Uploading Datasets to Oxen.ai

Oxen.ai makes it quick and easy to upload your datasets, keep track of every version and share them with your team or the world. Oxen datasets can be as small as a single csv or as large as millions of image files. Unlike git or git-lfs, Oxen was built from the ground up to handle datasets of any size.
When we say quick, we mean raw speed. Oxen chunks and transfers data faster than your traditional version control system. When we say easy, we mean there is a minimal learning curve.
Many of the features are also directly available through the Oxen.ai web interface as well as a suite of developer tools. For developers there is a powerful command line interface and python library mirrors git so that you can get up and running in a breeze.
Create Data Repository
If you have not already, head to https://oxen.ai/register and create an account. Once you are logged in, you can create a data repository. Your list of repositories will show up in your home page.
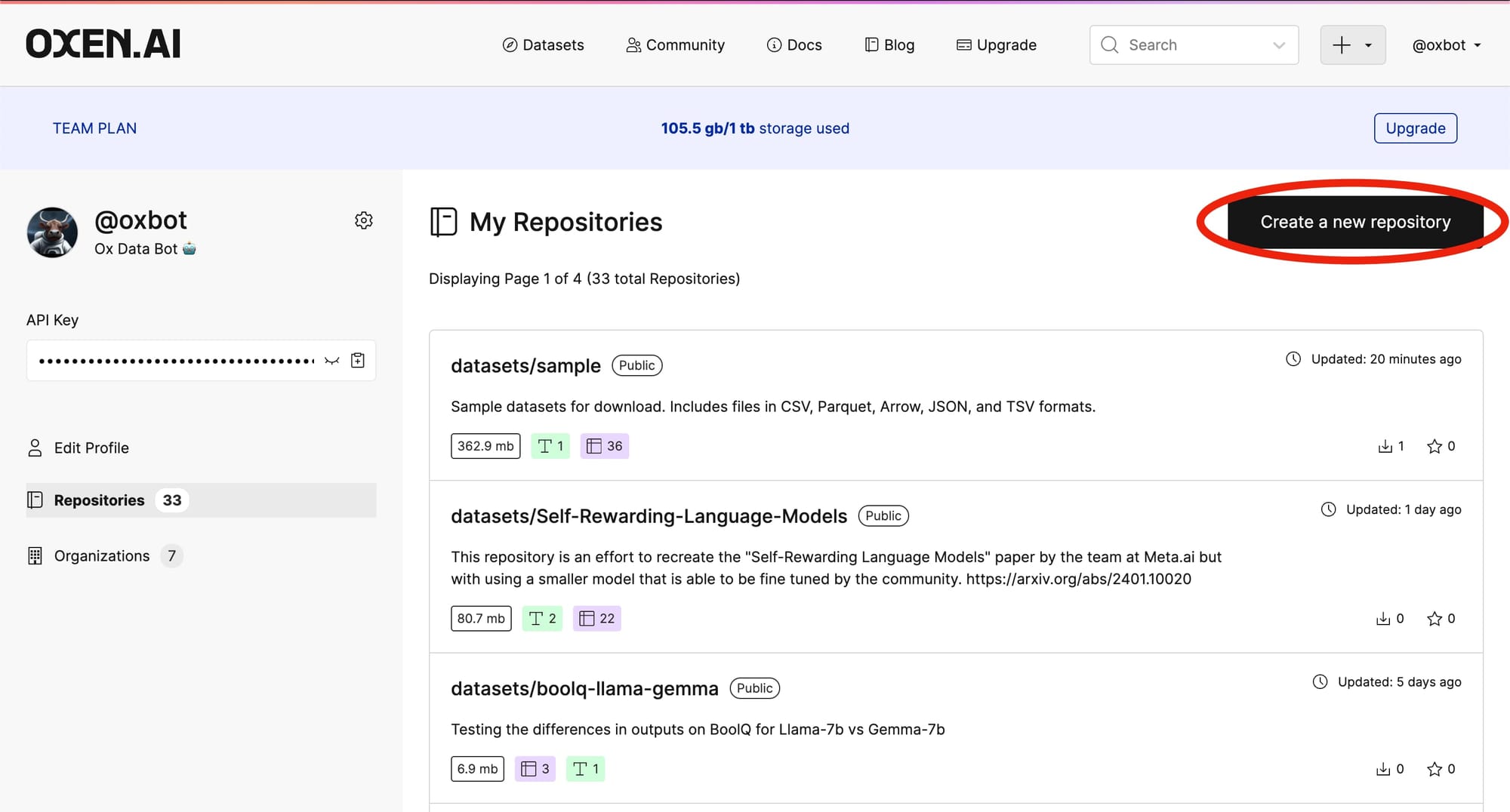
In this case we will be adding a tabular dataset for predicting house prices. You can make your repository public or private. If it is public anyone who lands on the page can view and download the data for their own use.
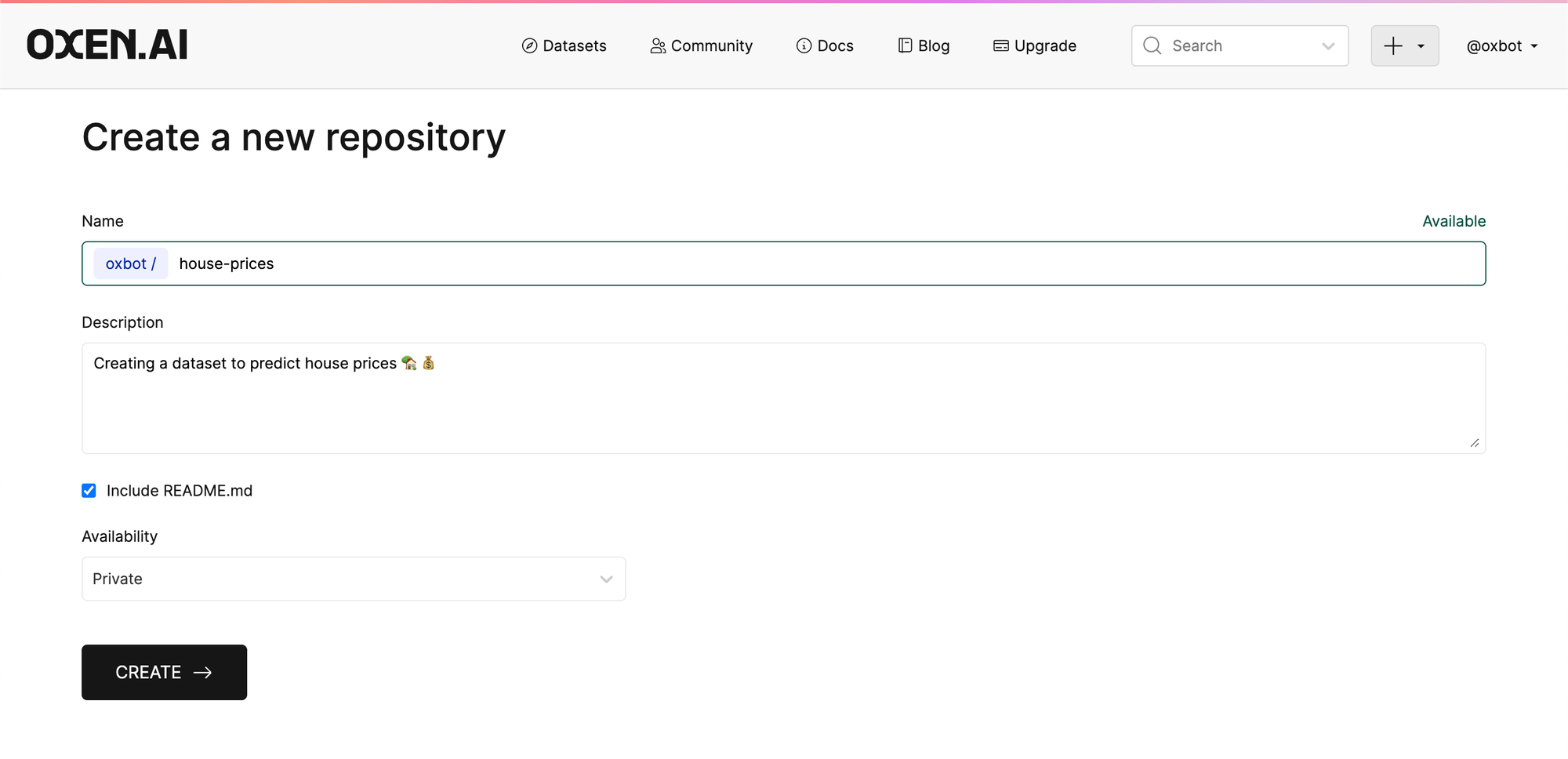
We recommend you including a README.md file to get started. The README.md file will automatically be created at the root of your repository and you can fill in with details about your dataset.
Add Files
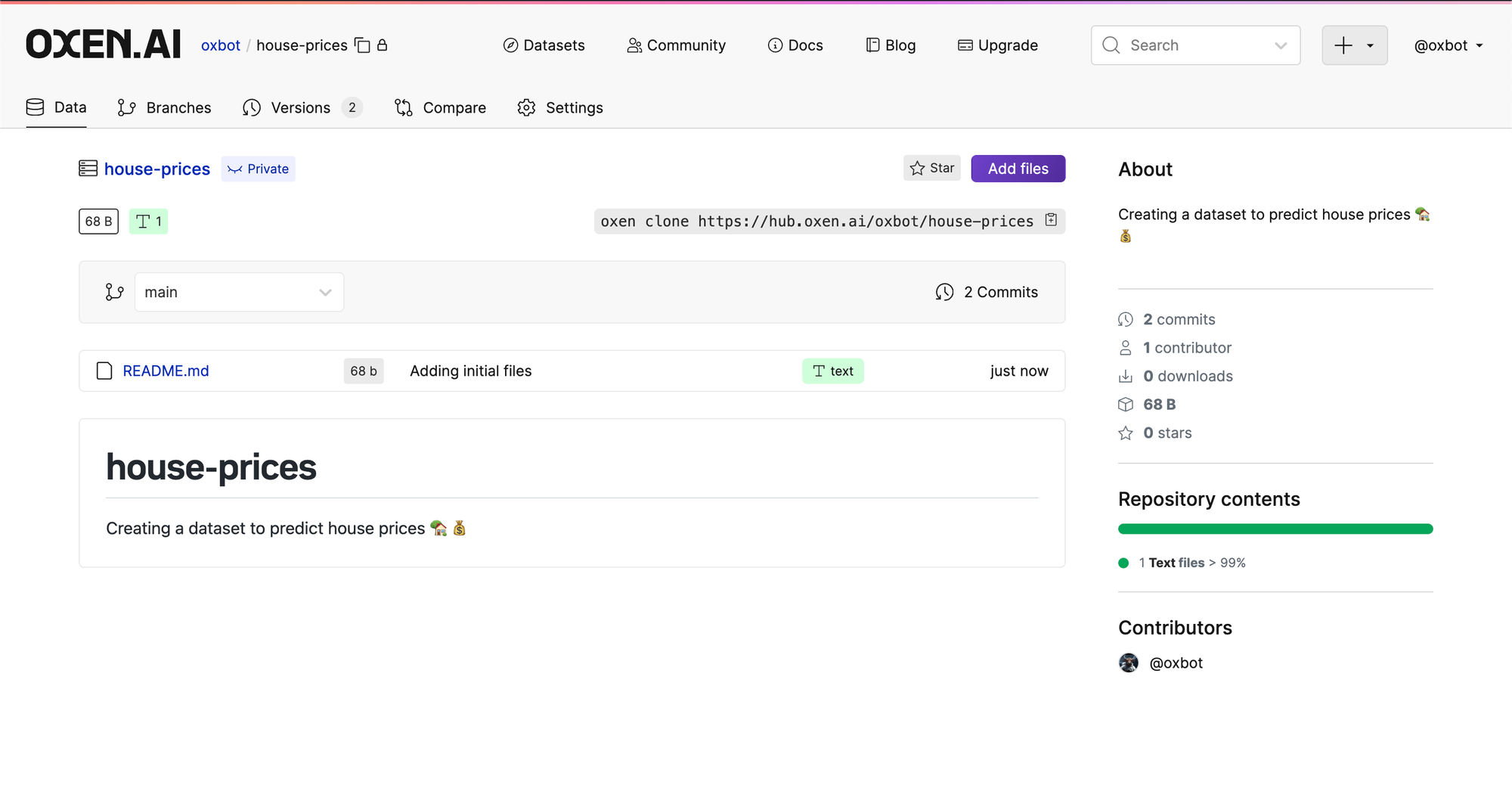
The easiest way to add data is directly through the user interface with the "Add Files" button above your link to clone.
Let's start by adding a CSV called House_price.csv to the repository. Feel free to download the CSV from Oxen.ai here.
oxen download datasets/sample csv/House_price.csv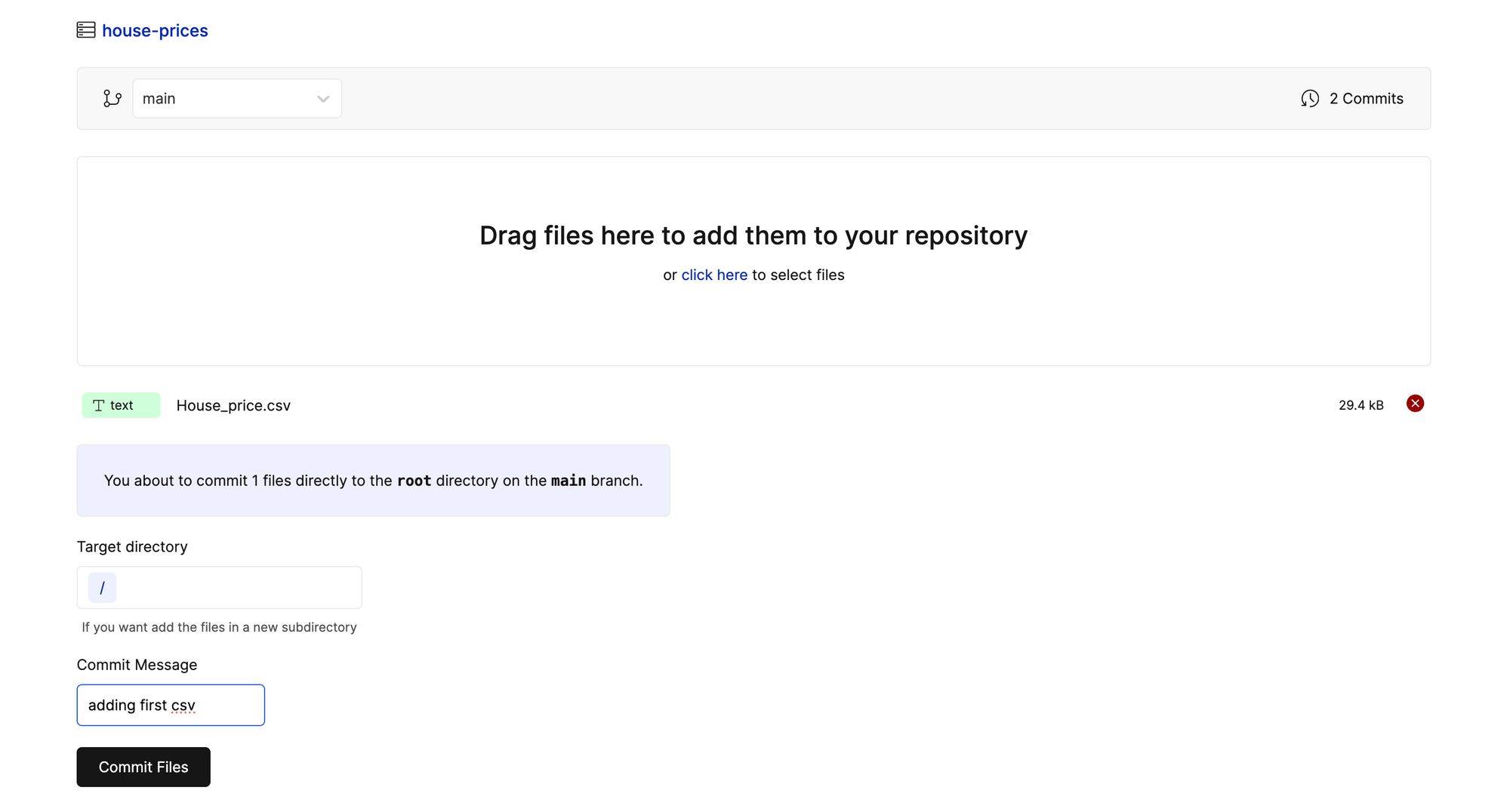
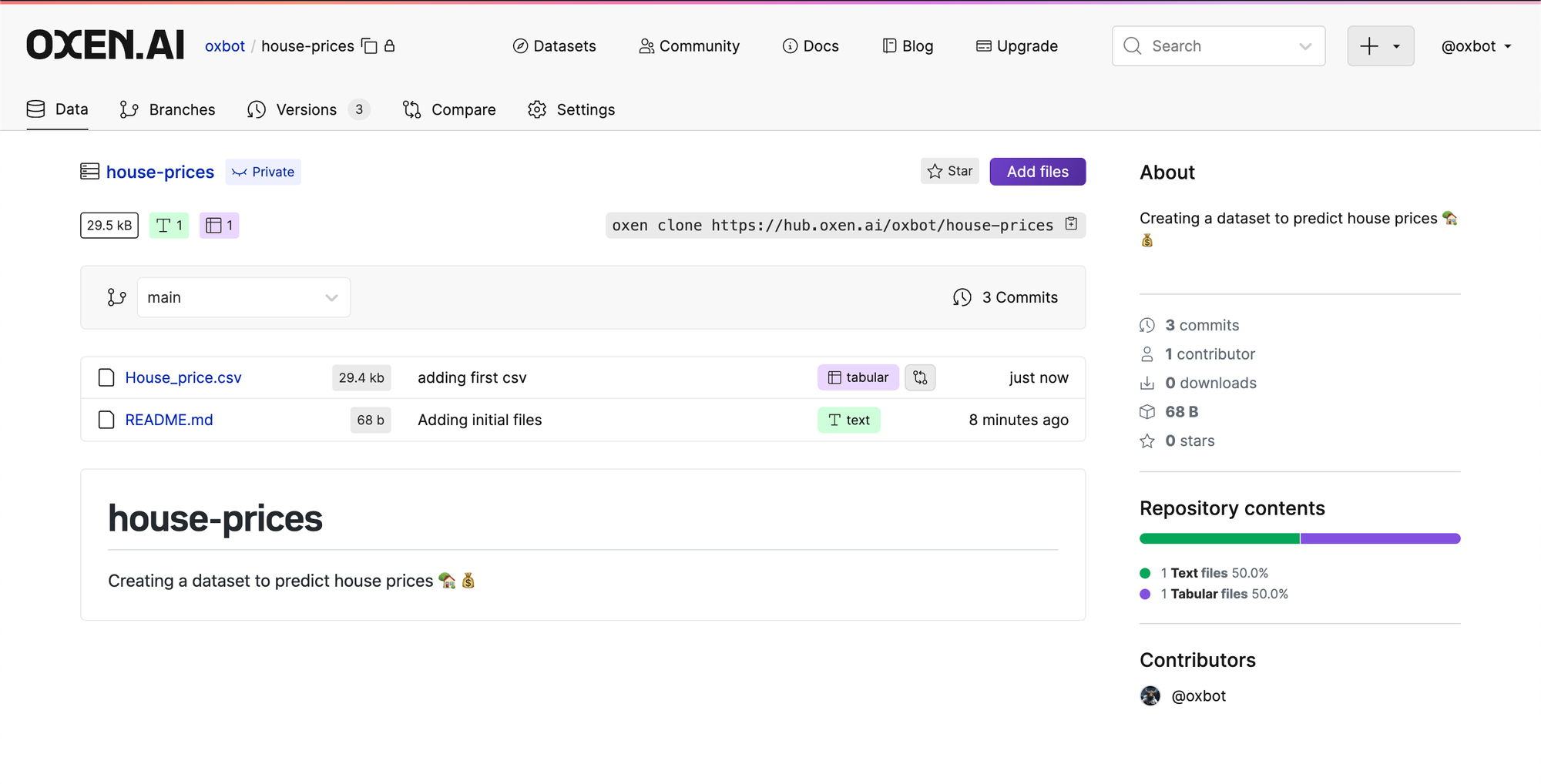
Then add a commit message that describes what you are doing, in this case "adding first csv". Click "Commit Files" and you will now see the file in the root directory!
Upload with CLI
The same functionality can be achieved in the command line interface or python library by using the upload function.
When uploading data from any of the developer tools, first you will need to setup your API Key. This ensures you have the correct permissions to upload to your data repository. Your API Key can be found in your profile page.

Setting up your API Key from the command line can be done through the oxen config command.
oxen config --auth hub.oxen.ai $YOUR_API_KEYAfter the API Key is configured, you can simply upload using the oxen upload command.
oxen upload $NAMESPACE/$REPO_NAME House_price.csv -m "adding first csv"Upload with Python
The same functionality can be achieved through python. First setup the API Key.
from oxen.auth import config_auth
# if you have not configured your API Key
if not oxen.is_configured():
config_auth(os.getenv("OXEN_API_KEY"))Then upload the dataset.
import os
from oxen.datasets import upload
upload("your_username/your_repo_name", "House_price.csv", message="adding first csv")Upload V2
Oxen.ai starts to shine when you update your datasets over time. Datasets in real world machine learning projects are not static, but are living breathing entities that evolve overtime. The house prices in the market yesterday are not the house prices today. Every time you train your model with new data, it is important to version the dataset that goes with it, so you can debug any new model behavior.
For the example's sake, edit the House_prices.csv file and remove a few rows. Upload the new dataset and you will be able to see a new commit in the Versions tab.
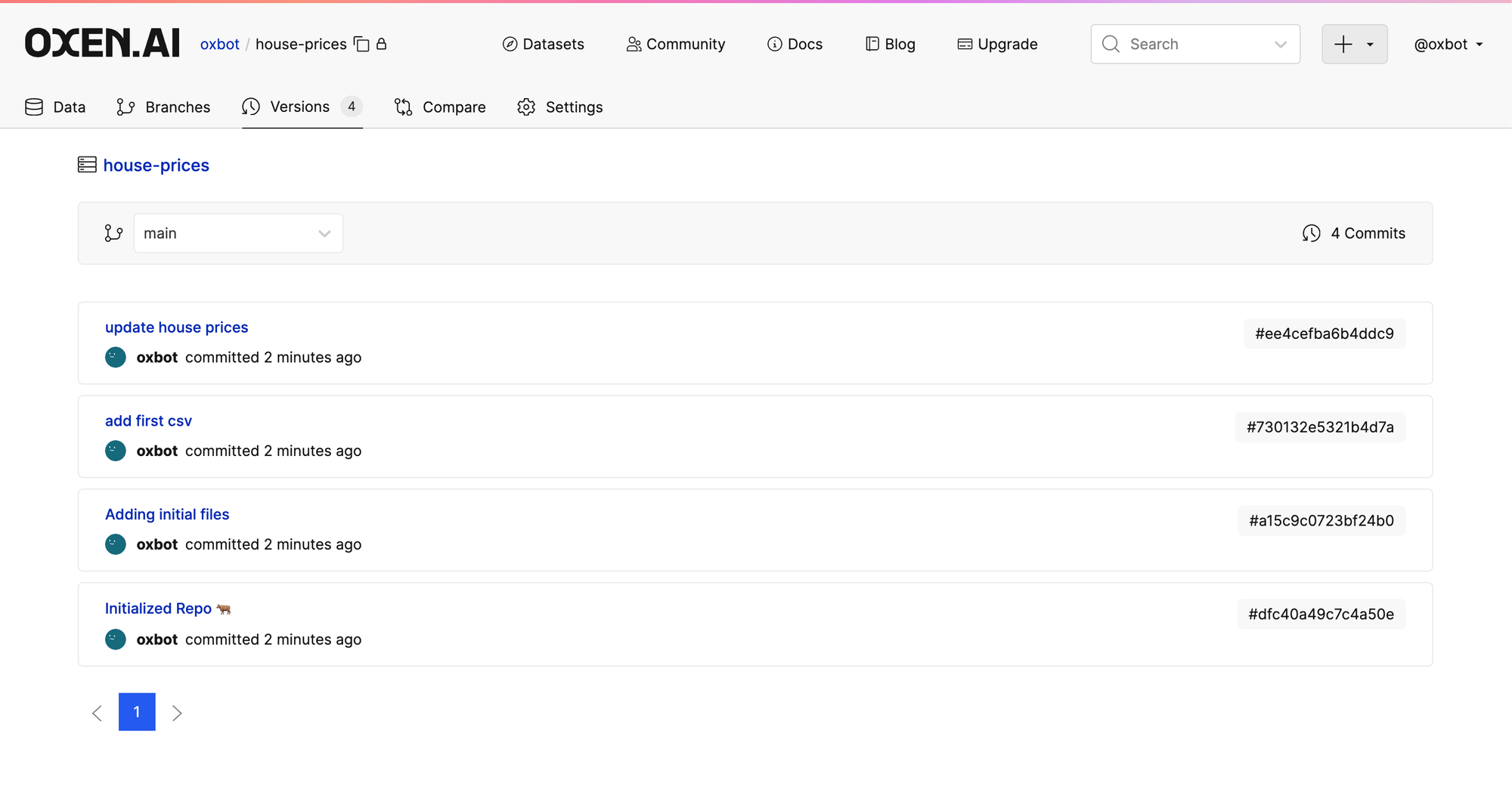
You can then use the commit ids on the right hand side to fetch any version of the data on download. Make sure to just grab the commit hash and not the leading #.
oxen download $NAMESPACE/$REPO_NAME House_prices.csv --revision ee4cefba6b4ddc9or in python
from oxen.datasets import download
download("your_namespace/your_repo", "House_price.csv", revision="COMMIT_HASH"Clicking through the specific commit in the UI will allow you to quickly get to all the changes that were made. In this case we removed 3 rows from the dataset.
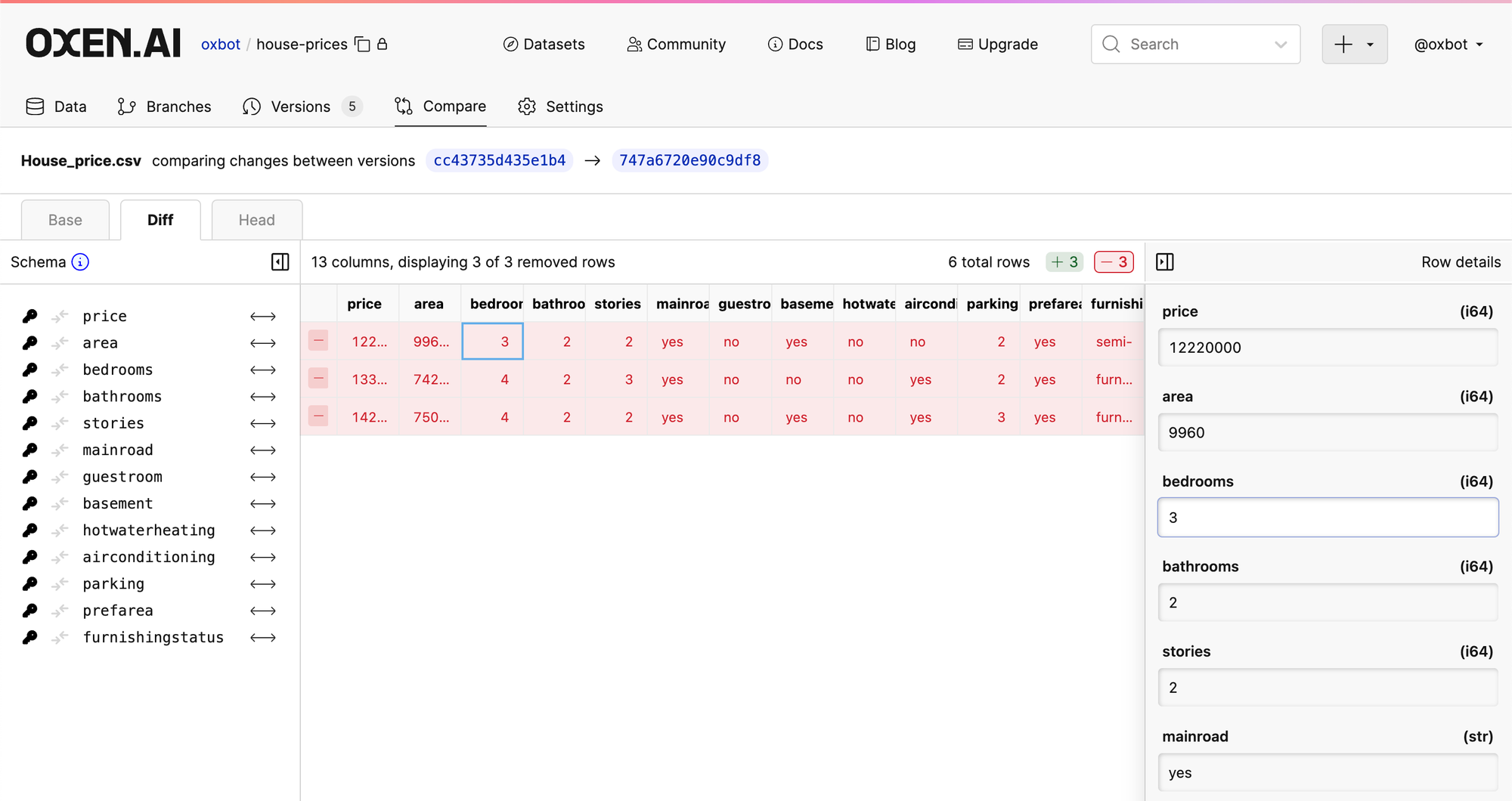
Congrats! You just versioned your first dataset with Oxen.ai. This was a rather simple example. If you want to start exploring the full power of Oxen, the best place to start is the developer docs.
