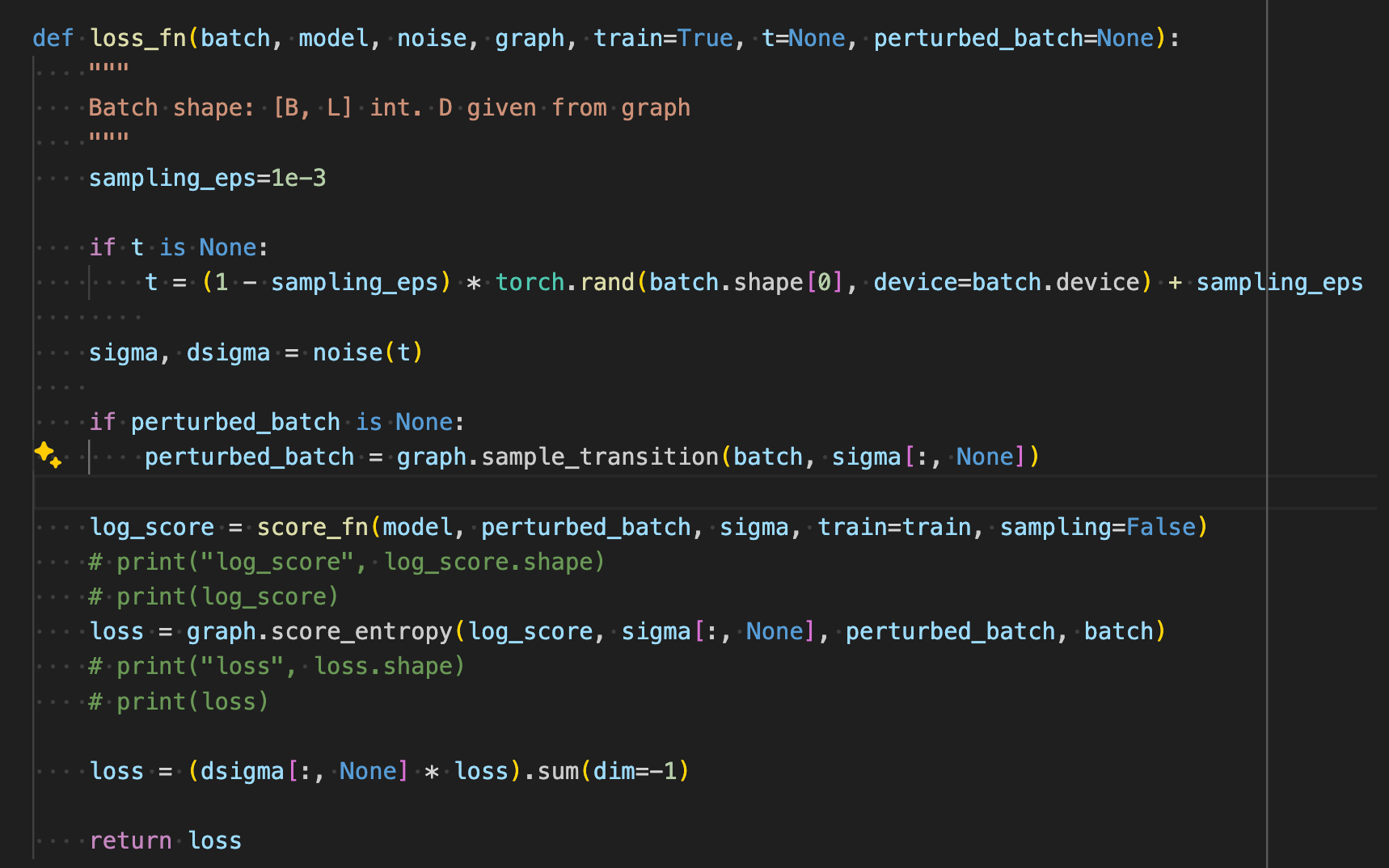
The model’s job is to assign high probability transitions to tokens that should be flipped given the level of noise. During training we sample a random time step each iteration, and the model has to guess which tokens were flipped and with what probability.
There is a script called scripts/demo_loss.py to make this more concrete. Uncomment the log_score and loss values before running this script.
python scripts/demo_loss.py "Oxen plows and maintains your fields of data" -m /path/to/SEDD-large/ -t 0.5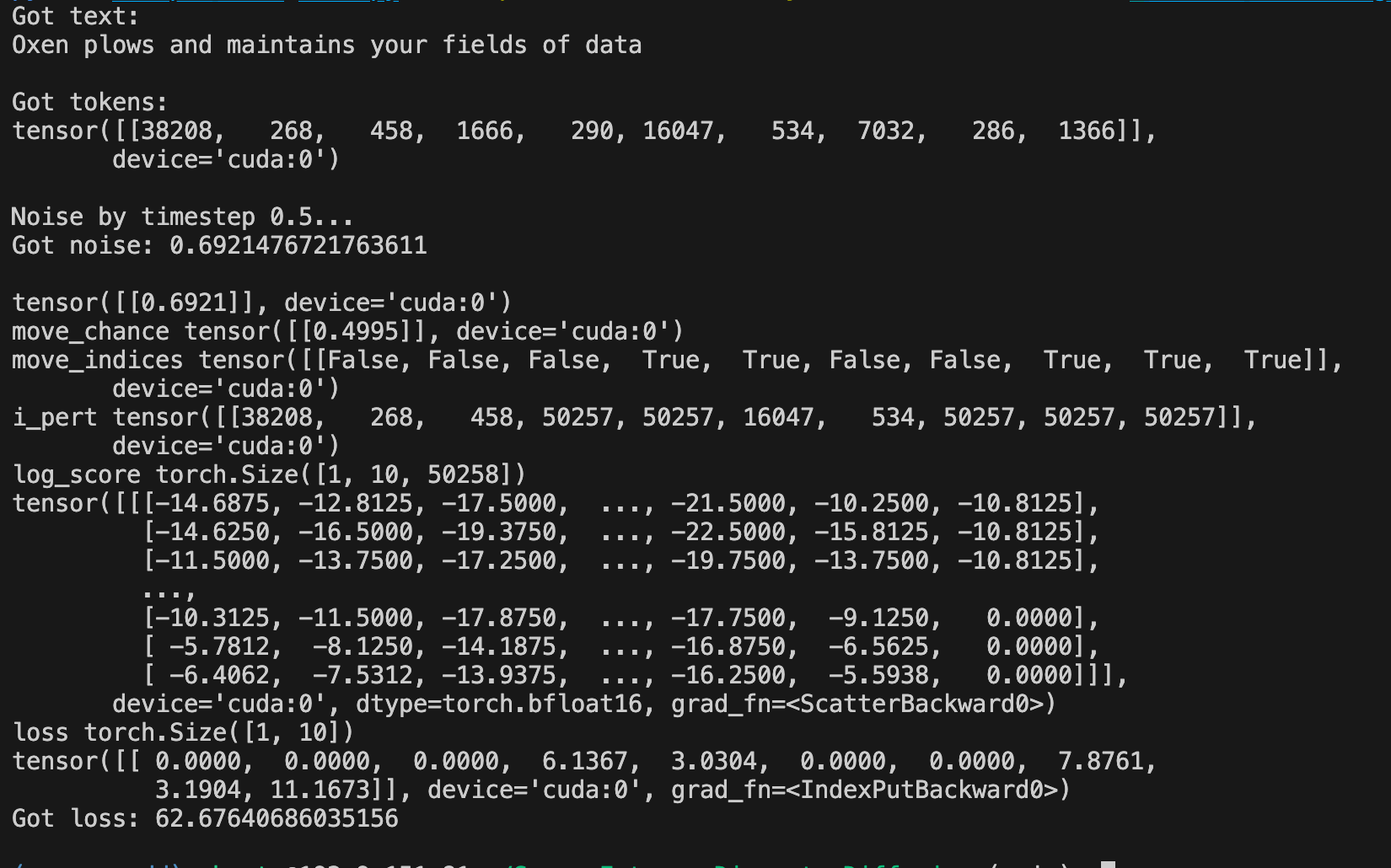
Look closely at the shape of the log_score and the loss tensors. In this case we have 10 tokens. We then corrupt the tokens with a move probability of 0.5. The score that comes out of the model is [batch_size, context_len, vocab_size]. This means for each token we have a probability mass function representing which token from the vocab we should replace each token in our sequence with. If the probability of the current token is close to what the model predicts, our loss will be low.
If we do this over and over again during training, Monte Carlo sampling random levels of noise and our training distribution, eventually we will be able to estimate the full probability mass function and flip the tokens to more and more coherent values.
The Model
Under the hood, the model is simply a transformer with an output layer the shape of the log_score tensor above. The paper uses the same number of layers and block size as the GPT-2 paper. A transformer is able to use it's self attention mechanism to look at the entire context of the noised input to try to decide which tokens to flip.
They pass in the time step as an embedded value as well as use rotary embeddings for encoding the position of each token. Flash attention is used to speed up compute. Full model code can be found in sedd/models/sedd.py.
Inference
Now take a look at the inference code that reverses the text from random noise to coherent text.
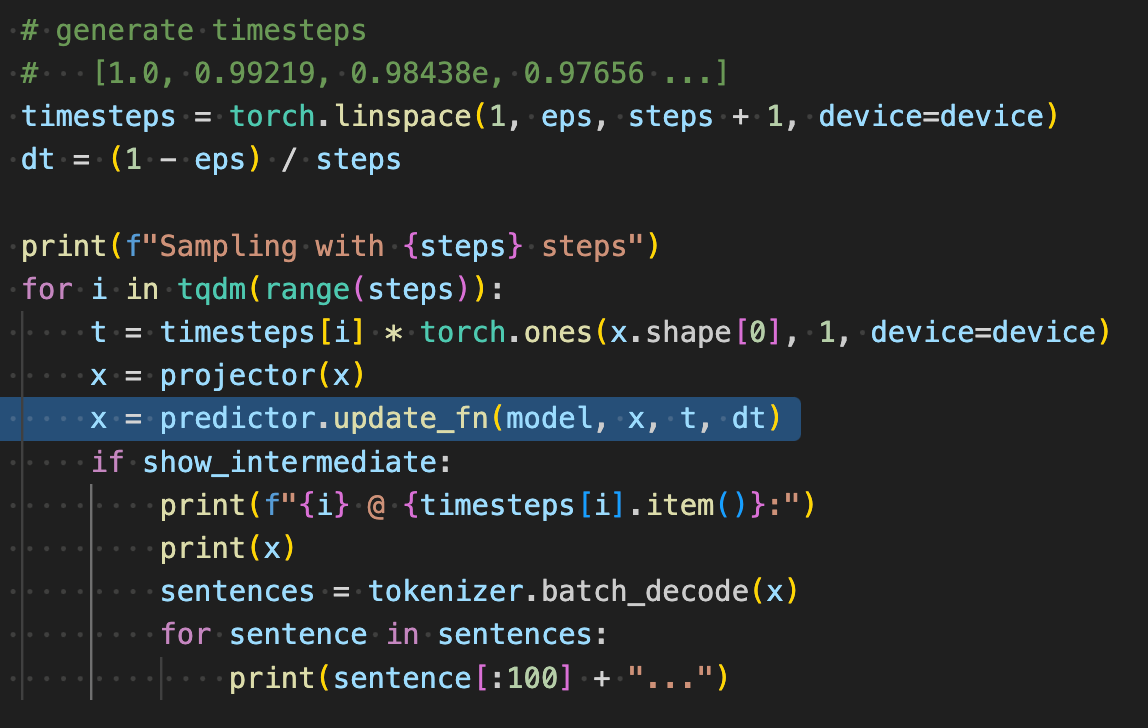
Given the number of time steps, we generate a linear set of values from [1.0 .. 0.0]. Then we sample from the model passing in the previous prediction, the time step, and the delta in time step. The projector function is used for prompting simply overwriting tokens with fixed values if we provide them.
What's cool is you can use the simple projector function to prompt from any location in your text.
def proj_fun(x):
x[:, input_locs] = input_ids
return xThis overwrites indices during inference and insure the model uses them for the next time step.
To see the prefix and suffix prompting in action, you can run scripts/run_sample_cond.py
python scripts/run_sample_cond.py --model /path/to/SEDD-large/ --prefix "Hi my name is" --suffix "and that's why I'm late" --steps 1024Hi my name is Sydney Jordan Brothers. I was a very good basketball player when I got there. Petersen and Richie, when I had, well, they were not an adopted brother but they were some similarities []. They both killed high balls. They were much brotherlier than me and much calmer than me. And they're both very strong guys. They're really—they're really strong. I think was what keeps them happy. When I got there, I didn't tell anybody because we heard about the same thing because I was a nonpro player. When I looked around and I was really happy, they no told what about me back then. But there were stupid rumors about running down the street and the same way we did things over there. But people you know why we're happy is there was different environment and it's a different type of individual I guess. Nobody was ready to workout like we grew up doing. It's just, I was a first drop by teams. And it was only because the coaches had pushed me and I was ready to do it. It was another thing to—you know, because nobody knew about nobody, man, I wasn't happy whatsoever. You was never after them for three years. You like it for a little bit. There's a group of people that love you. You time out your business, and people you met at work were like, a few of them then come back and see your time. It's a bit like a motion shoot. You know, it was the best part of my career. It was a lot and I was pretty good at making it work. You think how they treated you as a basketball player is a curse or curse? Just as I described it, that's the main thing why I'm happy for a basketball player, I guess.
CW: Right. For most guys it's the same thing. Yeah, you go drive to the mall going down there and you walk into the street and you drive by your family. You drive at night because that's normally it. Those are your only customers so you drive by your family a lot. Yeah. For me, these days, I drive by my house. That's the same thing is you're a pro at this time at practice and they can send you to immediately go in and go to the house, at night, to see if you like the house. Until then, the house. If I'm sorry to tell you that you were offended or saying something, it takes awhile and then just shut up like me because you get used to it so much, you're not talking about yourself, you're just about the house. Or the house, you're the housekeeper. The core thing is, because of the way you are treated and compared to guys the like of the leagues, perhaps you'd different and be done differently. That, I think there should be. Most players think it's for the league to give them better treatment because the players are—you know, there are ten million five thousand of them, when you don't know them, let's be honest with you. That could get us killed. But they could be freaking out. Not today. I don't think they want that. The other reason, for that to be a tough play, is, these players get paid. If you have millions in sports, you can be big, and if you can be little, you might not have so much. And they are playing here. So, when they first came in, and they know you, and they know the pay and you're sitting and they expect you to get up to the car and pay up and drive home. You're not supposed to say anything. It's just like, I paid. We don't have—money was not as good as us. But they have a bit. How is there money then? Yeah, they'd just have to use it more on our behalf. Yeah, that's the way they've got to be careful, not the players, not the NBA, the league. I think these years, until it's too late—Mille Mason didn't hang around when I was 10. I mean, yeah, I hung around at home.. He threw perfect. I mean, we didn't know he played football until 8. So, I remember him. I didn't get around when he was like 10. And he's just no slow mover just. He was a [earner than the first 300 receivers] from when he was done until he got released. So Nick comes along and they settle in, and he's my friend, and I'm there. I had an introduction with him. We at, i think, hey, this is you, we're talking to you, we are getting to know you and we know you, it's life, it's not like you have to have to be a regular job and it's supposed to be fun. So that's the real thing about it—and that's why I'm late
In theory this would be really nice to be able to prompt something like the the beginning of a code snippet, and the end, and be able to fill in the middle. In practice we fill the entire context length of 1024, so would have to modify the training regiment to output '' in the middle of sequences so that the infilling length of text is more dynamic.
Training from Scratch
Now that you have seen the noising during training and the sampling process, let’s put it all together and watch this thing train on a character level model. For this script, we replace the full GPT-2 tokenizer with a simple character level tokenizer, and reduce the model size significantly. This is simply so that we can see results quicker and verify everything is working end to end.
python scripts/run_train.py --repo YOUR_OXEN_USERNAME/SEDD_baby_namesThis script trains the model on baby names with a context length of 32 and padding of empty string at the end. The training data is from our datasets/baby_names repository on Oxen.ai.
To run the script fully, you will need to create an Oxen.ai account because we will be saving intermediate results there to compare over time.
Even after minimal training on 1000 steps we are starting to get short text strings that have capital letters at the start.

After training for a significant amount of time, we start to get actual strings that look like baby names out 🎉.

Next Steps / Conclusion
If you have enough compute, it would be interesting to train the full model on a larger dataset than even OpenWebText. It remains to be seen how well this approach scales up to models the size of GPT-3 and beyond.
Overall I think this approach is cool in theory, but after playing with it the infilling capabilities are still in early days and not practically usable as is out of the box.
Hopefully this post gave you a good understanding of how diffusion for text works, how you can train it on your own data, and I hope you try some experiments of your own!
If you like this kind of content, feel free to join our to Oxen.ai paper club or subscribe to our YouTube channel 🐂

