
Arxiv dives
Every Friday at Oxen.ai we host a paper club called "Arxiv Dives" to make us smarter Oxen 🐂 🧠. We believe diving into the details of research papers is the best way to build fundamental knowledge, spot patterns and keep up with the bleeding edge.
In Arxiv Dives, we cover state of the art research papers, and dive into the gnitty gritty details of how AI models work. From the math to the data to the model architecture, we cover it all.
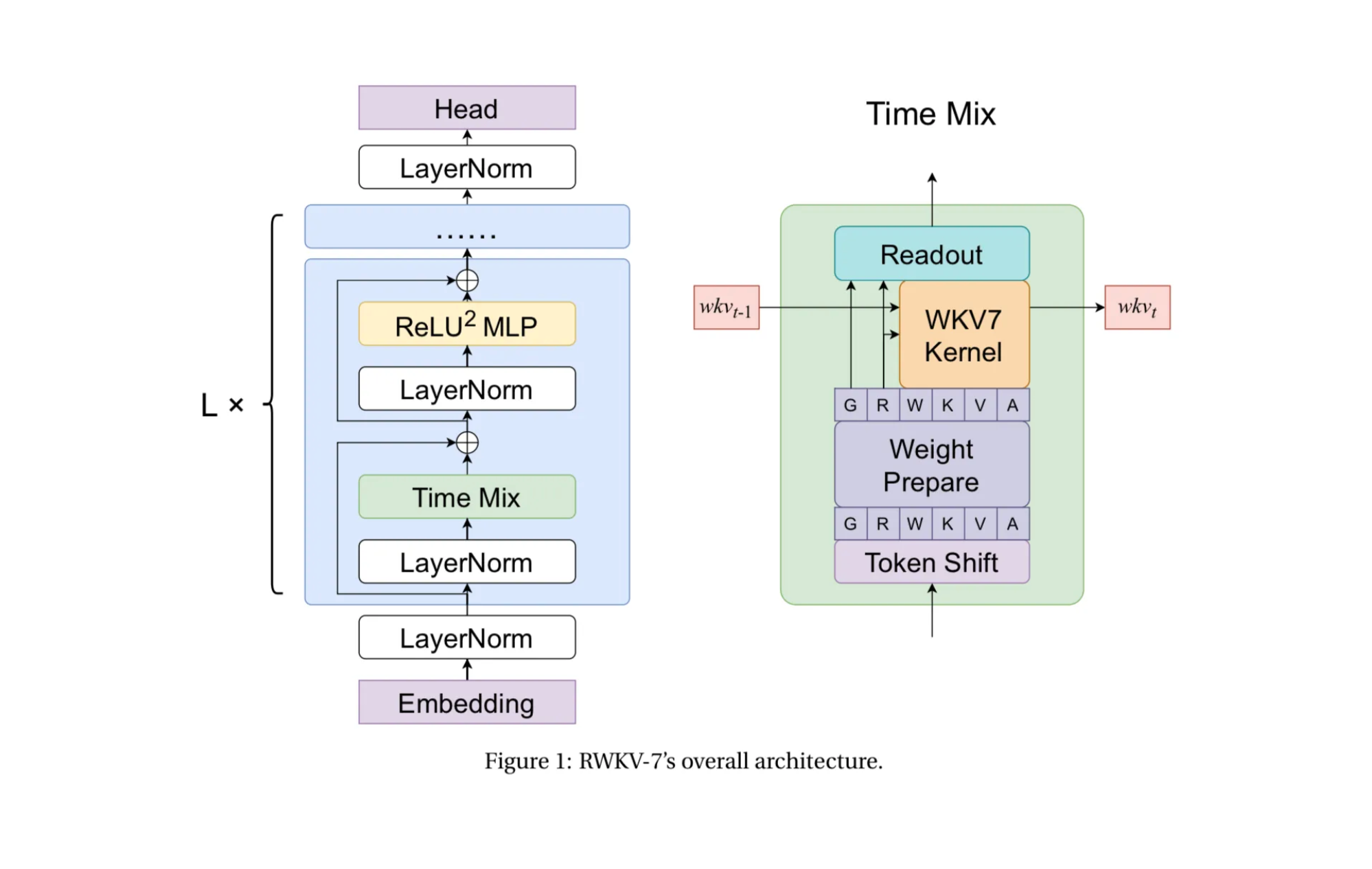
In this special Arxiv Dive, we're joined by Eugene Cheah - author, lead in RWKV org, CEO of Featherless AI, to discuss the development process and key decisions behind these models...

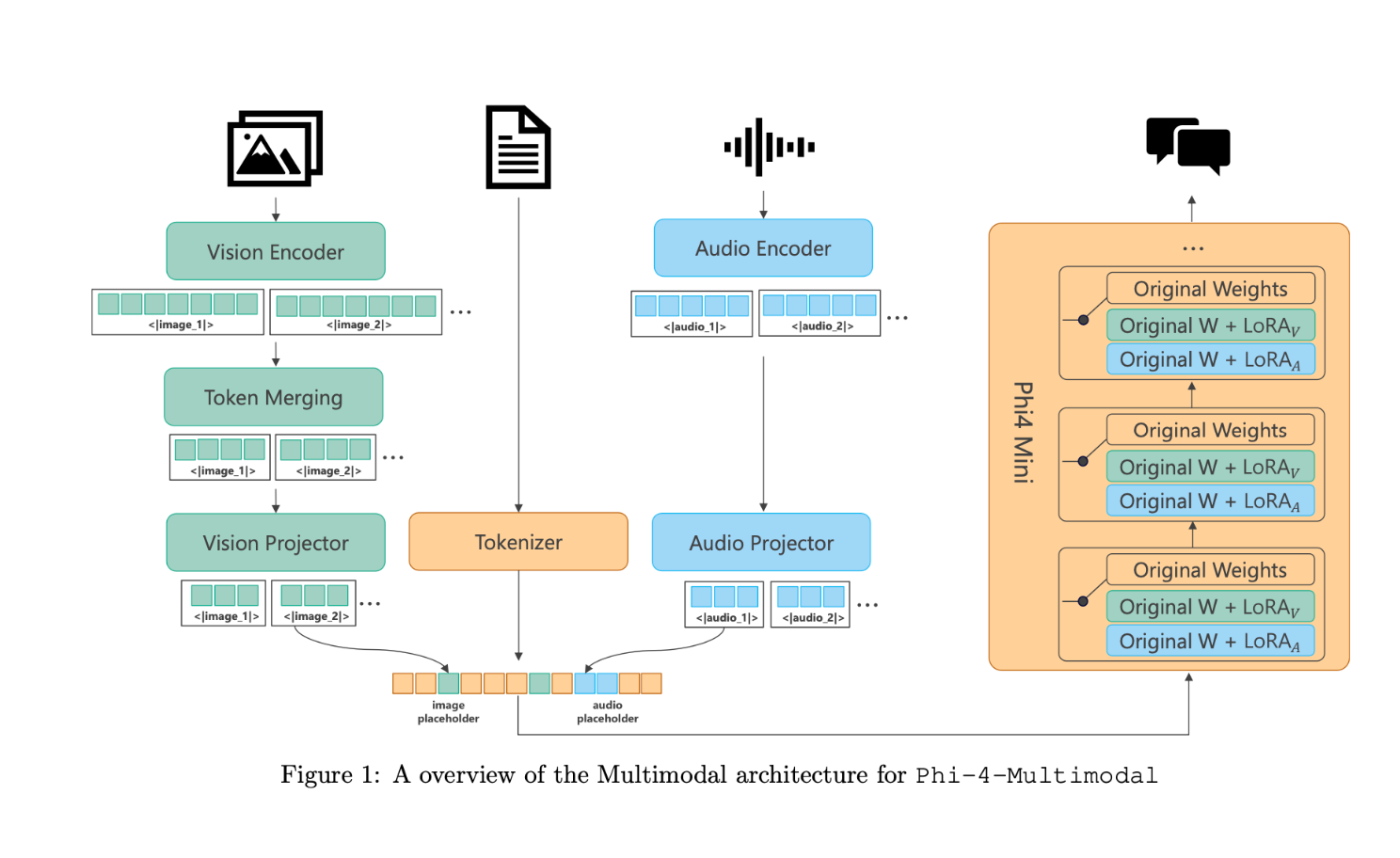
Phi-4 extends the existing Phi model’s capabilities by adding vision and audio all in the same model. This means you can do everything from understand images, generate code, recogn...
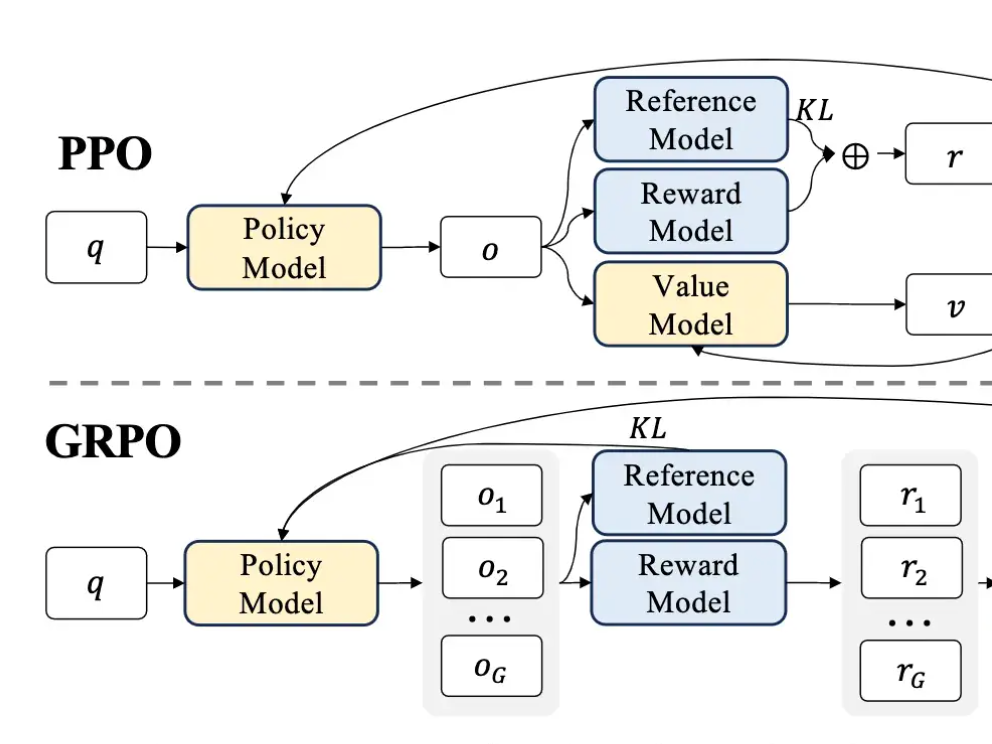
Last week on Arxiv Dives we dug into research behind DeepSeek-R1, and uncovered that one of the techniques they use in the their training pipeline is called Group Relative Policy O...
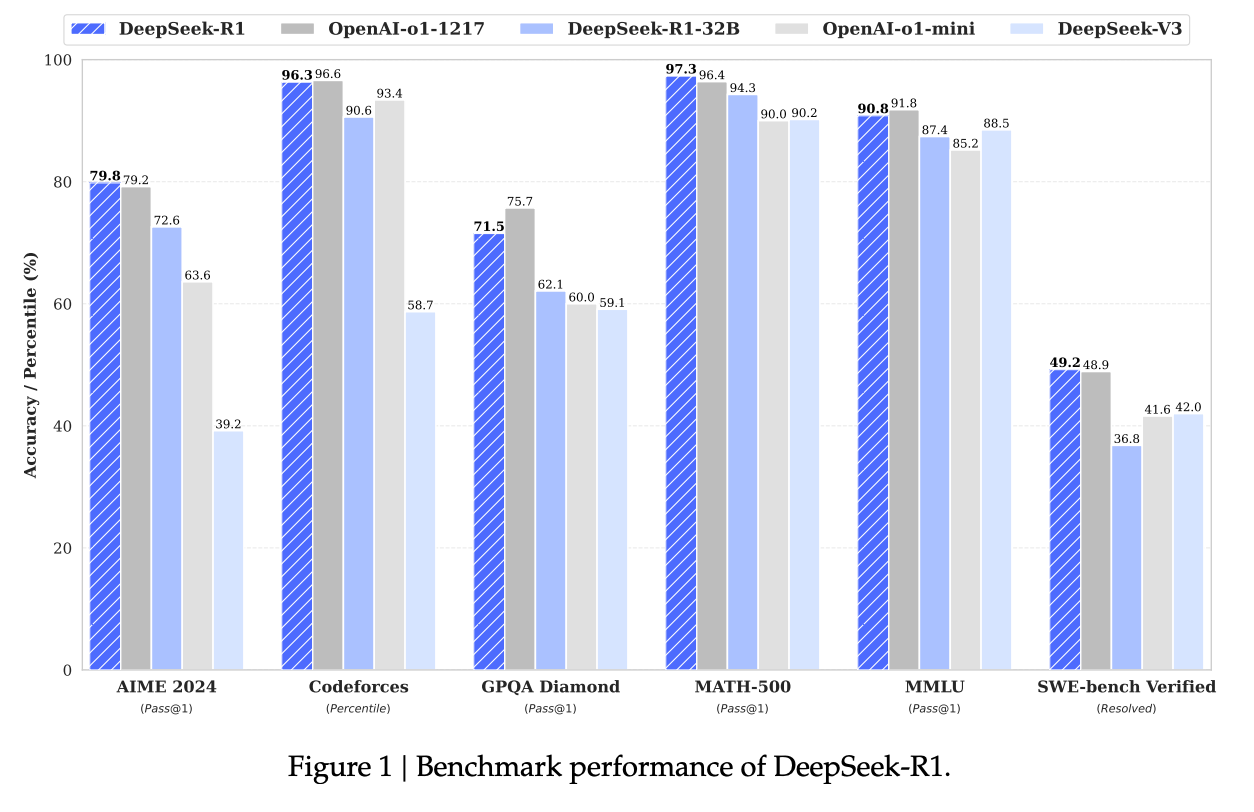
In January 2025, DeepSeek took a shot directly at OpenAI by releasing a suite of models that “Rival OpenAI’s o1.” From their website: In the spirit of Arxiv Dives we are going to...

DeepSeek-R1 is a big step forward in the open model ecosystem for AI with their latest model competing with OpenAI's o1 on a variety of metrics. There is a lot of hype, and a lot o...

RAGAS is an evaluation framework for Retrieval Augmented Generation (RAG). A paper released by Exploding Gradients, AMPLYFI, and CardiffNLP. RAGAS gives us a suite of metrics that ...

Welcome to the last arXiv Dive of 2024! Every other week we have been diving into interesting research papers in AI/ML. In this blog we’ll be diving into Open Coder, a paper and co...
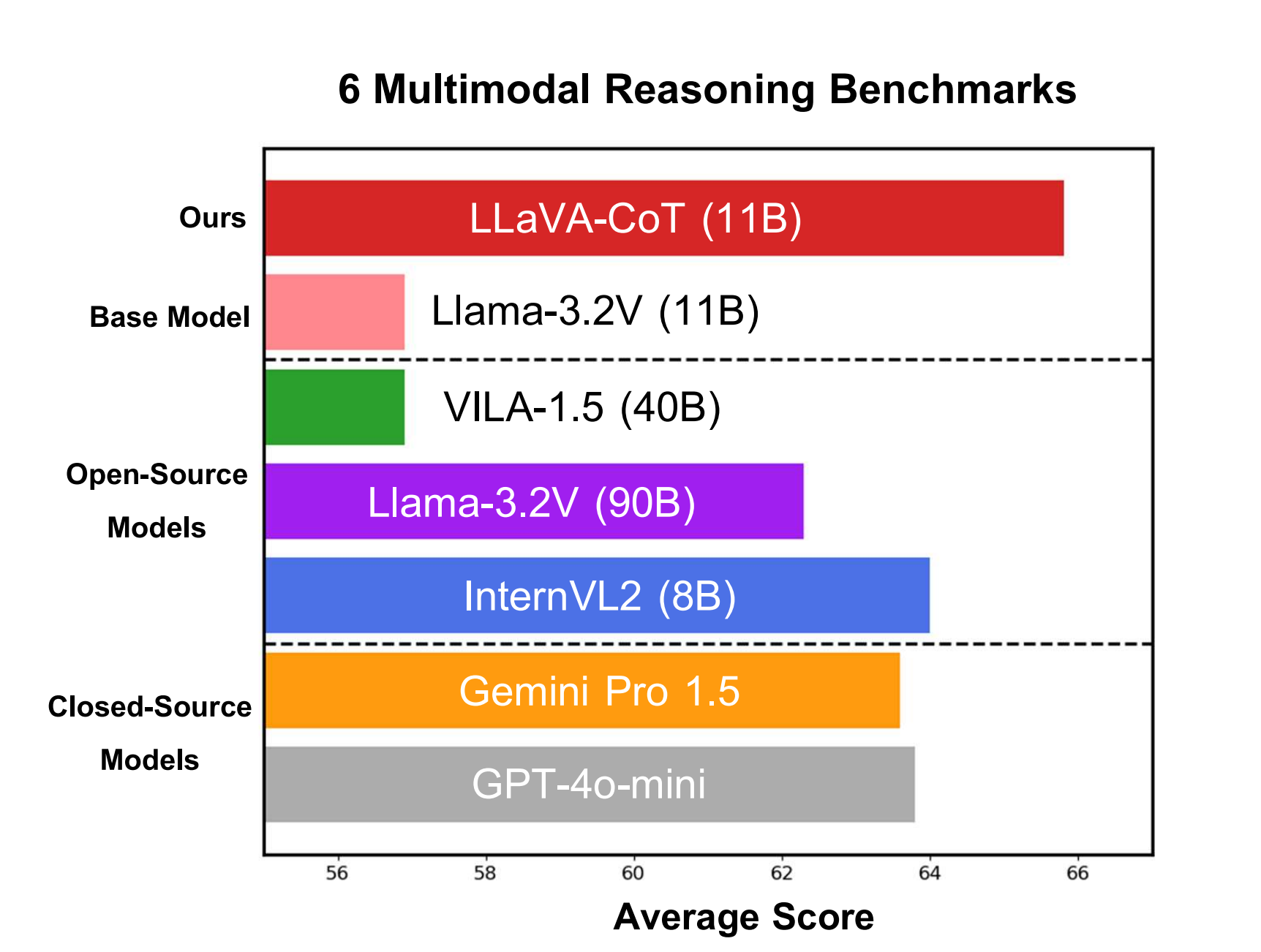
When it comes to large language models, it is still the early innings. Many of them still hallucinate, fail to follow instructions, or generally don’t work. The only way to combat ...
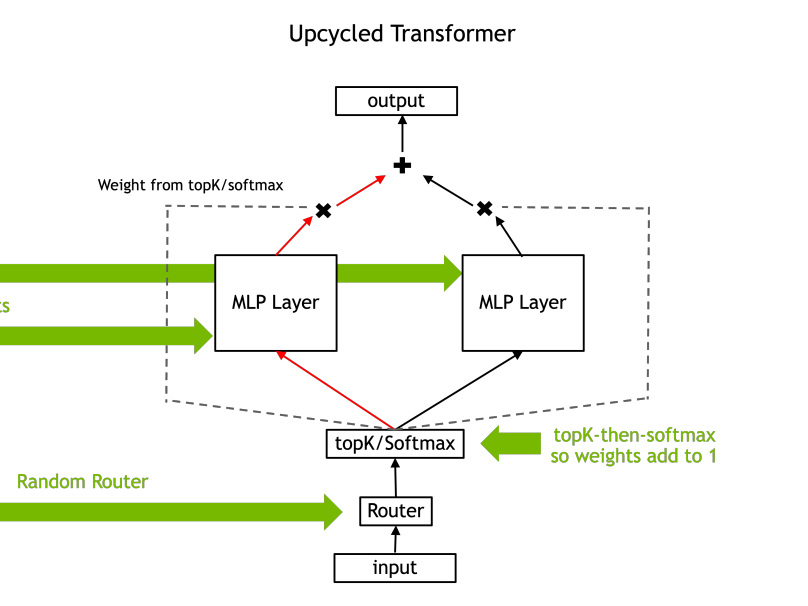
In this Arxiv Dive, Nvidia researcher, Ethan He, presents his co-authored work Upcycling LLMs in Mixture of Experts (MoE). He goes into what a MoE is, the challenges behind upcycli...
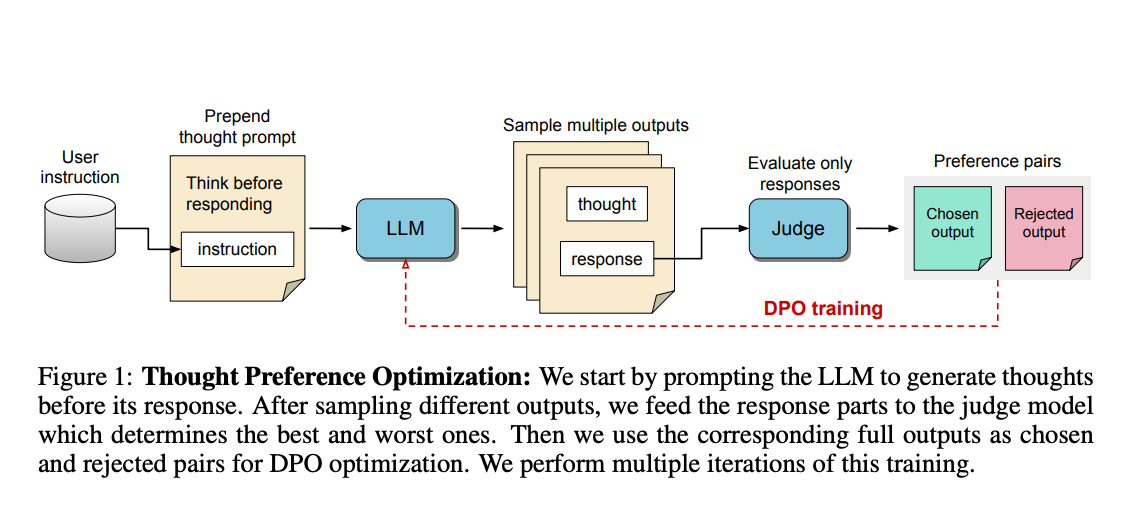
The release of OpenAI-O1 has motivated a lot of people to think deeply about…thoughts 💭. Thinking before you speak is a skill that some people have better than others 😉, but a sk...