🐂 Contribute to Massive Datasets in Seconds with Oxen.ai’s Remote Workspaces

The datasets used for training and benchmarking machine learning models are incredibly large and continue to grow rapidly. ImageNet, a foundational dataset for visual object recognition tasks, consists of 14 million images across over 20,000 classes. Common Crawl (a subset of which was used in training OpenAI's GPT models) contains petabytes of web-scraped text. While crucial to the development of robust, generalizable deep learning models, these foundational datasets are far too large for individuals to fully grasp, expand upon, or contribute to without access to massive computational resources.
If we want to collaborate on massive open datasets, locally downloading zip files containing gigabytes of imagery or text just to modify or add a few key observations is a costly waste of bandwidth, storage, and development time.

At Oxen, we’ve worked to make it easy and efficient to contribute to any dataset. With Oxen’s remote workspaces, you can quickly extend, audit, and modify your machine learning datasets with all the benefits of version control—no local downloads required.
What is Oxen?
Oxen.ai is an open-source project that makes versioning datasets as fast and easy as versioning code.
It’s optimized for lightning-fast performance on exactly the types of data used most commonly in large AI / ML projects, including imagery, video, audio, text, and tabular dataframes.
The following example shows you how to collect data for the computer vision task of object detection, but think of Oxen as the hub for all your structured or unstructured data workflows.
Learn more and see installation instructions here:
Without Oxen...
Let’s walk through an example of contributing to a large training dataset through adding additional training observations. We’ll use Meta’s EgoObjects object detection dataset, but all the same benefits apply for text, video, audio, and even tabular data workflows.
We'll start by trying to contribute to this dataset without using Oxen. After a quick search, we navigate to the dataset’s distribution page and find…
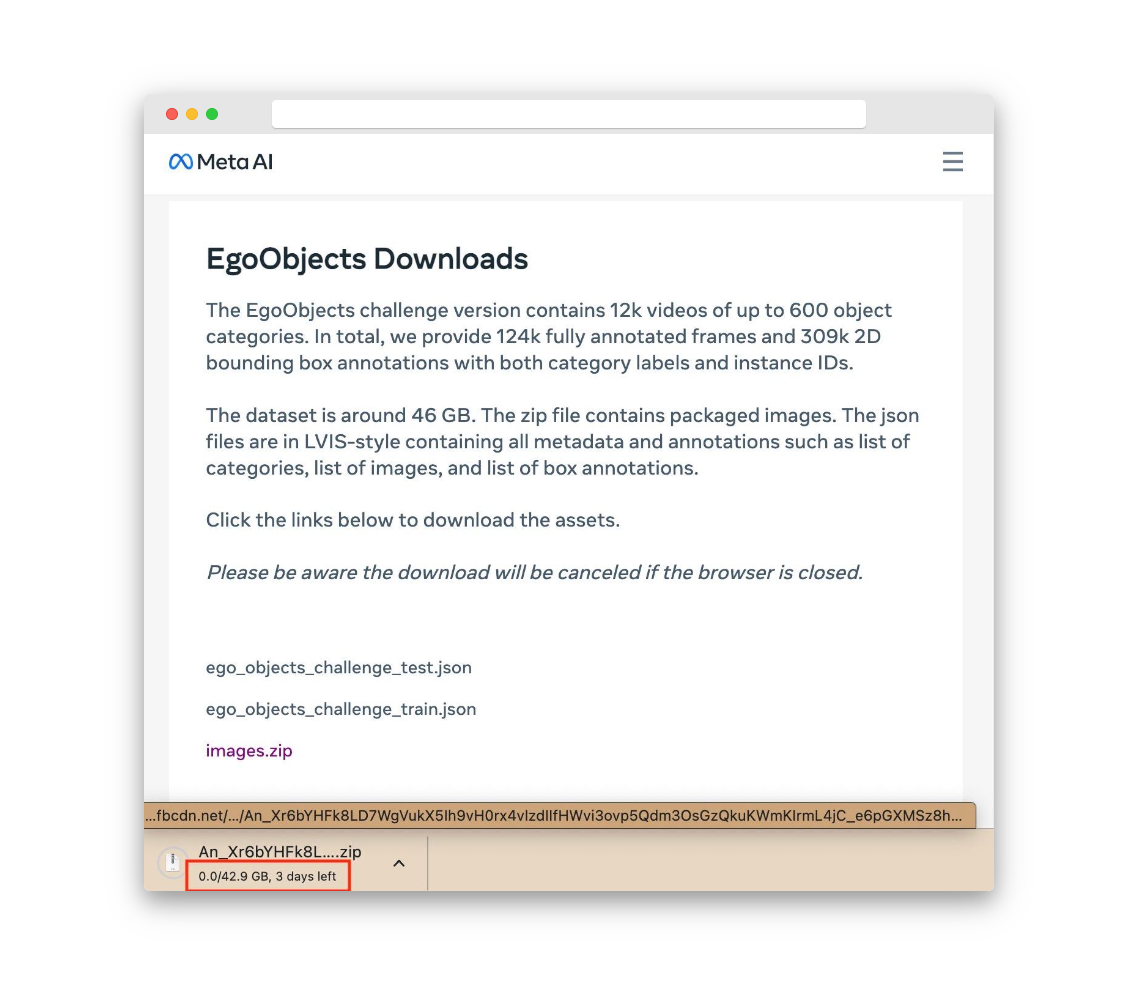
…a 42.9 GB .zip file, setting us up for a multi-day download and a massive waste of engineering time and resources. Even without the download time, we would have to email the team at MetaAI to make any modifications to this dataset and have them release it as another zip file.
Contributing with Oxen’s Remote Workspaces
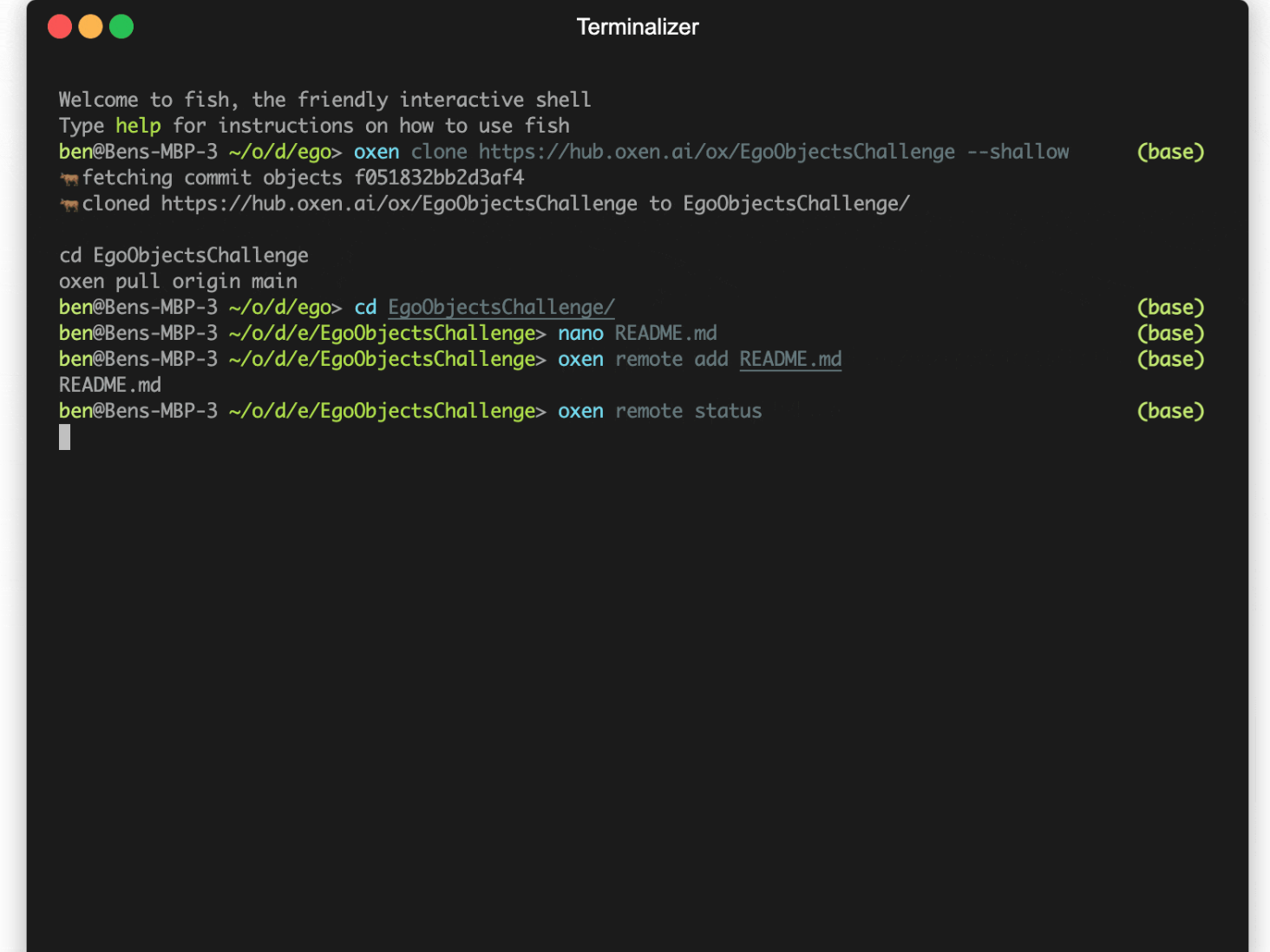
Since we don’t have that much time or storage to spare, we can head to an Oxen repo to view, download, and modify the same data with ease from the command line. Even without downloading we can start to poke around and see what's in the dataset.
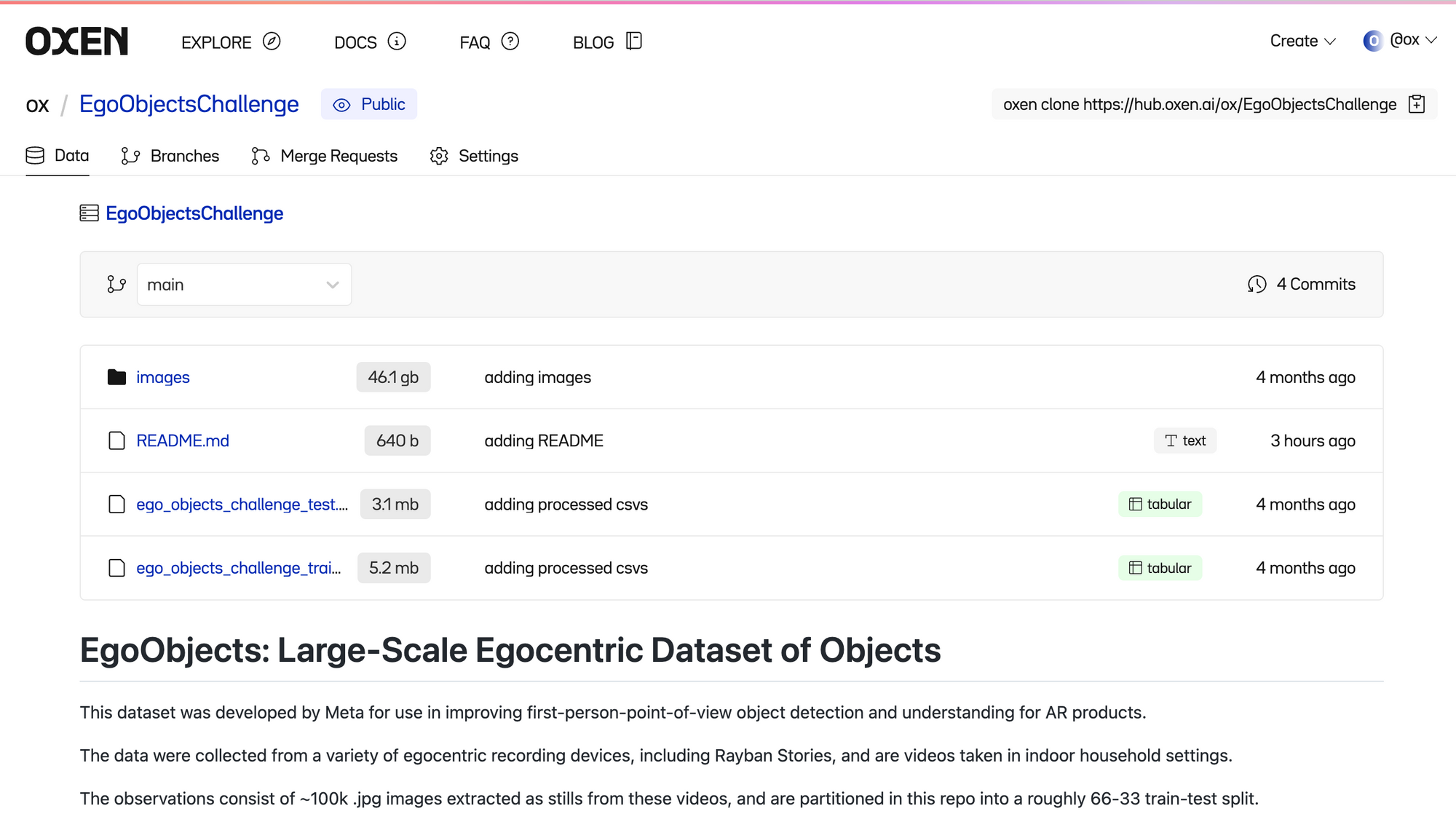
With a traditional version control system like git + git-lfs, we’d first have to clone the entire repository locally, modify a file, then push up the changes.
Instead, Oxen has allows you to pass a --shallow flag when cloning, which pulls only the necessary metadata to interact with version control system in the cloud. This takes seconds rather than hours to get started.
# Create a shallow clone of the repo
oxen clone https://hub.oxen.ai/ox/EgoObjectsChallenge --shallow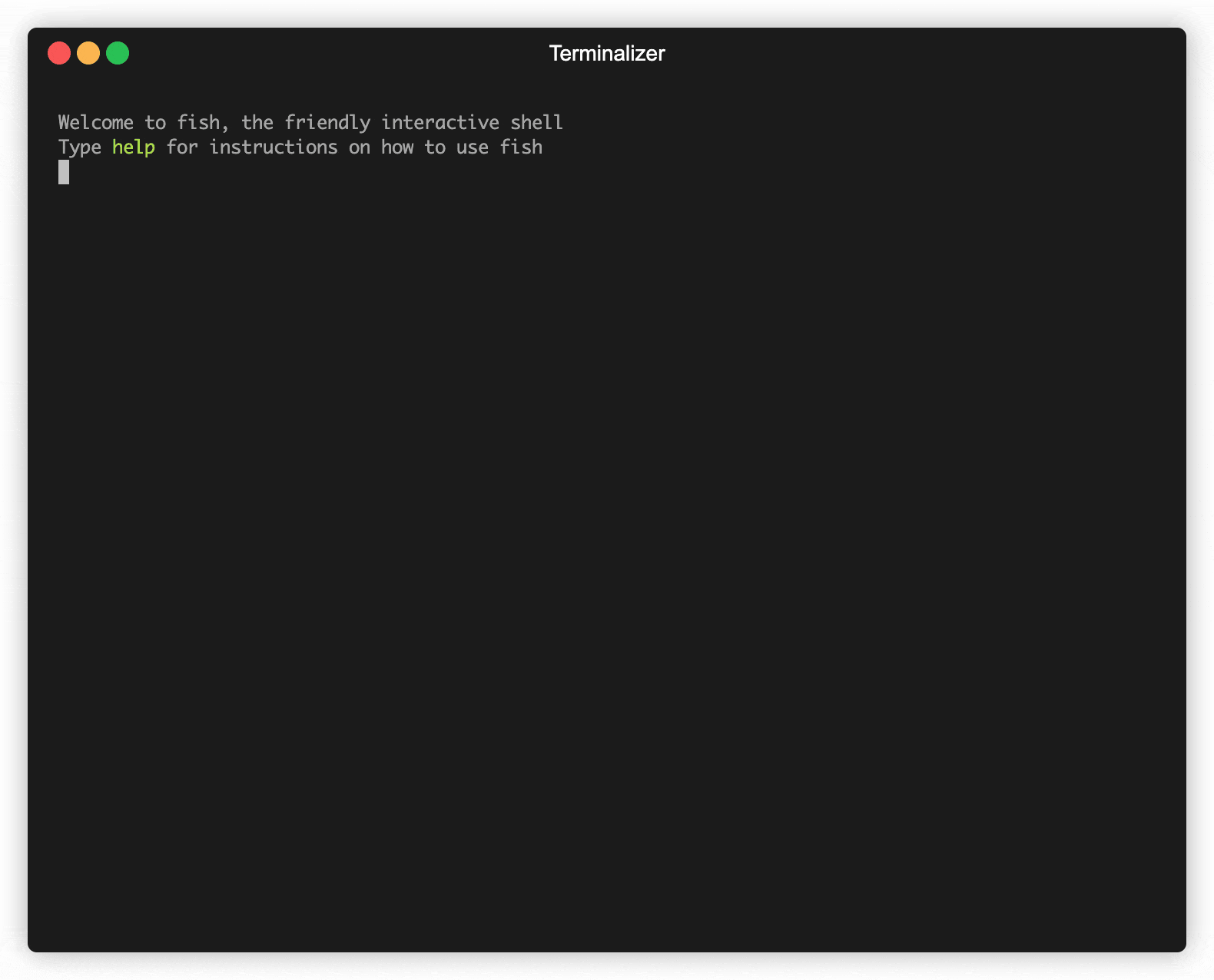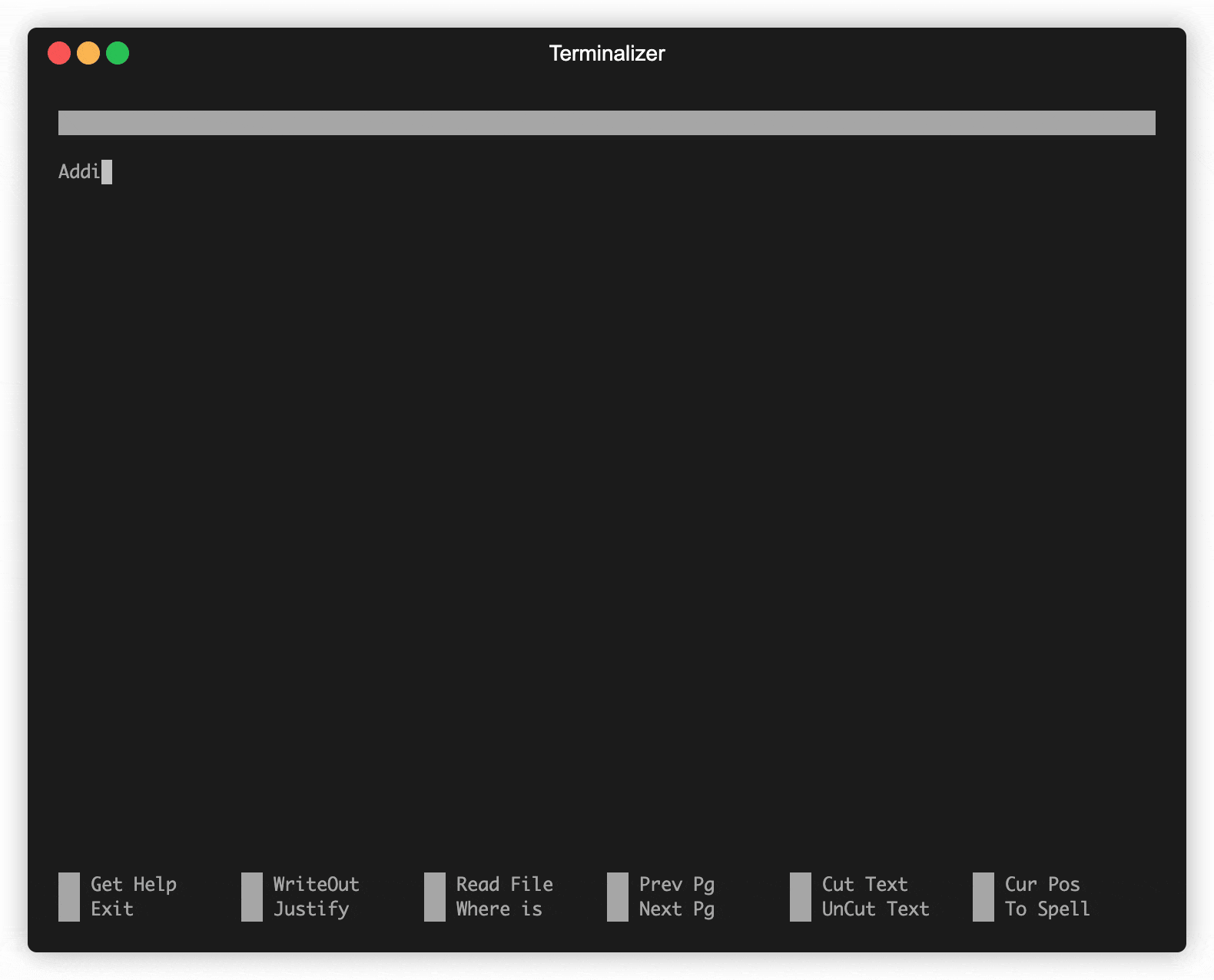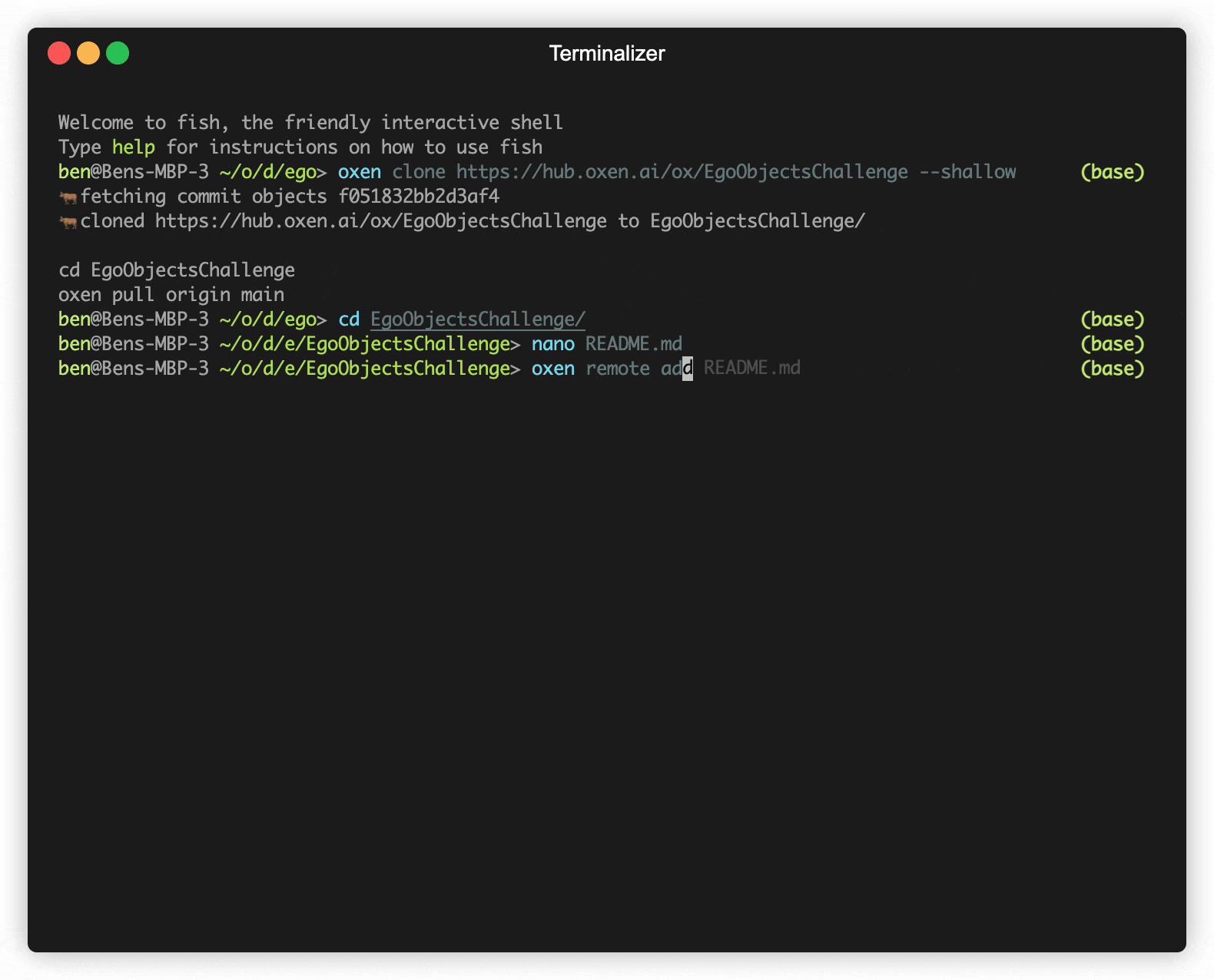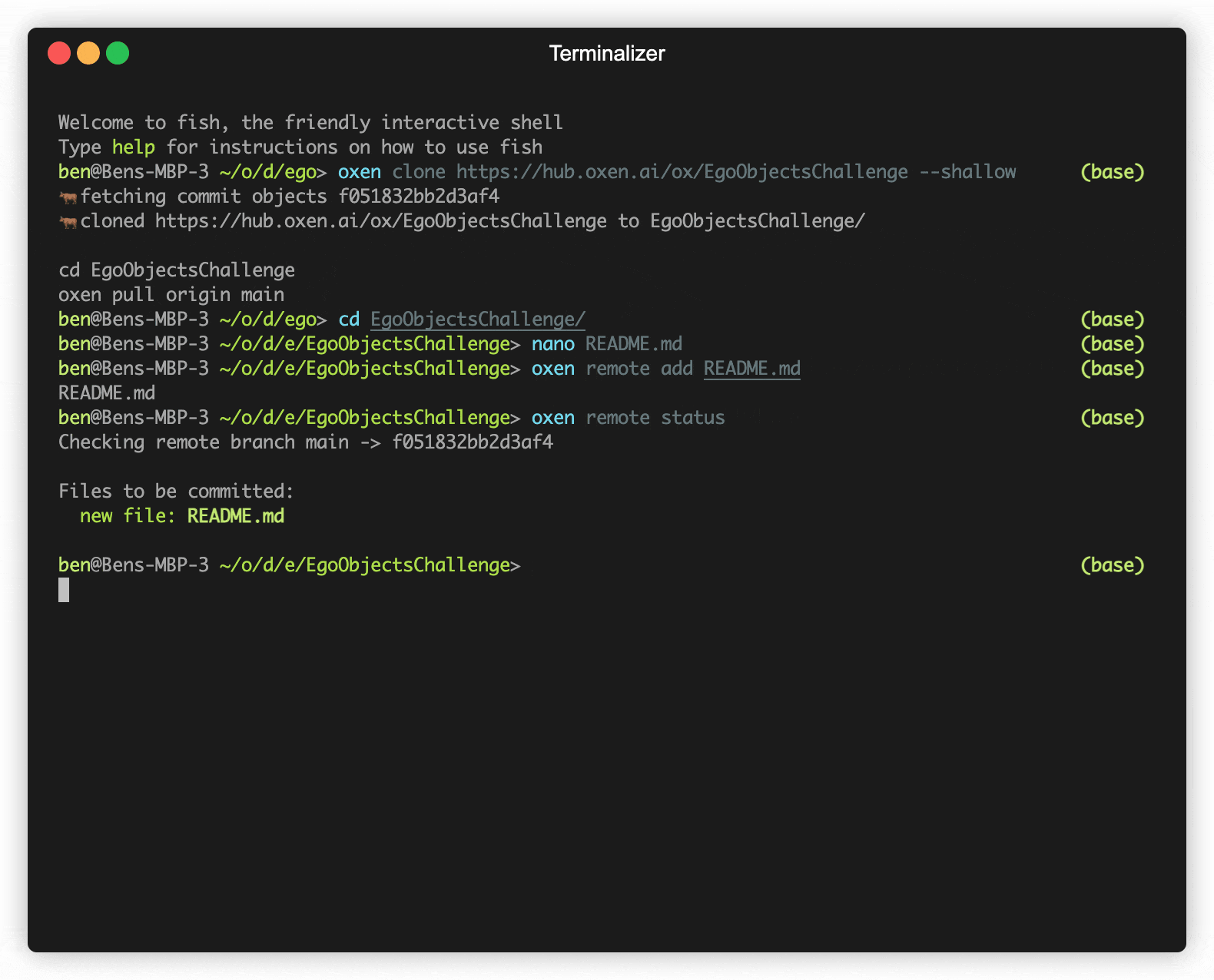
We now have a fully-functioning Oxen repository in remote mode, without needing to locally download any data we aren't interested in managing.
We can interact with it with all the familiar git-style commands, postfixed with remote to indicate we're working with a virtual copy of a remote repository. Think of it as a light shell into a remote machine where you are making all the actual changes.
Making a remote contribution
Let's make a branch on this repo and add an additional image to our training set, like this one below of a coffeemaker:

# Move the image into the correct folder in the repo
mkdir EgoObjectsChallenge/images
cp coffee-pot.jpg EgoObjectsChallenge/images
cd EgoObjectsChallenge
# Create a development branch and push it to the remote
oxen checkout -b dev
oxen push origin dev
# Remotely stage the image
oxen remote add images/coffee-pot.jpgSince we’re adding an image to the training set, we also need to update our training labels file to point at this new image’s path. We can quickly preview it in the Oxen CLI to get a grasp on the schema:
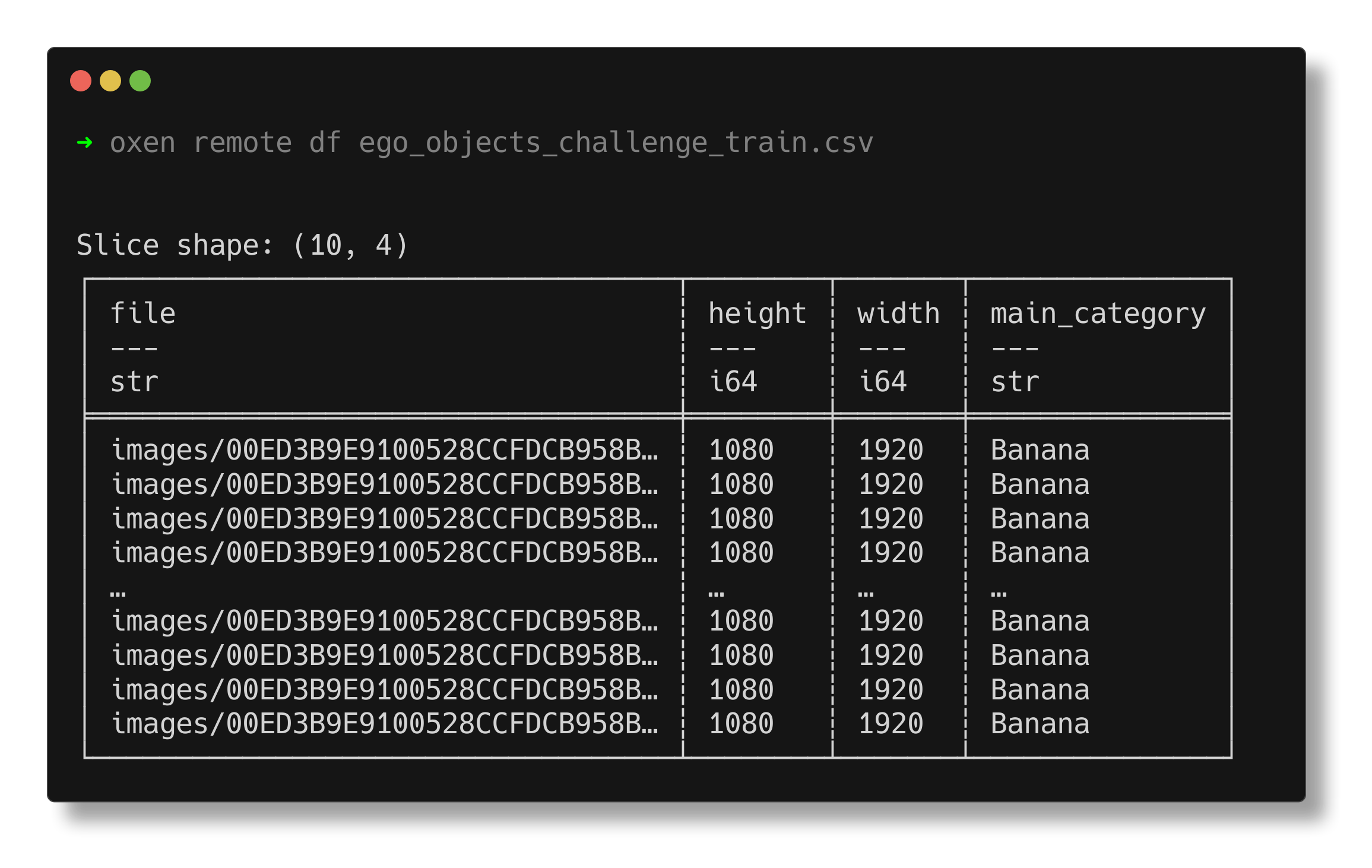
…and add a row to the DataFrame with our new observation!
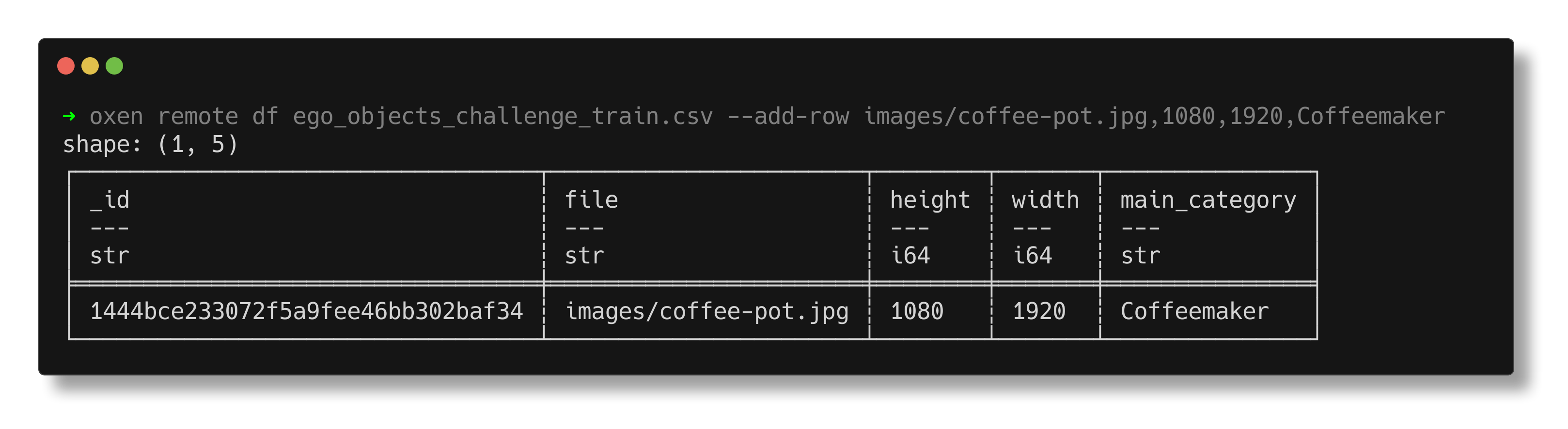
We've now remotely staged our image addition and label modification, and are ready to commit.
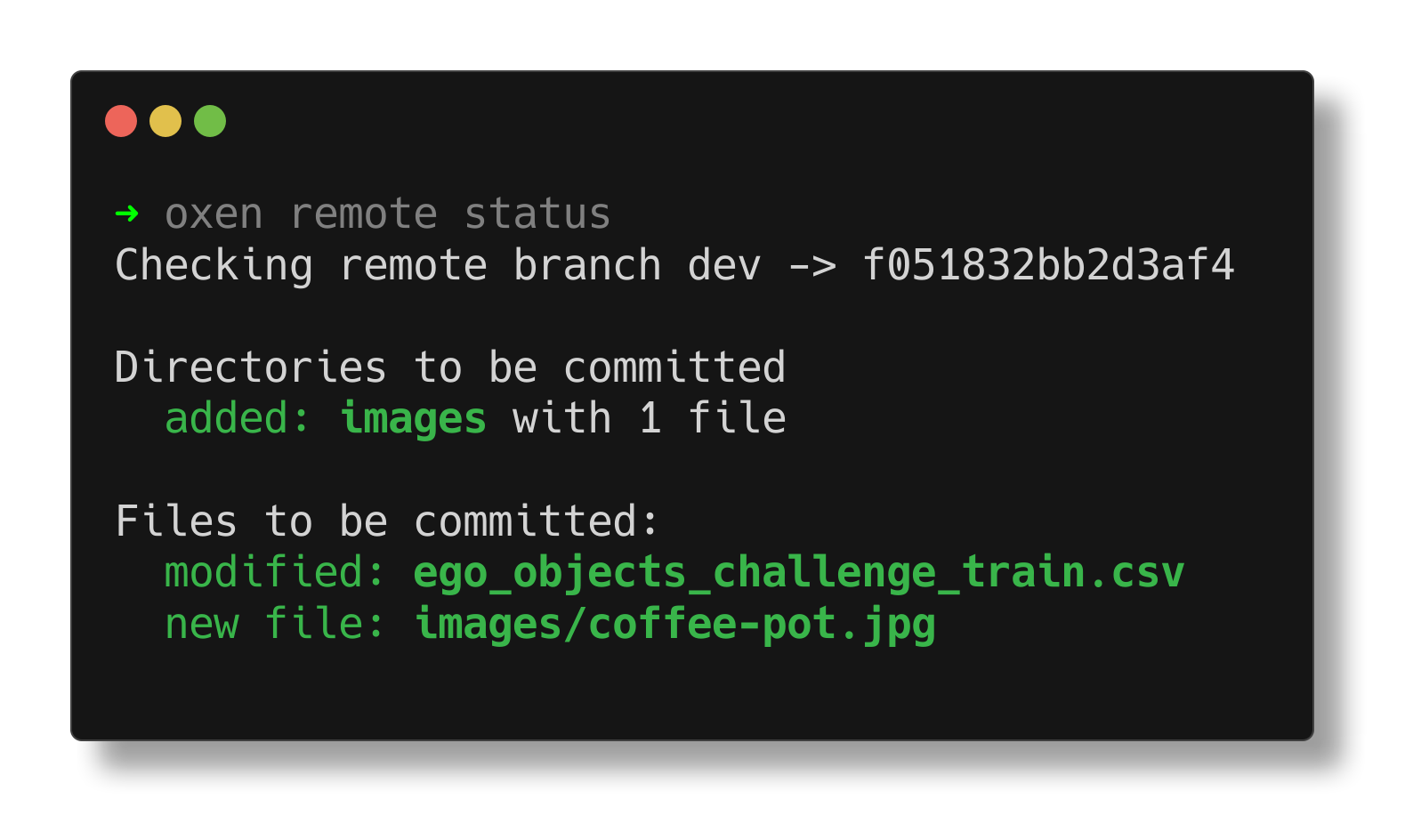
(For those familiar with git, note that no push command is required here, as we're creating a commit directly on the remote.)

🎉 Ta-da! The commit, image, label, and row have been added to our dev branch in OxenHub.
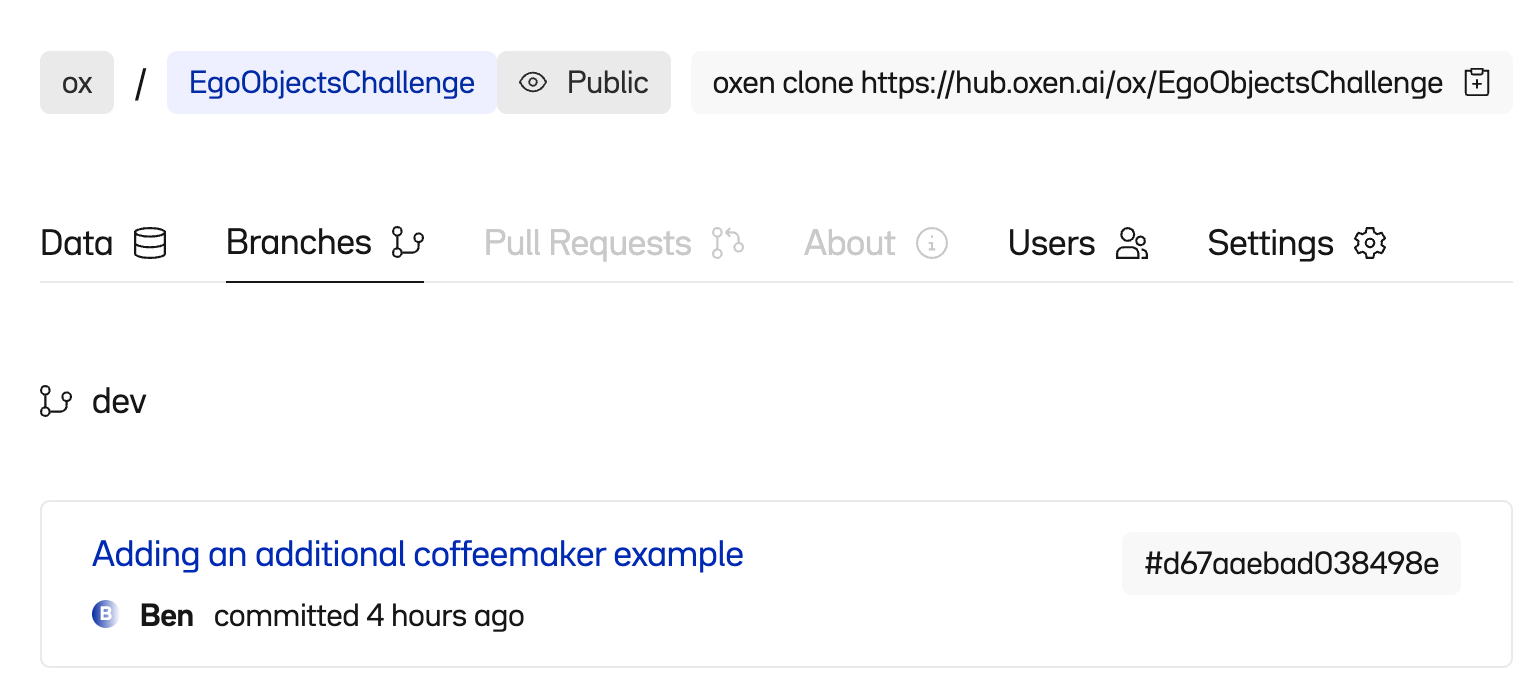
Wrapping up
Oxen's remote workspaces enable easy, lightweight contributions to some seriously heavyweight datasets. These command-line workflows alone bring a massive improvement in iteration speed and reproducibility relative to downloading and passing around files with names like Dataset_train_v3_recent_final_FINAL.zip, but this is just the beginning.
We're most excited about the wide range of flexible, low- and no-code data versioning that remote workspaces can enable. Watch this space for an upcoming tutorial showing how to contribute to Oxen data repos just by sending an email!
We'd love to see what you're building with these tools! Reach out to hello@oxen.ai, follow us on Twitter @oxendrove, give us a ⭐ on GitHub, dive deeper into the documentation, or Sign up for Oxen today.