Practical ML Dive - Building RAG from Open Source Pt 1
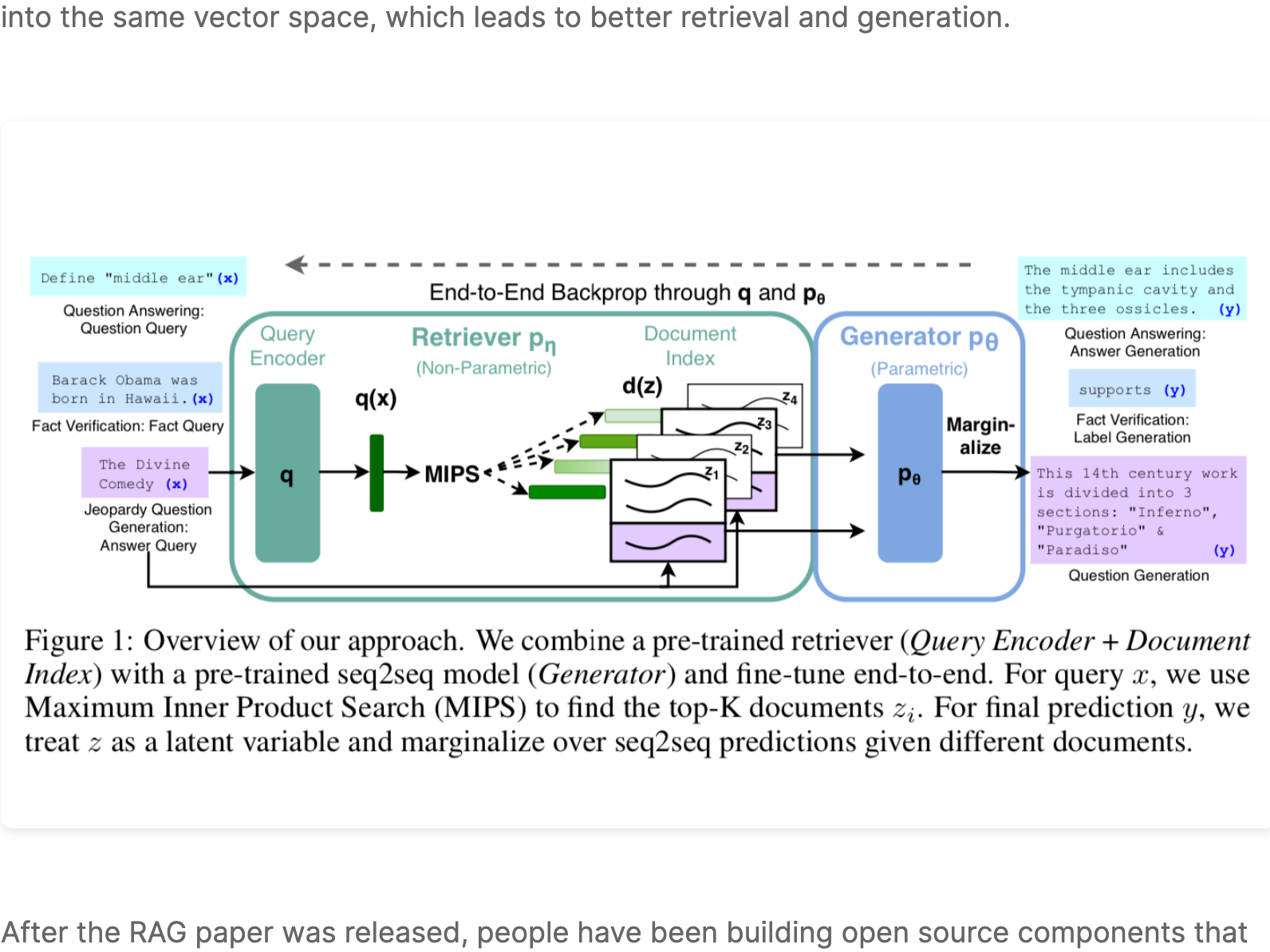

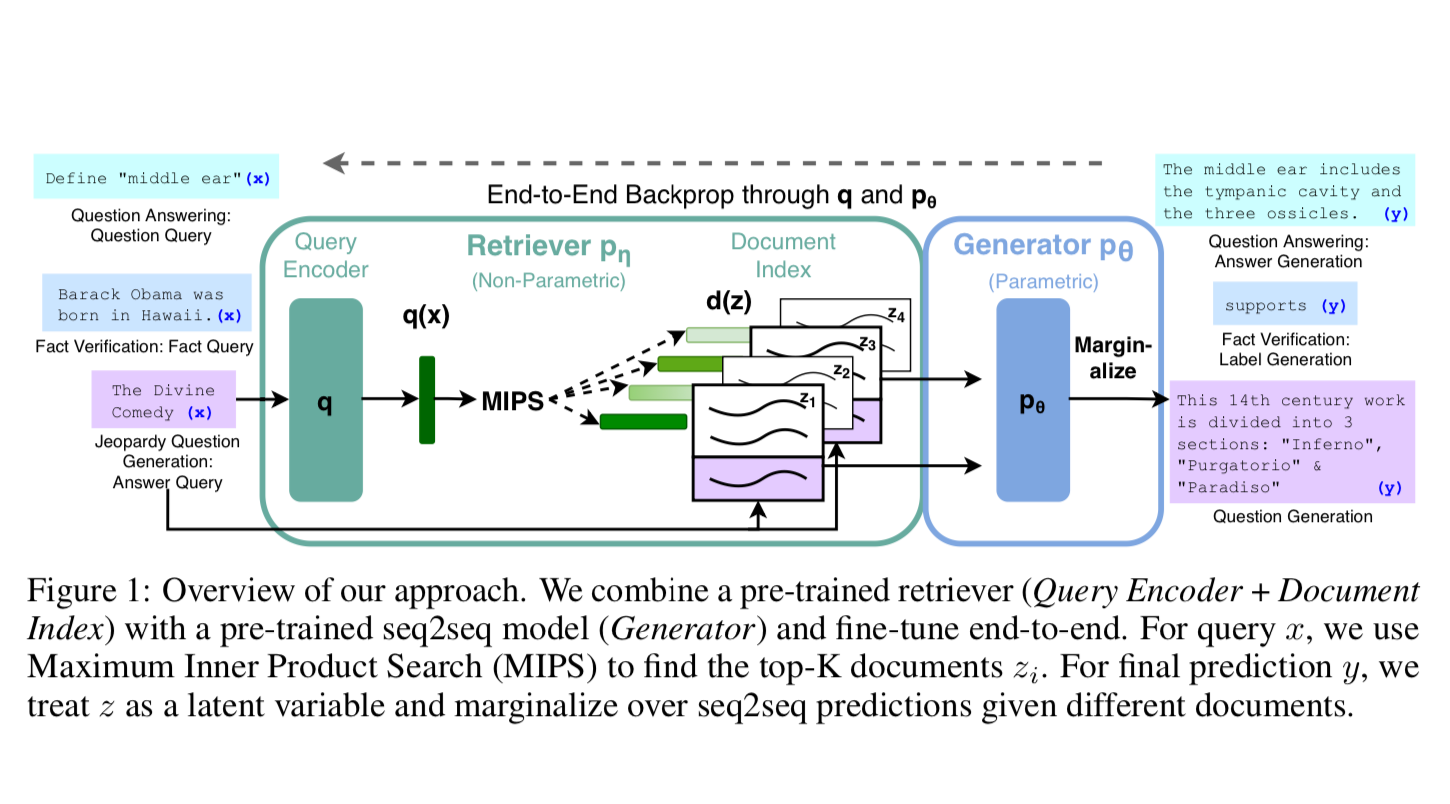
RAG was introduced by the Facebook AI Research (FAIR) team in May of 2020 as an end-to-end way to include document search into a sequence-to-sequence neural network architecture.
What is RAG?
For those of you who missed it, we covered the RAG paper back in September of 2023 on a previous Arxiv Dive.
 Greg Schoeninger
Greg Schoeninger
If you do not need to know about the internals, and just want to see how to apply a RAG-like system on your data, this is the blog post for you!
Practical ML Dive
This post is a part of a series called Practical ML Dives. Every Wednesday we get together and hack on real world projects. If you would like to join the practical discussion live, sign up here. Every week there are great minds from companies like Amazon Alexa, Google, Meta, MIT, NVIDIA, Stability.ai, Tesla, and many more.

The following are the notes from the live session. Feel free to watch the video and follow along for the full context.
What are we building?
This is a two part series, where we will build an end-to-end Question Answer system that fetches documents from a vector database, and uses these documents as context to answer a question. All the code will be available on GitHub.
 Oxen-AI
Oxen-AIThe components we will use:
- Oxen.ai will be used for storing the raw text, pre-computed embeddings, and model results.
- A General Text Embedding (GTE-large) model will be used for encoding the documents into vectors (embeddings)
- Modal will be used for server-less compute of the embeddings
- ChromaDB will be used for real time querying of the embeddings.
- Mistral 7B Instruct v0.2 will be used as the “reasoning engine” or Generator LLM on top of the results.
Today we will focus the first half of the QA pipeline of encoding and retrieving text so that we can answer questions. We will then evaluate our retrieval model given the embeddings and the SQuAD dataset.
In the next Practical Dive we will use the retrieved results with a Mistral 7B Model to answer a question given the context.
End-To-End Example
There are three main steps within RAG
1) Embed the user's question into vector space
2) Retrieve relevent documents as context
3) Generate an answer given the context
For Example:
User Question
Where was Beyonce's first child born?Retrieved Documents
Beyoncé Giselle Knowles was born in Houston, Texas, to Celestine Ann "Tina"
Knowles (née Beyincé), a hairdresser and salon owner, and Mathew Knowles,
a Xerox sales manager. Beyoncé's name is a tribute to her mother's maiden name.
Beyoncé's younger sister Solange is also a singer and a former member of
Destiny's Child.
Beyoncé Giselle Knowles-Carter (/biːˈjɒnseɪ/ bee-YON-say) (born September 4, 1981)
is an American singer, songwriter, record producer and actress.
Born and raised in Houston, Texas, she performed in various singing and
dancing competitions as a child.
On January 7, 2012, Beyoncé gave birth to her first child, a daughter,
Blue Ivy Carter, at Lenox Hill Hospital in New York. Five months later,
she performed for four nights at Revel Atlantic City's Ovation Hall to celebrate
the resort's opening, her first performances since giving birth to Blue Ivy.Generated Answer
Lenox Hill Hospital (New York)Why RAG?
Large Language Models have shown an impressive ability to store factual knowledge directly within their parameters. When we say “Neural network parameters” we are simply talking about a set of floats that get multiplied together, and when you train enough of them, start to show intelligent behavior.
parameters = [0.2, 0.1, -2.3, .... ] x N billionThe problem is, these parameters are typically static after you train them. It is expensive to train a neural network and update the parameters, so training often only happens once at the start.
In Andrej Karpathy’s “Intro to Large Language Models” video, he describes it as compression. You can think of an LLM as compressing a large corpus of data, like the internet.

The fact that this compression technique leads the neural network to learn a lot of facts about the world, but the world is not static.
Imagine we took a snapshot of your brain when you were 16 years old, and you are now 21. You would have had a lot of real world knowledge, and would be able to navigate the world, but 5 years later you would not know who the current president was or who won the last super bowl.
RAG is a technique that allows you to use the knowledge stored within the models parameters in combination with knowledge stored in external sources. The idea is that you “retrieve” knowledge from a vector database, then “augment” the “generation” from the model with the knowledge you retrieved.
RAG-like != RAG
Disclaimer: We should note we will be building a RAG-like system, not reproducing the paper itself.
The original RAG paper had a unified system between the generator and the query encoder. They performed end-to-end backpropagation through the generated response and the query encoder.
In theory the end-to-end nature of RAG allows you to encode the query and the documents into the same vector space, which leads to better retrieval and generation.
After the RAG paper was released, people have been building open source components that can stand in for the core text processing building blocks, and you can build a competitive system without training end to end.
The Open Source Components
What is nice about this general architecture, is we can swap in different LLMs and different tools at each step. Notably there are many different Encoder LLMs, vector databases, and Generator LLMs that we can try to fit our use case.
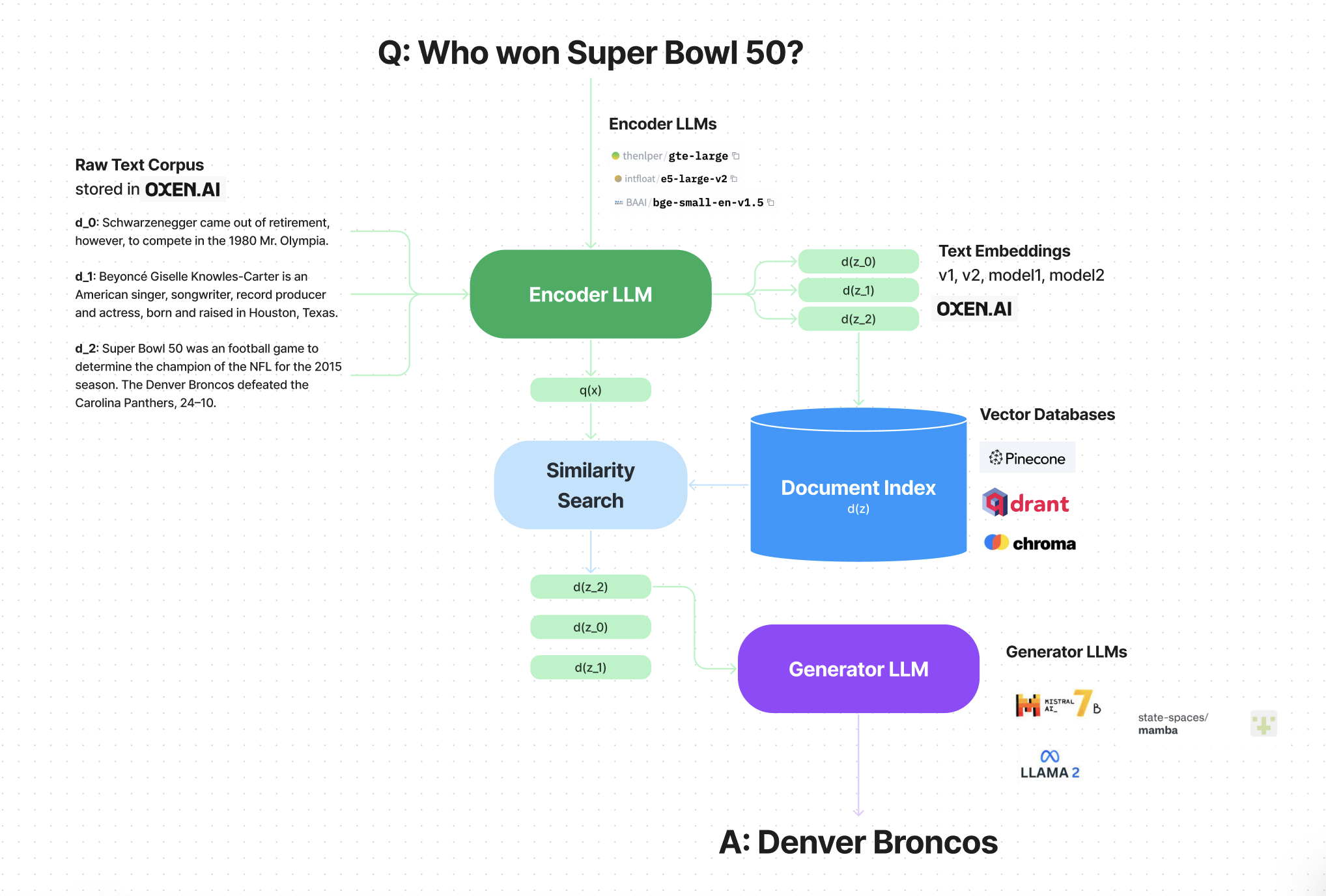
Text Corpora
The first thing we have to do is find a corpus of text or facts that we want to be able to answer questions about.
Example Text Corpora
- Wikipedia
- Legal documents
- Internal company documents
- Chat history
In this case we will be using a the SQuAD (Stanford Question Answering) dataset, which is a subset of wikipedia. SQuAD has labeled “question, document, answer” triples to help evaluate question answering systems.

Text Encoding
If we look at the SQuAD dataset above, we notice that there are many questions for each document.
We will split this dataset into two parts and store it in Oxen.ai

The first part is context + question ids, the second part is just questions + answers. This way we can break our pipeline into our three stages.
- Encoding the context
- Retrieving the context given the question
- Generating the answer
Collapsing all the contexts and linking to the question IDs will allow us to evaluate how well our retrieval system can retrieve a document, given a question.
The context and question ids can be found here and looks like the following
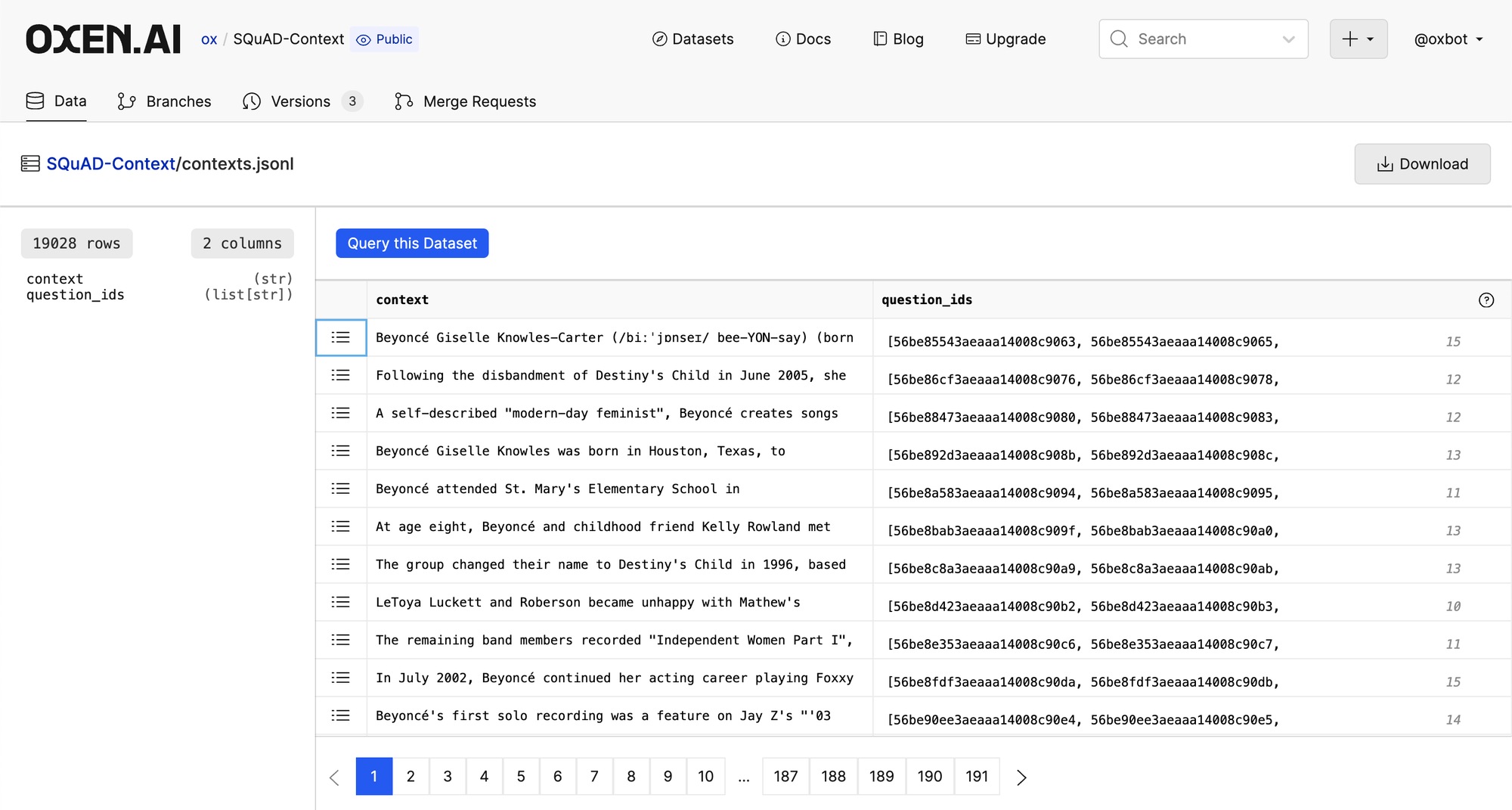
Next we have the question+answer pairs also linked to the question ids.
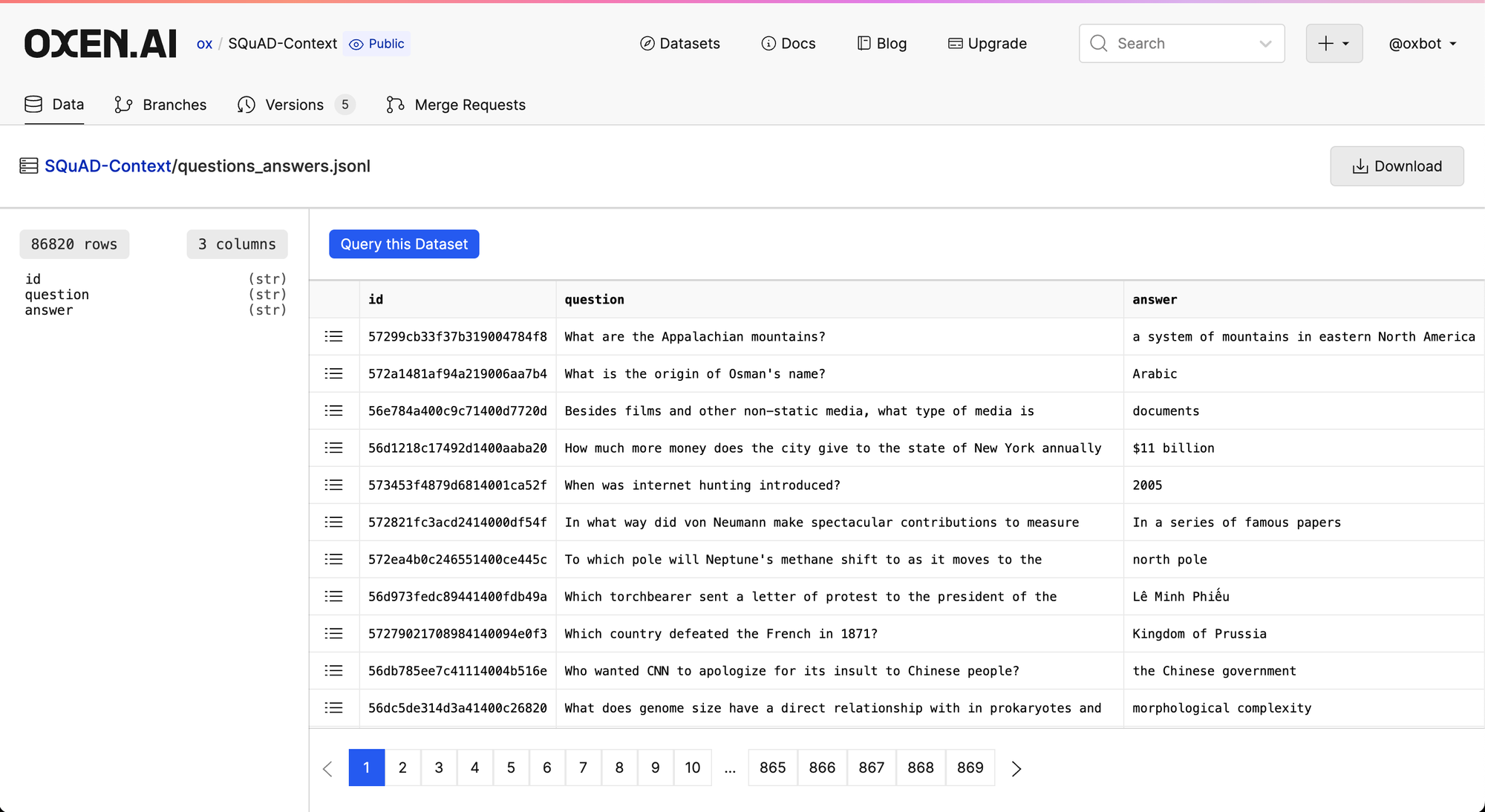
With the datasets split into their parts we can use Modal.com to encode all of the context into embeddings.
Modal + GTE Embeddings
Modal.com is a compute platform that lets you run server-less functions on high end hardware such as GPUs. This is ideal for the job of batch processing ~20,000 documents into their embeddings.
All the code for this step can be found on GitHub:
Oxen-AIFirst we setup a remote embedding server on the Modal cloud.
modal serve embeddings.pyThen we run the same script to connect to the server and compute embeddings.
modal run embeddings.pyWhat is great about Modal, is that you can run both of these commands from your local laptop without having to have an NVIDIA GPU, and it all cost under $2.

GTE Embeddings
This script uses Hugging Face’s Text Embedding Interface which can serve up embeddings from a variety of models.
In this case we are using a “General Text Embeddings (GTE) model” called thenlper/gte-large .

If you want to learn more about how the embeddings are computed they have a research paper.
~ TLDR ~ GTE uses a multi-stage contrastive learning curriculum to make sure that queries and documents get embedded into the same latent space. Think of it as CLIP, but instead of Image-Text pairs, you are embedding Text-Text pairs.
The embeddings.py script also uploads the embeddings in a parquet file to Oxen.ai so that we can distribute it to our team for different experiments.
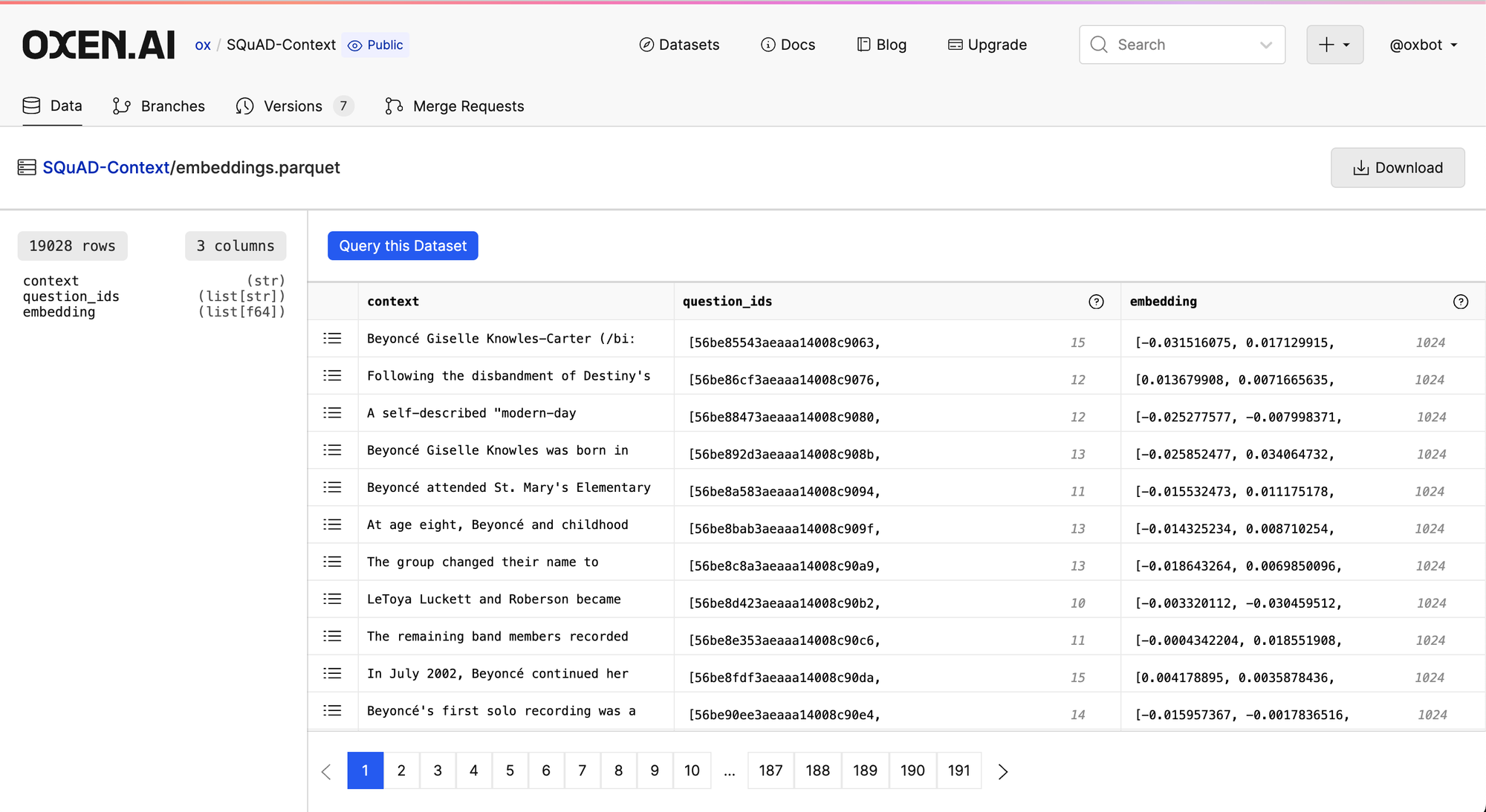
It is nice to separate the embedding computation from the indexing into a vector db, so that we can iterate on versions, try a different encoder models, and revert to the state of our embeddings at any time. Oxen.ai is a great way to store different versions of these embeddings that we can distribute to team members or other organizations building downstream applications.
Document Retrieval
We will be using Chroma for the similarity search and retrieval portion of the QA of the pipeline. Chroma has a simple python interface for creating a local database, and indexing the vectors with their respective documents and metadata.
Indexing the Embeddings
First we must create a database and insert all the embeddings and their metadata.
Oxen-AIimport chromadb
# Create client
chroma_client = chromadb.PersistentClient(path="chroma.db")
# Create database
collection_name = "squad_embeddings"
collection = chroma_client.create_collection(name=collection_name)
# Read embeddings
embeddings_file = "embeddings.parquet"
df = pd.read_parquet(embeddings_file)
# Index embeddings + documents + question ids
for index, row in tqdm(df.iterrows()):
question_ids_str = ",".join([str(x) for x in row["question_ids"]])
collection.add(
embeddings=[row["embedding"].tolist()],
documents=[row["context"]],
metadatas=[{"question_ids": question_ids_str}],
ids=[f"{index}"]
)This will create directory called chroma.db that we can then query given a new document.
Querying the Embeddings
Now that we have our vector database, it is time to query it to get a sense for how well it returns documents.
import chromadb
# Connect to chromadb
chroma_client = chromadb.PersistentClient(path="chroma.db")
collection_name = "squad_embeddings"
collection = chroma_client.get_collection(name=collection_name)
# User prompt to see what comes back
while True:
text = input("> ")
# Function to compute embeddings, see https://huggingface.co/thenlper/gte-large
embeddings = compute_embedding(text)
# Query given an embedding
result = collection.query(
query_embeddings=embeddings,
n_results=10,
)
# The query returns any documents and meta data that we added to the index
metadatas = result['metadatas'][0]
documents = result['documents'][0]
for i, document in enumerate(documents):
question_ids = metadatas[i]['question_ids'].split(",")
print(question_ids)
print(document)
print()Evaluating the Retrieval
The answer is not guaranteed to be in the top retrieved document. In fact it might not even be in the top 3, 10, or 100. Information retrieval is a long studied problem on it’s own, and we cannot expect an embedding retrieval model to be perfect.
In this case we know that all of the answers are in the index somewhere we just have to see how well our encoder can retrieve them, given a question. We have about 20k documents, so if we can get the correct passage within the top 10, we are doing pretty well.
I ran a few experiments to compute Recall with different top N retrievals to see how well the GTE-large embeddings encode the questions and the documents.
The nice thing about the way we setup the datasets, is we know the question-document pairing that we are looking for, so we can simply see if we return the correct question id with the document given a question embedding.
python compute_recall.py results/train_1k.jsonl results/search_results.jsonlWe can see that top 1 Recall is actually reasonably high. 63% of the time we return a the exact document we need to answer the question. As we work our way up to N=100, we can increase recall all the way to 97%.
Recall @N
@1 = 63.1
@3 = 78.7
@5 = 82.7
@10 = 86.9
@20 = 92.6
@50 = 95.9
@100 = 97.3
Next Up
This is very encouraging first step in our pipeline! If we know the answer is hidden somewhere within the first 100 documents, now all we need to do is have our final LLM extract it.
Next week we will be looking into how we can use Mistral 7B (or other models) to extract answers from the context we retrieved. Once we have done this, we can compute the overall Accuracy of our model as well as the Precision of the model given the Recall .
Precision will help us answer “how well did we answer the question, given we had the correct context available”, since we are not always going to fetch context that contains the answer.
If you want to take a sneak peek at the code to do this, it is already finished 😎 just needs some cleaning up before we dive in next week.
Oxen-AIOur first step seems promising in terms of Recall but we will see how well a model like Mistral 7B works in terms of accuracy next week.
Join the Community
To find out what paper we are covering next and join the discussion at large, checkout our Discord:

If you enjoyed this dive, please join us live next week!

All the past dives can be found on the blog.

The live sessions are posted on YouTube if you want to watch at your own leisure.


Best & Moo,
~ The herd at Oxen.ai
Who is Oxen.ai?
Oxen.ai is an open source project aimed at solving some of the challenges with iterating on and curating machine learning datasets. At its core Oxen is a lightning fast data version control tool optimized for large unstructured datasets. We are currently working on collaboration workflows to enable the high quality, curated public and private data repositories to advance the field of AI, while keeping all the data accessible and auditable.
If you would like to learn more, star us on GitHub or head to Oxen.ai and create an account.
Oxen-AI