The Prompt Report Part 1: A Systematic Survey of Prompting Techniques

For this blog we are switching it up a bit. In past Arxiv Dives, we have gone deep into the underlying model architectures and techniques that make large language models and other deep learning models work in the first place. This is a lot like studying the underlying CPU architecture in classical compute science. It is great to know about registers, memory, clock cycles, and logic units, but at the end of the day to be productive software engineers we need to know how to write higher level code.
The same can be said for AI. Understanding neural networks, transformers, residual streams, and how they affect next token prediction can be a useful mental model for what the systems can and cannot do. At the end of the day - we need to use these systems to solve real world problems.
Just as high level programming languages are the interface to CPUs, prompt engineering is the interface to these language models. In this blog, we will dive into The Prompt Reports first three major prompting categories, we go into the last three here!
In this blog, we use examples from our financial sentiment and GSM8k-Sample dataset which are completely public and free if you would like to see our results and play around with the data yourself.
What is a prompt?
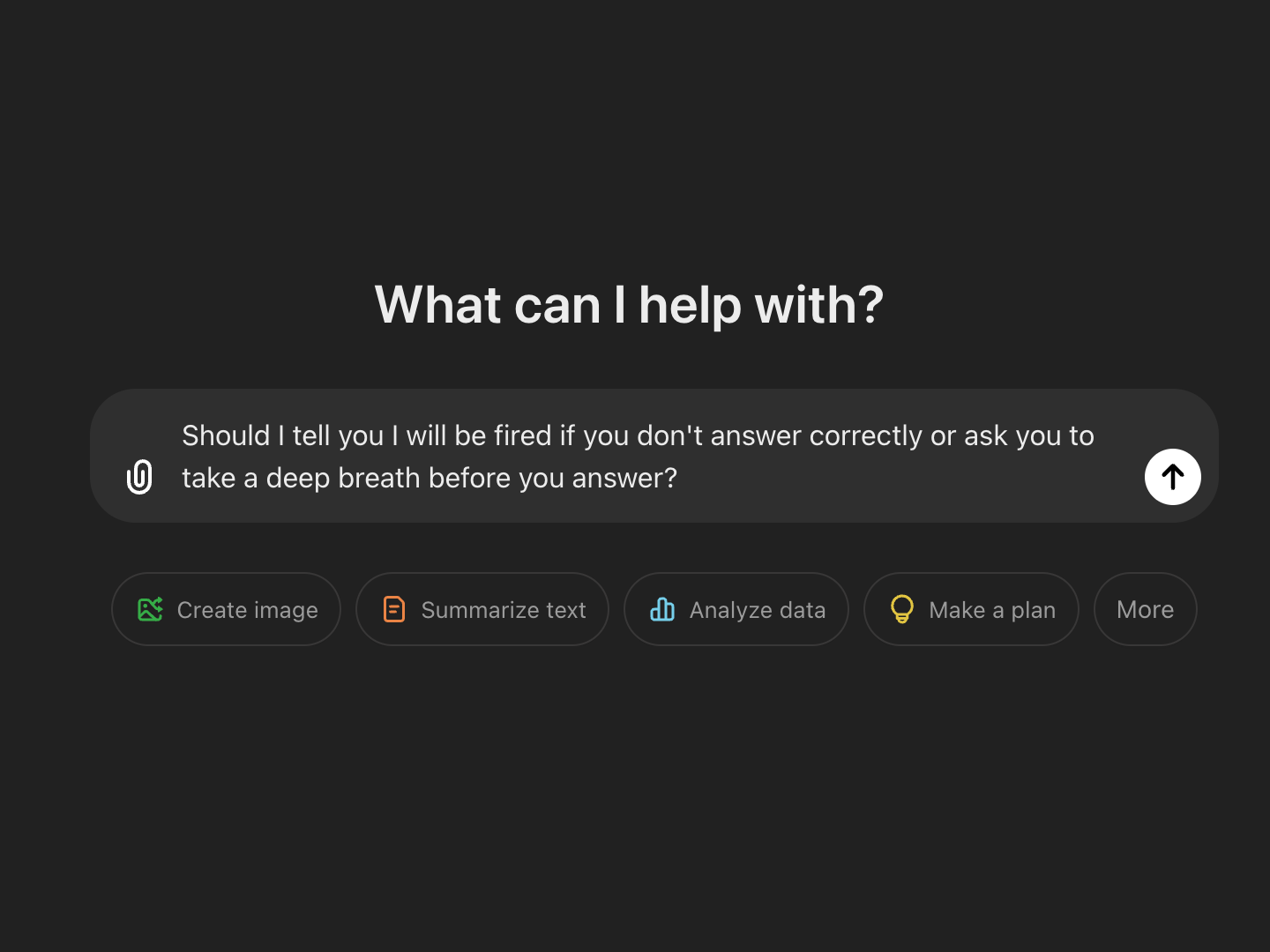
A prompt is simply an input to a GenerativeAI model to help guide it’s output.
For example a Large Language Model (LLM) may help you automate manual work.
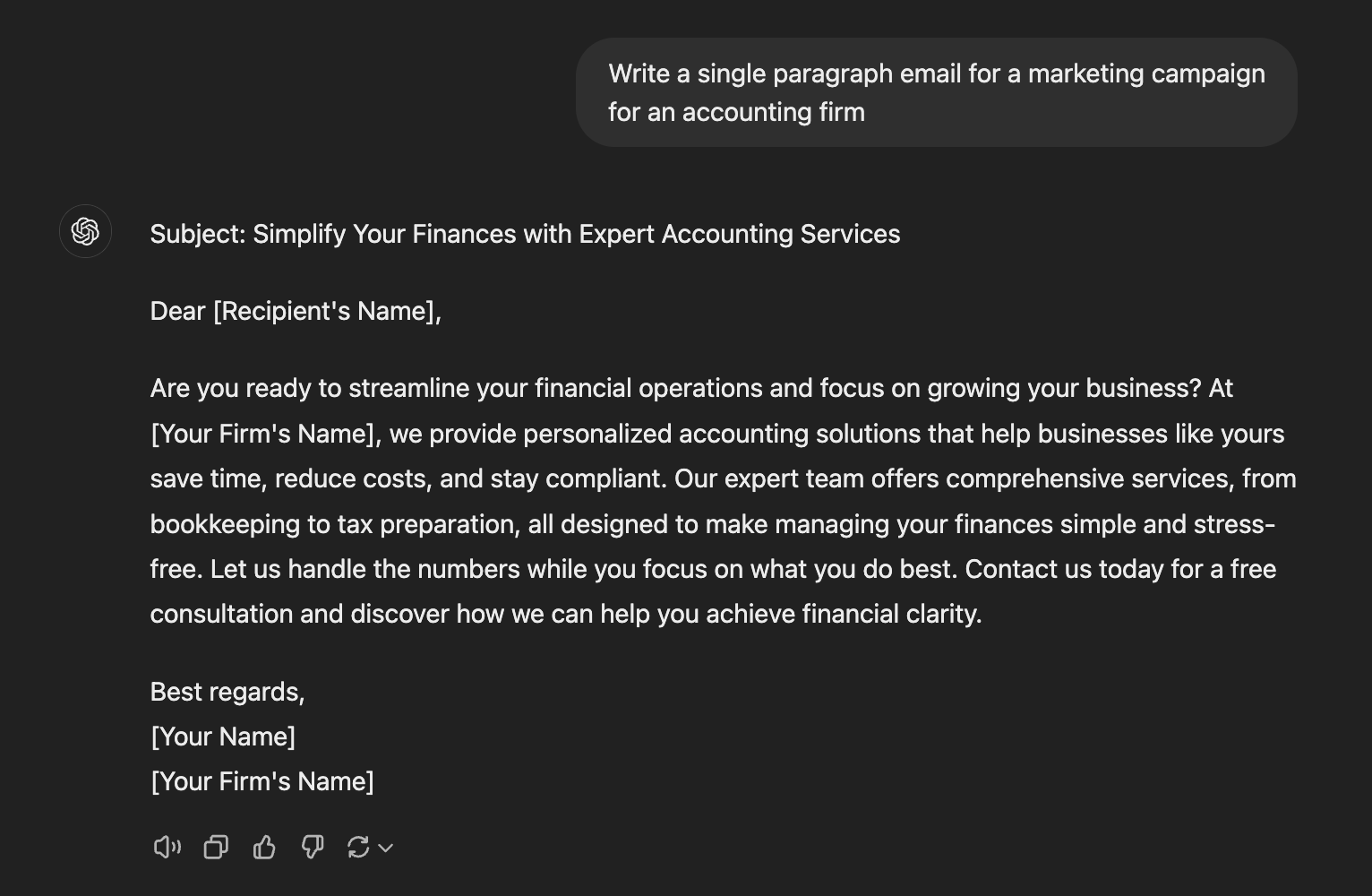
Or as a simple classifier of intent:
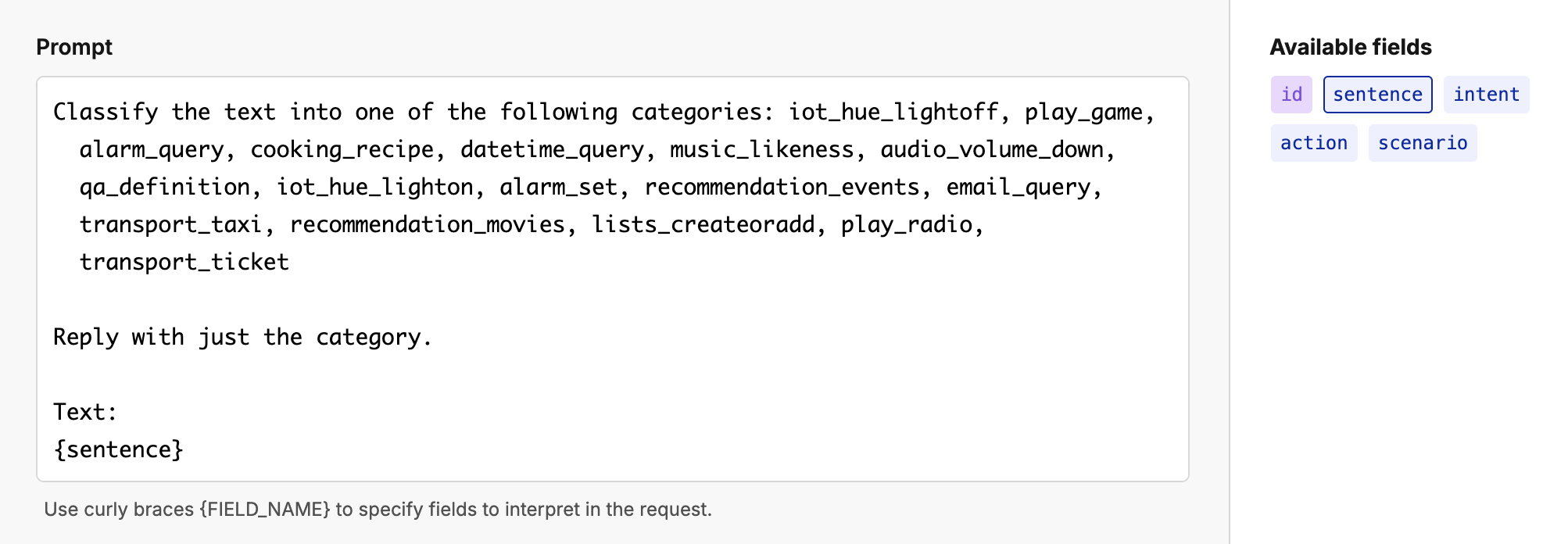

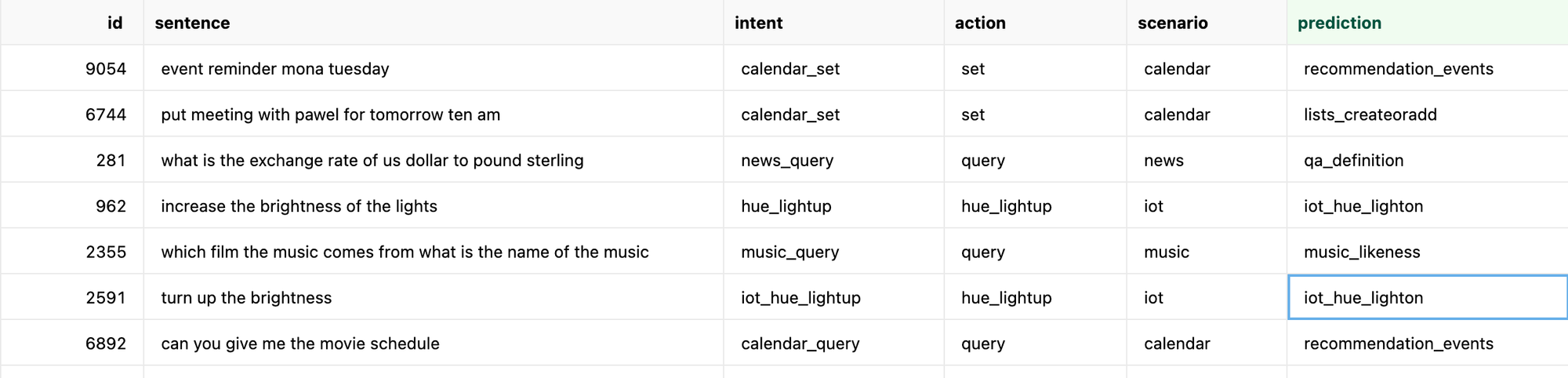
Or a Vision Language Model (VLLM) can help you automatically categorize and classify images in a scene.
List all the items in the scene in a comma separated list
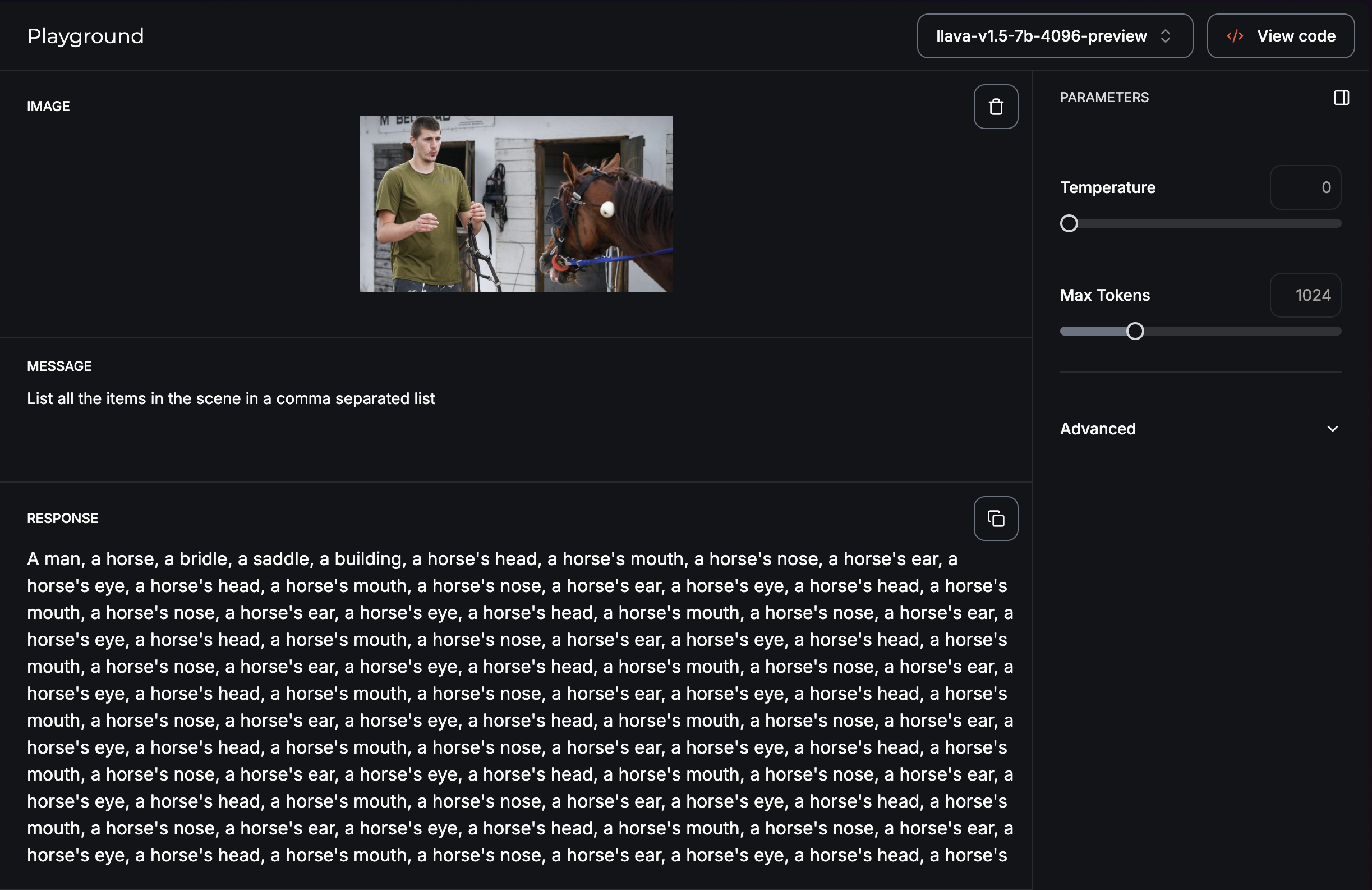
Okay so they aren’t always perfect 😉 but that’s why we need to learn how to use them properly.
Training vs Prompting
Prompting is a new paradigm in machine learning where we no longer have to backpropagate or use gradients to update weights in the model to get new behavior.
In traditional machine learning the workflow looks something like this:
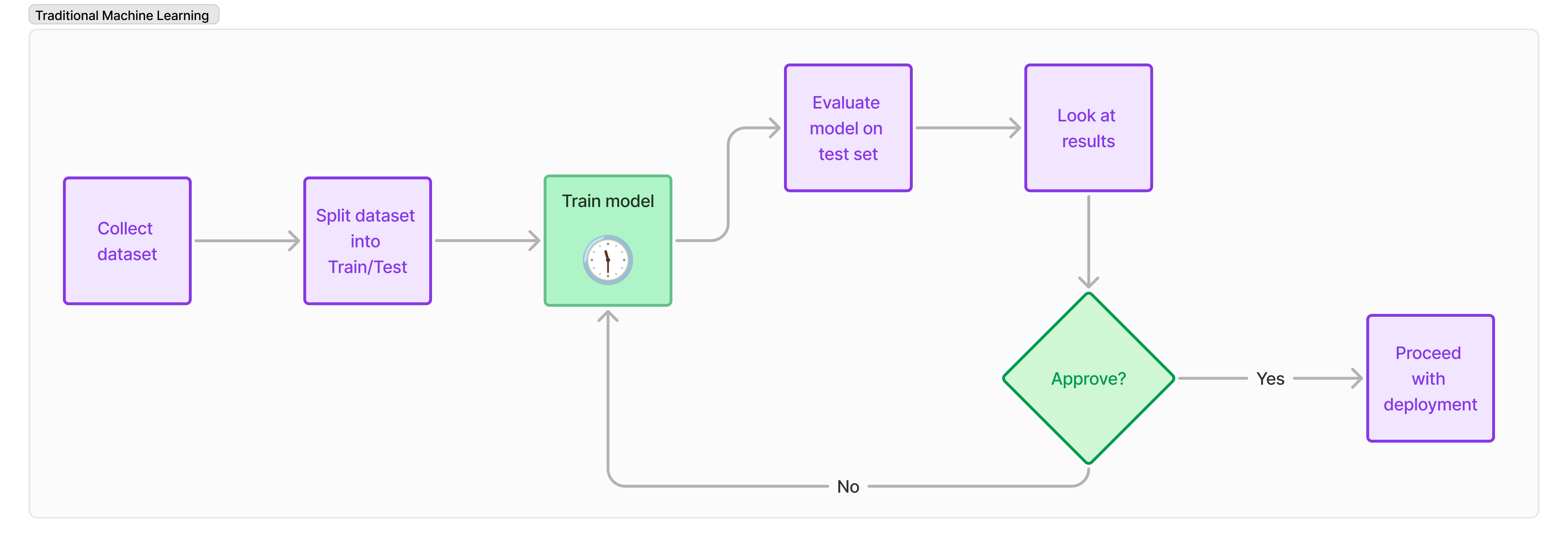
The step to train a model can take hours, days, or months depending on the size of the training set and the size of the model 🥱
Prompting speeds up this iteration process significantly.
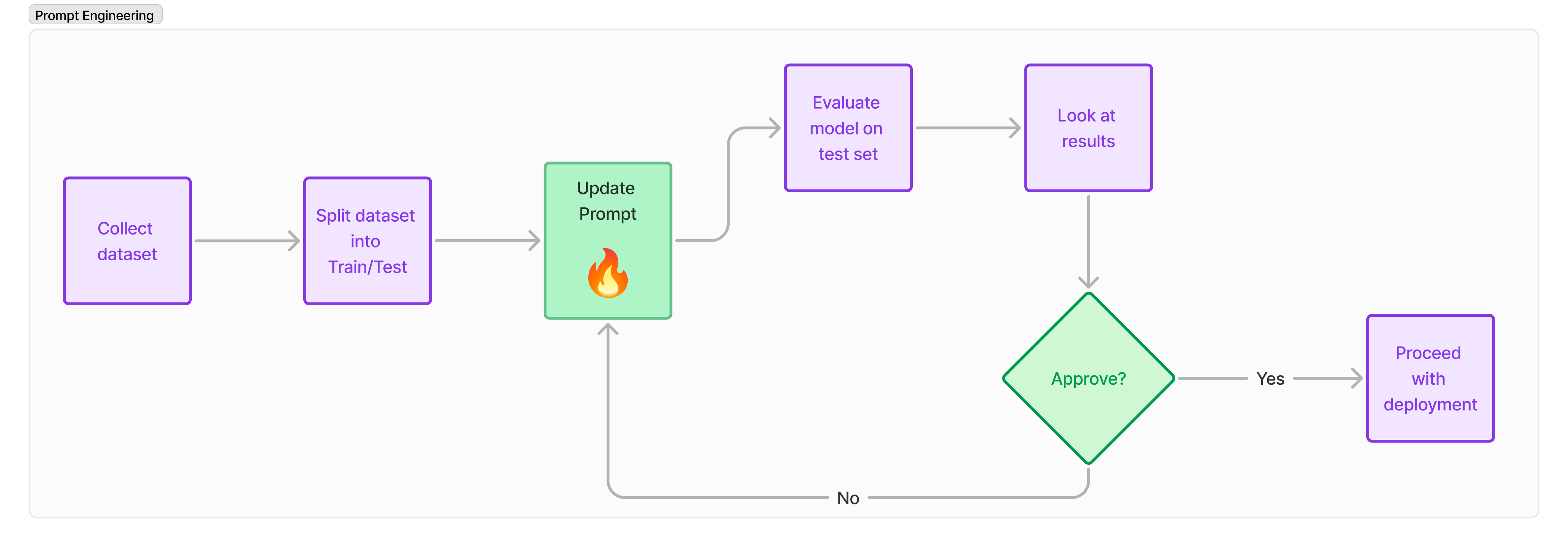
Although there is no actual training or fine-tuning done, I argue we should still use standard machine learning workflows while creating and evaluating prompts.
The outputs of these models are non-deterministic, and will not always be 100% correct. If you are newer to AI this can be a little un-nerving, as there are no guarantees that your end to end pipeline will work. Errors also cascade throughout the system if you are chaining prompts and models.
For example if you have a 4 step pipeline to go from a user message to a chatbot message. Each step along the way affects the downstream steps, which affects the final output.
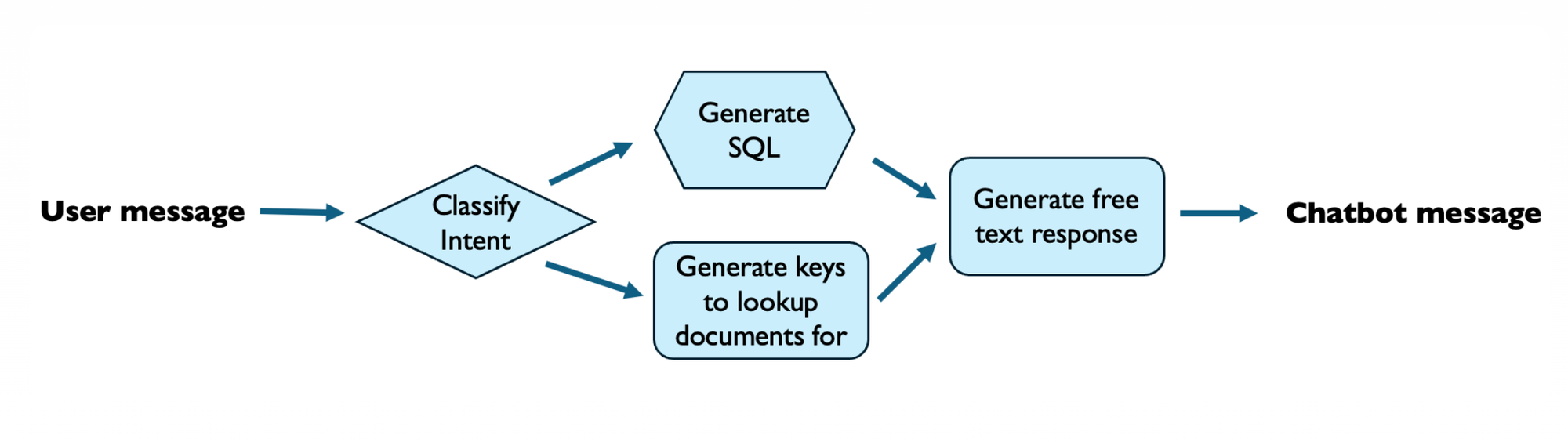
https://www.sh-reya.com/blog/ai-engineering-flywheel/
For each step in this pipeline you will want to understand which prompt+model pair performs the best on a wide variety of data before shipping to production.
I harp on this before we dive into the paper because I know it is easy to work on a single prompt on a single example for awhile and be tempted to ship it without fully testing on real world data.
Should I Fine-Tune?
A common question is “should I prompt engineer or fine-tune”? Fine-tuning is quicker than a full pre-training, but can still take hours or days.
As a good rule of thumb, you should always try to prompt engineer your way out of the problem first. Let the big AI labs do the heavy lifting for you, and see what capabilities are already built into the model.
Instead of waiting hours to fine-tune a model with a Lora, tweak the prompt, and try the model again.
Once you have verified that the base model can do the task, fine-tuning can in theory get you higher performance in terms of speed or overall accuracy, but is a much slower iteration cycle.
Prompting Taxonomy
In The Prompt Report paper the identify 58 different text-based prompting techniques and categorize them into a taxonomy. This paper is 76 pages long, and takes some traversing to other papers to get actual prompt examples.
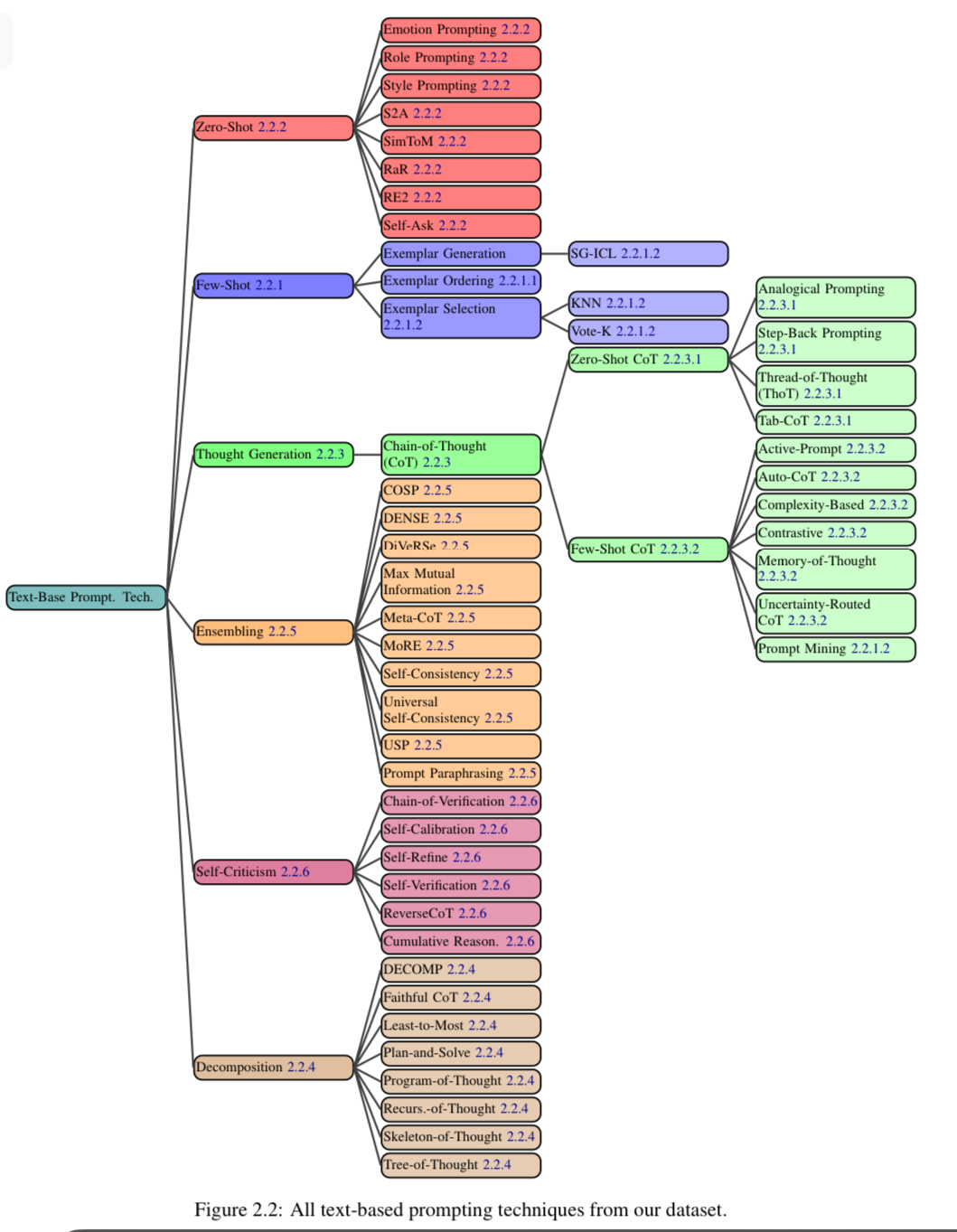
This covers everything from simple one line prompts to techniques that incorporate external tools, such as Internet browsing or calculators.
The Six Major Categories
Within the 58 categories, there are 6 top level categories.
- Zero-Shot
- Few-Shot
- Thought Generation
- Decomposition
- Ensembling
- Self-Criticism
We are going to dive into each of the six in the next two blogs by providing real world examples, and running them live to get you a feel for them.
Prompt Templates
The first thing you need to understand when thinking about prompting is “prompt templates”. These are simply interpolations of strings in your favorite programming language of choice.
Imagine we are doing binary classification of tweets. We can now solve this problem a simple prompt like the following:

This could be used to figure out how customers are talking about your product in the wild, to monitor company performance for investment decisions, or even for advertising to make sure you are putting ads next to positively correlated content.
NOTE: What’s crazy is that 10 years ago this was an entire product suite our company was selling. Functionality like this used to take months collecting data, training and fine-tuning models. Now it’s as simple as a prompt template and an API call to a foundation model.
Prompts should not be evaluated one off.
In production scenarios, each tweet or review in the dataset would be inserted into a separate instance of the template and the resulting prompt would be given to the LLM for inference.
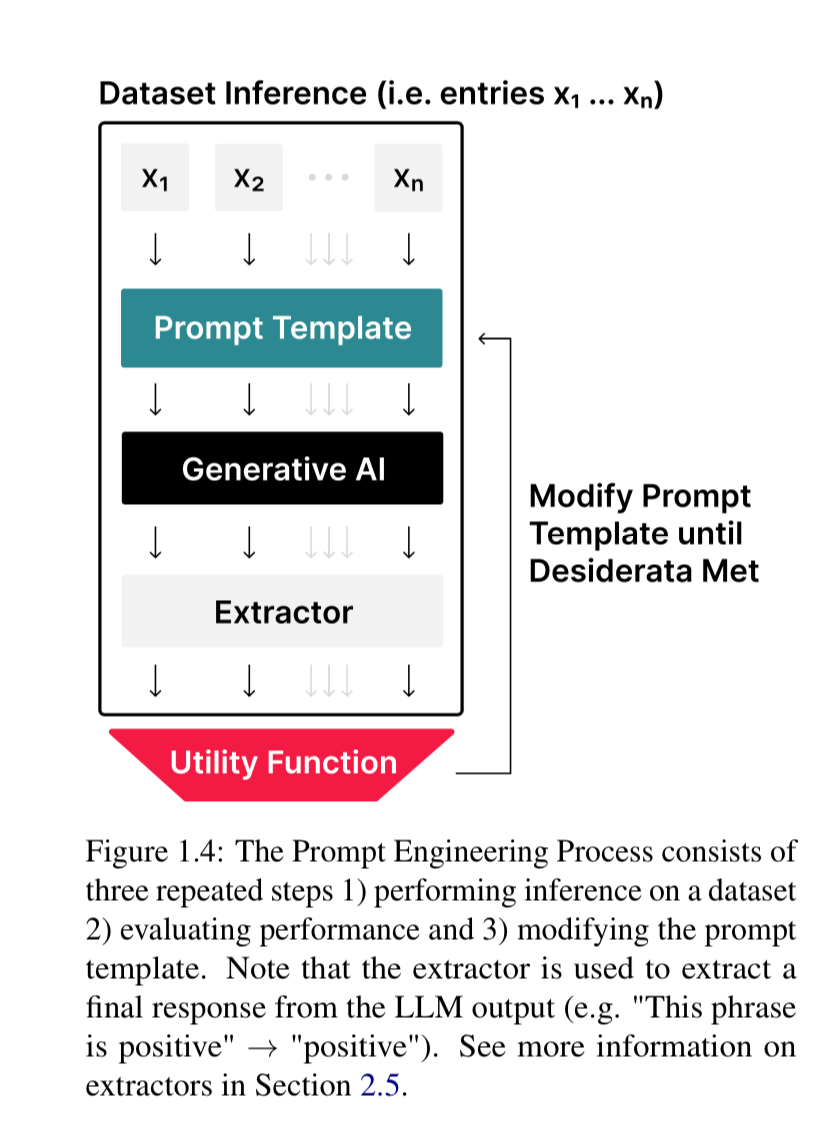
Funny enough, this diagram above is exactly what we’ve been cooking up at Oxen.ai the past month. If you would want to test out our newest release Run-Model-on-Dataset (here is an example), sign up here and use it on any dataset you'd like!
As we go through the high level prompt types, I want to give some concrete examples of the inputs and outputs and differences so we can get an intuition for the strengths and weaknesses of different techniques.
Let’s start with sentiment analysis for sentences from financial reports.
By the end of this dive I expect everyone to take the weekend to build their AI day trader, make millions, and decide to hack on passion projects in a tropical paradise 😉
Zero-Shot
What if you don’t give the model any examples? This is called zero-shot prompting.
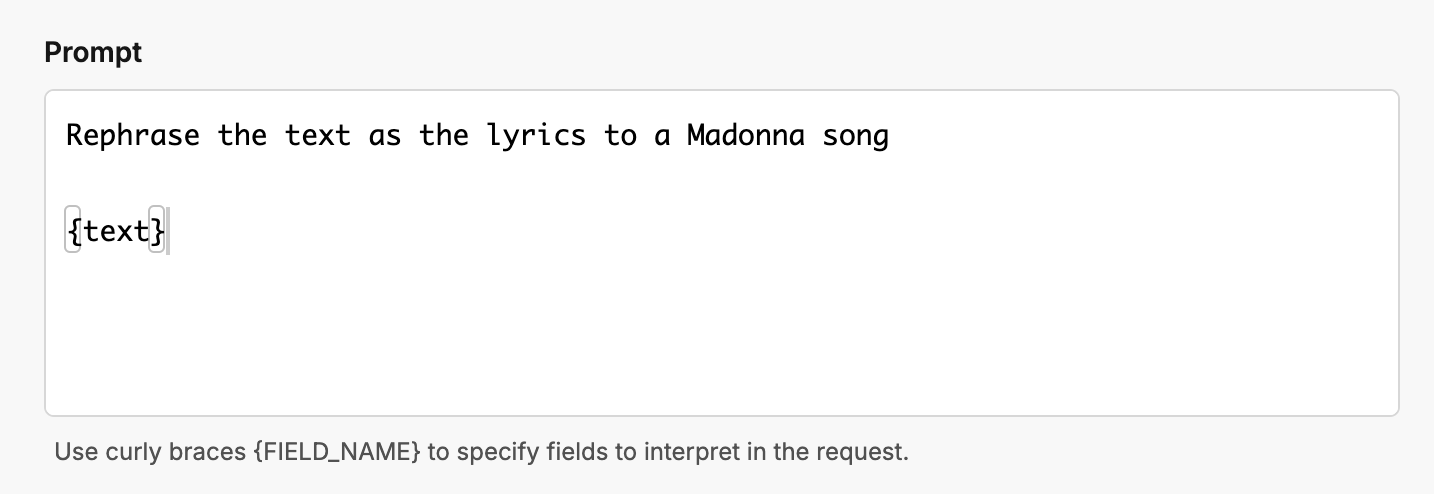
💅 Role Prompting
This is also known as persona prompting. For example “act like Madonna” or like a “science fiction writer”.
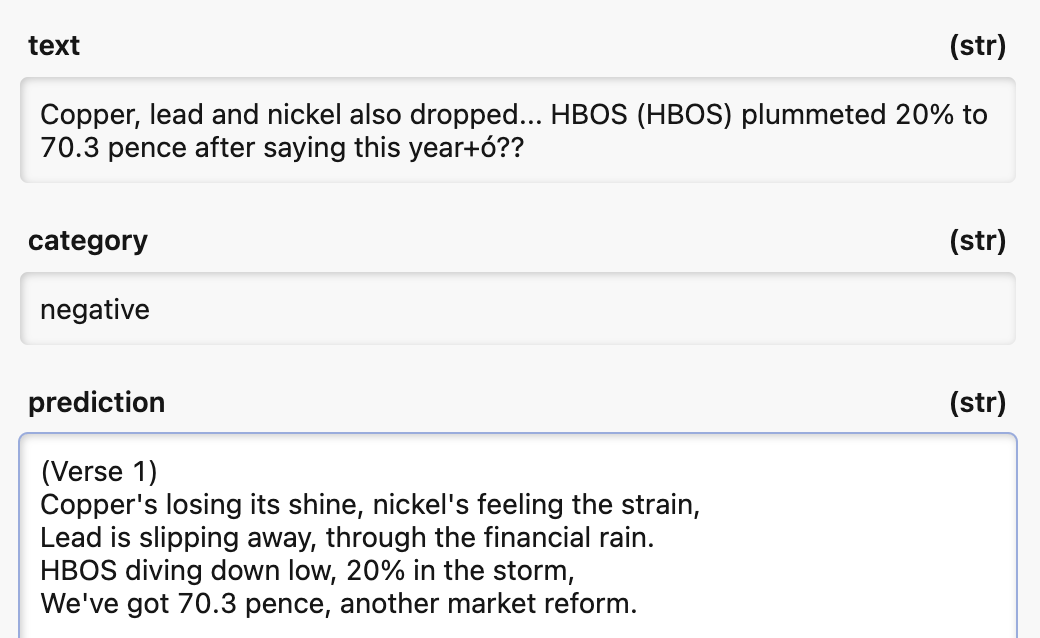
🤏 Style prompting
Style prompting be used to get the model to be more verbose or more concise, this has some overlap with role prompting.
For example sometimes LLMs can ramble on.

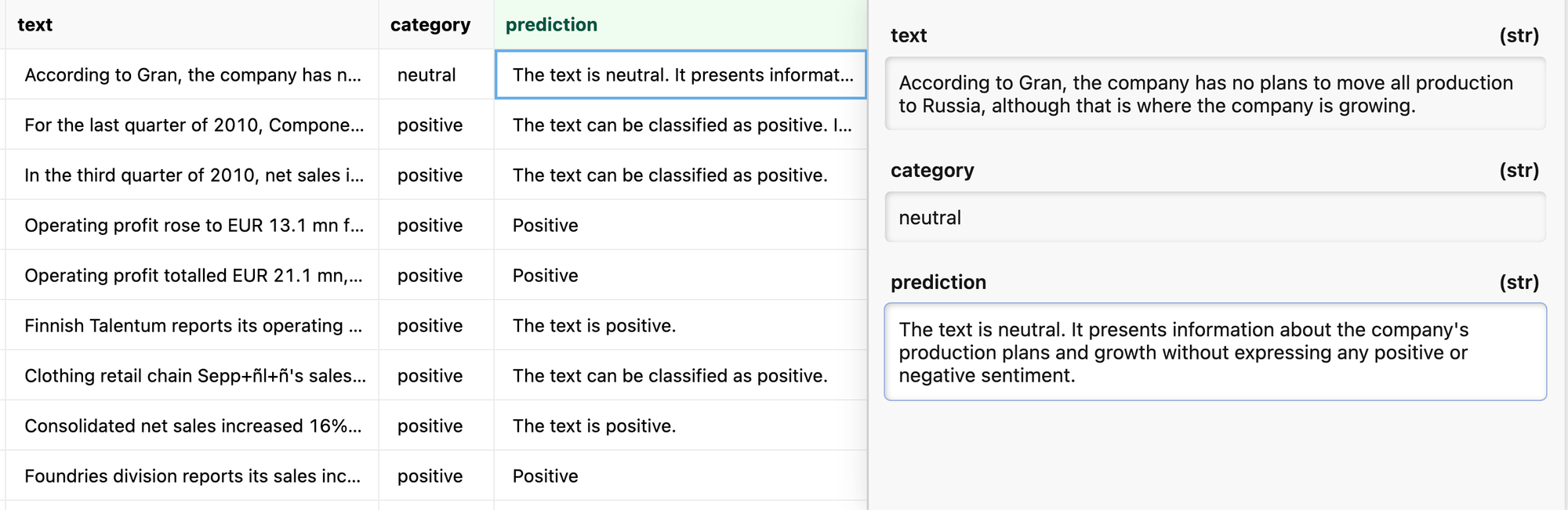
It would be hard to compute the accuracy for this task if there are not direct string matches. For example a simple regex would match all three categories in the above sample.
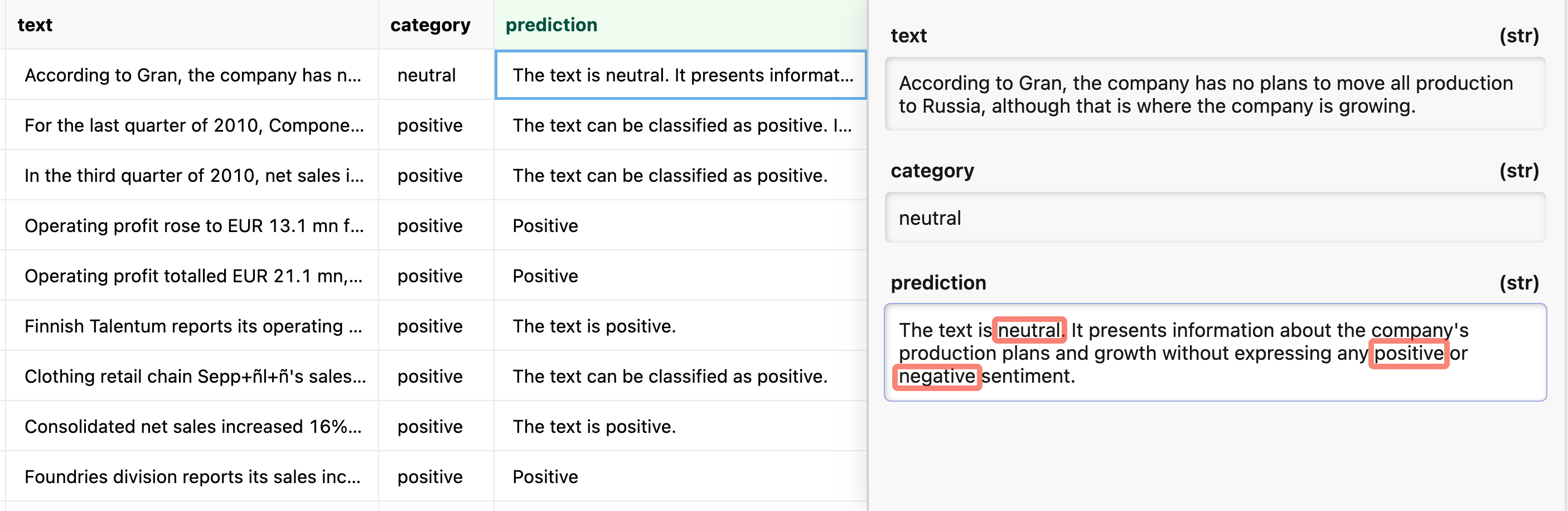
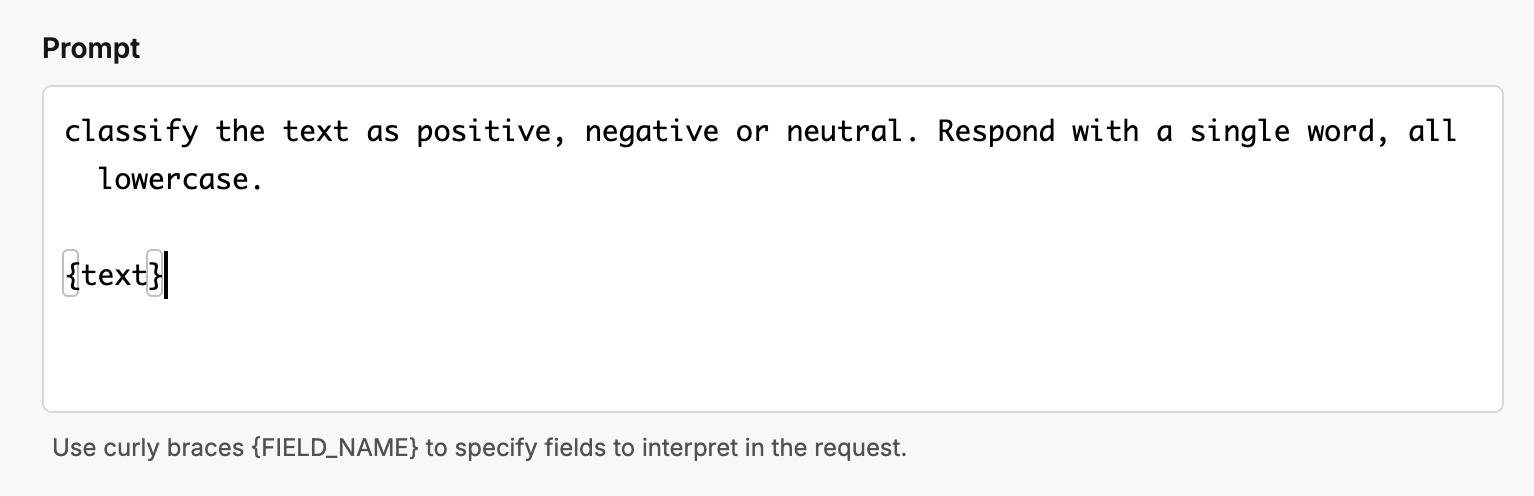
You can fix this with some “Style Prompting” by enforcing a concise one word all lowercase response.

My random sample of 89/100 correct.
🥺 Emotion Prompting
Incorporates psychological phrases relevant to humans like “my career depends on this”.

I saw that most of the errors above were predicting “neutral” when it should have been positive or negative. So I tweaked the prompt.
This bumped the results to 91% on the 100 samples.
I since did a couple more iterations on this prompt and it averages out around 90% with gpt4o, so inconclusive if emotion prompting helps.
https://www.oxen.ai/ox/financial_sentiment/evaluations
Few-Shot
Few shot prompting is the process of prepending a few examples before the text you actually want the response for. This helps guide the model into the expected behavior.
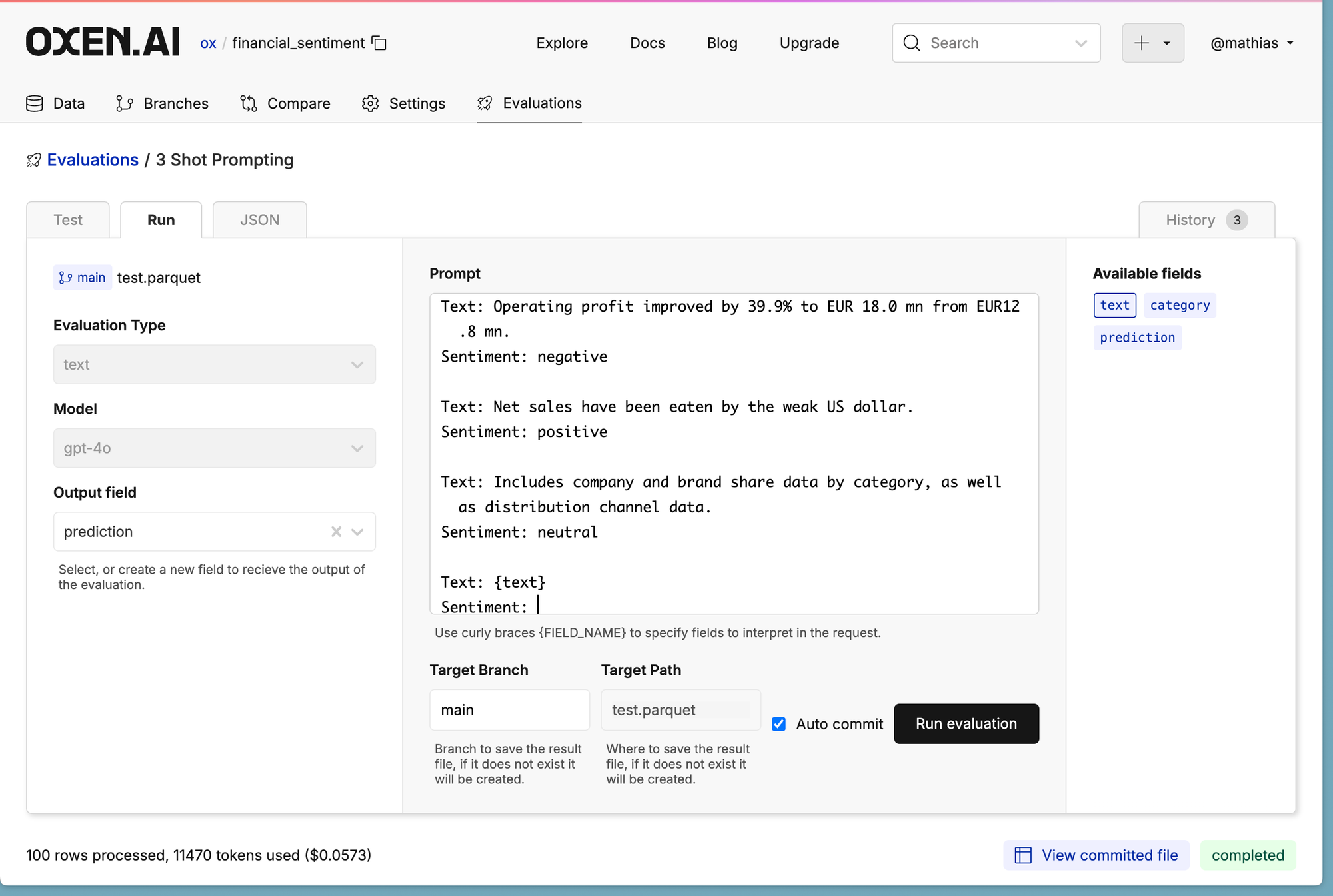
Here is the link to the above example: https://www.oxen.ai/ox/financial_sentiment/evaluations/58126199-3ec5-42a2-935a-9312f4d892f3
Typically I find few-shot prompting more useful with base models that have not gone through post training. Less affective on GPT4-like models.
That being said, there are many aspects to consider when picking examples for few-shot prompting.
Example Quality
In general, more examples the better, but some people have seen diminishing returns after 20 examples.

Example Ordering
Try to make sure if there is a pattern it is intentional, the model will pick up on it. For example if you have all positive examples at the start, and negative at the end, the model may keep picking negative.

Label Distribution
Similar to traditional ML, if you provide 90% positive examples and 10% negative, this may bias the modal towards positive.

Label Quality
This should go without saying, but make sure that the examples are labeled correctly in the N-Shot Examples.

The paper states that some work suggests that providing the model with exemplars with incorrect labels may not affect performance…but in certain circumstances it affects it drastically.
I decided to test this out with GPT-4o, providing the wrong labels in an N-shot example. For example, say we wanted to reverse the sentiment analysis in our last case because we are trying to short the market.
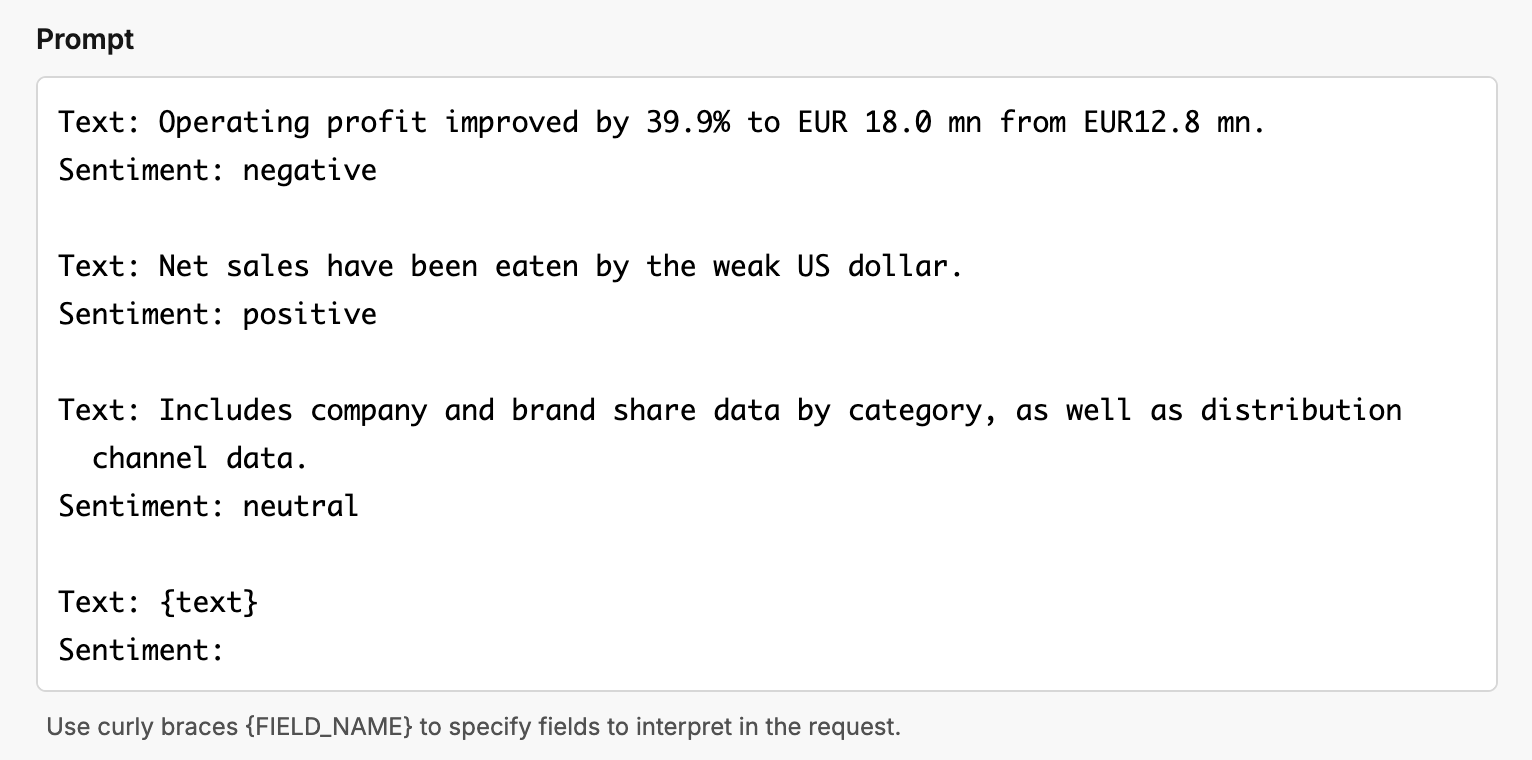
The model surprisingly still got 88% accuracy on the 100 examples.
Maybe we need more than 3 shot to flip the script…so I tried 6 shot.
I tried again and still got 87% correct.
Finally I decided to give the model more details to flip the script and then it was able to do the task
You are a financial analyst who sees bad market outcomes as good and good market outcomes as bad because you are trying to short companies.
For example:
...N-Shot
This bumped us to 95%! Which more tells me that combining N-Shot and an role prompting is a good combination.
Example Format
Try to pick a format that is commonly seen in the training data. For example using XML or Q:{}\nA:{}\n is common in most training data.

We even have seen some papers that claim XML is easier for the model than markdown because of the way the pre-training data was crawled and collected.
Example Similarity
Always favor diversity over similarity. This is the same as when picking training examples during training or fine-tuning.
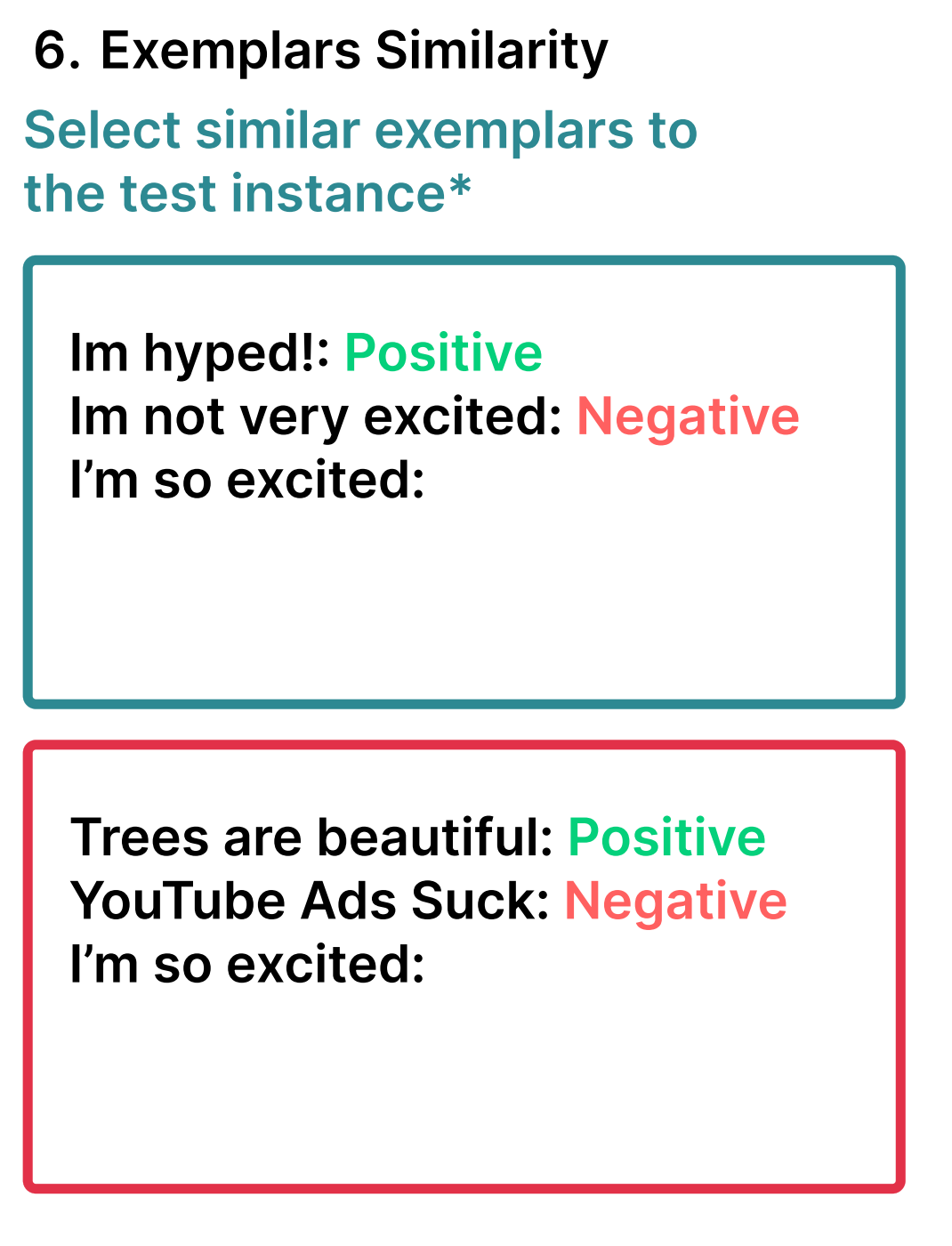
How should you select the few shot examples? The paper suggests a few approaches including
- K-Nearest Neighbor to find examples at test time
- Vote-K where you use one model to propose unlabeled examples for an annotator to label, then use those as the few shot
- Self-Generated In-Context Learning has the model generate the labeled examples for you before proceeding. This seems like the least affective IMO.
Thought Generation
At a high level, these techniques prompt the LLM to articulate it’s reasoning while solving a problem.
For example, the following prompt uses a combination of single-shot and chain-of-thought to prime the model into giving reasoning for the next question.

Zero-shot Chain of Thought
In order to use the same prompt across tasks, you may not want to insert any task specific knowledge into the prompt.
Examples of this may be phrases at the start of the prompt like:
“Let’s think step by step”
or
“Let’s work this out step by step and make sure
we have the right answer”
or
“First, let’s think about this logically”
or
“Walk me through this context in manageable
parts step by step, summarizing and analyzing
as we go.”
These are nice and generic and don’t require any task specific knowledge injected.
I wanted to try these 4 combinations on GSM8K which stands for “Grade School Math 8k”. GSM8K is an interesting dataset because it has math word problems, that in theory could save accountants work. Chain of Thought is important especially in the auditing sense of if the model makes a mistake, we need to be able to see why it made the mistake.
I started with a baseline of no CoT and just the word problem itself.
https://www.oxen.ai/ox/GSM8k-sample/evaluations/88a8c56a-2bcb-4516-b96c-f9c75cee42be
What’s interesting, is gpt-4o was post trained to do CoT as part of it’s response already.

This is where I started going down a rabbit hole 🐰 🕳️ come join me as we explore the data.
I realized that the model was getting ~95% accuracy no matter what prompt I used. So my first question was….what questions are we getting wrong?
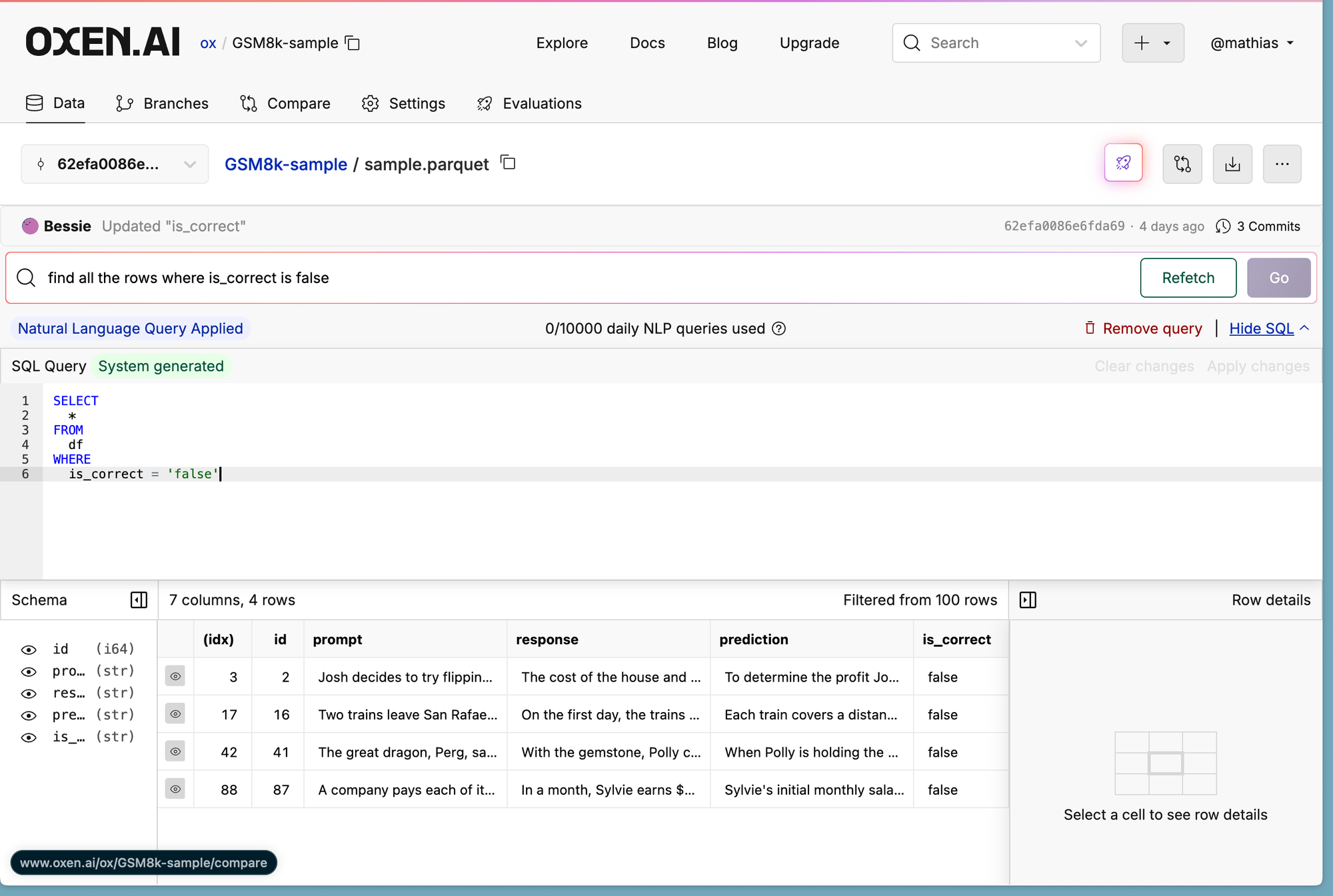
Then my next question was, is the model actually getting this high of accuracy, or are we overfitting to the benchmark?
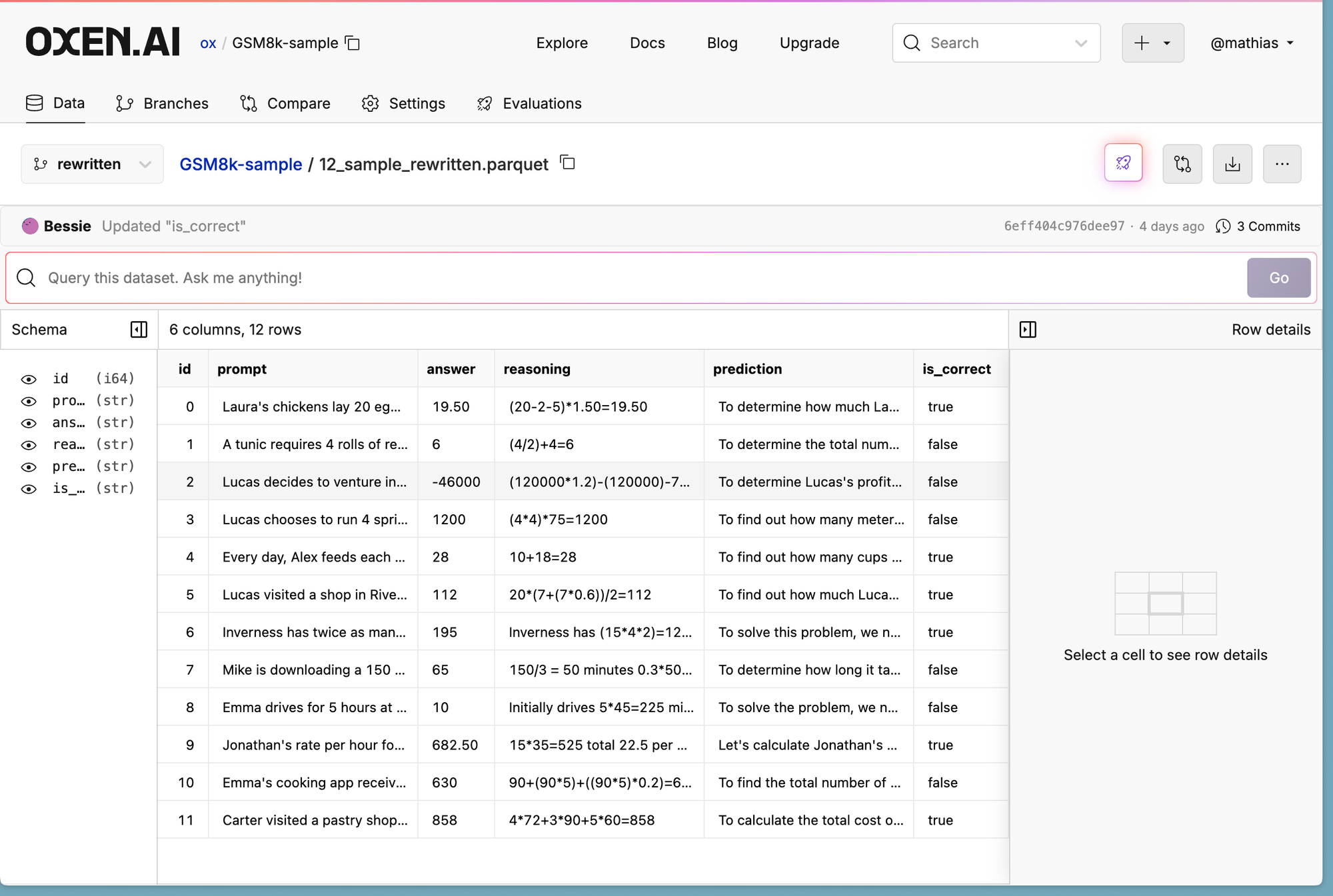
https://www.oxen.ai/ox/GSM8k-sample/file/rewritten/12_sample_rewritten.parquet
It took me a decent amount of time solving the math word problems myself, but let’s look at the results. According to LLM as a Judge we only got 6/12 which is not promising.
My Process:
- Run CoT prompt on GSM8K
- Run LLM as a Judge to Judge accuracy
- Think - I wonder if it is the problems themselves or not
- Use LLM to reword the problems
- Solve 12 myself just as a sanity check
- Wish I was crowd sourcing this
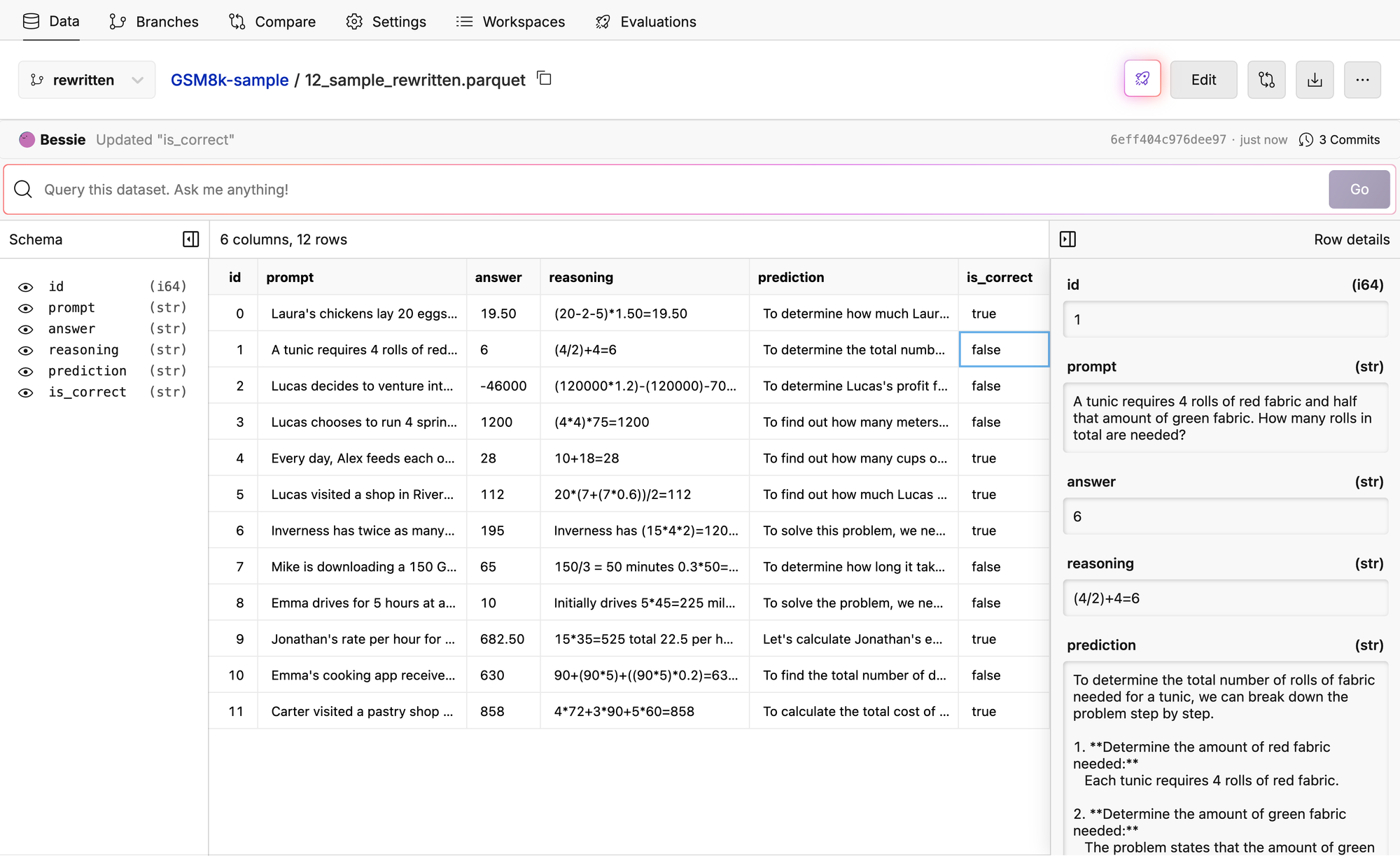
So I did some further debugging….let’s look at row with id = 1 for example.
LLM as a Judge is not perfect, and it’s hard to eval these CoT reasoning chains.
PSA TO LOOK AT YOUR DATA.
Then I realized there are other benchmarks like MATH that are harder
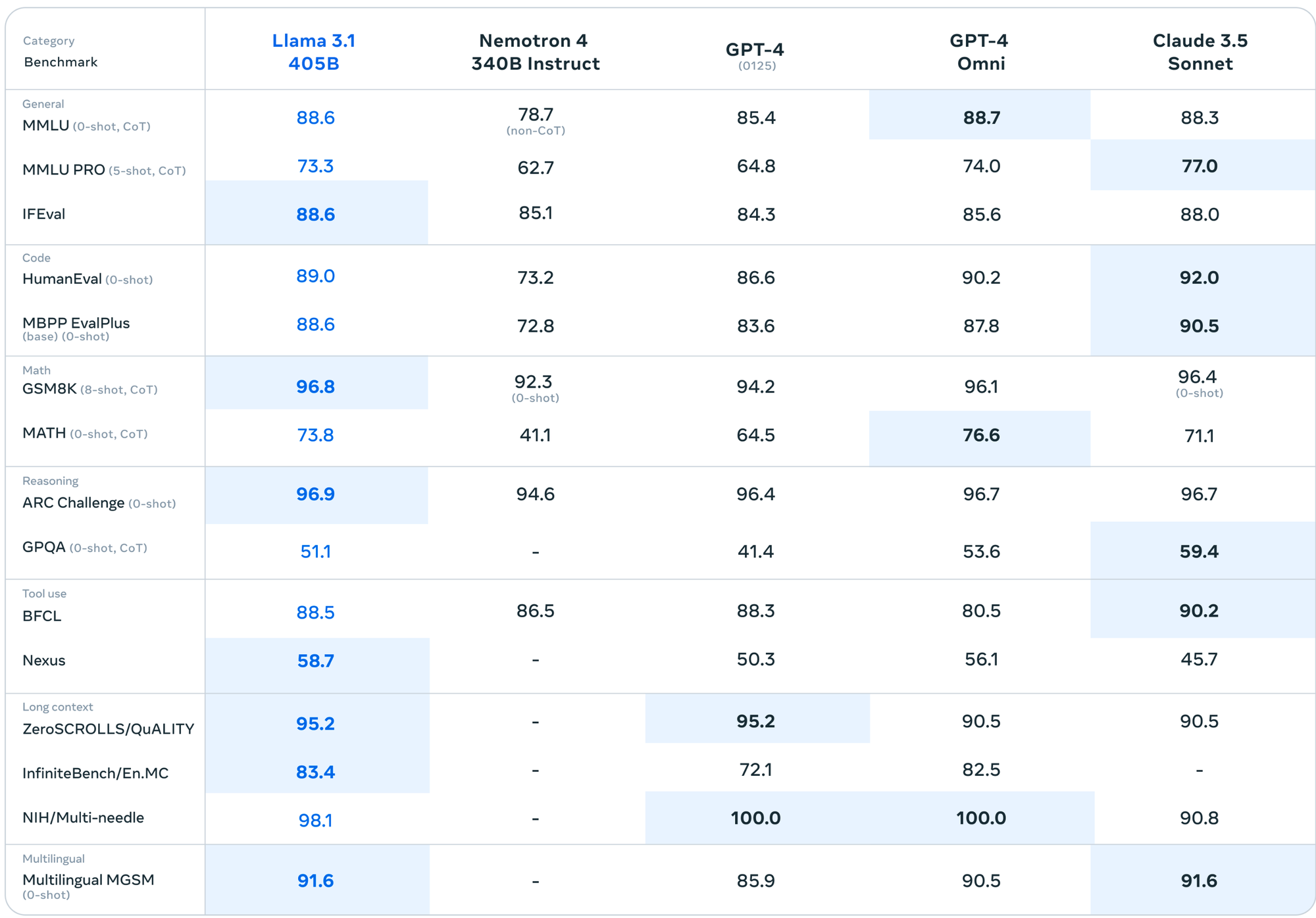
I would love to continue testing out more prompts from this paper - as well as more models as we roll them out in the UI. If you want to help out hit me up in discord and I’ll give you some free credits and we can divide and conquer. Also if a tool like this would be useful for your own work, let us know what else you’d want us to add!
Top things we are working on are 1) multimodal modals and 2) supporting a wide variety of open source models, as well as BYO model.
Thanks for going down this rabbit hole with me
Few-Shot CoT
Contrastive CoT Prompting
Is a technique where you provide both positive and negative chain of thought examples in order to show the model how NOT to reason.

https://www.oxen.ai/ox/GSM8k-sample/evaluations/3d4f4991-e548-4816-96b9-64298820adaf
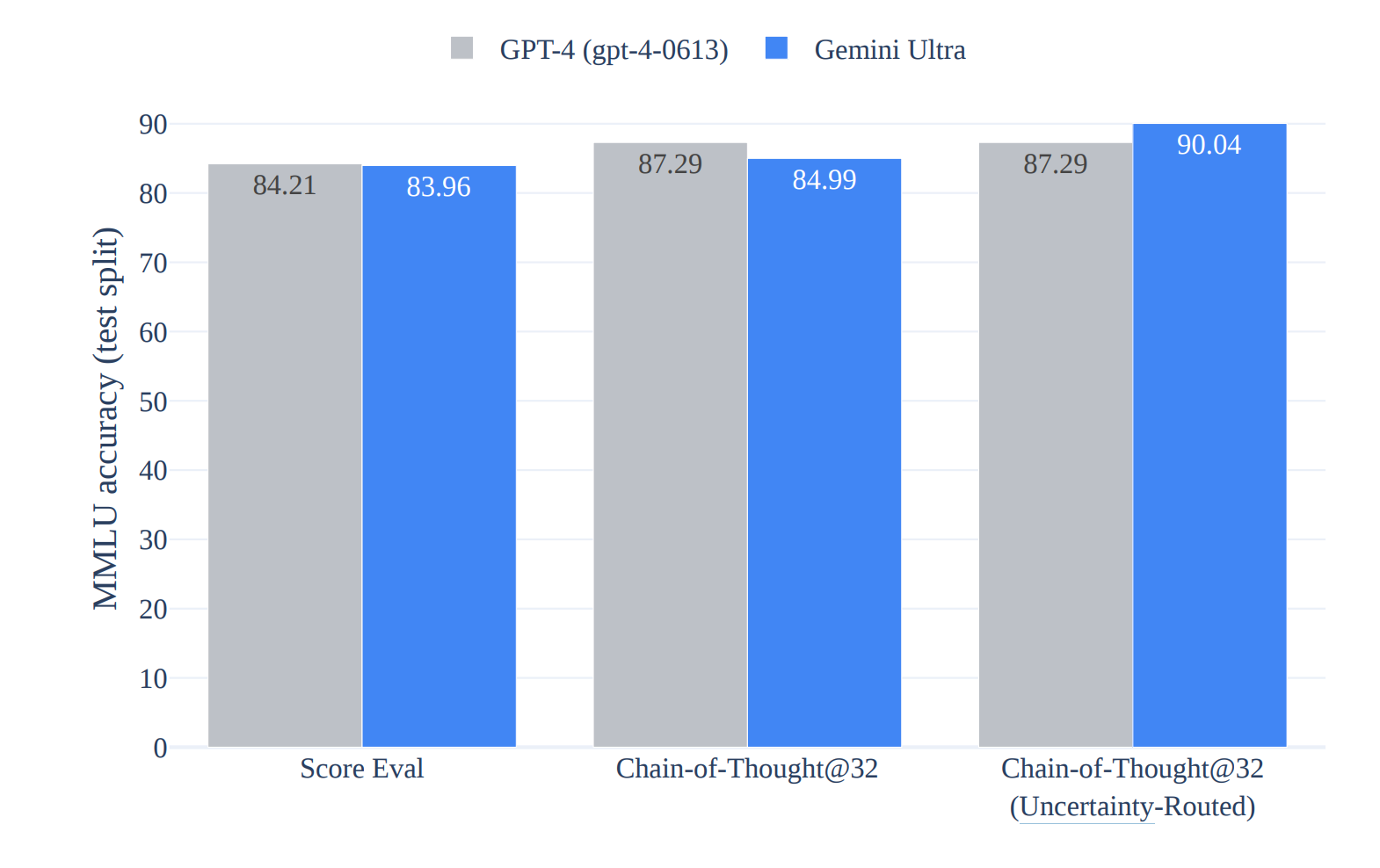
Uncertainty-Routed CoT Prompting
Is a technique where you sample multiple reasoning paths then selects the majority response. This is similar to ensembling which we will see later.
This was proposed in the google gemini technical report.
https://storage.googleapis.com/deepmind-media/gemini/gemini_1_report.pdf
Conclusion
This is only part one into zero-shot, few-shot, and thought generation. We will be posting another video and blog very soon with our dive into decomposition, ensembling, and self-criticism. Thanks for reading and make sure to reach out on discord if you want some free Run-Model-on-Dataset credits to experiment with. Thanks herd!