Arxiv Dives - Retrieval Augmented Generation (RAG)

Every Friday at Oxen.ai we host a public paper club called "Arxiv Dives" to make us smarter Oxen 🐂 🧠. These are the notes from the group session for reference. If you would like to join us live, sign up here.
The following are the notes from the live session. Feel free to follow along with the video for the full context.
Arxiv Paper: https://arxiv.org/abs/2005.11401
Intro
Large language models have been shown to store knowledge in their parameters, and perform state of the art when fine tuned on downstream tasks.
We’ve seen this with GPT-2, GPT-3 and InstructGPT in the past few Arxiv Dives.
Their performance on “Knowledge Intensive Tasks” is still behind task-specific architectures.
Background Knowledge
Let's walk through an example of the type of task we are performing. In this case question answering, where we have to extract the answer to a question from candidate passages.
Can you figure out the answer to the question, given the following passages?
Question
Who directed the classic 30s western Stagecoach?
Passages
- Actor-director Herb Jeffries recalls his inspiration for his singing cowboy role in many of the classic musical westerns of the late 30s.
- By the late 1930s, the Western film was widely regarded as a "pulp" genre in Hollywood, but its popularity was dramatically revived in 1939 by major studio productions such as Dodge City starring Errol Flynn, Jesse James with Tyrone Power, Union Pacific with Joel McCrea, Destry Rides Again featuring James Stewart and Marlene Dietrich, and especially John Ford's landmark Western adventure Stagecoach starring John Wayne, which became one of the biggest hits of the year.
- John Wayne is "The Ringo Kid" in this John Ford-directed parable of outcasts traveling towards various kinds of figurative and literal redemption/salvation. (Source IMDB)
- Stagecoach is a 1939 American Western film directed by John Ford and starring Claire Trevor and John Wayne in his breakthrough role (Source Wikipedia)
Answer
John Ford
It probably took you a little reading to figure out the final answer.
Traditional Approaches
- Break down the query into keywords (“directed”, “classic 30s western”, “stagecoach”)
- Search for passages containing the keywords
- Extract candidate answers for the keywords
- Find more evidence for each candidate answer
- Score each answer - question pair given the evidence
Exact string matches make the search and retrieval problem hard
- “western” != “westerns”
- “1930s” != “30s”
- “Director” != “directed”
- “Stagecoach” == a music festival, a movie, a thing you ride in….which one are we looking for?
Word Vectors, Document Vectors, Dense Vector Index
For the rest of the paper to make sense, it is important to know what a word vector, a document as a latent variable, and a dense vector index mean.
Word Vectors
A good explaination can be found here:
 Jayesh Bapu Ahire
Jayesh Bapu Ahire
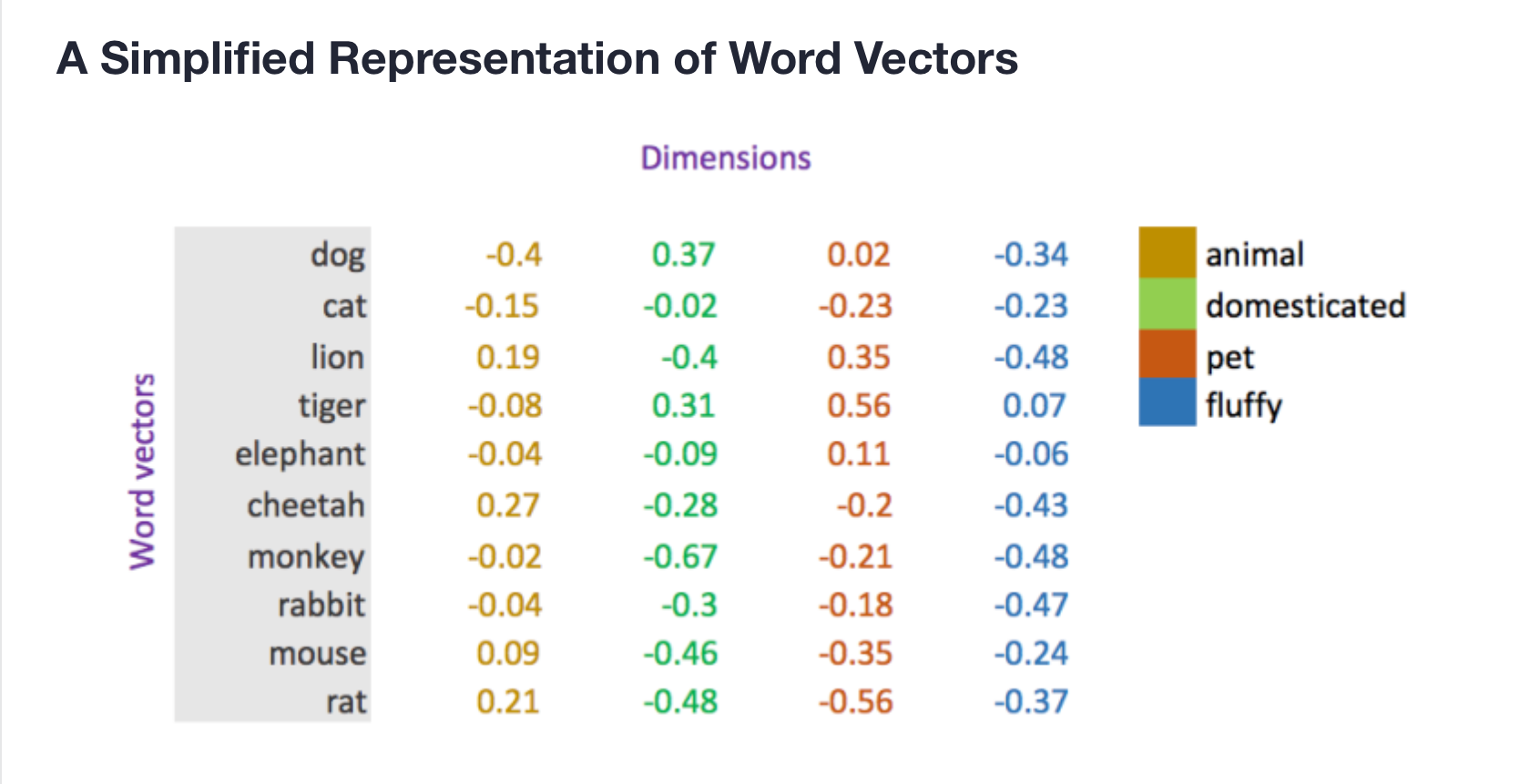
Words can be represented as vectors of numbers, where each number is a feature about the word.
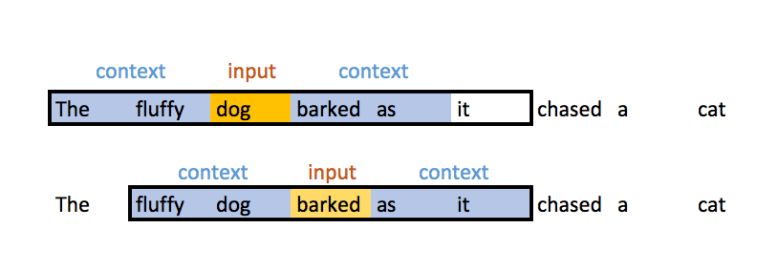
These vectors are learned through a simple process of predicting the words that surround it with a neural network.
“You shall know a word, by the company it keeps”
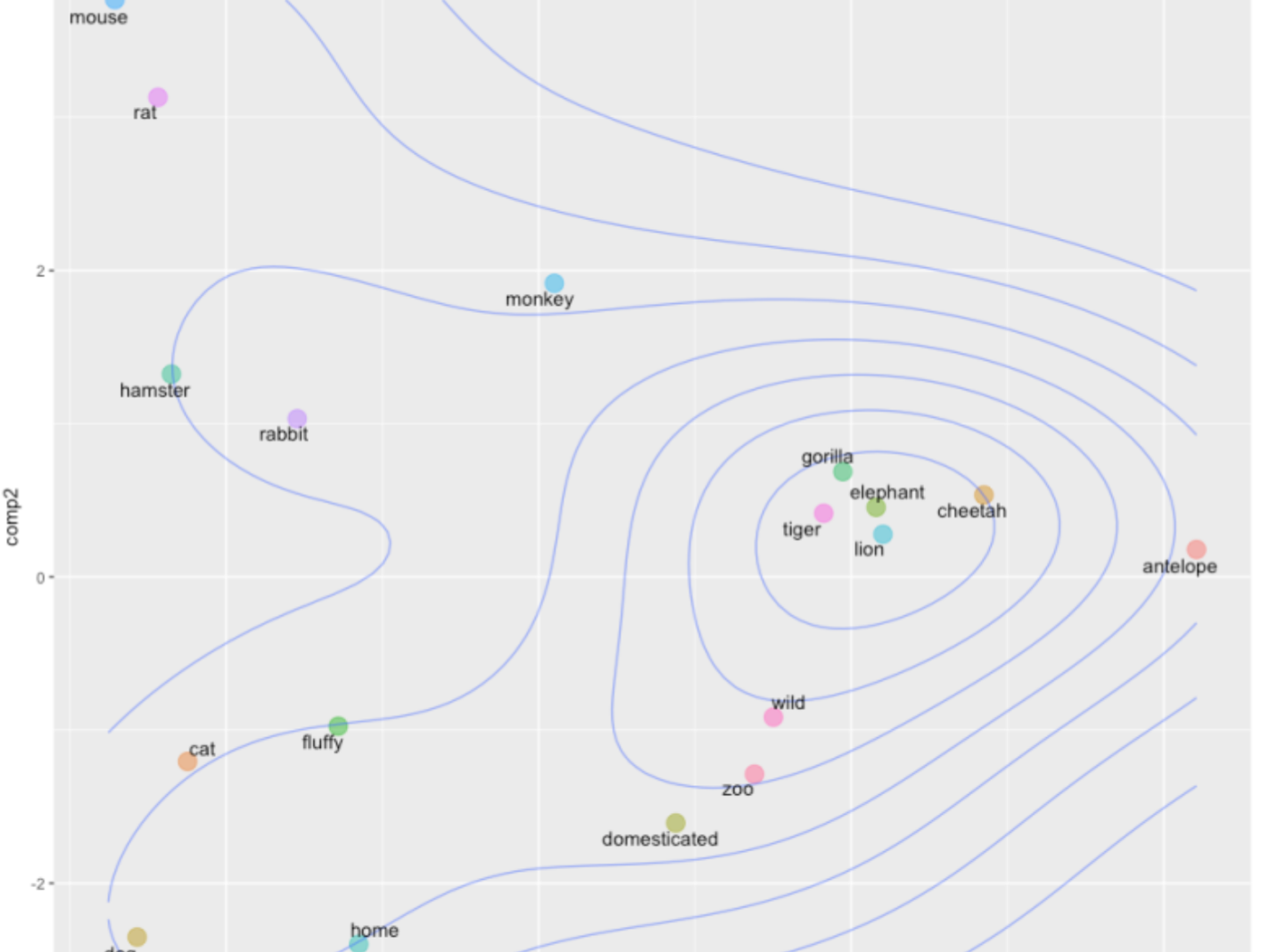
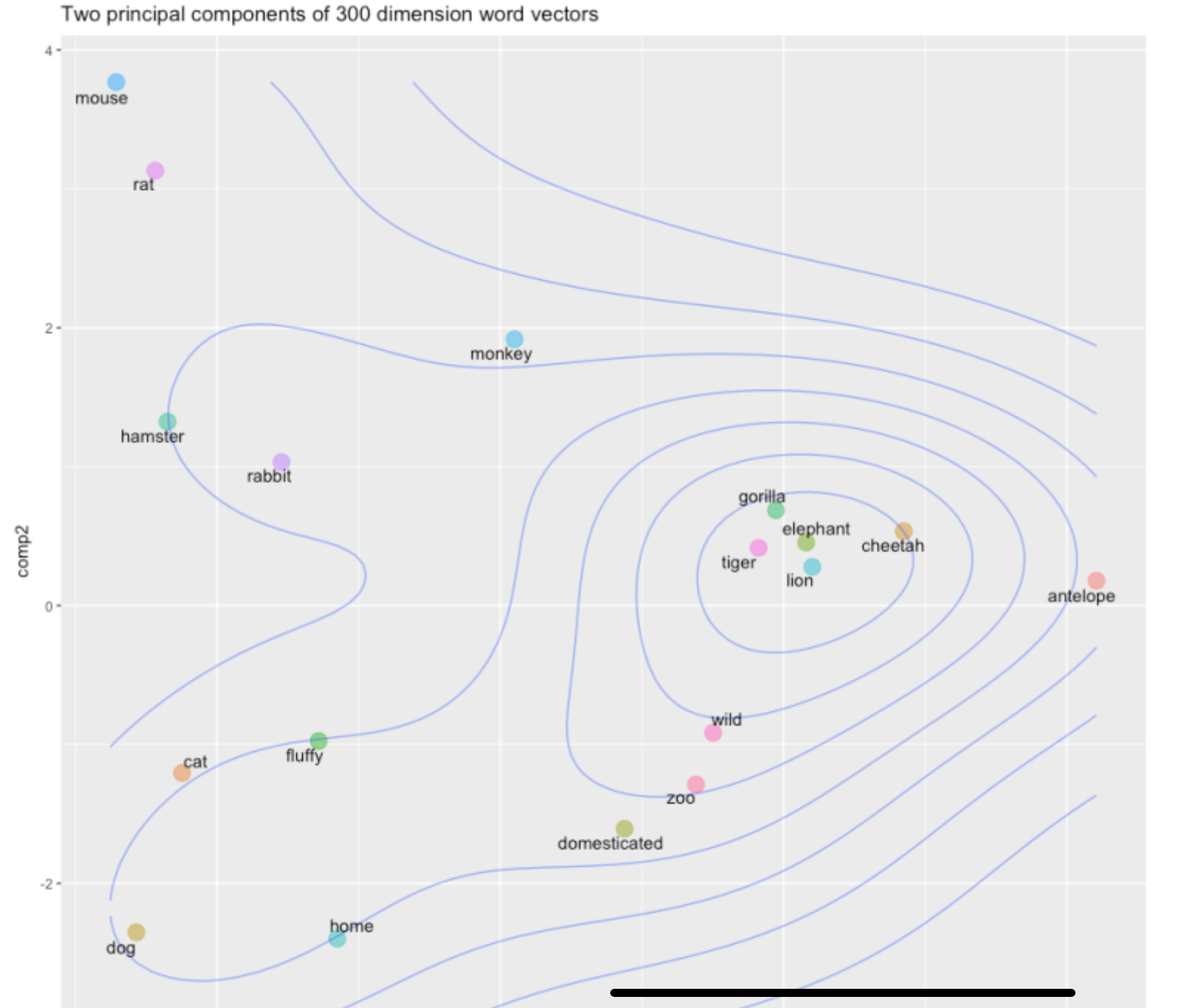
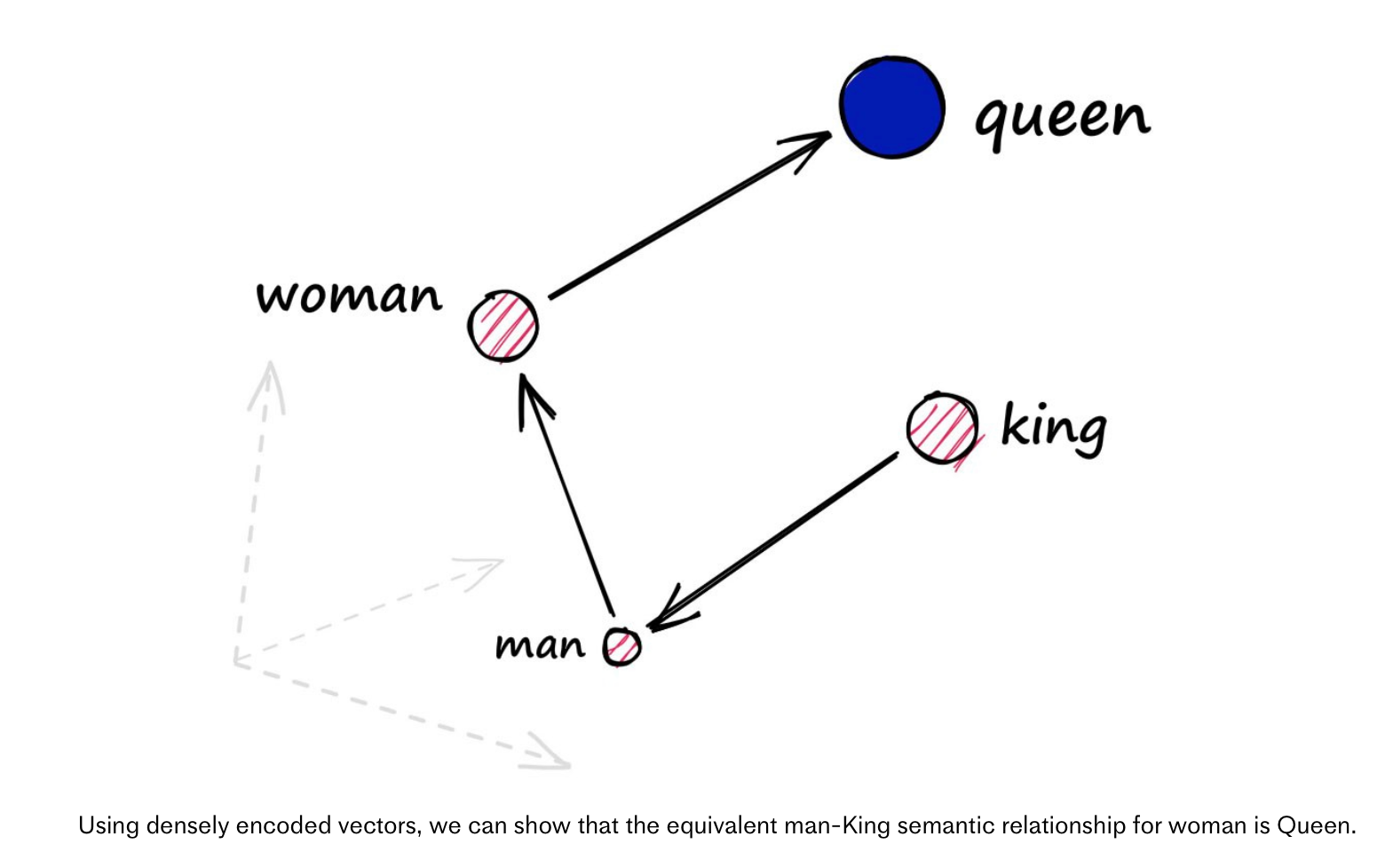
Once you have these word vectors, researchers have found that they cluster together in "embedding space".
You can also do math on them, for example subtracting the value of "man" from "king" and adding the value of "woman" gives you a vector that is closest in space to "queen".
Document Vector
Do this same process…but with entire documents. You can imagine predicting the previous/next sentence given the current sentence.
You can also just extract hidden states from large language models for this. Also called “embeddings” or “latent variables”.
Dense Document Index
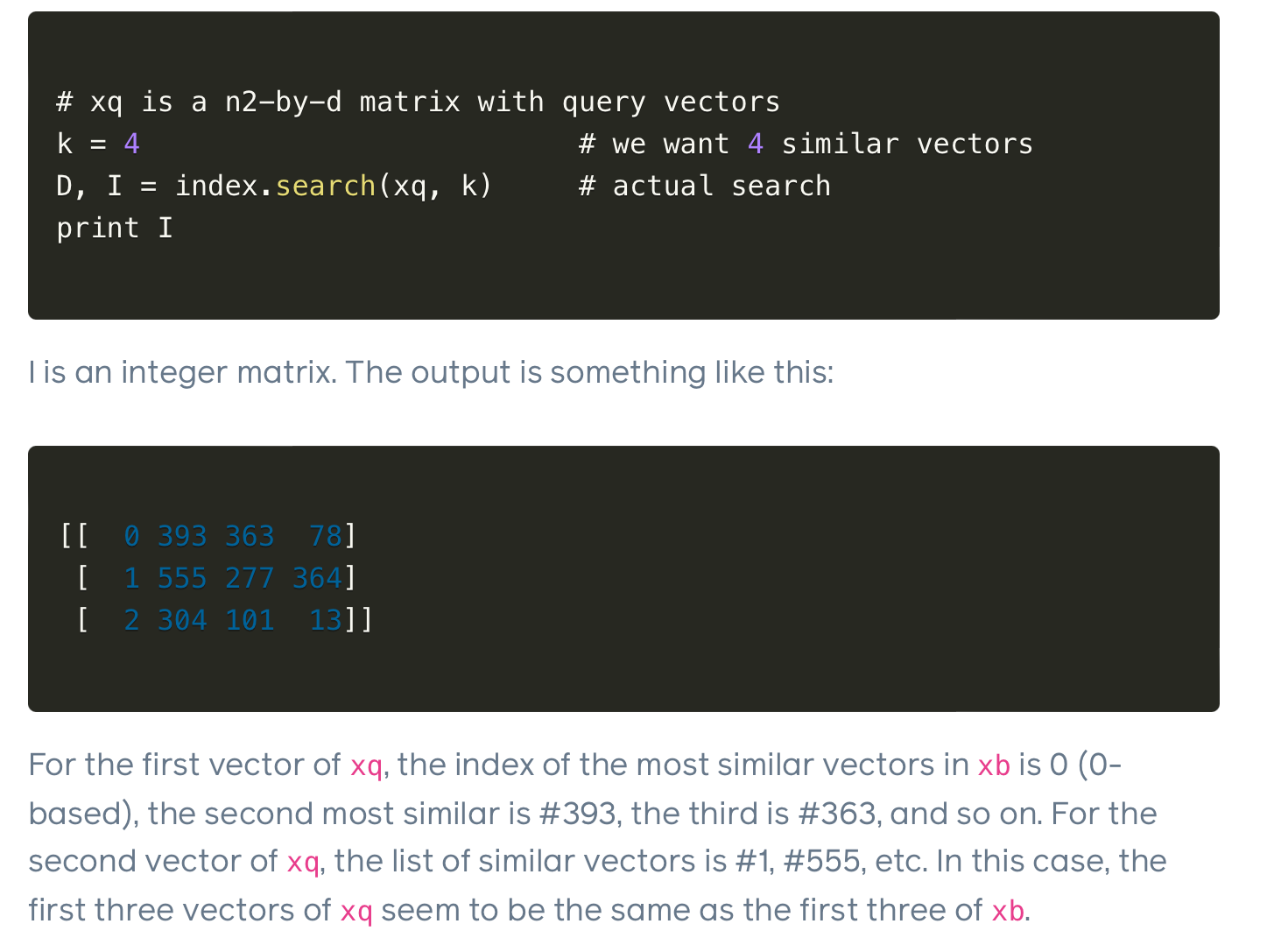
There are open source libraries such as FAISS that make it pretty easy to do a nearest neighbors search given a set of vectors.
Datasets
They find that RAG sets state of the art on 3 open domain question answering tasks, and generates more specific, diverse, and factually correct statements during language generation.
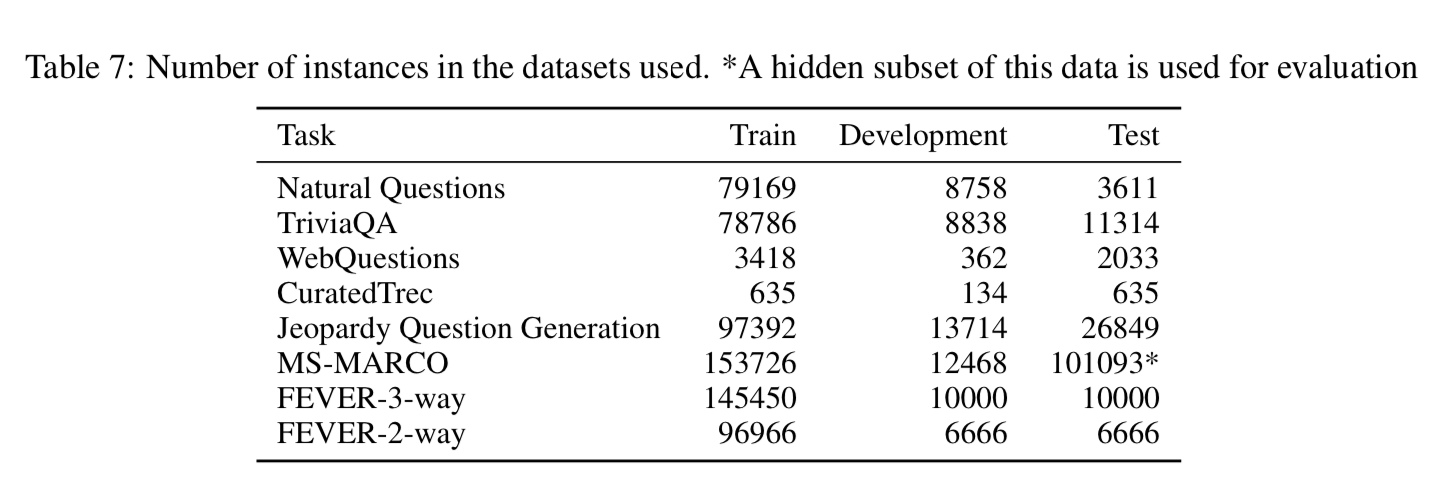
QA Datasets
- Natural Questions
- Web Questions
- CuratedTrec
- TriviaQA
Knowledge-intensive generation
- MS-Marco
- Jeopardy question generation
- FEVER - Fact verification
Usage
They published an example here. Note: you need a lot of RAM to index the entire set of wikipedia documents.
Methods
Use the input text (x) to retrieve text documents (z) and use them as additional context when generating target sequence (y).
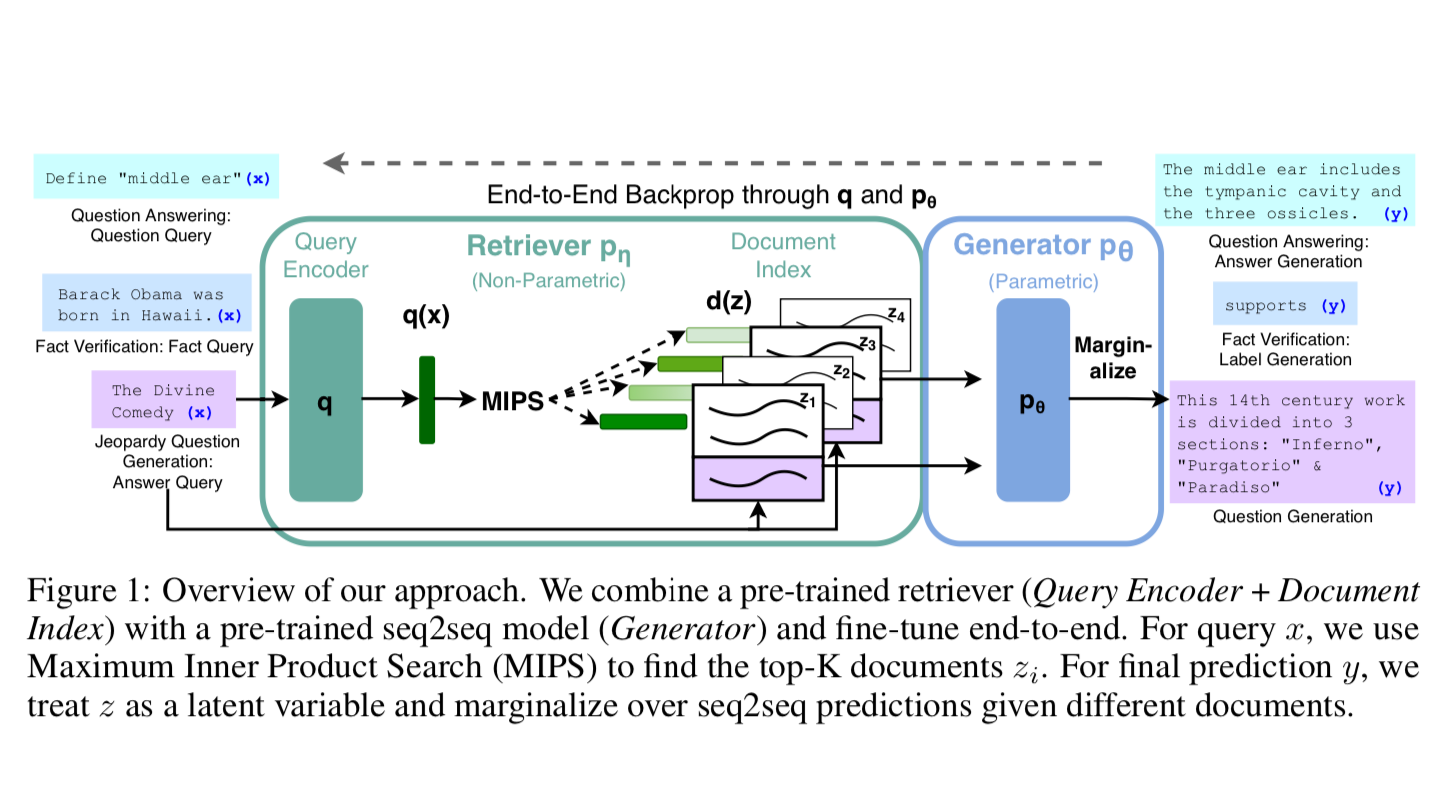
They train the retriever and the generator end-to-end by treating the retrieved document as a latent variable.
Models
Rag-Sequence
Treats the retrieved document as a single latent variable to get the probabilities p(y|x) of a set of documents.
The retriever finds K documents, and for each document, the generator generates some text, given that single document.
I think it’s helpful to break these equations down, because they are not that hard once you know each variable.

RAG-Token Model
The model can look at a different document vector for each target token.
This allows the generator to choose content from several documents when producing an answer.
Each individual component of this equation is the same, just arranged slightly different.

They note that you can also use these models for sequence classification tasks, not only sequence generation, by treating the target class as a sequence of one. For example sentiment analysis, you could just be predicting the output “positive”, “negative”, or “neutral”.
The Retriever (DPR)
“Dense Passage Retriever” https://arxiv.org/abs/2004.04906
The probability of a passage z given the input text x p(z|x)
They run the passage through a trained BERT model d(z) (Bidirectional Encoder Representation Transformer) called the “document encoder”.
They run the text through another BERT q(x) called the “query encoder”.
Then you simple multiply the encoded query by the encoded document to get a score.
Maximum Inner Product Search (MIPS) to rank all the documents.
MIPS is just attempting to maximize the inner product between the query and data items retrieved. A fancy way of saying we multiply the vectors together and see what the product is, then take the ones with the largest number (are the most similar).
Replacing systems like Lucene or Elastic Search TF-IDF or BM25 for retrieving documents.
Generator: BART
They say it can be any encoder-decoder model, they happen to use a pre trained seq2seq transformer with 400M parameters called BART (Denoising Autoencoder from Transformer).
BERT is useful for encoding, and BART is useful for decoding.
https://iq.opengenus.org/bart-vs-bert/

Decoding
RAG-Token is your basic predict the next word based on the previous words.
RAG-Sequence, since it has a different document it is looking at for each sequence, so they do some additional decoding measures called “Thorough Decoding” to multiply and sum the probabilities across all the documents, it’s a little more expensive, and needs additional optimizations is the main takeaway.
They retrieve k=5..10 documents when querying the document index.
Training
They say that it is expensive to update the document index if you update the “document encoder” model, so they really only fine tune the “query encoder” BERTq and the BART generator.
They trained BART on 8, 32GB NVIDIA v100s, but mention that training or inference can be run on a single GPU, it’s just slower.
You can really use any encoders or decoders for these building blocks, they happen to choose BERT and BART, but you could use Llama-2 or OpenAI embeddings API or any model that can take in text, and spit out a vector that represents that text.
Data
Specifically they use a December 2018 dump of Wikipedia.
Each article is split into 100-word chunks, making 21M total documents.
Each vector is 728 floating point numbers. So 728 421million = 61,000,000,000 bytes, but they said you can store them as 8bit floating point precision, so definitely some finagling you can do here.
The document index required ~100GB of CPU memory for all of Wikipedia, which probably includes the string metadata + raw floating point vectors.
They have an open source version that they compressed the document index to a CPU memory requirement of 36GB.
An advantage of the document encoder index is you can add new knowledge at any time, by inserting new document vectors.
The disadvantage is if you want to update the document encoder model itself, you have to update the entire index, which is slow.
Evaluation
I like to think of evaluating systems like this similar to how IBM Watson evaluated it's models.
Precision vs Recall
IBM plotted the winners of Jeopardy by how often they answered correctly (Precision) given how often they buzzed in at all (Recall). The winners are the red dots. The best players being able to get the questions correct 90% of the time and buzzing in for 80% of the questions.
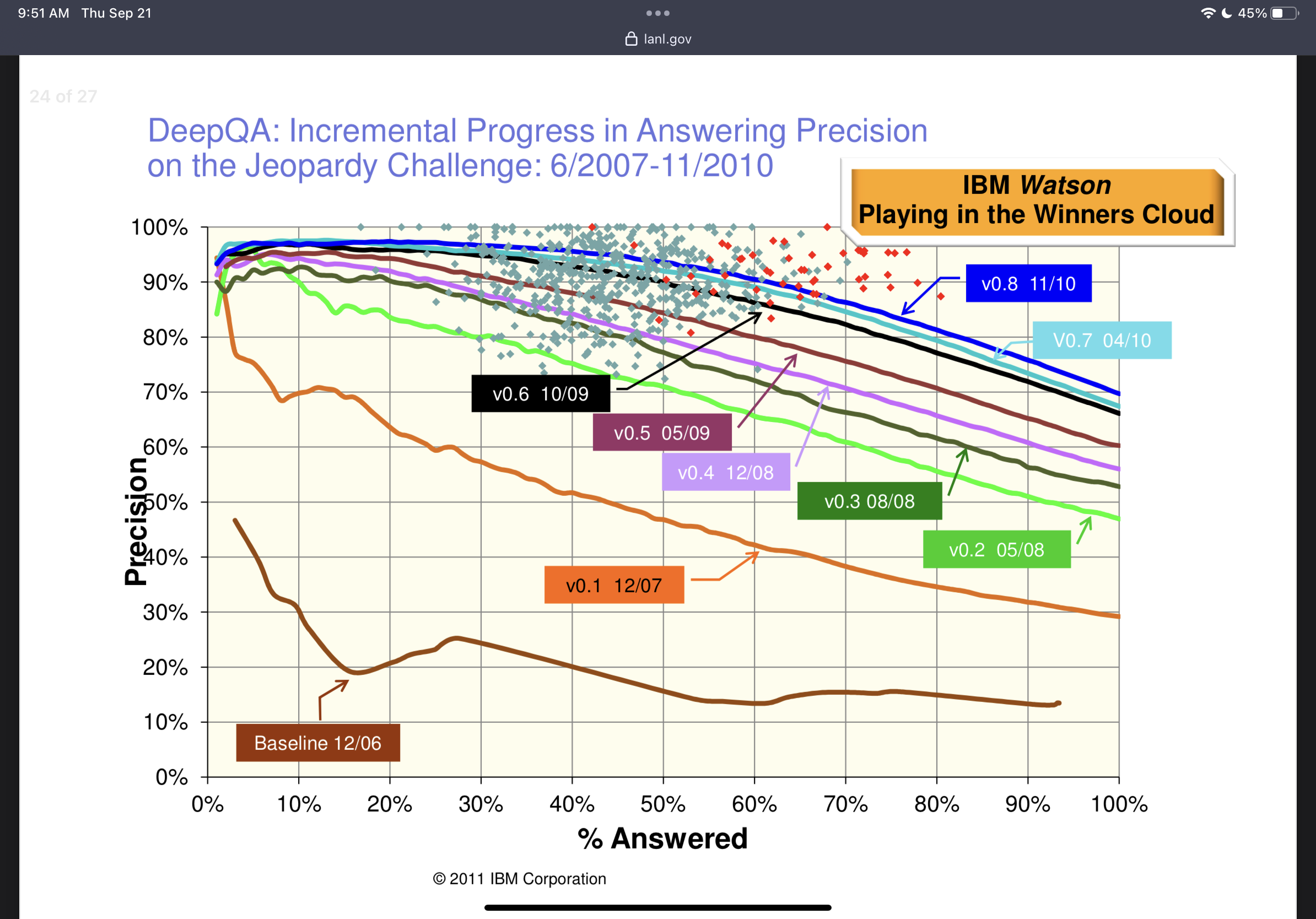
Knowing when to answer a question, and when you do not know, is an imporant skill for LLMs.
Since there can be multiple answer variations for a single question, they trained on each answer variation as a separate (q, a) pair example.
They built an internal tool to help with Human Evaluation.

Here are some more examples from the datasets to illustrate the difficulty of the task.

If you enjoyed this dive, please join us next week!

All the past dives can be found on the blog.


The live sessions are posted on YouTube if you want to watch at your own leisure.


Best & Moo,
~ The herd at Oxen.ai
Who is Oxen.ai?
Oxen.ai is an open source project aimed at solving some of the challenges with iterating on and curating machine learning datasets. At its core Oxen is a lightning fast data version control tool optimized for large unstructured datasets. We are currently working on collaboration workflows to enable the high quality, curated public and private data repositories to advance the field of AI, while keeping all the data accessible and auditable.
If you would like to learn more, star us on GitHub or head to Oxen.ai and create an account.