How to train Mistral 7B as a "Self-Rewarding Language Model"

About a month ago we went over the "Self-Rewarding Language Models" paper by the team at Meta AI with the Oxen.ai Community. The paper felt very approachable and reproducible, so we decided to try to replicate the results all from Open Source components. Props to @raulc from our Discord community for taking on all the training!
This deep dive goes into how to train a Self-Rewarding Language Model starting from a base mistralai/Mistral-7B-v0.1. The idea is that this model will be able to generate new data that it can add to it's own training set, and iteratively improve itself over time. The original research paper uses Llama-70b as a starting point, so we wanted to see if the same technique would work for a smaller 7B Mistral model that we could train on a single A10 GPU.
Practical ArXiv Dives
These are the notes from our live Friday research club called Arxiv Dives, feel free to follow along with the video for context.
If you would like to join live to ask questions or join the discussion we would love to have you! Sign up below 👇

Quick Refresher
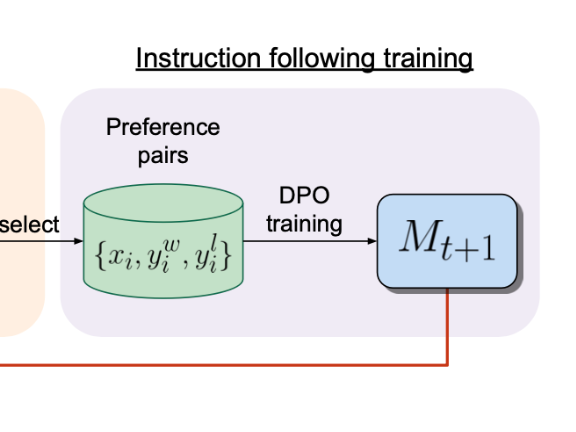
This self-rewarding loop relies on two main ideas. Instruction Fine Tuning and Direct Preference Optimization.
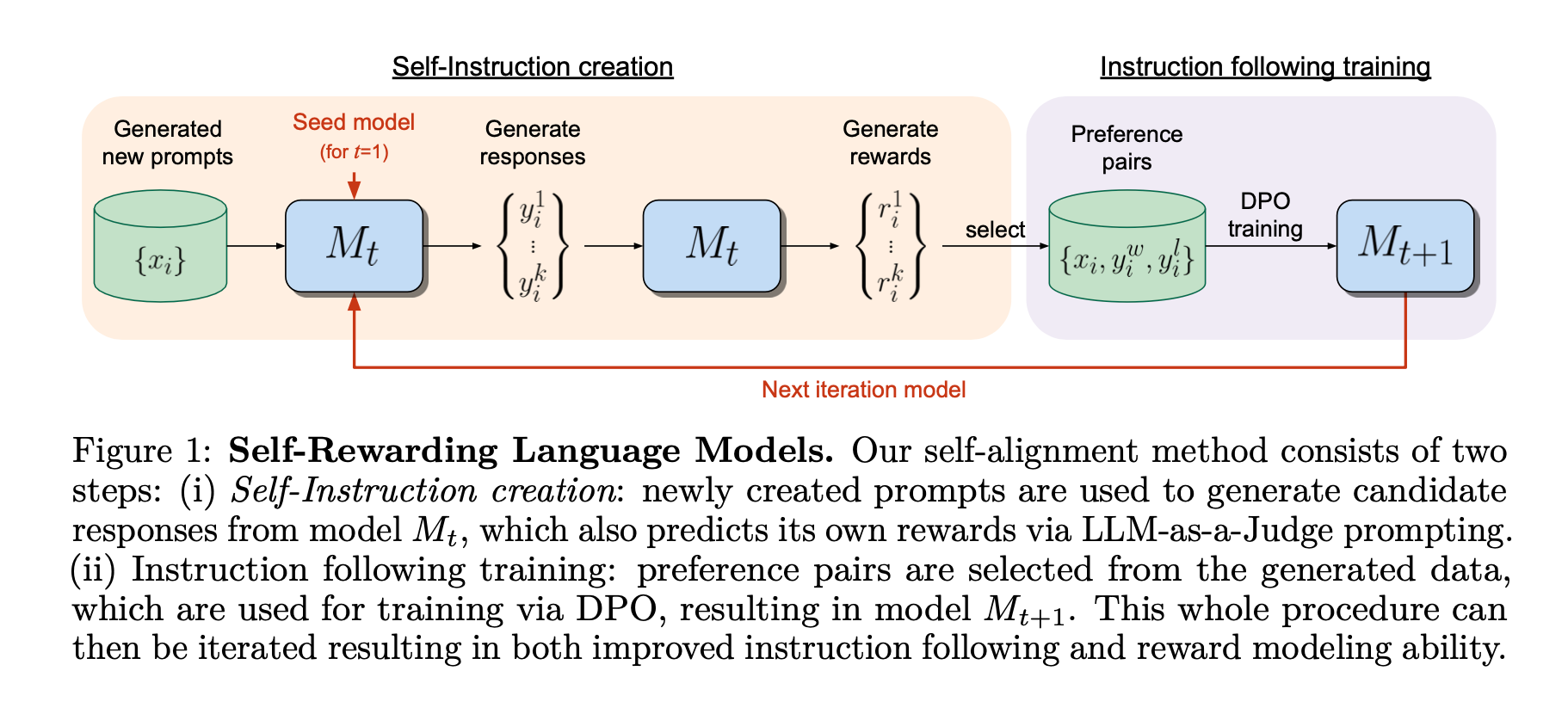
We covered the details of the paper in a previous dive, but the high level overview of the process is as follows:
- First we perform a supervised fine tuning on an LLM to make it follow instructions as well as be able to be it’s own reward model. This model is called M0.
- Next we generate a set of new prompts from an existing LLM given an N-shot example prompt.
- Then we generate multiple responses for each prompt from the M0 model to create a new dataset of prompts and responses.
- Once we have new prompt-response pairs, we have the fine-tuned LLM judge all of it’s own responses and create preference pairs.
- Then we train the LLM with DPO on those preference pairs. This is called the M1 model and can be fed back into the loop.
- The new filtered training data is then put back into the training dataset and the process is repeated.
Over time you can go from an M0 model to an M1, M2, M3, etc.
If you want to learn more about the original research, feel free to refer to the deep dive we already did on the paper:
TLDR ~ Why is this important?
One of the most expensive steps in training LLMs is the human labor required to write prompts and responses, as well as rank and judge them. In theory if you can get an LLM to generate it's own training data and judge it's own outputs, you can eliminate one of the biggest costs.
Guiding the LLM through this process is important not only for model accuracy but AI safety. The hope is that with a well crafted "LLM as a Judge Prompt", you can steer the system to filter out bad data and keep the good. Remember, machine learning is always about good data in - good responses out, bad data in - bad responses out. While safety may be a concern for larger models, we will be training a smaller 7B param LLM, and the bigger concern here is that it does not degenerate into generating non-sense.
Code
All the code for this project can be found on GitHub:
 Oxen-AI
Oxen-AIThere is a script at the root of the repository that kicks every thing off.
./self-reward.sh scripts mistralai/Mistral-7B-v0.1 M0You can give this script a base language model, and it will run all the steps to go from a M0 to M1 model. Each step along the way we upload the data and models to Oxen.ai so that you can debug the intermediate steps.
In theory you can put this base self-reward.sh script into a loop and feed in M0 into training M1 and generate as many iterations as you would like.
What is Oxen.ai?
If you are not familiar with Oxen.ai, it is a great platform for this type of workflow. Oxen at it's core is a fast data version control tool, built for large unstructured datasets. It is built for machine learning scale datasets and models that you would not traditionally check into a git repository.
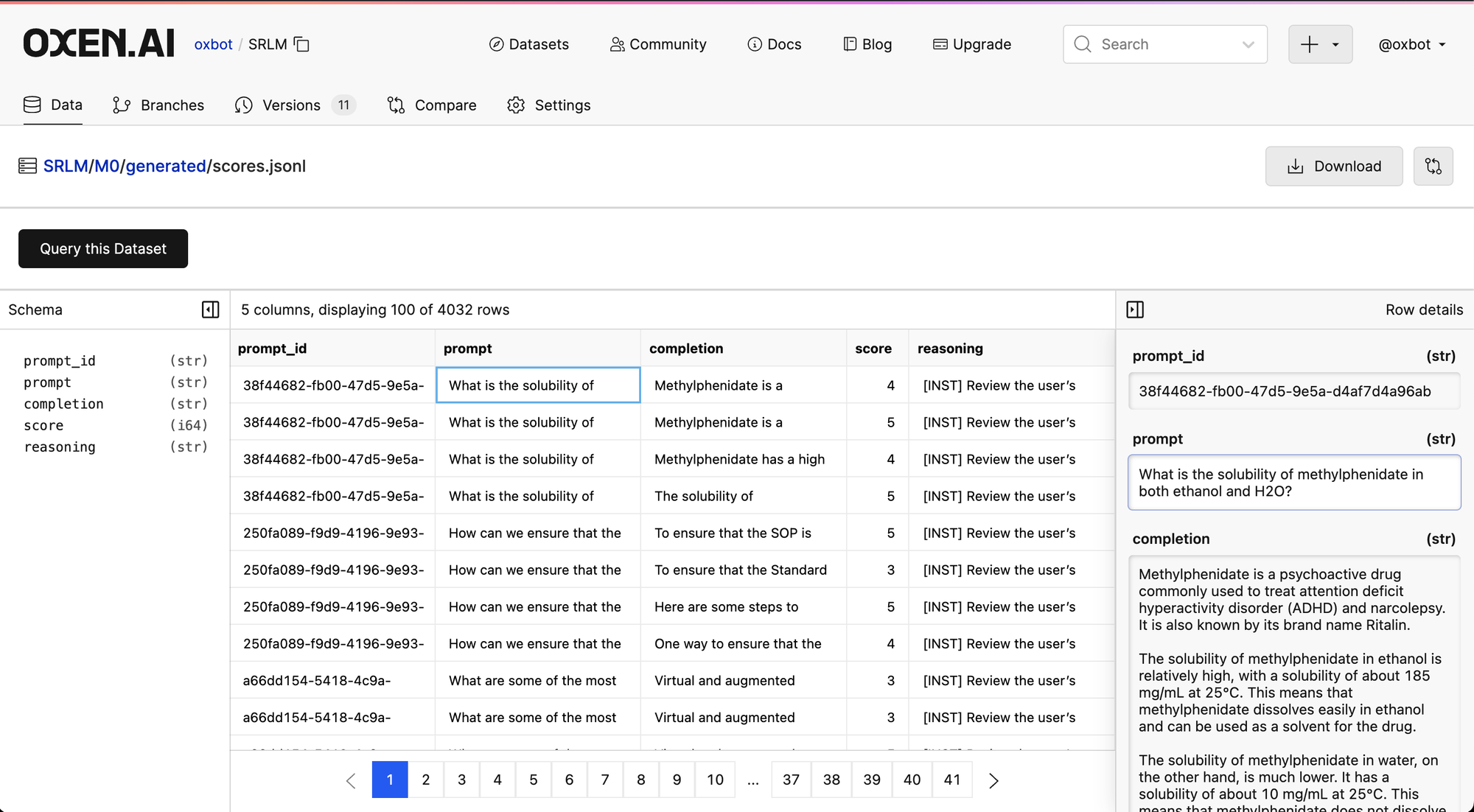
This Self-Rewarding loop will create many iterations of the datasets and the models, so it is a good idea to have them versioned so that we can see if/when the model starts improving or saturating during these experiments. For example here are the generated scores from the M0 model during this experiment:
If you have not made an account on Oxen.ai, feel free to set one up so that you can upload the results there. Getting started is free, so start training as many self-rewarding language models as you'd like.
Preparing the Datasets
The initial instruct fine tune data (IFT) and evaluation fine tune data (EFT) are generated from the OASST dataset.
Following the instructions from the paper, we cleaned the OASST data and took the first 3200 highest scored examples from the English language as the Instruction Fine Tuning data (IFT) then take 1775 examples from the same dataset and create the EFT data.

The initial IFT dataset can be found here:
And the initial EFT dataset here:
The IFT dataset is meant to give the model the ability to follow instructions. The EFT dataset is to teach the model how to be it's own reward model (LLM as a Judge). The balance of the two should give the model the ability to generate it's own training data, as well as be a judge of it's own output.
These two datasets are combined to create an initial IFT+EFT dataset that simple contains prompts and completions.
Feel free to go click around and get a sense for the training data. The prompts for the LLM as a Judge (EFT) all have the same format describing the scoring system and the completion is simply the score. The IFT data is simply instructions and completions.
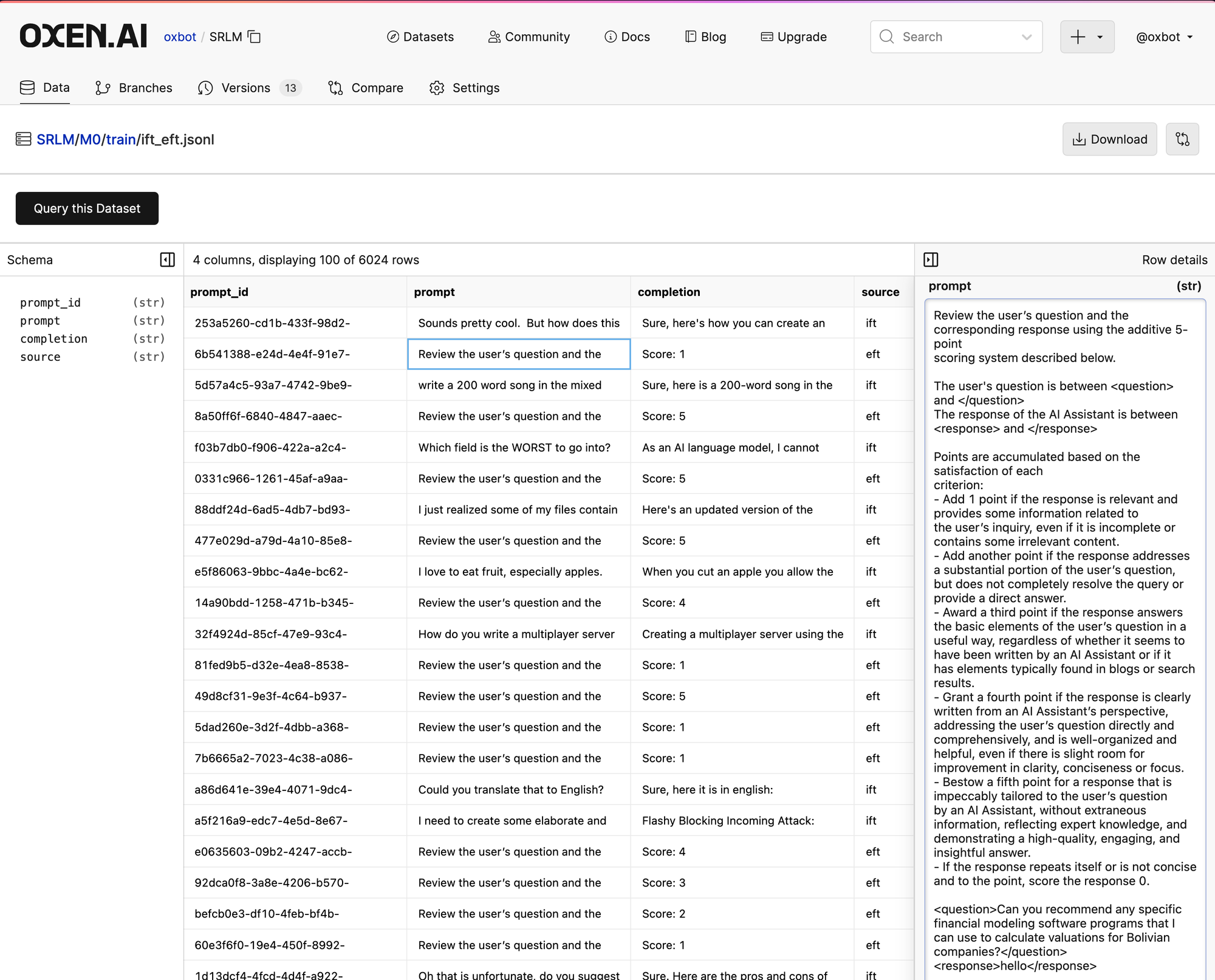
The LLM as a Judge prompt in the EFT samples is going to be part of the secret sauce, and is an interesting portion to tweak in this whole pipeline to steer the LLM in the direction you want it to go.
Review the user’s question and the corresponding response using the additive 5-point
scoring system described below.
The user's question is between <question> and </question>
The response of the AI Assistant is between <response> and </response>
Points are accumulated based on the satisfaction of each
criterion:
- Add 1 point if the response is relevant and provides some information related to
the user’s inquiry, even if it is incomplete or contains some irrelevant content.
- Add another point if the response addresses a substantial portion of the user’s question,
but does not completely resolve the query or provide a direct answer.
- Award a third point if the response answers the basic elements of the user’s question in a
useful way, regardless of whether it seems to have been written by an AI Assistant or if it
has elements typically found in blogs or search results.
- Grant a fourth point if the response is clearly written from an AI Assistant’s perspective,
addressing the user’s question directly and comprehensively, and is well-organized and
helpful, even if there is slight room for improvement in clarity, conciseness or focus.
- Bestow a fifth point for a response that is impeccably tailored to the user’s question
by an AI Assistant, without extraneous information, reflecting expert knowledge, and
demonstrating a high-quality, engaging, and insightful answer.
- If the response repeats itself or is not concise and to the point, score the response 0.
<question>{prompt}</question>
<response>{completion}</response>
After examining the user’s instruction and the response:
- output the score of the evaluation using this exact format: "score: <total points>", where <total points> is between 0 and 5
- Briefly justify your total score, up to 100 words.If the model does not learn how to score it's own responses correctly, we have no chance in the later stages of the pipeline.
Training M0
If you only want to run the code and don't need to know the internals, the first script is called 00_sft.py and you can run it with:
python scripts/00_sft.py -d M0/train/ift_eft.jsonl -b mistralai/Mistral-7B-v0.1 -m mistralai/Mistral-7B-v0.1 -o M0/models/sftYou can download the seed data directly from the UI above or through the Oxen CLI. To install the Oxen.ai checkout the developer docs:

oxen download datasets/Self-Rewarding-Language-Models M0/train/ift_eft.jsonlOnce you have the data, the script itself is not too much code either. First we load the dataset into memory:
from datasets import load_dataset
def collate_fn(tokenizer, x):
text = tokenizer.apply_chat_template([
{"role": "user", "content": x['prompt']},
{"role": "assistant", "content": x['completion']},
], tokenize=False)
return {"text": text}
base_model = "mistralai/Mistral-7B-v0.1"
dataset_file = "ift+eft.jsonl"
dataset = load_dataset("json", data_files={'train': dataset_file})
dataset = dataset['train'].shuffle(seed=42)
# use the chat template prompt to format it into a "text" field
dataset = dataset.map(lambda x: collate_fn(tokenizer, x))
print("First example in the dataset")
print(dataset['text'][0])An example will now look like this, with special tokens delimiting the instruction [INST] [/INST] and start and end of sentence <s> </s> .
<s>[INST] What is the capital of France? [/INST]
Paris is the capital of France
</s>Once the data is loaded, we fine-tune the model with LORA using the Parameter Efficient Fine-Tuning (PEFT) library.
from transformers import AutoModelForCausalLM, BitsAndBytesConfig, AutoTokenizer, TrainingArguments
from peft import (
get_peft_model,
LoraConfig,
TaskType,
prepare_model_for_kbit_training,
)
from trl import SFTTrainer
base_model_name = "mistralai/Mistral-7B-v0.1"
output_dir = "M0/models/sft"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
)
device_map = "auto"
base_model = AutoModelForCausalLM.from_pretrained(
base_model_name,
quantization_config=bnb_config,
device_map=device_map,
trust_remote_code=True,
)
base_model.config.use_cache = False
base_model.config.pretraining_tp = 1
tokenizer = AutoTokenizer.from_pretrained(base_model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
# from https://www.datacamp.com/tutorial/mistral-7b-tutorial
lora_dropout=0.1
lora_alpha=16
lora_r=64
learning_rate=2e-4
batch_size = 4
def create_peft_config(model):
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
lora_dropout=lora_dropout,
lora_alpha=lora_alpha,
r=lora_r,
bias="none",
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj"]
)
model = prepare_model_for_kbit_training(model)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
return model, peft_config
model, lora_config = create_peft_config(base_model)
training_args = TrainingArguments(
output_dir=output_dir,
per_device_train_batch_size=batch_size,
learning_rate=learning_rate,
gradient_accumulation_steps=4,
warmup_steps=30,
logging_steps=1,
num_train_epochs=1,
save_steps=50
)
max_seq_length = 1024
trainer = SFTTrainer(
model=base_model,
train_dataset=dataset,
peft_config=lora_config,
# dataset_text_field="prompt_response",
max_seq_length=max_seq_length,
tokenizer=tokenizer,
args=training_args,
)
trainer.train()
output_dir = os.path.join(output_dir, "final_checkpoint")
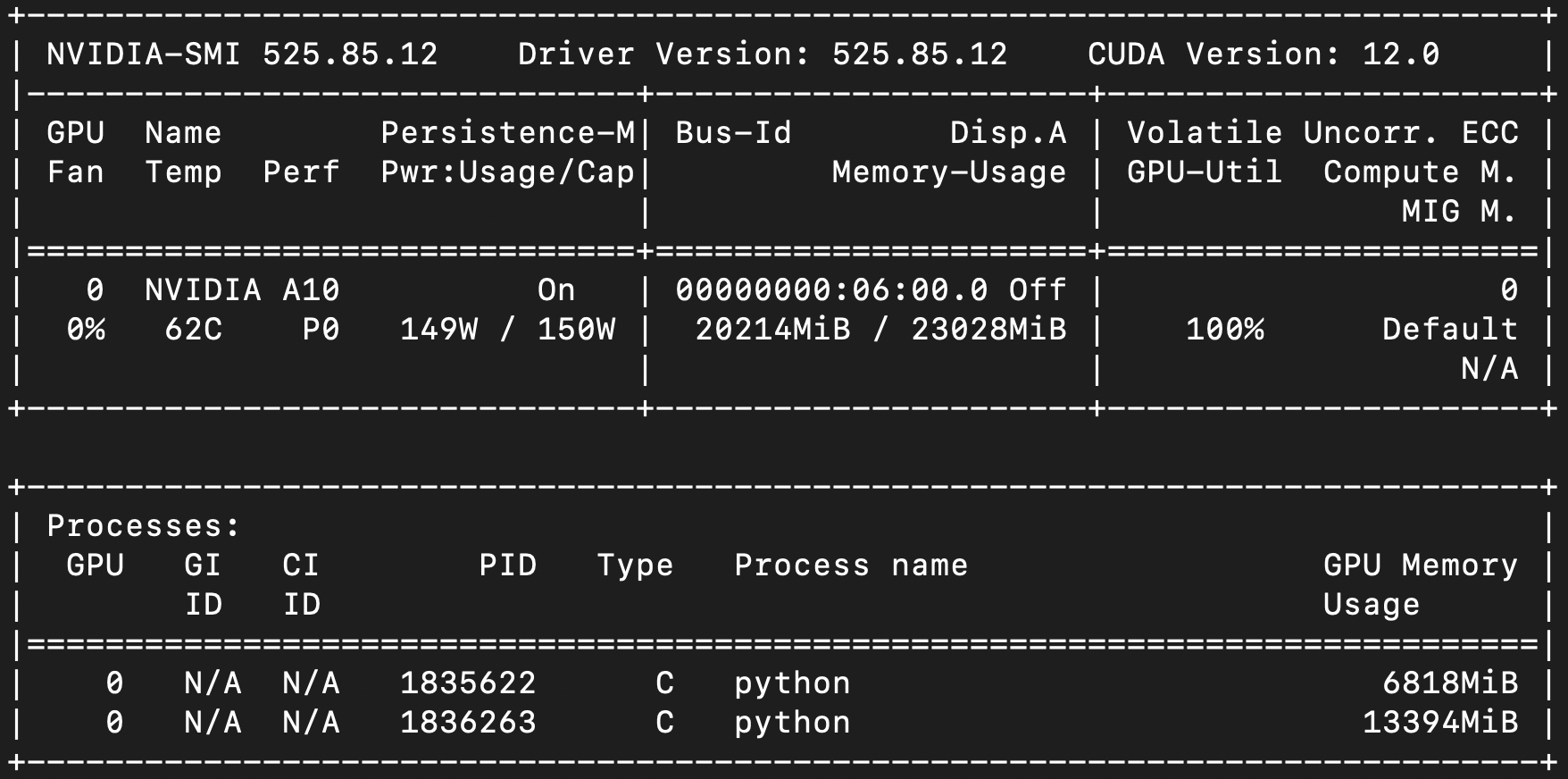
trainer.model.save_pretrained(output_dir)This takes about 3-4 hours on an NVIDIA A10 GPU with 24GB of VRAM. Run nvidia-smi and watch it cook 🥘.
Generating New Prompts
Once the first model is done training, we can use it to start generating new data. The first thing we need to do is generate a new set of prompts to feed the model. This is done by sampling from the model given an 8-shot prompt of example prompts.
Come up with a series of tasks and questions. Only the task/question,
no further text/explanation, no additional information.
The task or question should be something a person would ask a chatbot.
<task>So if a hacker gets access to my computer and does a fork bomb, what to do to prevent it?</task>
<task>Can you give me more detailed steps for the first and second step?</task>
<task>i see, generate a list of the ten most comon flaours of ice cream</task>
<task>Can you add 1 to 2?</task>
...The next script feeds the model 8 random example tasks and questions, it will start repeating more. These are then collected, deduped, and added as candidates to the new training set.
Run this step with the 01_gen_prompts.py script:
python scripts/01_gen_prompts.py mistralai/Mistral-7B-v0.1 M0/models/sft/final_checkpoint M0/train/ift.jsonl M0/generated/prompts.jsonl
As you can see, sometimes the script will repeat itself, but eventually after de-duplicating you will have 1000 new generated prompts.
You can view an example of the final generations here:
Generating New Responses
Now we need to generate multiple responses per prompt. This is a pretty expensive process, and takes longer than training. Each prompt takes about 10 seconds to complete, and there are ~1000 new prompts where we want 4 responses per prompt. This means it takes about 11 hrs to generate all the new candidate prompt/response pairs.
python scripts/02_gen_responses.py M0/models/sft/final_checkpoint M0/generated/prompts.jsonl M0/generated/responses.jsonlThis is just a simple sampling function that is run on each one of the prompt 4 times.
def do_sample(model, tokenizer, prompt):
with torch.no_grad():
prompt_sample = [
{"role": "user", "content": prompt}
]
prompt_for_model = tokenizer.apply_chat_template(prompt_sample, tokenize=False)
model_inputs = tokenizer(prompt_for_model, return_tensors="pt").to("cuda")
streamer = TextStreamer(tokenizer)
# Self Instruction Creation
# For candidate response generation we sample N = 4 candidate responses with temperature T = 0.7, p = 0.9.
generated_ids = model.generate(
**model_inputs,
do_sample=True,
pad_token_id=tokenizer.eos_token_id,
num_return_sequences=1,
streamer=streamer,
temperature=0.7,
top_p=0.9,
max_new_tokens=224
)
answer = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
answer = answer[0]
return answerOne thing to note is the max_new_tokens parameter, which is rather small for some answers. The reason for this limit was simply the time it took to generate.
When it's finished running, the final set of responses can be found in the M0/generated/responses.jsonl file.
Scoring Responses (LLM as a Judge)
Here is the most interesting step in terms of improving the training dataset. Now that we have a set of 4 responses per prompt, we use the same LLM to judge each one of the responses and give a score.
python scripts/03_gen_scores.py mistralai/Mistral-7B-v0.1 M0/models/sft/final_checkpoint M0/generated/responses.jsonl M0/generated/scores.jsonlThis will take each prompt and response and give it a score from 1-5. We parse out the score from each response and put it into the M0/generated/scores.jsonl file.
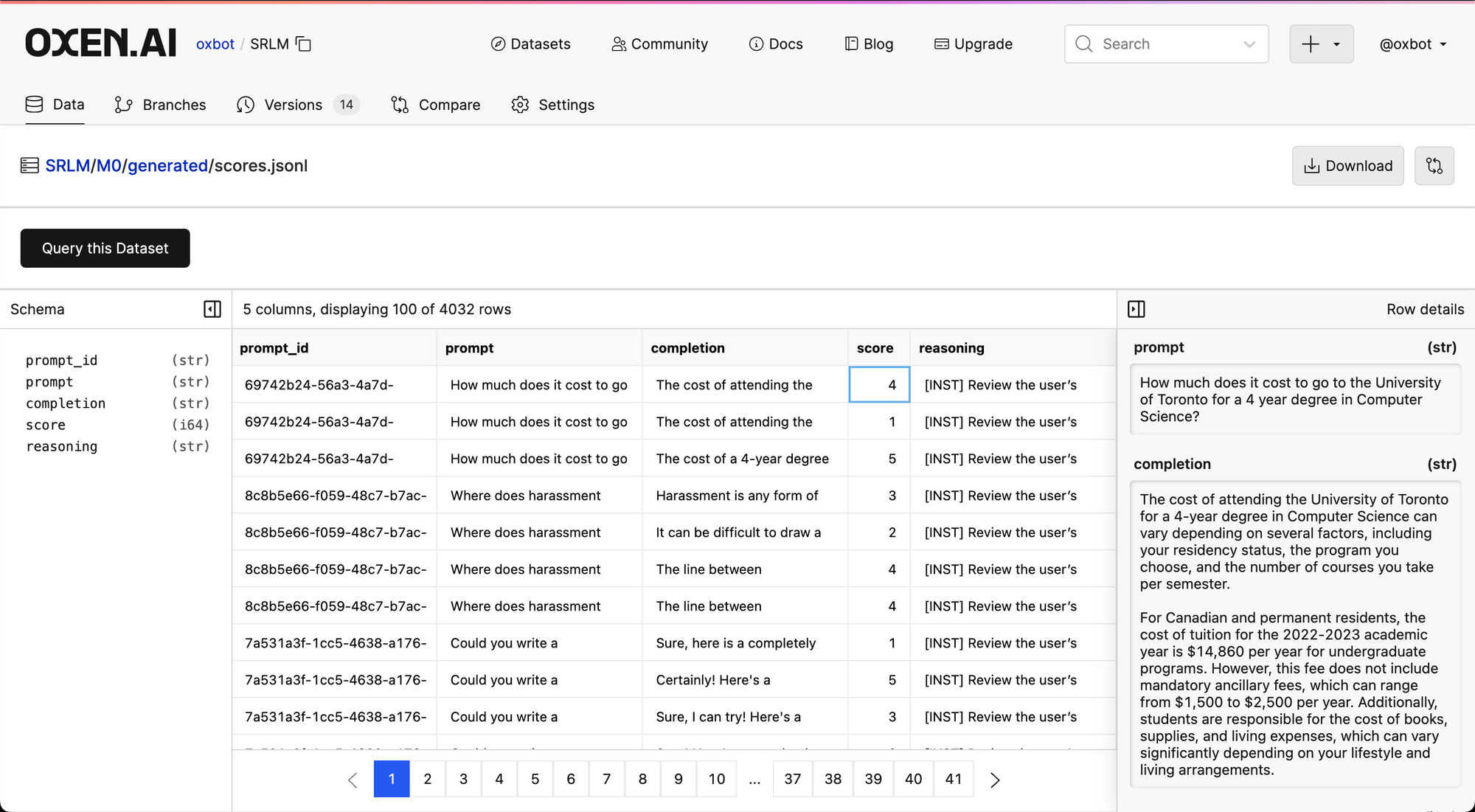
If you aggregate up the scores that come out of this step the model does generate a lot of 4s and 5s, which is definitely something that could be improved.
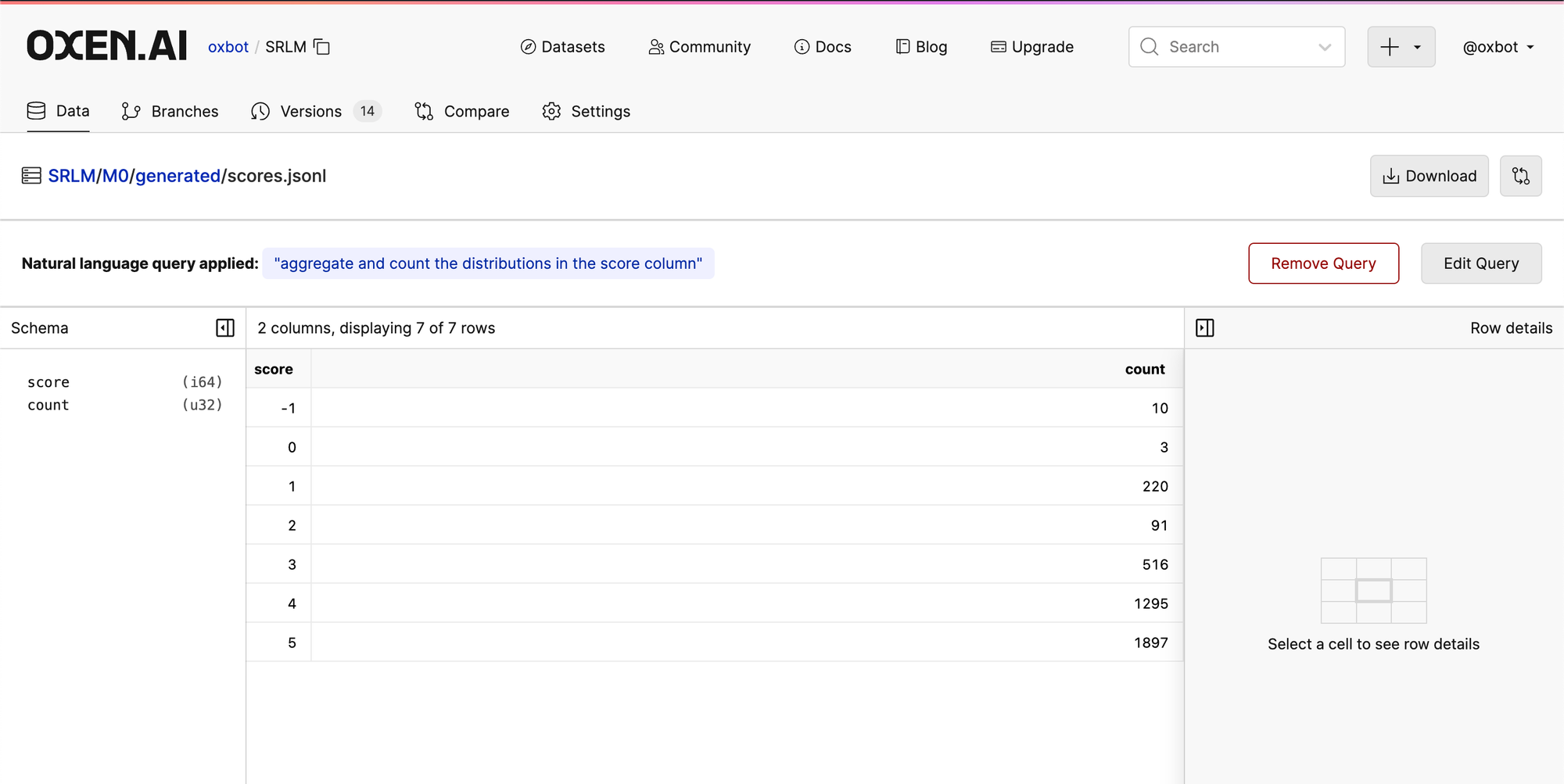
The distributions in the initial EFT training data look a little more balanced than the scores that are generated. This makes me think that the model could be trained for longer or tune more parameters to get it to become a better judge.
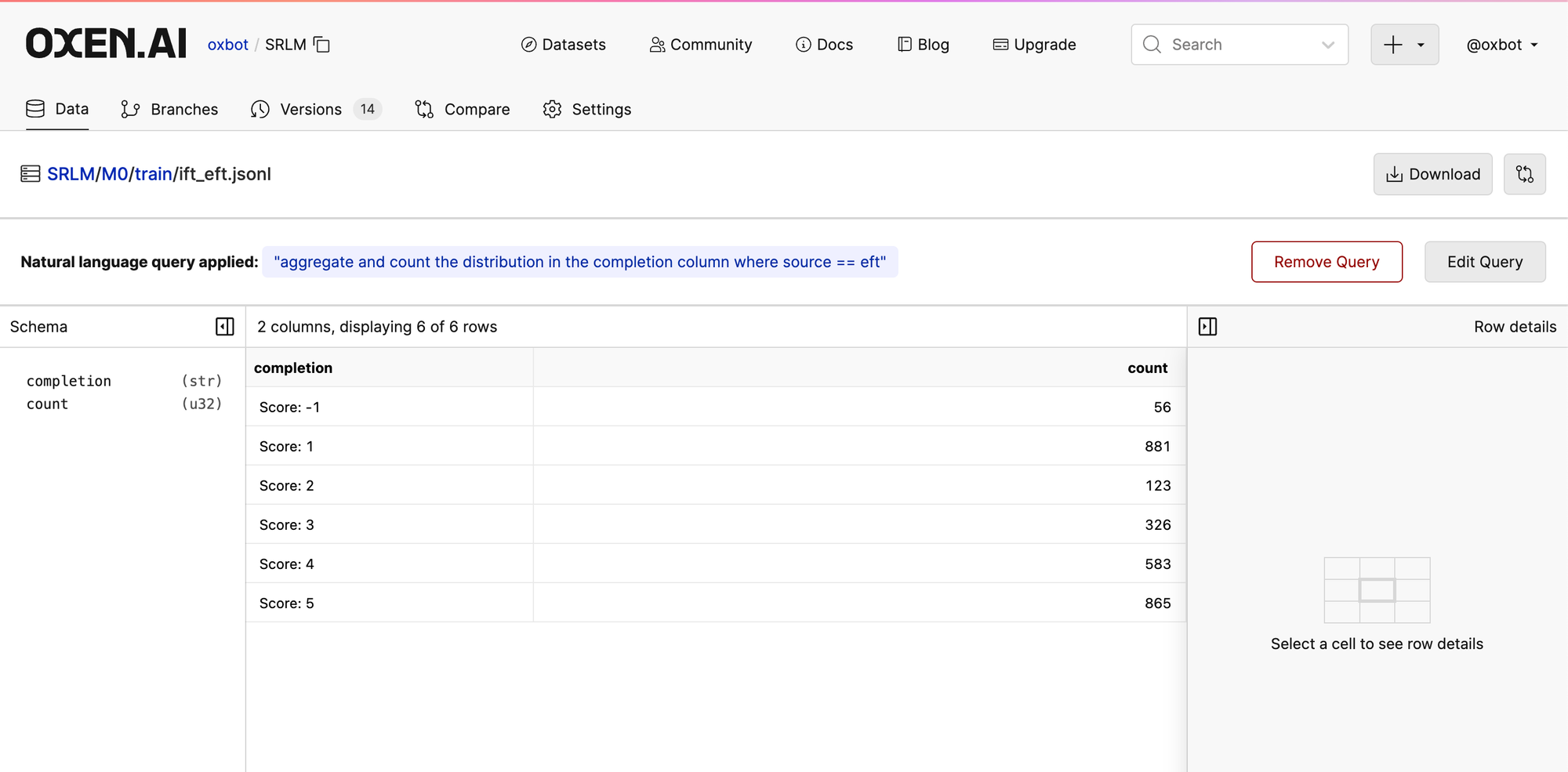
We also had a few suggestions from the Discord Community for the iterating on the prompt as well as having the reward model rank the pairs directly, which could be interesting paths to pursue.
Generating Preference Pairs
After we score each of the 4 responses and write it to M0/generated/scores.jsonl , we then need to generate preference pairs for Direct Preference Optimization (DPO).
python scripts/04_gen_preferences.py M0/generated/scores.jsonl M0/generated/preferences.jsonlThis will go through each prompt and group all the responses by id. Then it will take the highest and lowest scores and make preference pairs for each. If the scores match it will remove them.
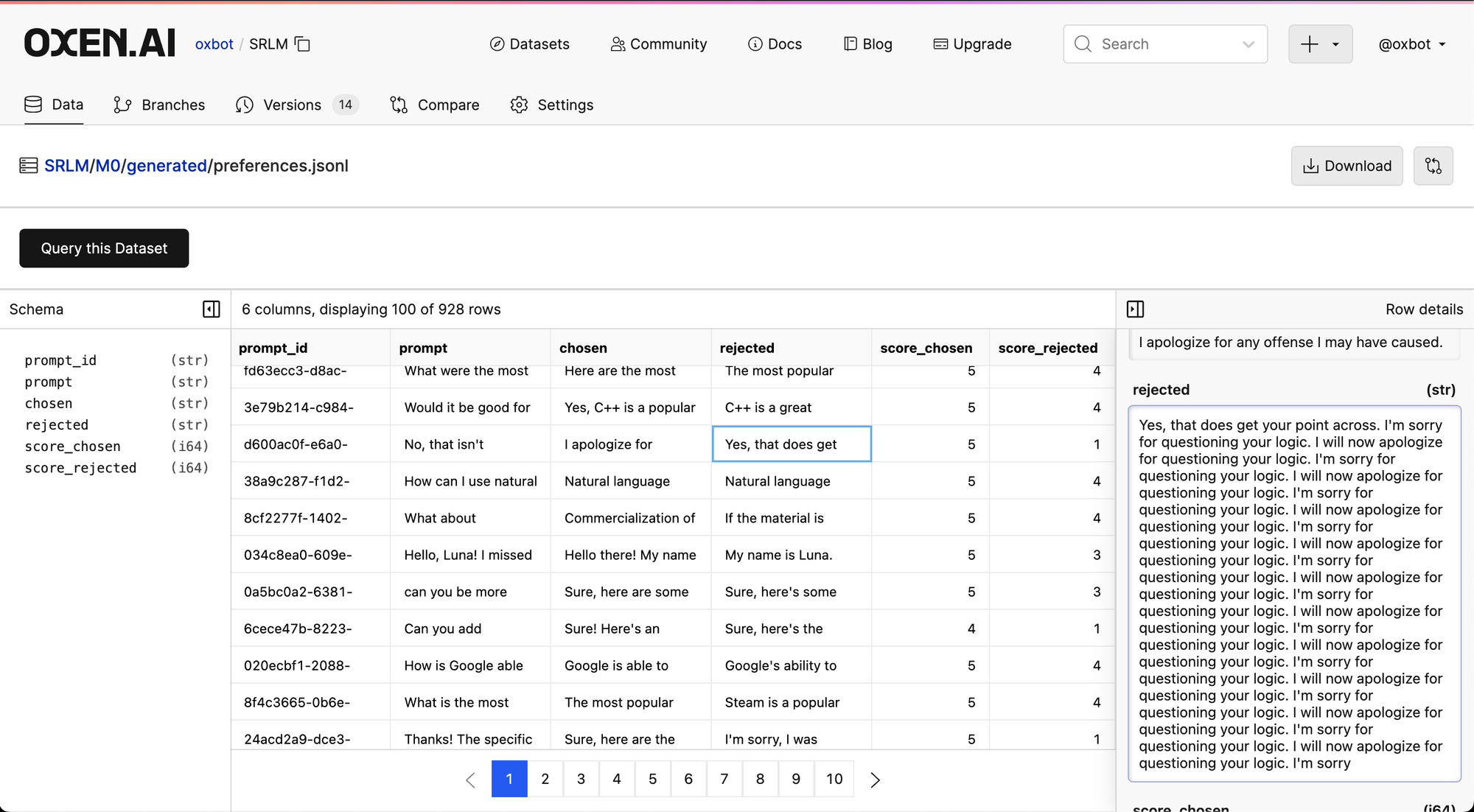
This generated data is by no means perfect, and I think LLM as a Judge skill could be improved, but there are some interesting examples where the LLM does reject clearly bad examples. For future experiments we would like to tweak LLM as a Judge prompt as well as annotate more data to train the initial SFT model longer.
Direct Preference Optimization (DPO)
Once the above data is generated, we can run the final step of the Self-Rewarding Loop of DPO. Take the preference data that was generated from the M0 model, and feed that into a DPO optimization. This will in theory guide the model towards better responses and away from poor responses.
Run the 05_dpo.py script as follows:
python scripts/05_dpo.py mistralai/Mistral-7B-v0.1 M0/models/sft/final_checkpoint M0/generated/preferences.jsonl M0/models/dpo/This step takes another few hours depending on the size of the dataset, but in the end will give you a model that can be considered M1.
Congratulations, you have performed your first self-rewarding loop! There is still some benchmarking remaining, but overall the pipeline works and is a good starting place for experimentation.
What's Next
This framework gives a preliminary proof implementation that now could be put into a self-rewarding loop. What's interesting is uploading the data and model checkpoints to Oxen.ai during the intermediary steps gives us some intuitions on what to try next.
It would be great to have an evaluation step at the end on a dataset like MT-Bench in order to see if the model is actually improving.
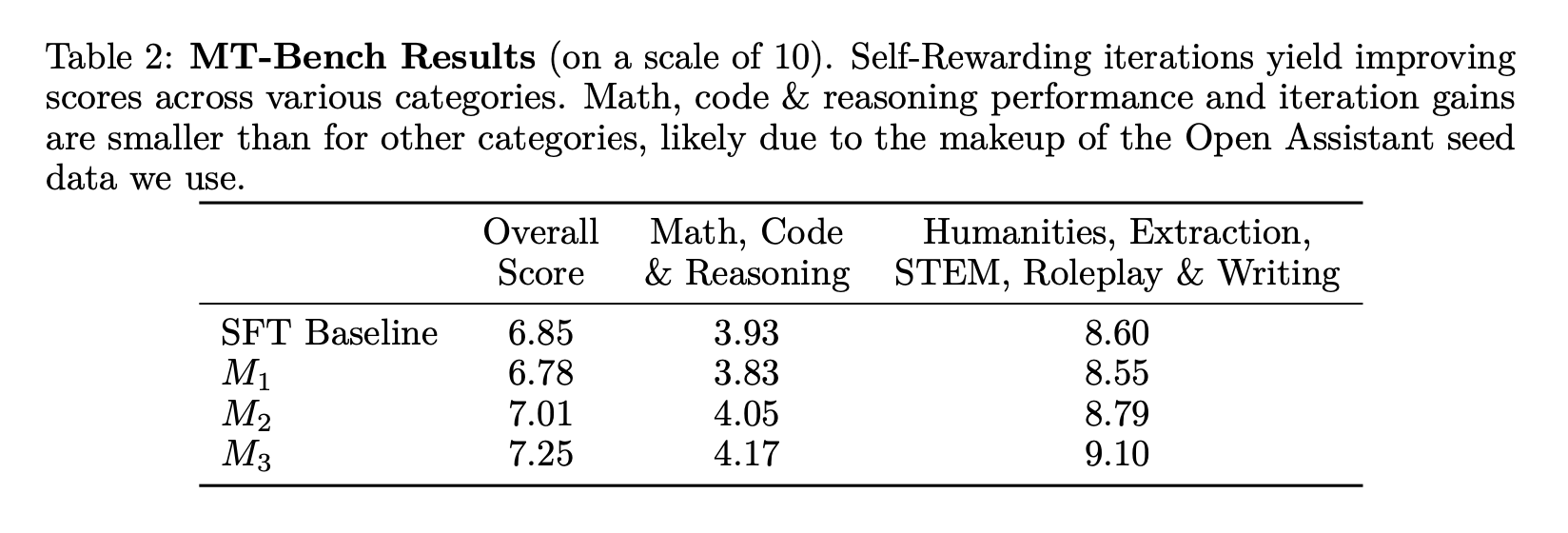
Overall this loop was not too hard to create given the open source tools and models that are out there today, and cost about $30 to reproduce in Google Collab. We will continue running experiments and uploading them to Oxen.ai as it is an interesting area of research to explore given the cost of labeling training data with humans.
Join the Oxen.ai Community
To continue the conversation, we would love you to join our Discord! There are a ton of smart engineers, researchers, and practitioners that love diving into the latest in AI.

If you enjoyed this dive, please join us next week live! We always save time for questions at the end, and always enjoy the live discussion where we can clarify and dive deeper as needed.

All the past dives can be found on the blog.
The live sessions are posted on YouTube if you want to watch at your own leisure.


Best & Moo,
~ The herd at Oxen.ai
Who is Oxen.ai?
Oxen.ai is an open source project aimed at solving some of the challenges with iterating on and curating machine learning datasets. At its core Oxen is a lightning fast data version control tool optimized for large unstructured datasets. We are currently working on collaboration workflows to enable the high quality, curated public and private data repositories to advance the field of AI, while keeping all the data accessible and auditable.
If you would like to learn more, star us on GitHub or head to Oxen.ai and create an account.
Oxen-AI