🧼 SUDS - A Guide to Structuring Unstructured Data


At Oxen.ai we value high quality datasets. We have many years of experience training and evaluating models, and have seen many interesting data formats. Interesting is something we should optimize for when it comes to content of a dataset, not the format.
In order to try to standardize dataset formats, we propose a Simple Unstructured Data Schema (SUDS) for cleaning up unstructured data. Unstructured data is the lifeblood of modern AI systems, but can be hard to query, aggregate, stream and use in downstream applications. SUDS provides a simple framework as a jumping off point to solve many of these problems.
The 🧼 SUDS Framework
Unstructured data should be clean, well-organized, shareable, extendable, and suitable for streaming.
If the format below seems too simple or obvious, that’s the point. SUDS meant to keep data simple to understand and easy use for anyone to hop into a dataset without much background or context.
KISS (Keep It Simple Stupid)
In order to illustrate the framework, let’s start with a quick example directory structure. Imagine you are doing image classification and have many image files that are labeled with a class such as “bird”, “car” or “dog”.
# Example Directory Structure
data/
images/
*.jpg
annotations/
train.csv
test.csvThe .csv could be csv, jsonl, parquet or any other structured data frame format with a column that specifies the relative path to the unstructured data. For example:
shape: (5_000, 3)
┌─────────────────┬──────────┬──────────────┐
│ image ┆ category ┆ category_idx │
│ --- ┆ --- ┆ --- │
│ str ┆ str ┆ i64 │
╞═════════════════╪══════════╪══════════════╡
│ img/1/2119.png ┆ airplane ┆ 1 │
│ img/1/3424.png ┆ airplane ┆ 1 │
│ img/1/4917.png ┆ airplane ┆ 1 │
│ img/1/3616.png ┆ airplane ┆ 1 │
│ … ┆ … ┆ … │
│ img/10/4184.png ┆ truck ┆ 10 │
│ img/10/654.png ┆ truck ┆ 10 │
│ img/10/2398.png ┆ truck ┆ 10 │
│ img/10/4658.png ┆ truck ┆ 10 │
└─────────────────┴──────────┴──────────────┘If you are following so far, that's good. Like I said. Simple.
Three Tenets & Rules
There are three key tenets and three rules to the 🧼 SUDS framework that can help guide formatting and structuring the data. The tenets are core beliefs or principles that guide the rules that we can put into practice.
Three Tenets
- Data Simplicity
- Data Consistency
- Data Usability
Three Rules
- Data should be organized in data frames with well defined schemas.
- Data should be human readable and easy to query.
- Data and code should be not be tightly coupled.
Concretely, when you have data in this format relative path names and structured schemas it allows you to do nice visualizations like we have in Oxen.ai
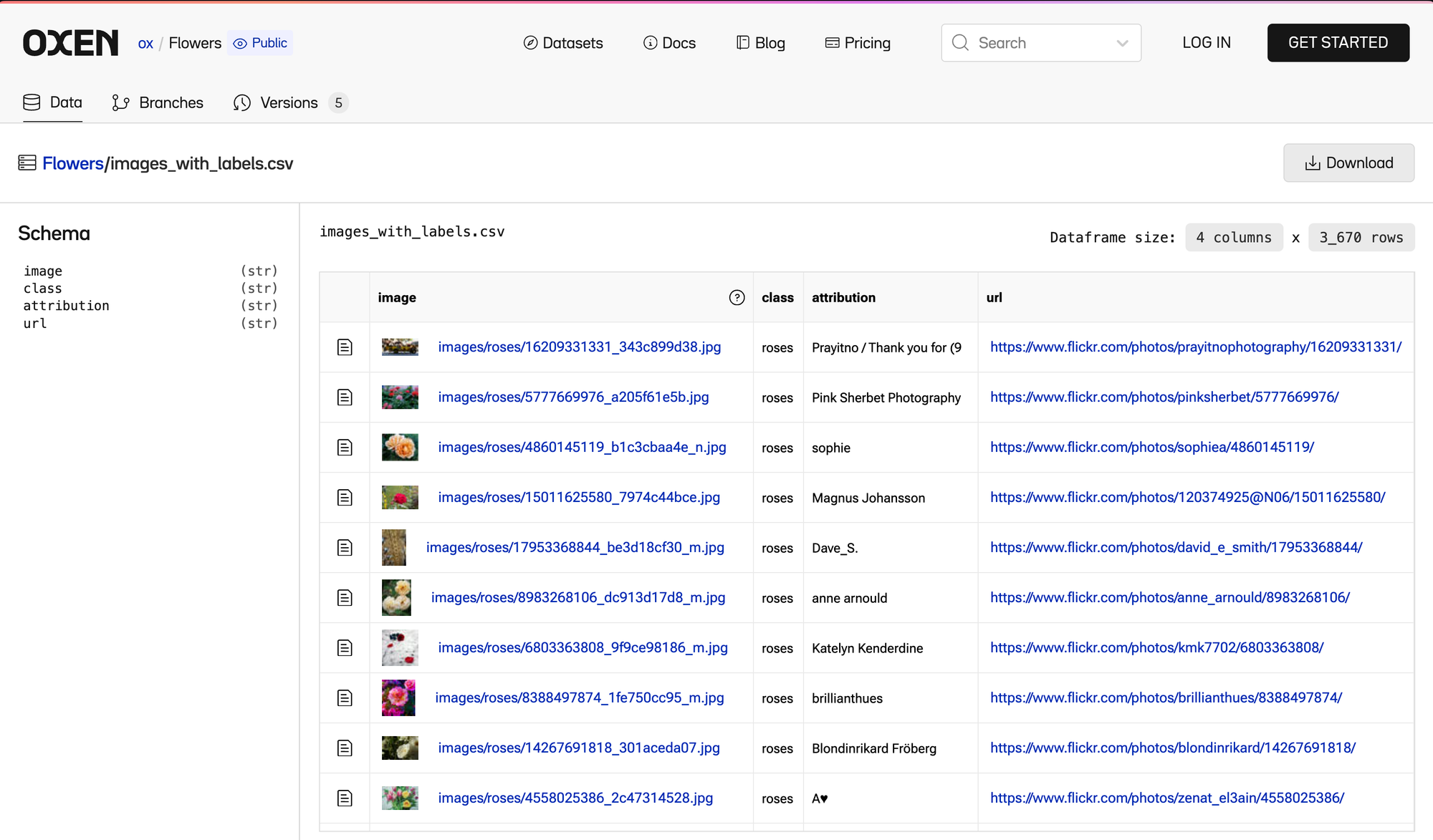
Using a combination of structured data schemas and optimizing for human readability, SUDS enables faster data exploration, querying and streaming. This leads to better human understanding of datasets and for engineers to get up and running faster with datasets.
Unstructured data comes in many forms
Before getting too deep into SUDS, let’s dive into the types of datasets we are talking about.
When it comes to organizing, storing, and sharing unstructured data, it is the Wild-Wild West. In this context we consider images, videos, audio, text, etc all as unstructured data. These data types are the inputs to many modern AI systems such as large language models, large scale computer vision models, and other GenerativeAI models.

The problem is, unstructured data does not fit cleanly into rows and columns of a relational database. This means it gets stored in a variety of formats, and it is important to standardize on some rules of the road.
How not to store unstructured machine learning datasets
There are many examples of poorly formatted, hard to use datasets. Instead of listing them all here, see our post on how not to store unstructured machine learning datasets.
Typically unstructured data is tied to structured data annotations; such as the category that some text falls under or key points within an image. Tying structured annotations to the unstructured data helps the model learn what the raw pixels in images or characters in text mean.
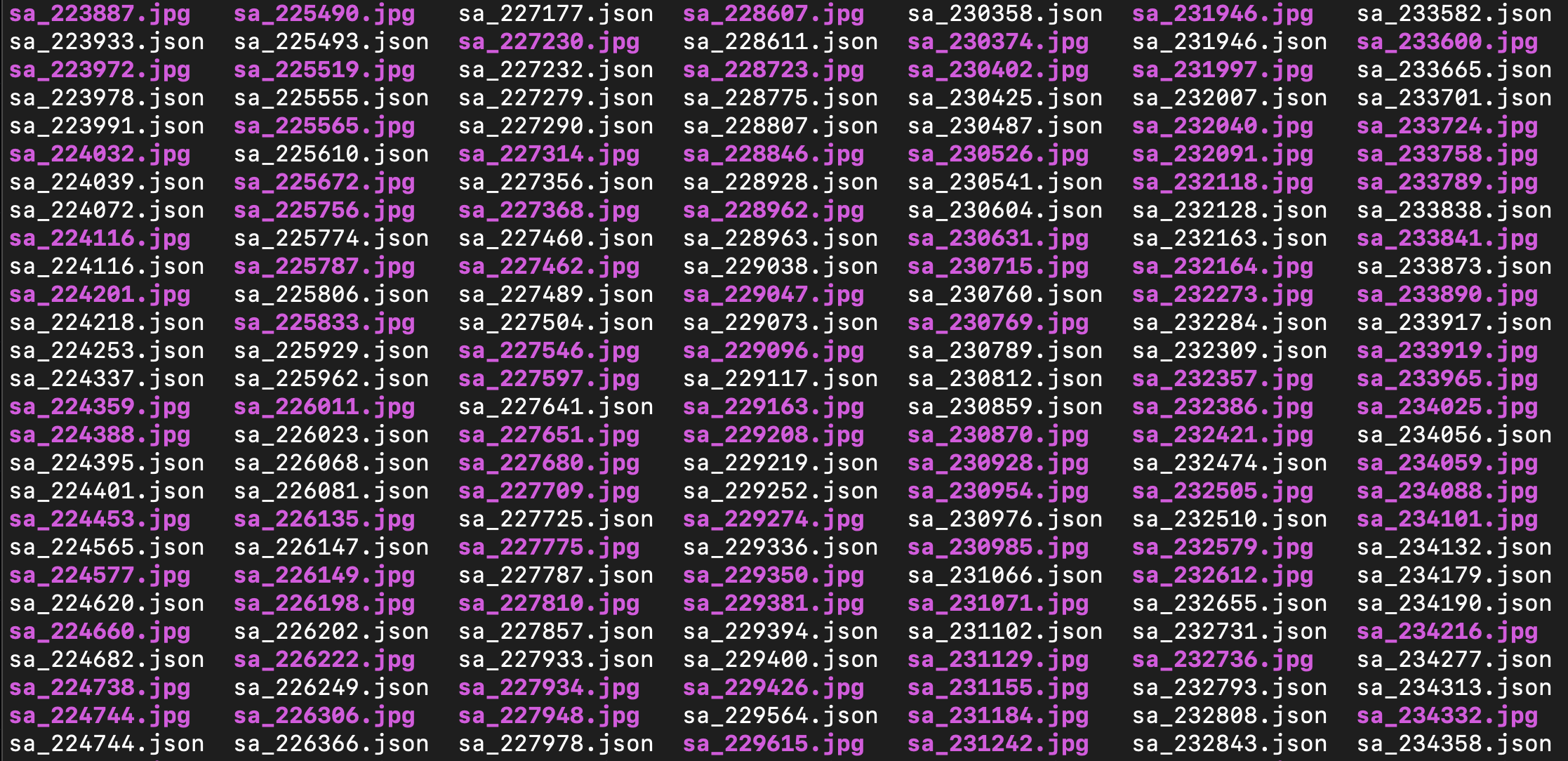
The above image is a screenshot from the original Segment Anything dataset, which is a large scale modern computer vision dataset. It has tied the annotations to the image via matching filenames. This is may seem like a convenient simple way to store the dataset, but is awful and hard to work with for a host of reasons.
Since the data itself does not fit cleanly into a database, each dataset tends has a different format and convention. Every time our team downloads a dataset, there is extra work to get up and running. Each convention has its pros and its cons, but the lack of consistency makes really hard for downstream code to adapt and iterate.
Unstructured data is inherently hard to query and aggregate, and it is worth the extra work of structuring it in a consistent format for data scientists and engineers to get a full sense of what is inside it and use it in downstream applications.
What does 🧼 SUDS look like in practice?
Let's get into more practical details about the pros and cons of what SUDS looks like.
The Tenets
Simplicity means anyone can land in a directory with data and immediately grok what is going on, and what the dataset can be used for.
Consistency means we have well defined locations for data and don’t have to write slightly different data loaders any time we want to train a model or do exploratory data analysis.
Usability means we can view, query, download, or stream the data into many tools as fast as possible so that we are not waiting on a 50GB tarball to download before we can get started.
The Rules
In order to optimize for simplicity, consistency, and usability, the framework has three simple rules of the road.
Rule 1) Data should be organized in data frames. This means every data point should fit cleanly into rows or columns. Data frames can come in many formats such as csv, jsonl, parquet or arrow files. CSVs or line delimited json files should have schemas so that the data is well defined, and can be shared, merged, or imported into other data systems.
Rule 2) Unstructured data should be human readable and live in its own column linked out to with relative paths or fully qualified URLs. Separating structured data into columns linked to unstructured data makes it easier to find a need in a haystack or get a general sense of distributions of the dataset.
Rule 3) Data processing code should be stored in auxiliary repositories or directories separate from the main data. Data should be in a predictable place for the code to reference and access. This means you can have a many-to-many relationship with data and code. Many datasets could be used for the same data loader. Many models could be used with the same data.
Example Datasets
Let's show not tell. Here are some examples to get a sense of the flexibility and simplicity of the format.
Speech To Text
Link out to the audio files with a relative path to the root of the data repository. Have a separate column for the speaker so you can aggregate and balance the distributions, have a column for the raw text you want as output.

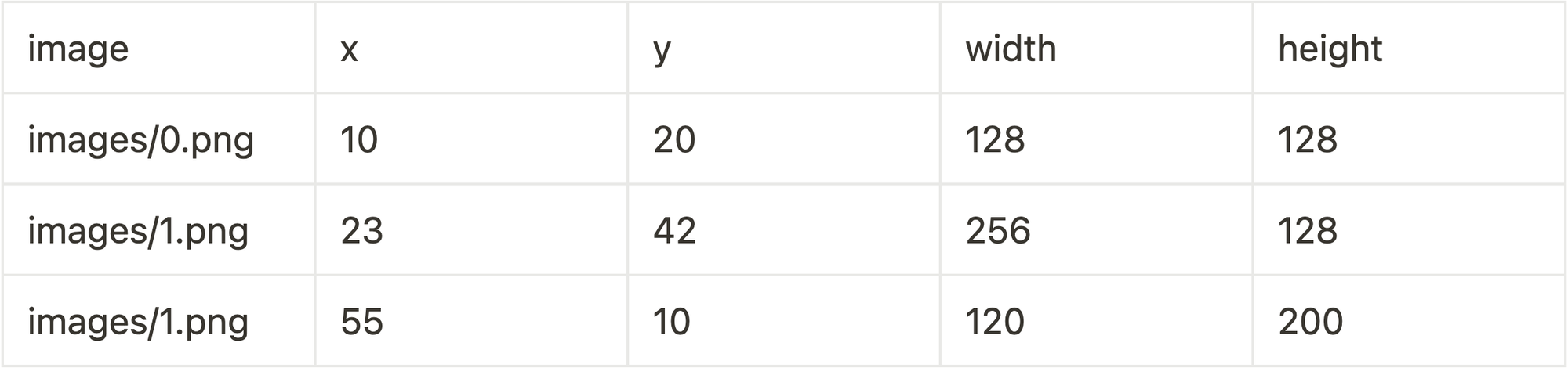
Image Bounding Box
Link out to the images with a relative path to the root of the repo, then put the x and y coordinates as well as width and height in their own column. If there are multiple annotations per image, make a separate row. You can aggregate on the image column to find all the bounding boxes per image if you need.
LLM Fine Tune
Here we can fit the text directly in the columns themselves. You could also link out to external text files or IDs into a vector database, but this is the format that most fine tuning workflows take in. Notice the column for the source to allow you to get a sense of the distribution of the dataset. You may not want too many examples of stories or trivia etc.

Hopefully this gives you a jumping off point, and you can extrapolate to other data types.
Benefits and Tradeoffs
With any framework there are benefits and tradeoffs between performance, usability, understandability, and practicality. We dive into each of the rules and how they support a tenet below, while also acknowledging what the trade offs are with this approach.
Rule 1: Data Frames
The data should have top level data frames in the form of csv, jsonl, or parquet that one could peek at with any tool that ingests tabular data (think pandas, polars, excel etc) and immediately get a sense of what is in the data.
There are benefits and drawbacks to each flat file format, but most data libraries can load and convert between them. Worst comes to worst, anyone on the team (technical or non-technical) could load a csv into their program of choice and get up and running.
Apache Arrow is a great format for random access into massive data frames, and parquet is a nice compressed representation that has many advantages over csv or jsonl.
Rows and columns should be able to be aggregated, concatenated, and streamed as needed. Formats like csv, parquet, arrow, jsonl are easy to stream into training loops or just grab the slice you need for exploratory data analysis.
For example if you want to get a class distribution from a data frame, you can write a quick SQL query to do so.
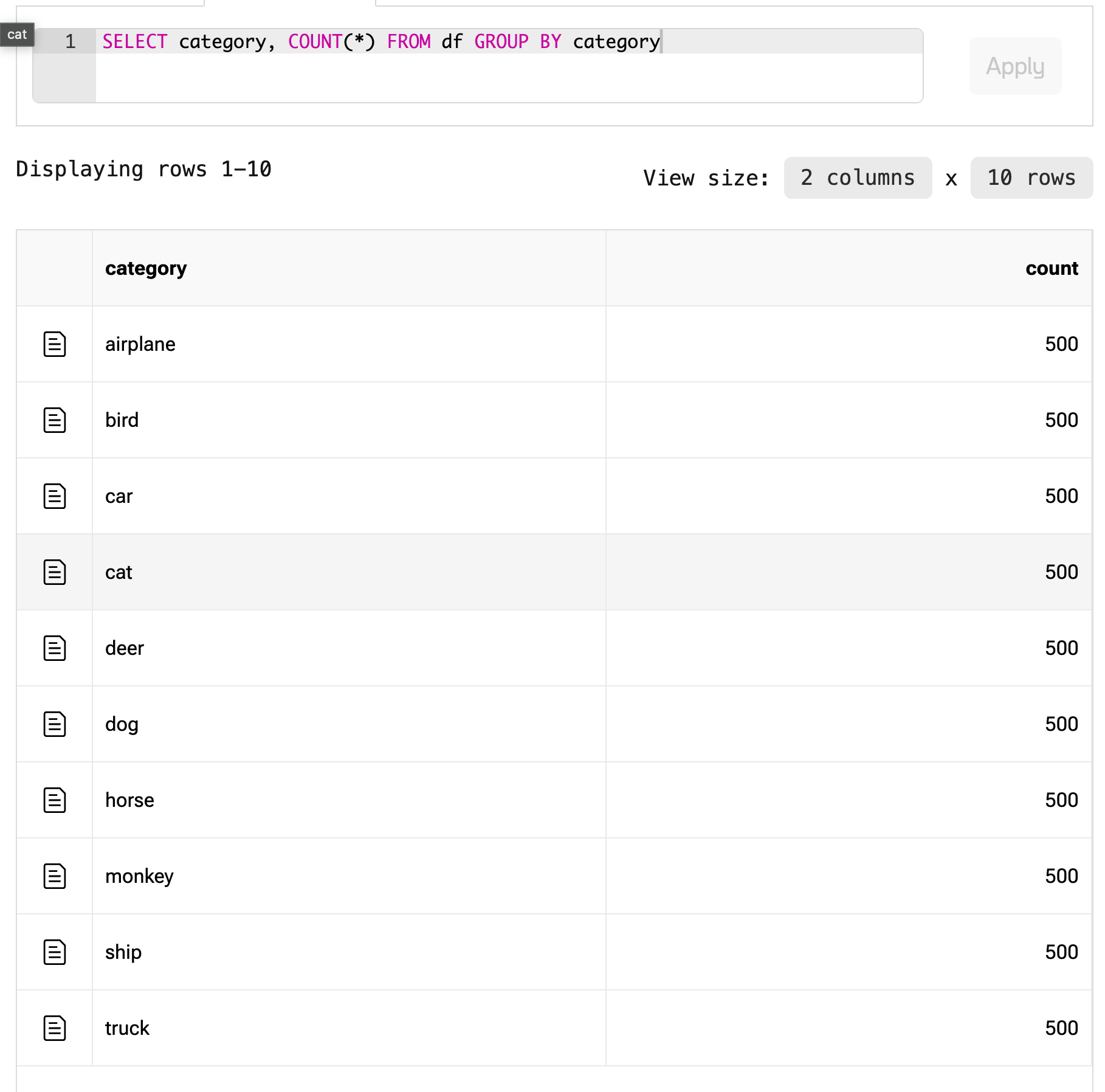
Data frames should have well defined schemas with types that can be used to validate, compare, and provide default values of data. Schemas can be inferred from certain file types (for example parquet) but aren’t necessarily required to get up and running (take a csv file). Explicitly defining a schema after you are happy with your data format can be extremely beneficial in creating robust data pipelines and other end applications.

Data frames are simple, consistent, and easy to use data format whether you are a data scientist, engineer, or product manager who likes to work in spreadsheets.
Why not a fully blown relational database or data warehouse?
The first reason is the unstructured nature of the data. Though the data frames themselves are structured, it is more efficient and organized to keep all the data together in one location. Your images could sit in the same subdirectory or S3 bucket as the data frame.
There are many benefits to using a relational database instead of a flat file when it comes to datasets, I’m not here to argue we should never use a database. They simply add complexity to the system. Human readable text files are not going away as a data format, and are interoperable in many systems, even if they may not be the most efficient.
Databases require you to have a certain level of technical chops, are hard to version, and are more complex than a simple file exchange format.
Data warehouses are great for storing massive amounts of data but can be expensive and hard to learn. They go against the core tenet of simplicity.
When it comes to sharing, versioning, having a canonical copy for training/testing, and exchanging between tools to do the job, I still think flat files are hard to beat as a starting point, and you can scale up to more robust systems as you need. Anyone on your team can spin up an environment to work with a CSV, line delimited json file, or parquet file.
Rule 2: Human Readable
Modern AI systems navigate the world through the same lens that we as humans do. They have no problem understanding natural language, audio, video, or images if given enough data.
Being able to understand why AI performed an action it did is becoming more important than ever. Since the weights of a neural network itself are not debuggable, it comes down to the data it was trained on, and data that is being fed in to evaluate. I think that the more human readable this data is, the more eyes we can get on the problem.
For example, you may have a clever run length encoding algorithm to compress image masks and save disk space, but it is arguably more useful to let someone see and debug the masks as images to truly get a sense of how well your model will perform.
Non-Human Readable:
Human Readable:

Even though it may be slightly less efficient than binary compressed representations of the data, I think the importance of human readability outweighs the technical challenges of efficient data streaming and storage. Network costs and storage costs are not negligible, are slowly going to zero. Human costs of understanding, debugging, and querying data is more important and what we should be optimizing for in my opinion.
If the dataset is truly massive, you can always sample a subset of the data into SUDS human readable format for quality insurance.
The faster we can answer what is in the data, the better we can debug why a model behaved as it did, and know what experiment to run next.
Rule 3: Data and code should be not be tightly coupled
Data is not useful in a vacuum. It requires code to explore, load, transfer, model, or generally make use of.
Often datasets and code are too tightly coupled. As a basic example, you should be able to download a directory of data separately from a directory of code and not have them entangled. Many version control system do not scale well to datasets after a certain size.
Separating the data from the code allows code have a many-to-many relationship with data. The same code can be applied to many datasets and vice-versa. This means the data should be consistent and usable with many tools.
Knowing which version of the data went with which version of the code is important for saving engineering resources and time, so it is important to have version control both at the code and data level to make reproducible, auditable, robust systems.
At Oxen.ai we build data version control tools to help manage these workflows to curate and iterate on your data to build the best possible models.
🧼 SUDS in the Wild
At Oxen.ai we are putting SUDS into practice by cleaning up legacy datasets into simple, consistent, and reusable formats.
Explore a list datasets we have cleaned up here:
If you upload a public dataset in this format, let us know! We would love to share and have other people contribute to your dataset. Matching data schemas as well as well defined locations for unstructured data files make it easy for others to extend, remix, and compose your data.
Next Steps
We would love to hear from you! If you have datasets you would love to see cleaned up, or if you believe SUDS is too simplistic and would not work for your dataset, let us know at hello@oxen.ai or join our Discord.

We believe that the more people that contribute to artificial intelligence through the use of data, the more aligned and robust future AI systems will be.
Who is Oxen.ai? 🐂 🌾
Oxen.ai is an open source project aimed at solving some of the challenges with iterating on and curating machine learning datasets. At its core Oxen is a lightning fast data version control tool optimized for large unstructured datasets. We are currently working on collaboration workflows to enable the high quality, curated public and private data repositories to advance the field of AI, while keeping all the data accessible and auditable.
If you would like to learn more, star us on GitHub or head to Oxen.ai and create an account.
 Oxen-AI
Oxen-AI