Oxen.ai Blog
Welcome to the Oxen.ai blog 🐂. The Oxen team is dedicated to helping AI creators and builders go from research to production. We love to learn and share our learnings with the community. Sign up for any of our future events on our luma page.

Every time I decide to write one of these I come up with an initial shortlist. By the time I actually sit down to write, a couple of days have usually passed and I have to complete...


The hardest part of AI video isn't pressing generate. It's finishing. How do you get high-quality 4K HDR content into your post-production pipeline? That's where models like the To...


Hey Herd, It's been awhile since we've done a proper feature update, so wanted to come up for air to show you the latest and greatest. The Oxen team has been heads down plowing th...

Higgsfield is great for solo creators who want a polished, creative-first studio. Its curated cinematic presets and effects get you to a good-looking result quickly, all wrapped i...

Magnific and Oxen.ai both put the top AI image and video models in one place, alongside upscaling and editing tools. If you are choosing between them, the differences come down to ...

Welcome back to another iteration of everybody's favorite moooodel report. Every time I sit down to write one of these I'm shocked by how much there is to cover (as you might've se...

🚨You're about to embark on a journey of ups and downs and many aha moments. We're pulling back the curtain on every painful hour so you never have to spend them yourself. Fine-tun...

Welcome back to another iteration of everybody’s favorite moooodel report. In AI, any given day feels like a decade, and the past couple of weeks have felt like a couple of centuri...

💡Curious about fine-tuning multi-modal models? This Friday, we're diving into the new Qwen3.5 series, what makes it great and how to train it on images and video. Join us live for...

Welcome back to another iteration of our favorite moooodel report. This week we've got an absolutely packed lineup, from motion-controlled video generation to open-weight language ...

0:00 /0:45 1× An AI generated goat rapping alongside Ludacris in Frank's RedHot's "Eat The GOAT" Super Bowl ad. The goat was fully genera...

A giant isometric pixel-art map of New York City, inspired by SimCity 2000 and Rollercoaster Tycoon. Andy Coenen fine-tuned an image model on Oxen with just 40 training examples to...

0:00 /0:30 1× A fully AI generated commercial for the Canadian telecom giant Bell. Made in collaboration with KnuckleheadTV and amazing ...

Welcome to this week's Oxen moooodel report. We know the AI space moves like crazy. There's a new model, paper, podcast, or hot take every single day. To help y'all keep up, we're ...

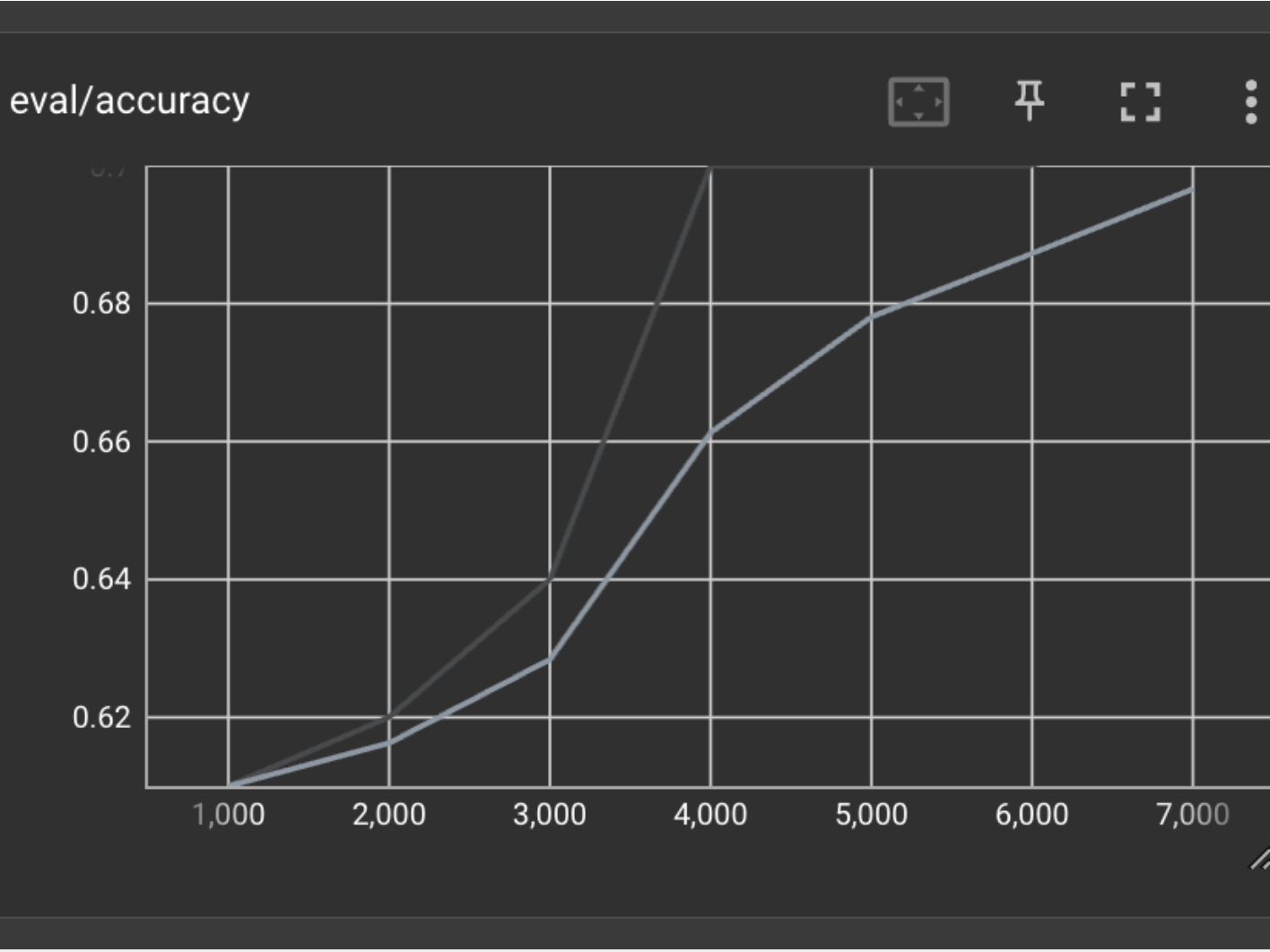
Can a $1 fine-tune beat a state-of-the-art closed-source model? ModelAccuracyTime (98 samples)Cost/RunBase Qwen3-VL-8B54.1%~10 sec$0.003Gemini 3 Flash82.7%2 min 46 sec$0.016FT Q...

LTX-2 is a video generation model, that not only can generation video frames, but audio as well. This model is fully open source, meaning the weights and the code are available for...

Imagine you are shooting a film and you realize that you have the actor wearing the wrong jacket in a scene. Do you bring the whole cast back in to re-shoot? Depending on the actor...

At Oxen.ai, we think a lot about what it takes to run high-quality inference at scale. It’s one thing to produce a handful of impressive results with a cutting-edge image editing m...
Fine-tuning Diffusion Models such as Stable Diffusion, FLUX.1-dev, or Qwen-Image can give you a lot of bang for your buck. Base models may not be trained on a certain concept or st...

Welcome back to Fine-Tuning Friday, where each week we try to put some models to the test and see if fine-tuning an open-source model can outperform whatever state of the art (SOTA...

OpenAI came out with GPT-OSS 120B and 20B in August 2025. The first “Open” LLMs from OpenAI since GPT-2, over six years ago. The idea of fine-tuning a frontier OpenAI model was exc...

Welcome to Fine-Tuning Fridays, where we share our learnings from fine-tuning open source models for real world tasks. We’ll walk you through what models work, what models don’t an...

FLUX.1-dev is one of the most popular open-weight models available today. Developed by Black Forest Labs, it has 12 billion parameters. The goal of this post is to provide a barebo...

Can we fine-tune a small diffusion transformer (DiT) to generate OpenAI-level images by distilling off of OpenAI images? The end goal is to have a small, fast, cheap model that we ...

Welcome to a new series from the Oxen.ai Herd called Fine-Tuning Fridays! Each week we will take an open source model and put it head to head against a closed source foundation mod...

Fine-tuning Fridays is a series from the Oxen.ai Herd where each week we do a deep dive into a model and put it head to head against the competition. We will be giving you practica...
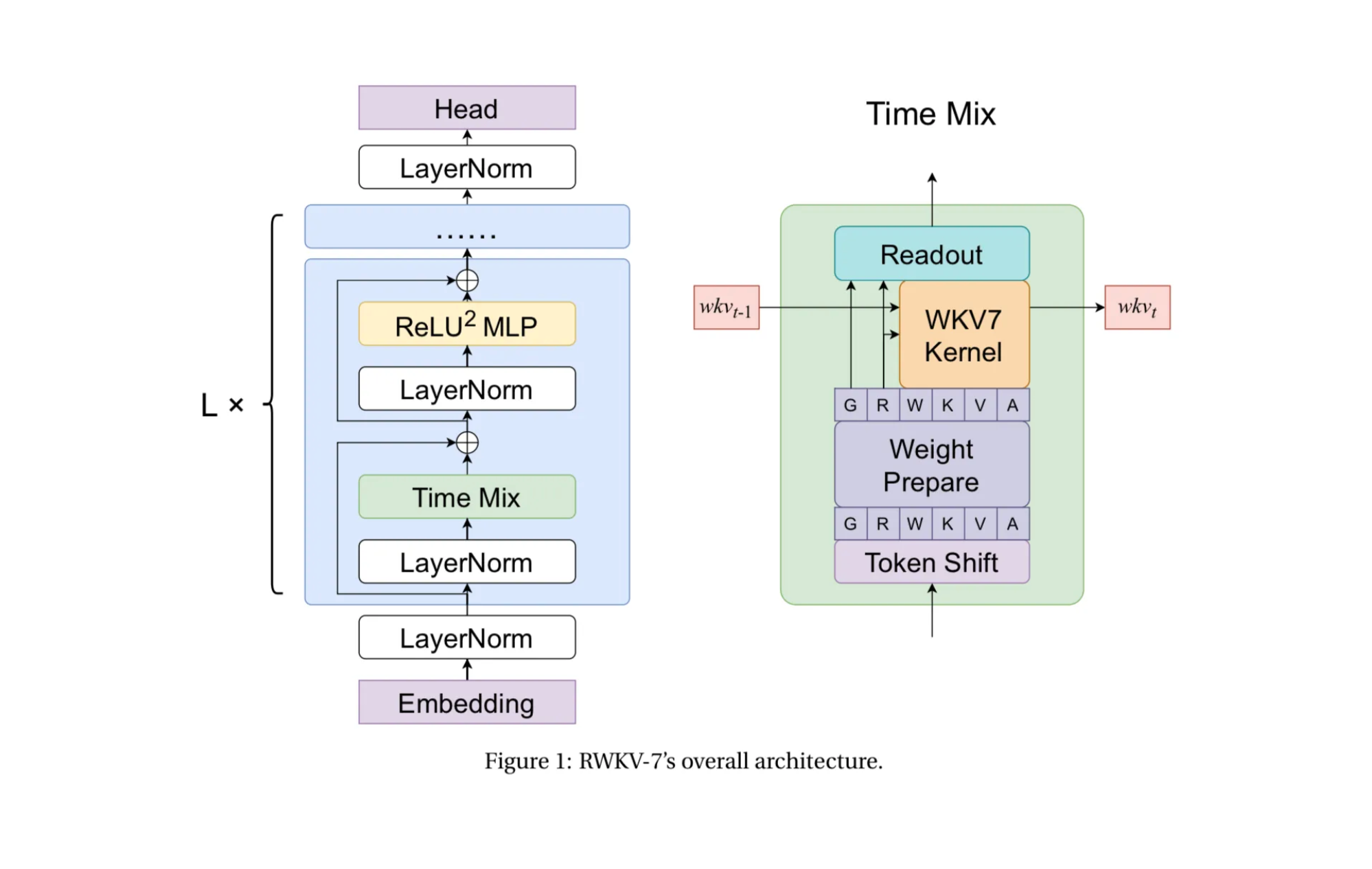
In this special Arxiv Dive, we're joined by Eugene Cheah - author, lead in RWKV org, CEO of Featherless AI, to discuss the development process and key decisions behind these models...
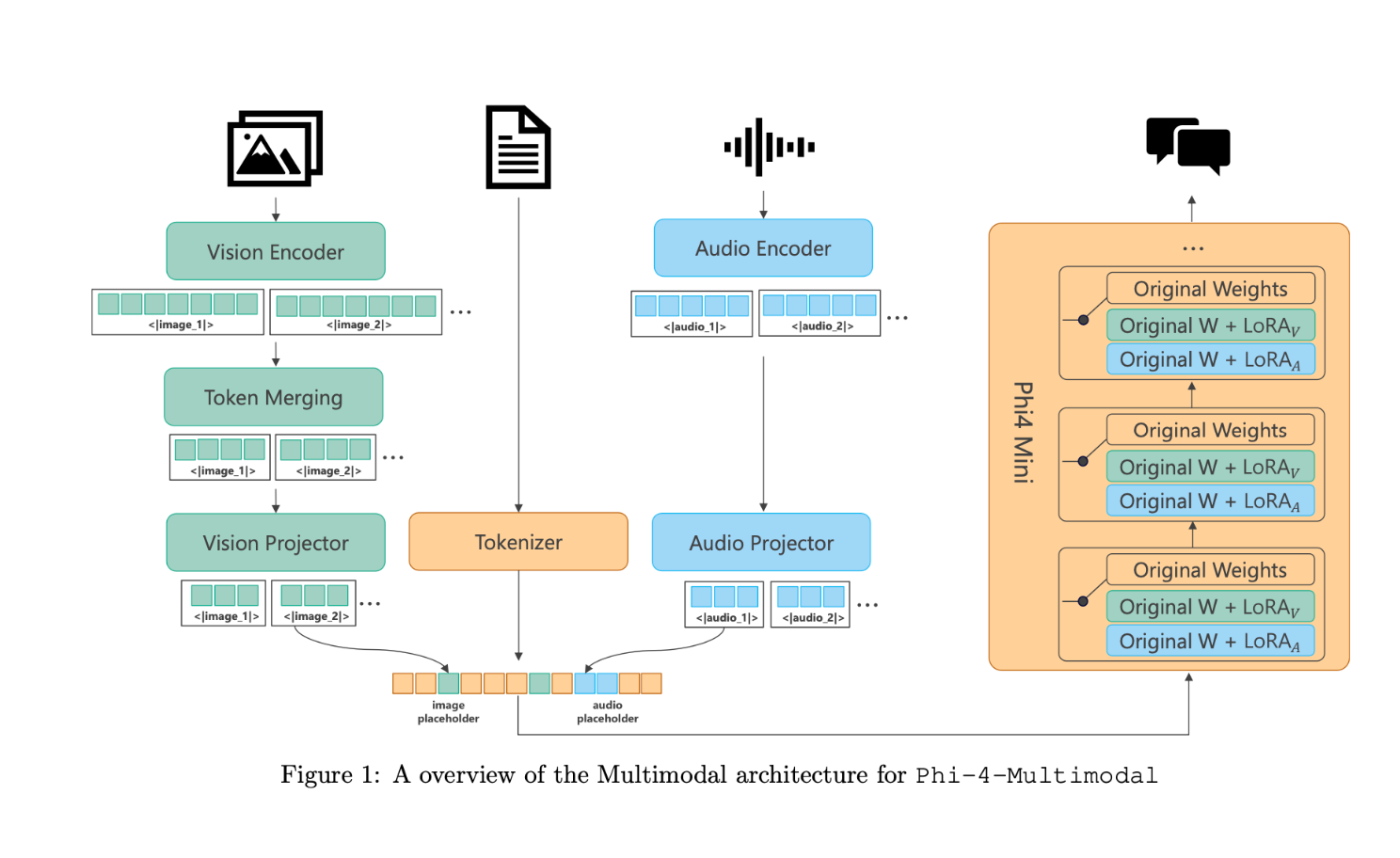
Phi-4 extends the existing Phi model’s capabilities by adding vision and audio all in the same model. This means you can do everything from understand images, generate code, recogn...

Group Relative Policy Optimization (GRPO) has proven to be a useful algorithm for training LLMs to reason and improve on benchmarks. DeepSeek-R1 showed that you can bootstrap a mod...
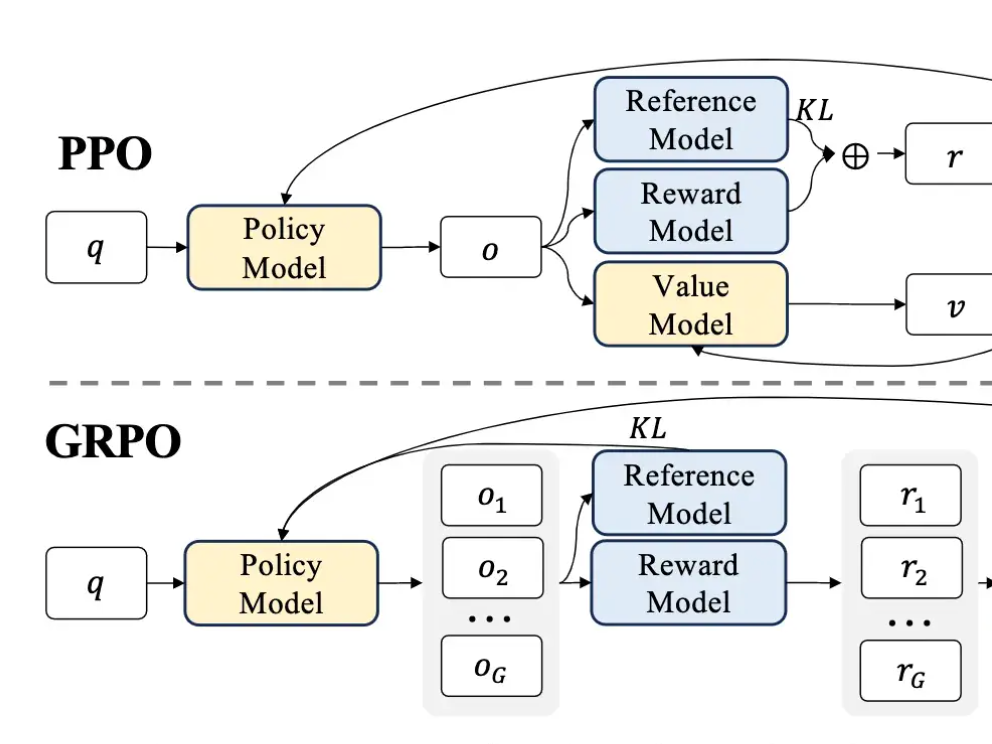
Last week on Arxiv Dives we dug into research behind DeepSeek-R1, and uncovered that one of the techniques they use in the their training pipeline is called Group Relative Policy O...

Since the release of DeepSeek-R1, Group Relative Policy Optimization (GRPO) has become the talk of the town for Reinforcement Learning in Large Language Models due to its effective...
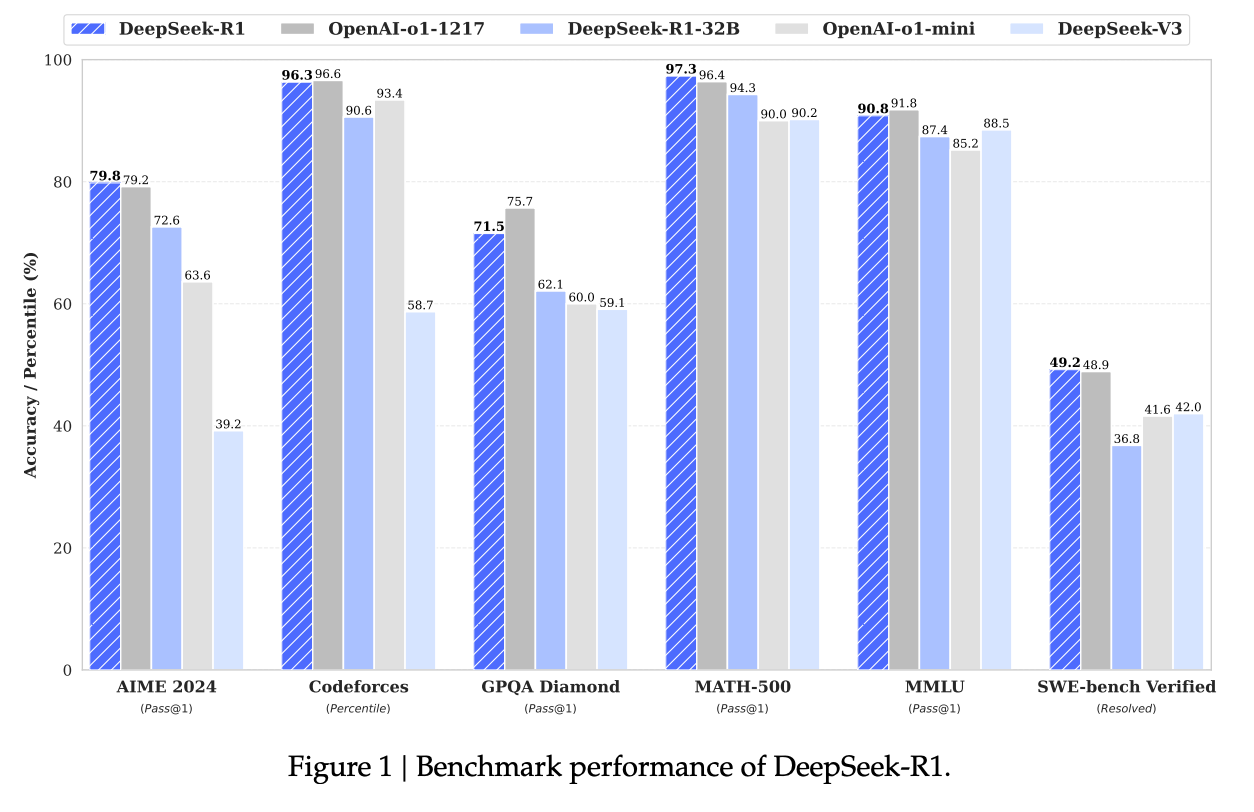
In January 2025, DeepSeek took a shot directly at OpenAI by releasing a suite of models that “Rival OpenAI’s o1.” From their website: In the spirit of Arxiv Dives we are going to...

DeepSeek-R1 is a big step forward in the open model ecosystem for AI with their latest model competing with OpenAI's o1 on a variety of metrics. There is a lot of hype, and a lot o...

Today we released oxen v0.25.0 🎉 which comes with a few performance optimizations, including how we traverse the Merkle Tree to find files and folders. The main improvement is how...

In this post we peel back some of the layers of Oxen.ai’s Merkle Tree and show how we make it suitable for projects with large directories. If you are unfamiliar with Merkle Trees ...

Intro Merkle Trees are important data structures for ensuring integrity, deduplication, and verification of data at scale. They are used heavily in tools such as Git, Bitcoin, IPF...

RAGAS is an evaluation framework for Retrieval Augmented Generation (RAG). A paper released by Exploding Gradients, AMPLYFI, and CardiffNLP. RAGAS gives us a suite of metrics that ...
![The Best AI Data Version Control Tools [2025]](https://storage.ghost.io/c/bc/24/bc2443b9-eb39-4b32-b473-8eb4576181dd/content/images/2024/12/ox-carrying-data.jpg)
Data is often seen as static. It's common to just dump your data into S3 buckets in tarballs or upload to Hugging Face and leave it at that. Yet nowadays, data needs to evolve and ...

Welcome to the last arXiv Dive of 2024! Every other week we have been diving into interesting research papers in AI/ML. In this blog we’ll be diving into Open Coder, a paper and co...
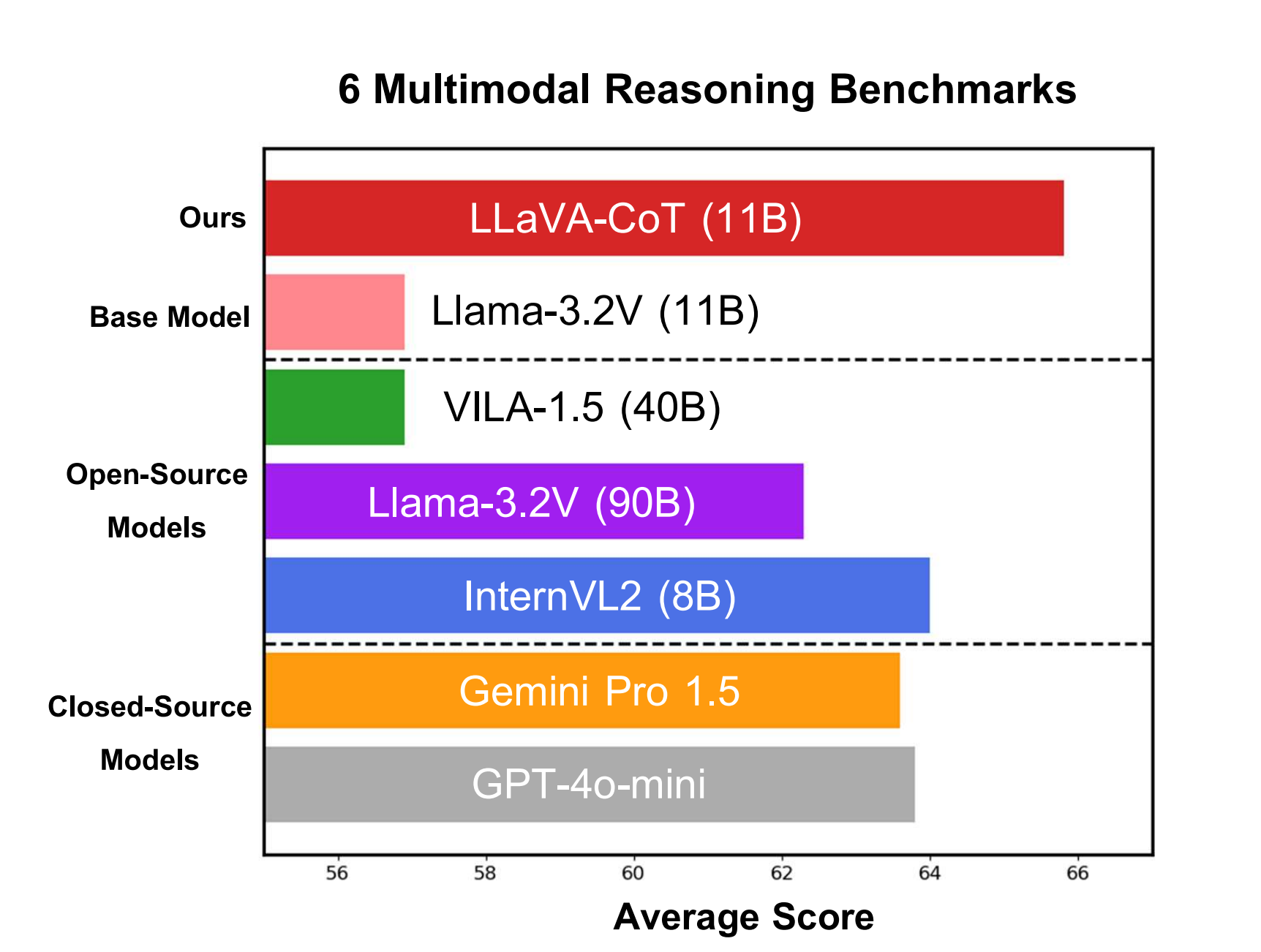
When it comes to large language models, it is still the early innings. Many of them still hallucinate, fail to follow instructions, or generally don’t work. The only way to combat ...
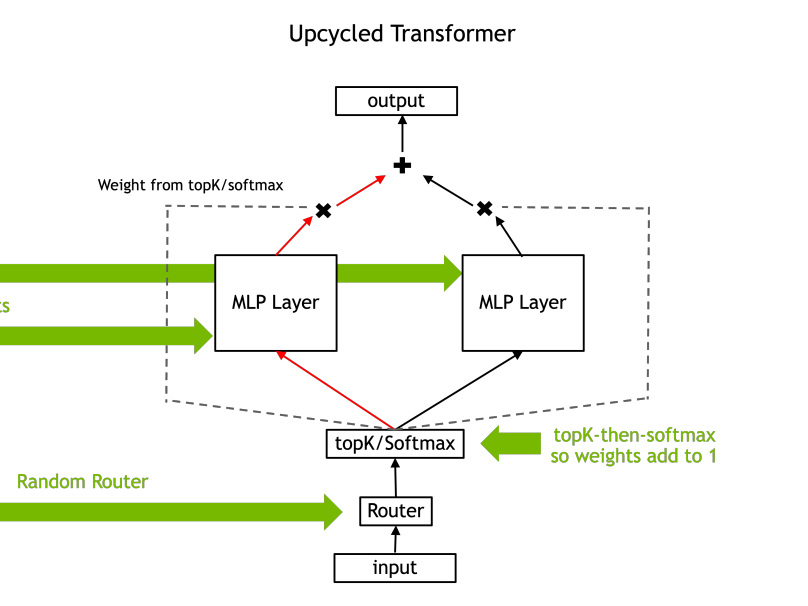
In this Arxiv Dive, Nvidia researcher, Ethan He, presents his co-authored work Upcycling LLMs in Mixture of Experts (MoE). He goes into what a MoE is, the challenges behind upcycli...
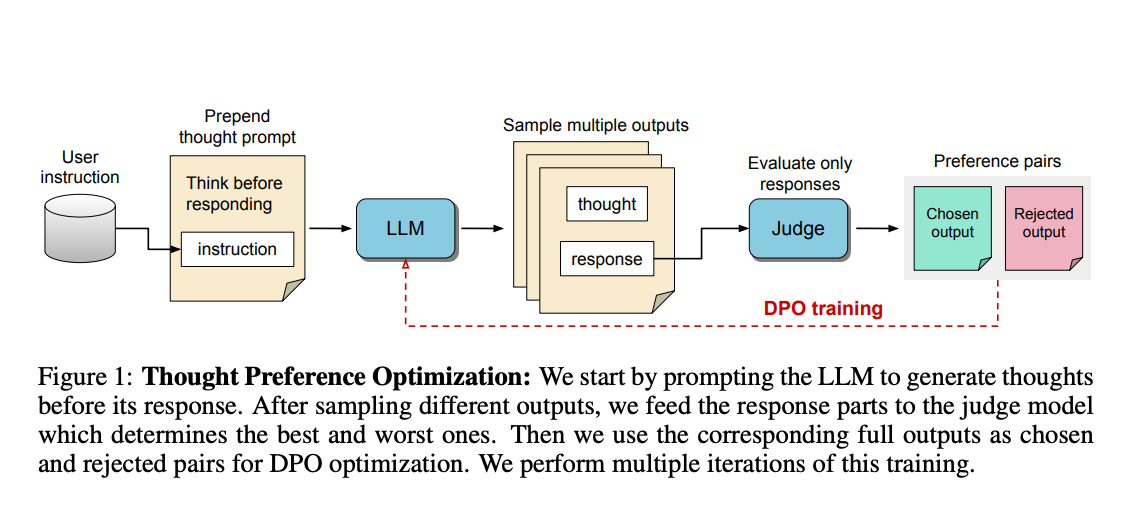
The release of OpenAI-O1 has motivated a lot of people to think deeply about…thoughts 💭. Thinking before you speak is a skill that some people have better than others 😉, but a sk...
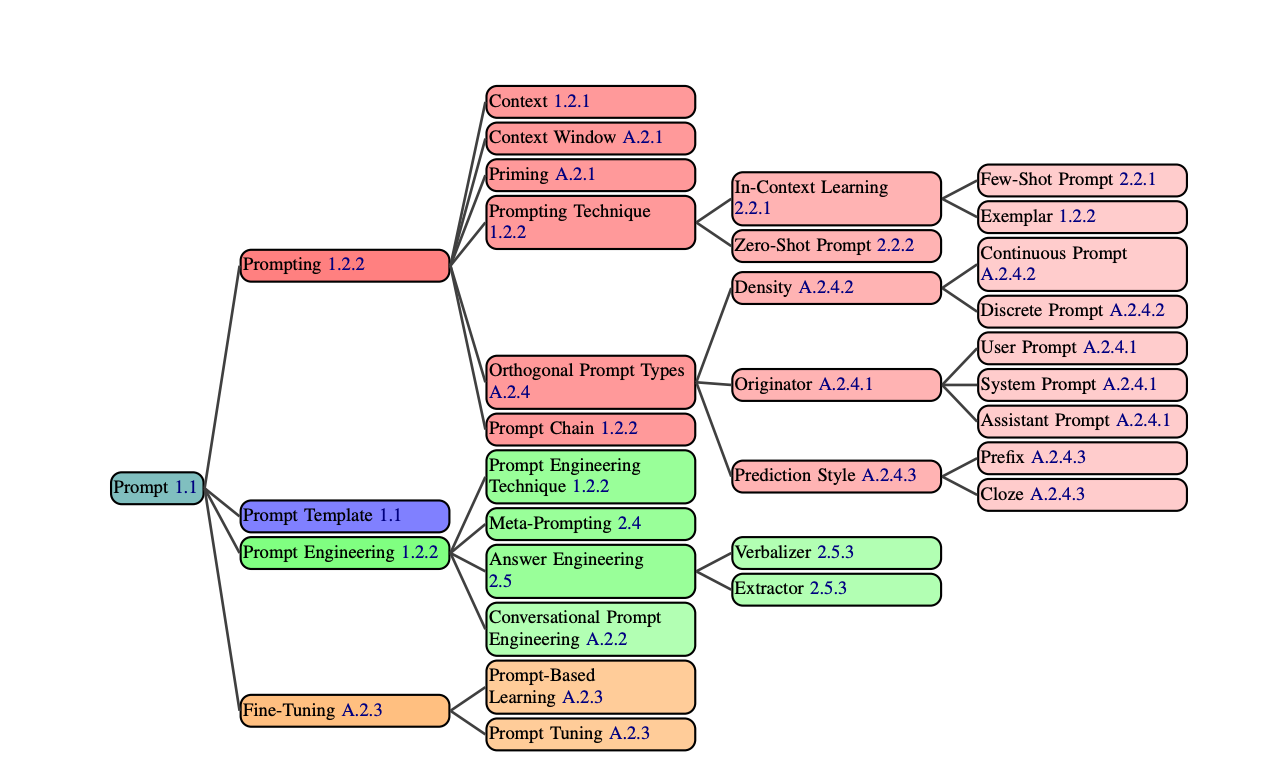
In the last blog, we went over prompting techniques 1-3 of The Prompt Report. This arXiv Dive, we were lucky to have the authors of the paper join us to go through some of the more...
For this blog we are switching it up a bit. In past Arxiv Dives, we have gone deep into the underlying model architectures and techniques that make large language models and other ...

Flux made quite a splash with its release on August 1st, 2024 as the new state of the art generative image model outperforming SDXL, SDXL-Turbo, Pixart, and DALL-E. While the model...
![How Well Can Llama 3.1 8B Detect Political Spam? [4/4]](https://storage.ghost.io/c/bc/24/bc2443b9-eb39-4b32-b473-8eb4576181dd/content/images/2024/09/DALL-E-2024-09-13-20.39.28---A-stylized--futuristic-llama-holding-an-American-flag-in-its-mouth--with-sharp--bold-lines-and-glowing--laser-like-eyes.-The-llama-has-a-sleek-fur-tex-1.webp)
It only took about 11 minutes to fine-tuned Llama 3.1 8B on our political spam synthetic dataset using ReFT. While this is extremely fast, beating out our previous record of 14 min...

![Fine-Tuning Llama 3.1 8B in Under 12 Minutes [3/4]](https://storage.ghost.io/c/bc/24/bc2443b9-eb39-4b32-b473-8eb4576181dd/content/images/2024/09/DALL-E-2024-09-03-11.22.45---A-stylized-llama-with-vibrant-red-and-blue-fur--shooting-laser-beams-from-its-eyes.-The-llama-s-eyes-glow-intensely--with-one-eye-emitting-a-red-laser-copy.jpg)
Meta has recently released Llama 3.1, including their 405 billion parameter model which is the most capable open model to date and the first open model on the same level as GPT 4. ...

Llama 3.1 is a set of Open Weights Foundation models released by Meta, which marks the first time an open model has caught up to GPT-4, Anthropic, or other closed models in the eco...
![How to De-duplicate and Clean Synthetic Data [2/4]](https://storage.ghost.io/c/bc/24/bc2443b9-eb39-4b32-b473-8eb4576181dd/content/images/2024/08/blog-copy.jpg)
Synthetic data has shown promising results for training and fine tuning large models, such as Llama 3.1 and the models behind Apple Intelligence, and to produce datasets from minim...
![Create Your Own Synthetic Data With Only 5 Political Spam Texts [1/4]](https://storage.ghost.io/c/bc/24/bc2443b9-eb39-4b32-b473-8eb4576181dd/content/images/2024/08/political_spam.png)
With the 2024 elections coming up, spam and political texts are more prevalent than ever as political campaigns increasingly turn towards texting potential voters. Over 15 billion ...
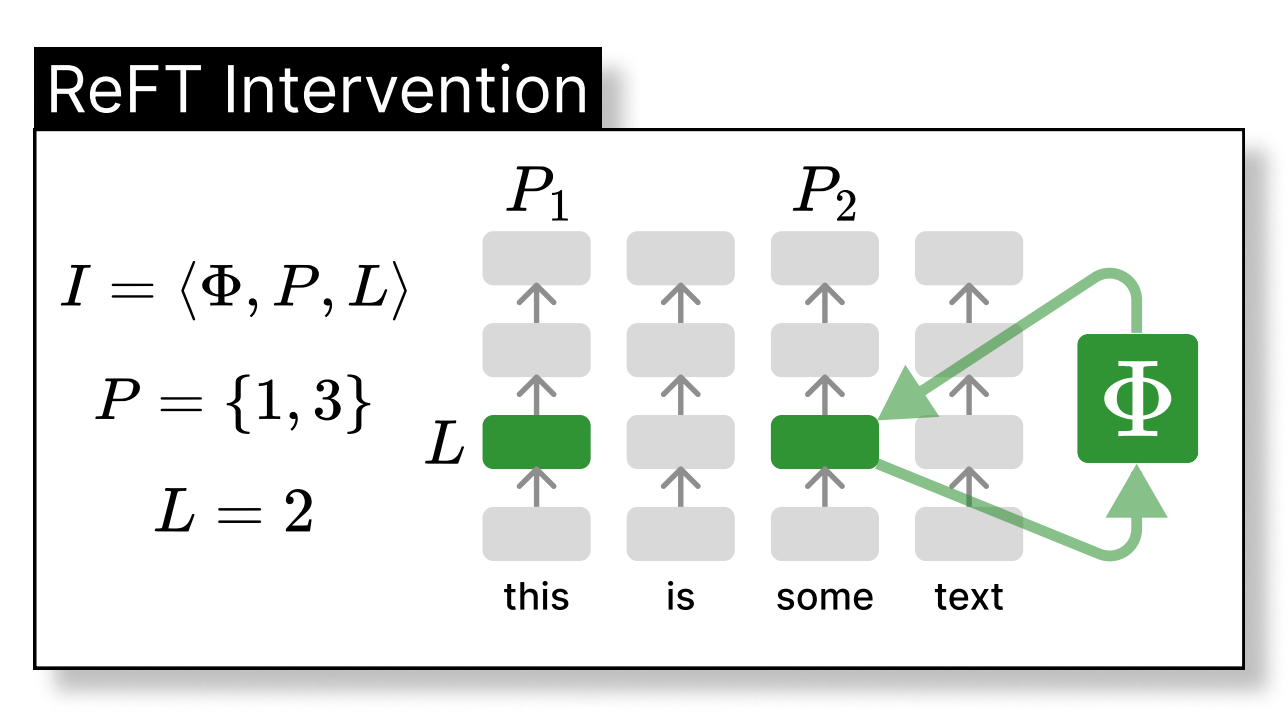
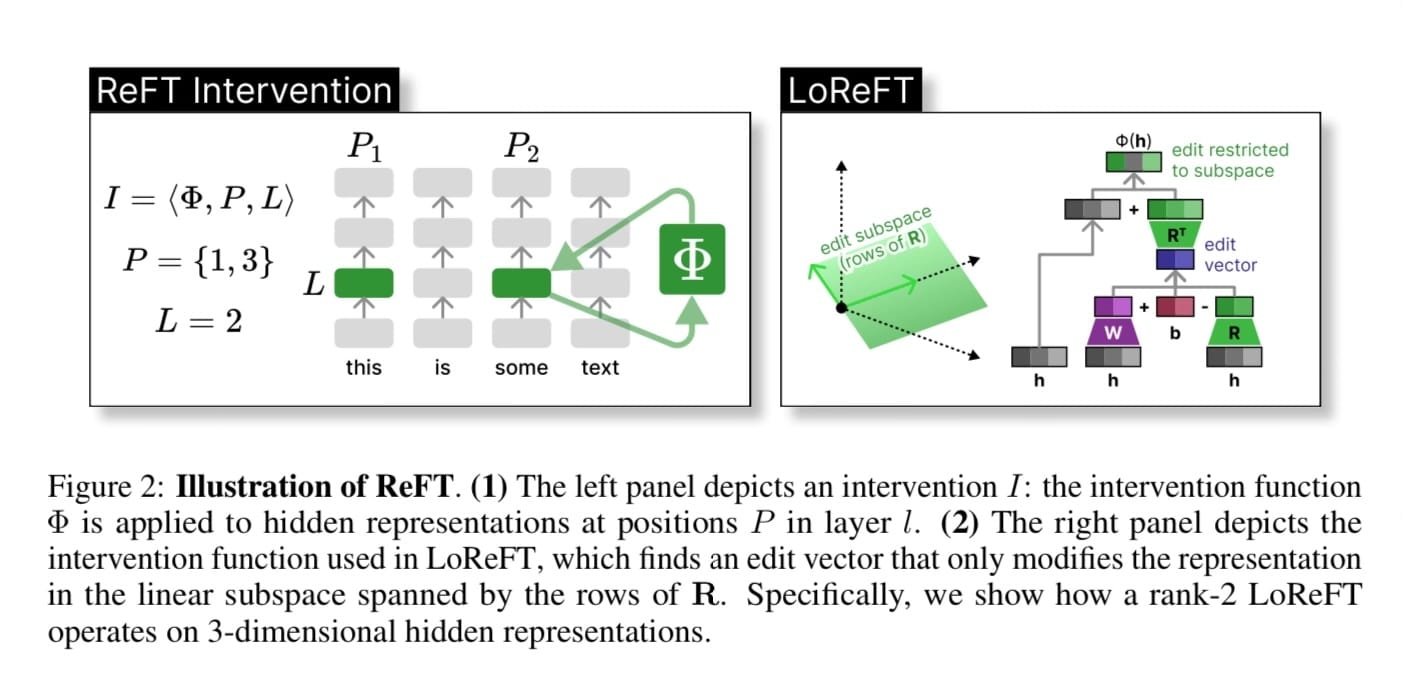
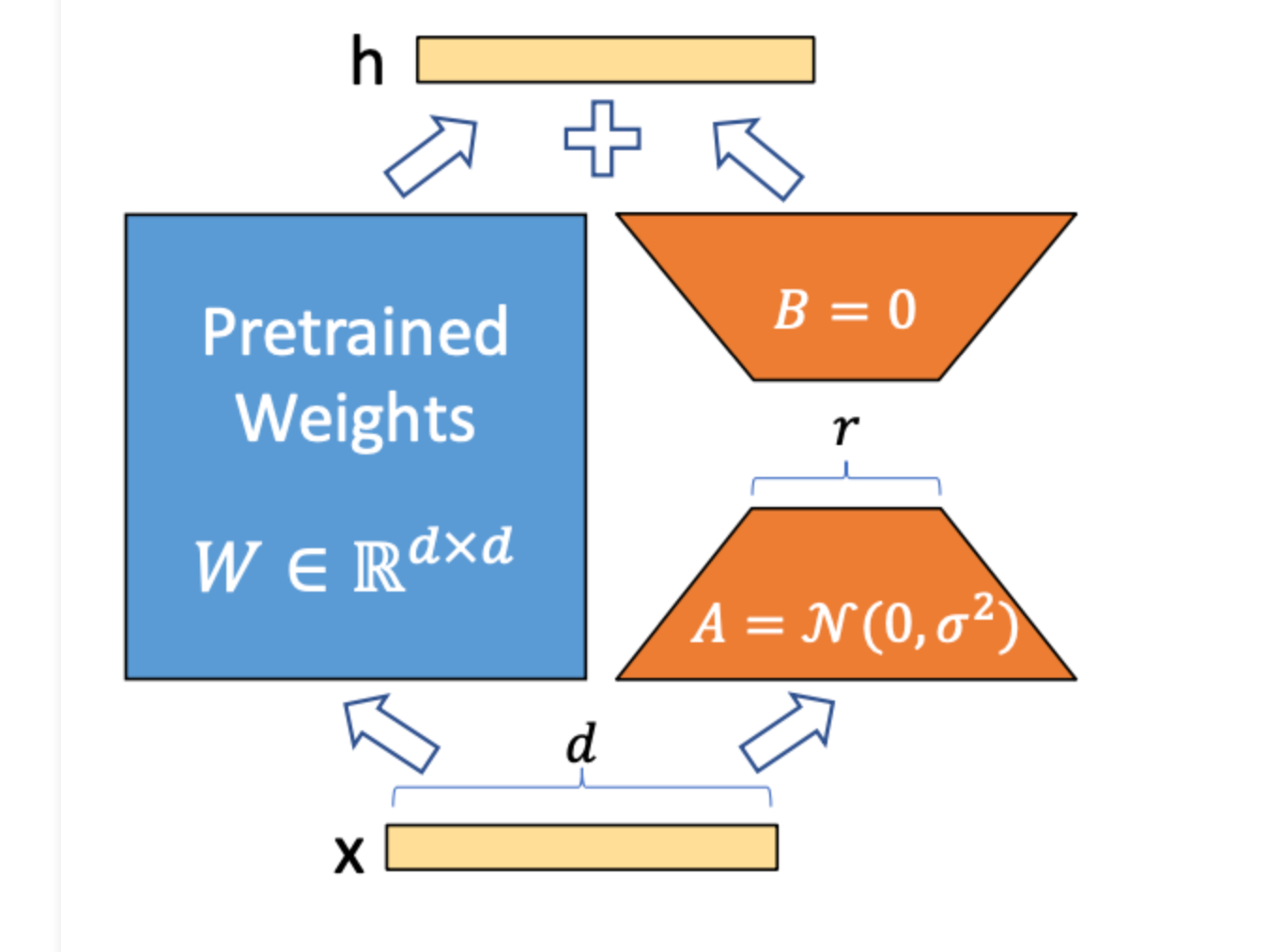
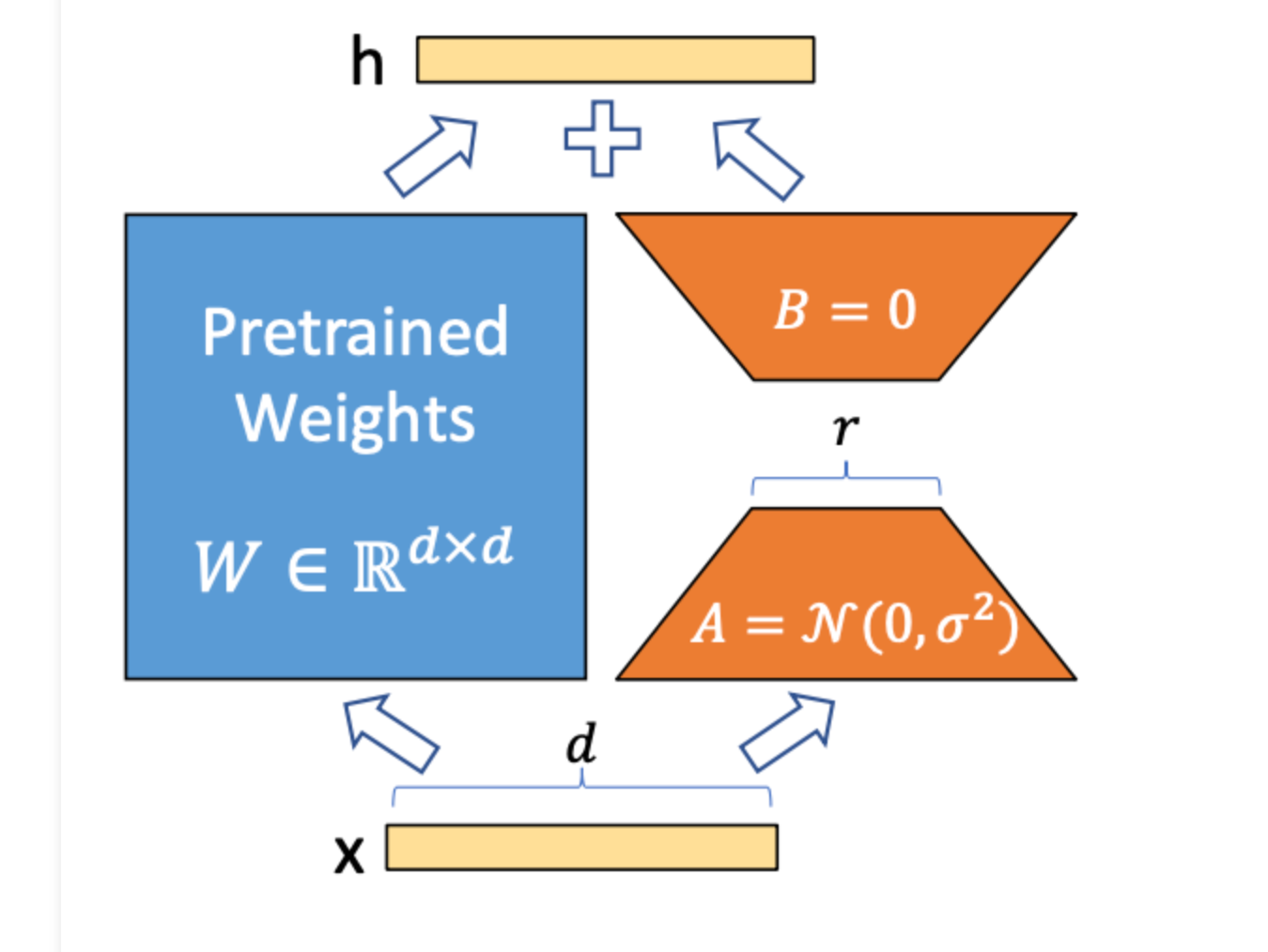
If you have been fine-tuning models recently, you have most likely used LoRA. While LoRA has been the dominant PEFT technique for a long time thanks to its efficiency and effective...
ArXiv Dives is a series of live meetups that take place on Fridays with the Oxen.ai community. We believe that it is not only important to read the papers, but dive into the code t...

Modeling sequences with infinite context length is one of the dreams of Large Language models. Some LLMs such as Transformers suffer from quadratic computational complexity, making...

The ability to interpret and steer large language models is an important topic as they become more and more a part of our daily lives. As the leader in AI safety, Anthropic takes o...

Diffusion Transformers have been gaining a lot of steam since OpenAI's demo of Sora back in March. The problem, when we think of training text-to-image models, we usually think mil...

Large Language Models have shown very good ability to generalize within a distribution, and frontier models have shown incredible flexibility under prompting. Now that there is so...
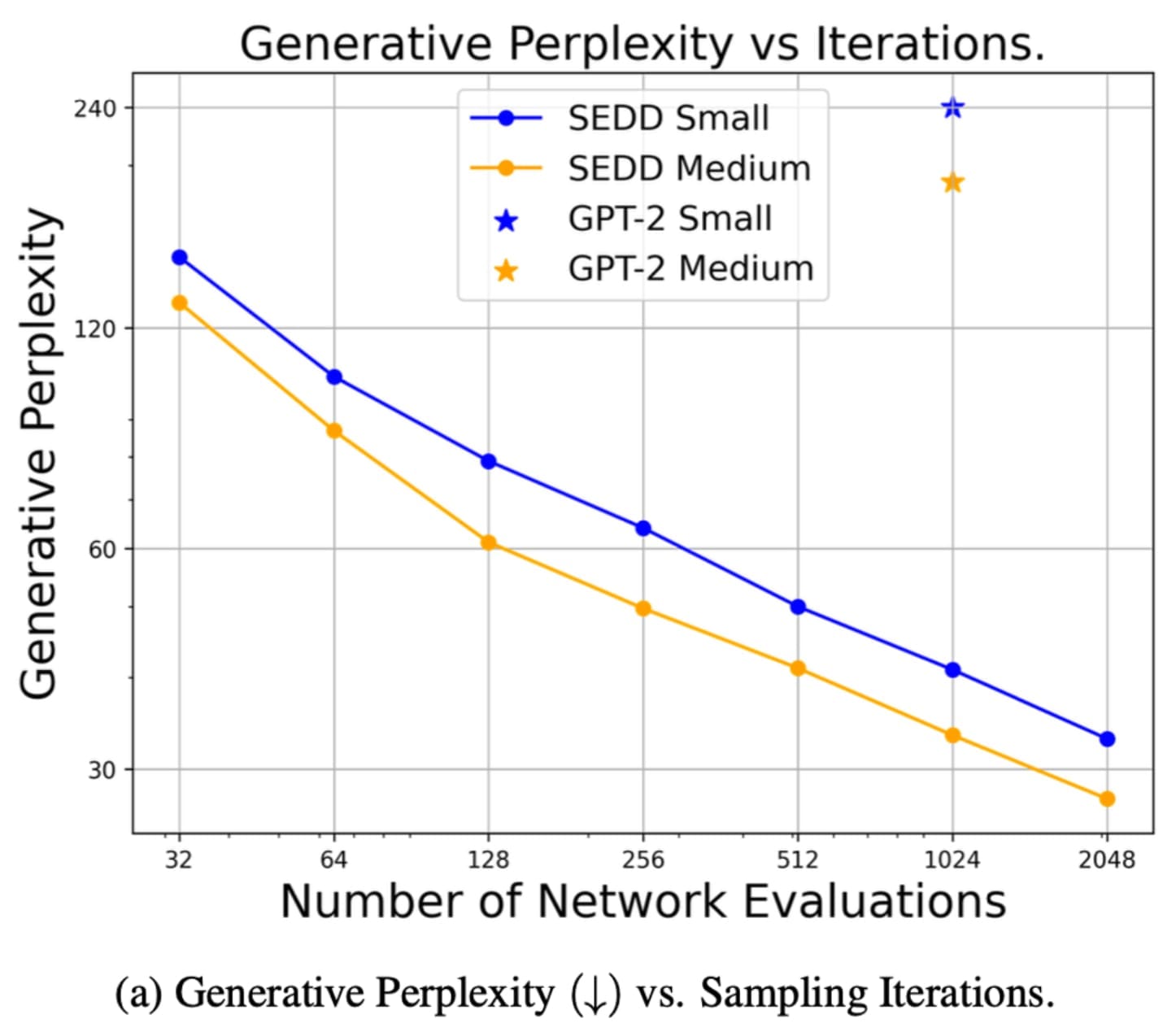
This is part two of a series on Diffusion for Text with Score Entropy Discrete Diffusion (SEDD) models. Today we will be diving into the code for diffusion models for text, and see...

Diffusion models have been popular for computer vision tasks. Recently models such as Sora show how you can apply Diffusion + Transformers to generate state of the art videos with ...
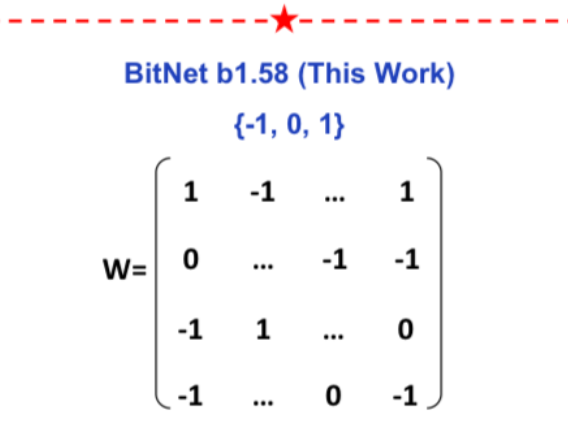
This paper presents BitNet b1.58 where every weight in a Transformer can be represented as a {-1, 0, 1} instead of a floating point number. The model matches full precision transfo...
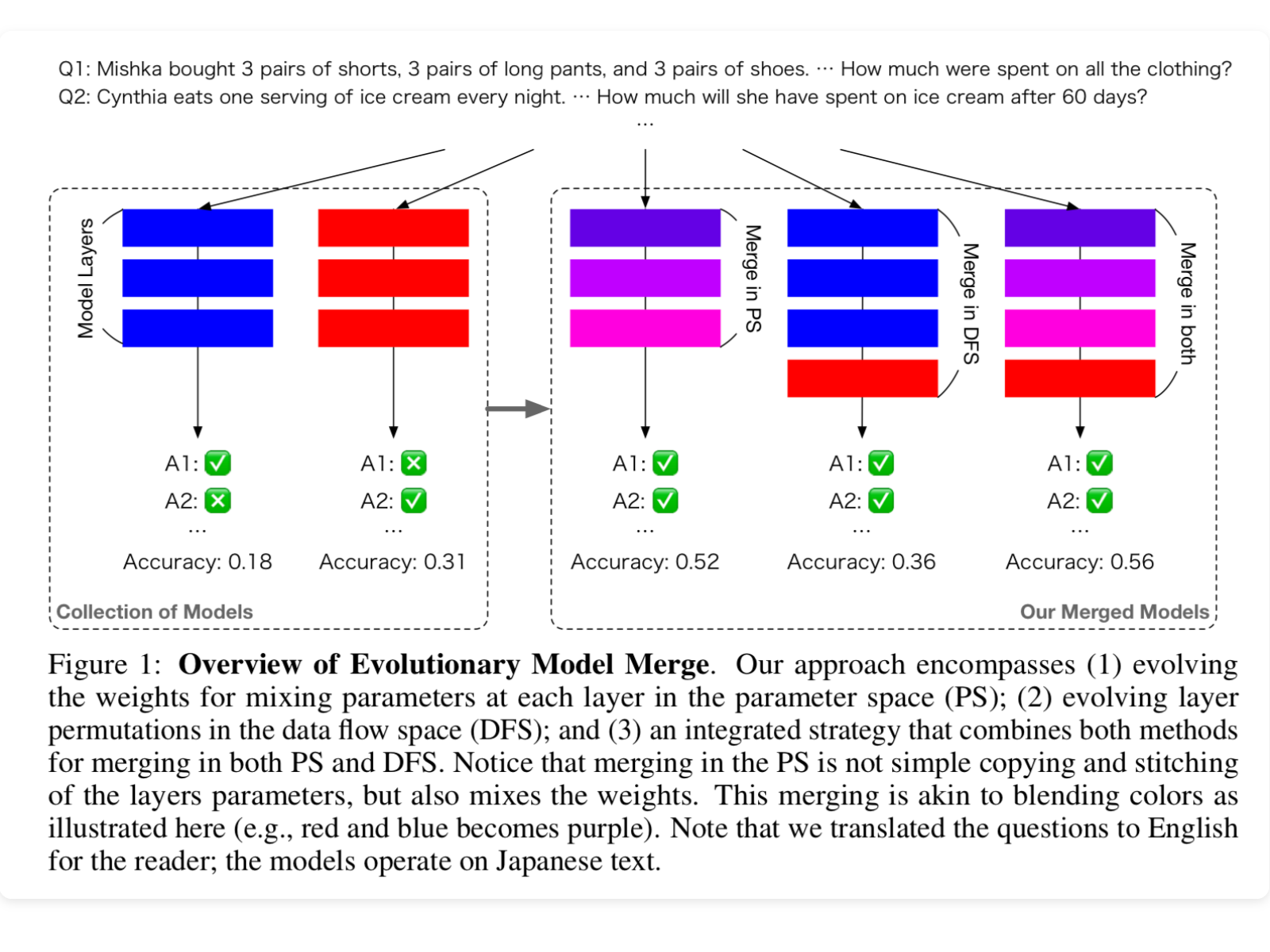
Today, we’re diving into a fun paper by the team at Sakana.ai called “Evolutionary Optimization of Model Merging Recipes”. The high level idea is that we have so many open weights ...
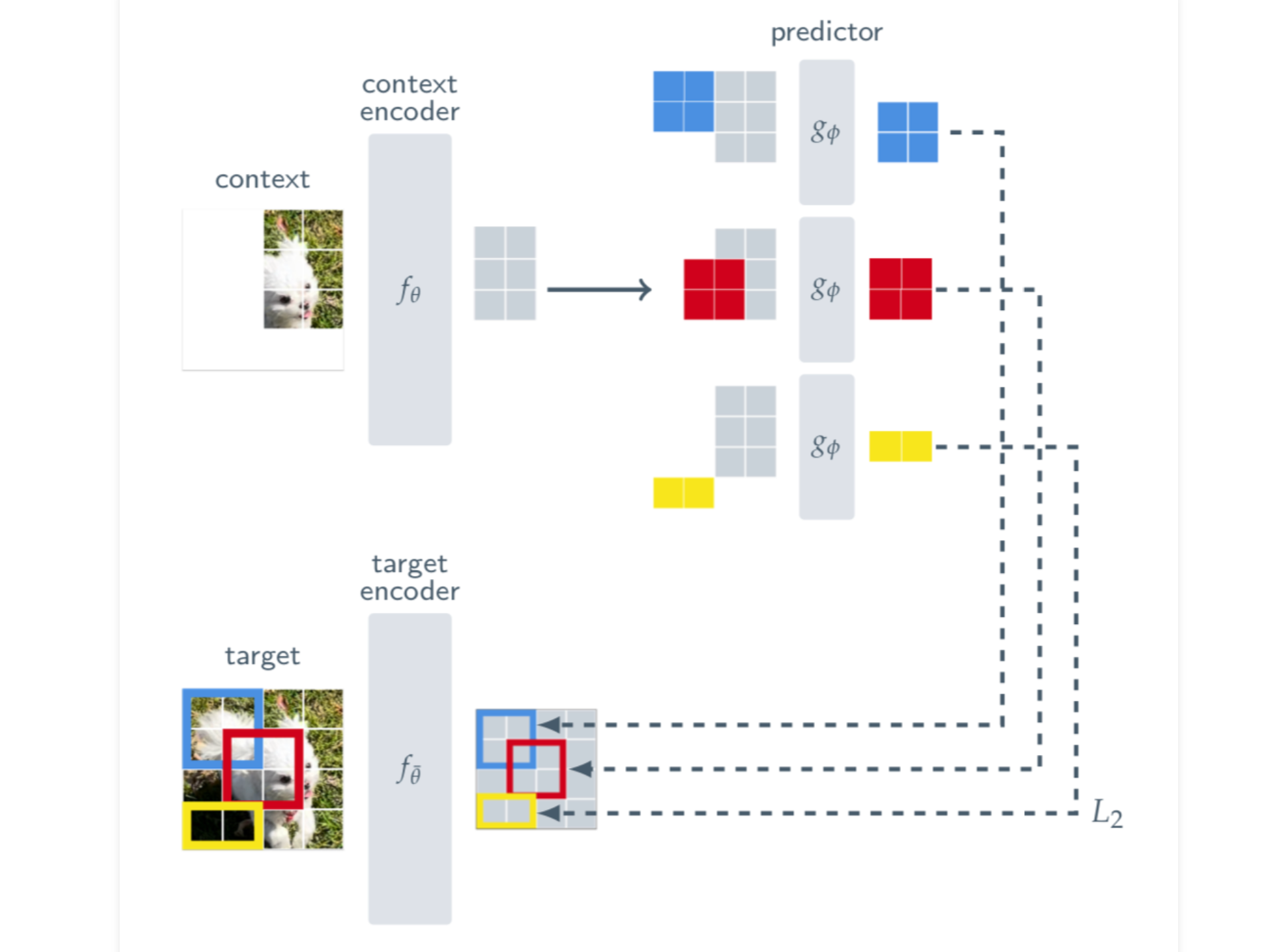
Today, we’re diving into the I-JEPA paper. JEPA stands for Joint-Embedding Predictive Architecture and if you have been following Yann LeCunn, is a technique he has been hyping up ...
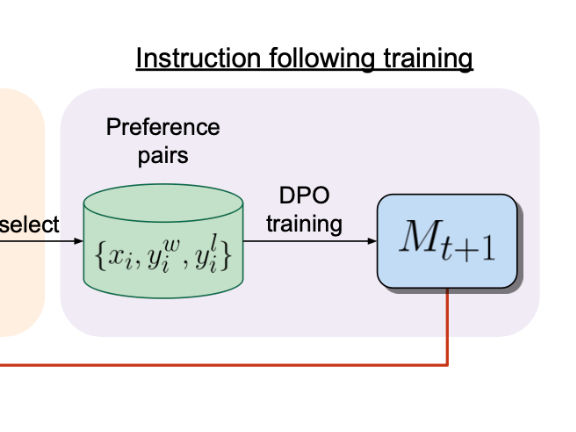
About a month ago we went over the "Self-Rewarding Language Models" paper by the team at Meta AI with the Oxen.ai Community. The paper felt very approachable and reproducible, so w...
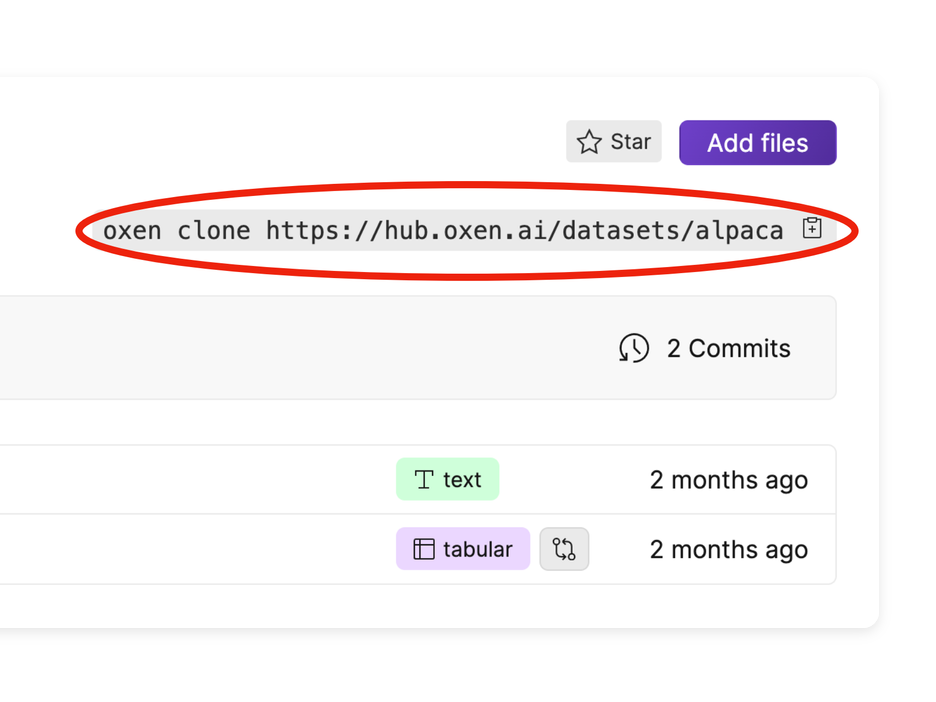
Oxen.ai makes it quick and easy to download any version of your data wherever and whenever you need it. When we say quick, we mean raw speed. Oxen chunks and transfers data faster...
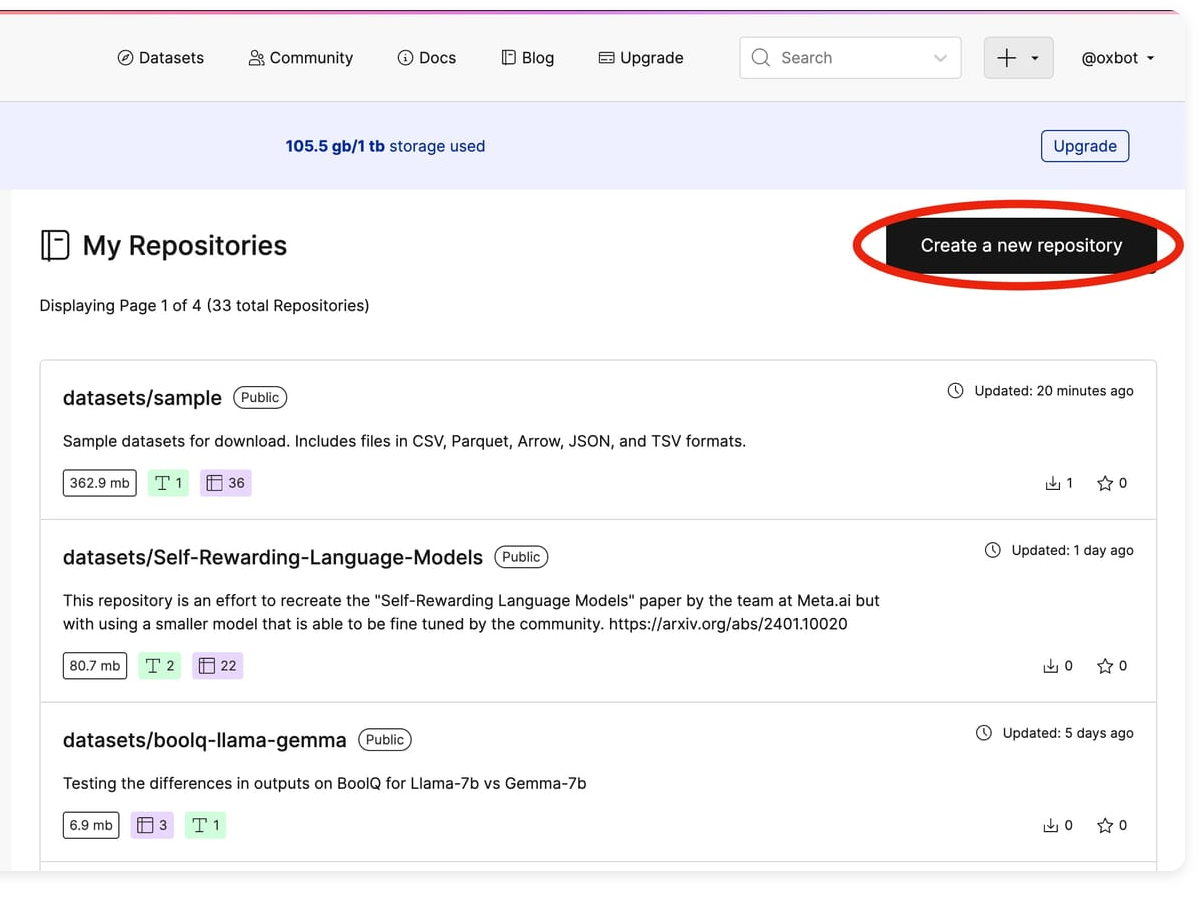
Oxen.ai makes it quick and easy to upload your datasets, keep track of every version and share them with your team or the world. Oxen datasets can be as small as a single csv or as...

Diffusion transformers achieve state-of-the-art quality generating images by replacing the commonly used U-Net backbone with a transformer that operates on latent patches. They rec...
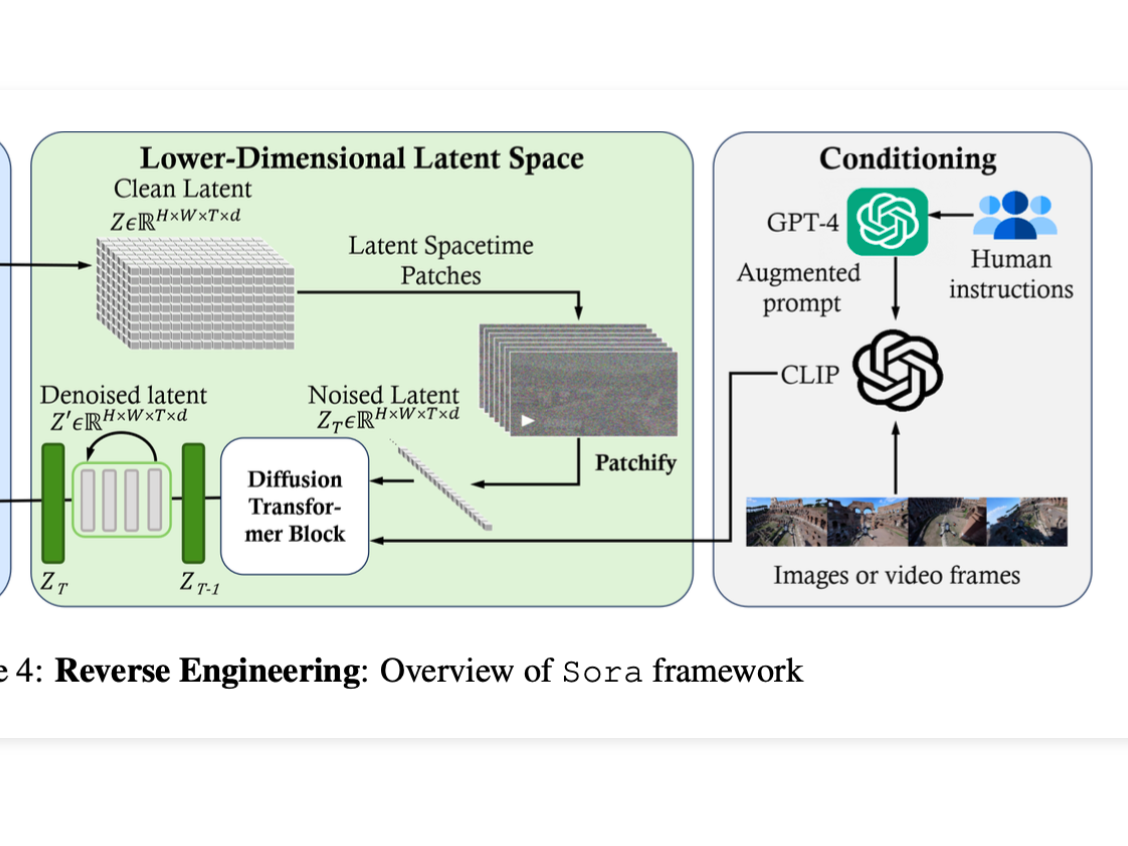
This post is an effort to put together a reading list for our Friday paper club called ArXiv Dives. Since there has not been an official paper released yet for Sora, the goal is fo...
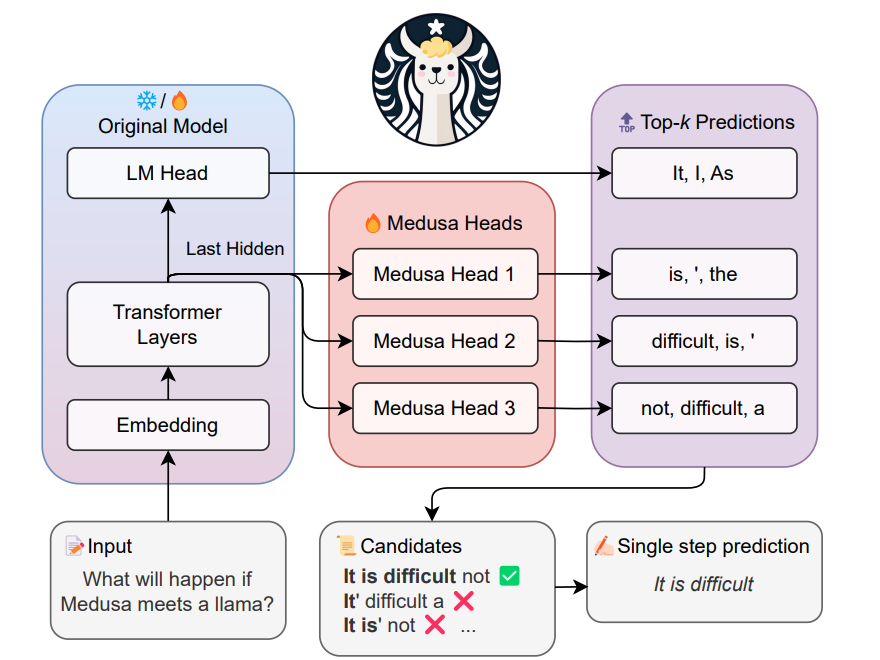
Abstract In this paper, they present MEDUSA, an efficient method that augments LLM inference by adding extra decoding heads to predict multiple subsequent tokens in parallel. The ...
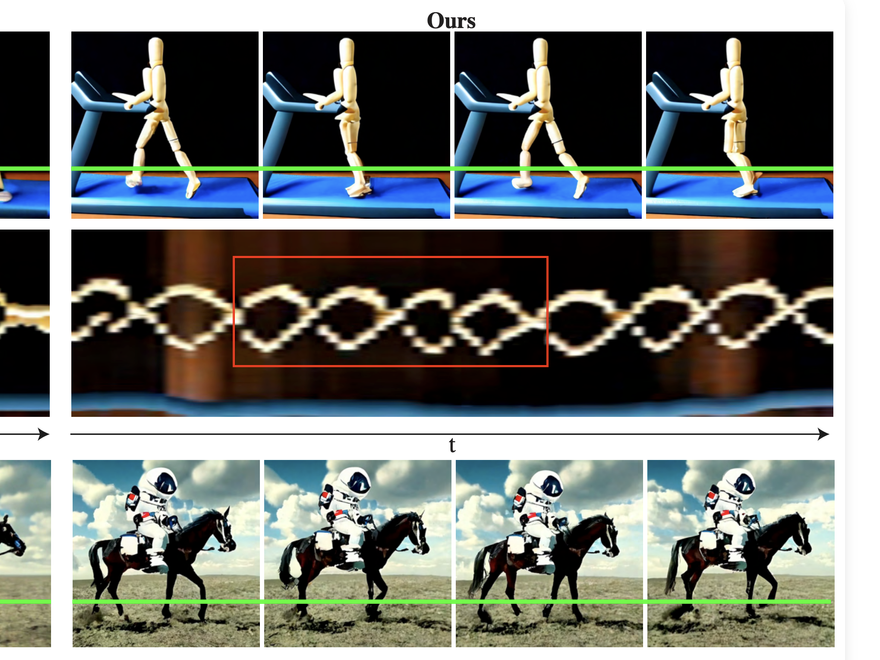
This paper introduces Lumiere – a text-to-video diffusion model designed for synthesizing videos that portray realistic, diverse and coherent motion – a pivotal challenge in video ...

This paper presents Depth Anything, a highly practical solution for robust monocular depth estimation. Depth estimation traditionally requires extra hardware and algorithms such as...
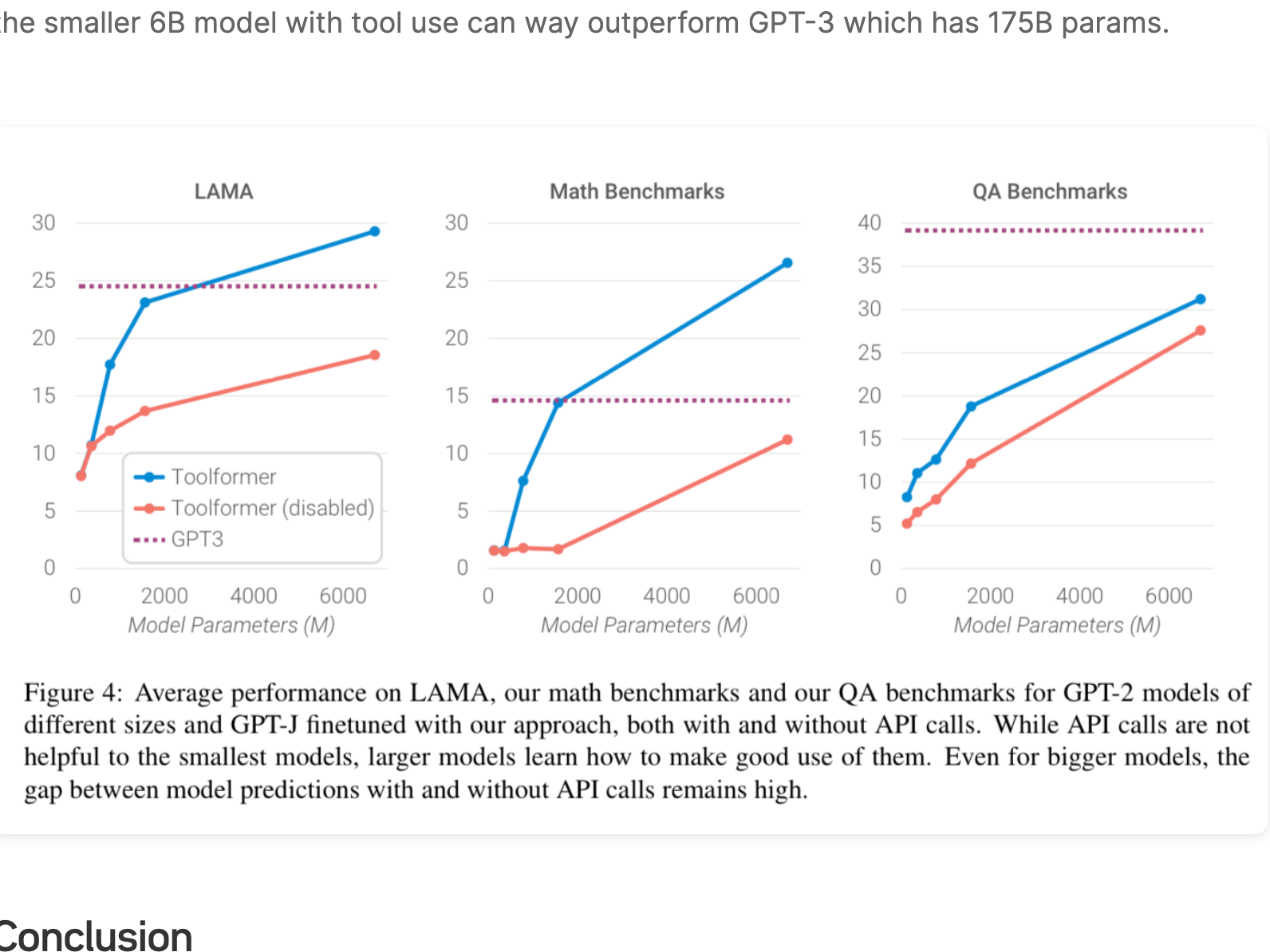
Large Language Models (LLMs) show remarkable capabilities to solve new tasks from a few textual instructions, but they also paradoxically struggle with basic functionality such as ...
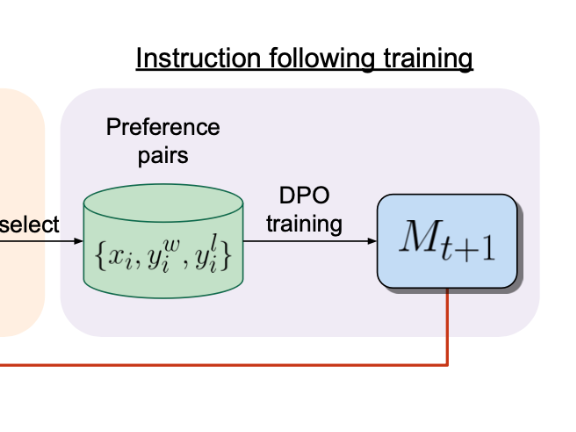
The goal of this paper is to see if we can create a self-improving feedback loop to achieve “superhuman agents”. Current language models are bottlenecked by labeled data from human...
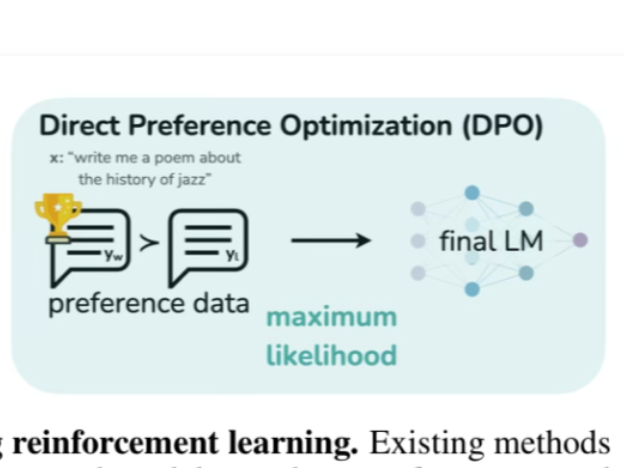
This paper provides a simple and stable alternative to RLHF for aligning Large Language Models with human preferences called "Direct Preference Optimization" (DPO). They reformulat...
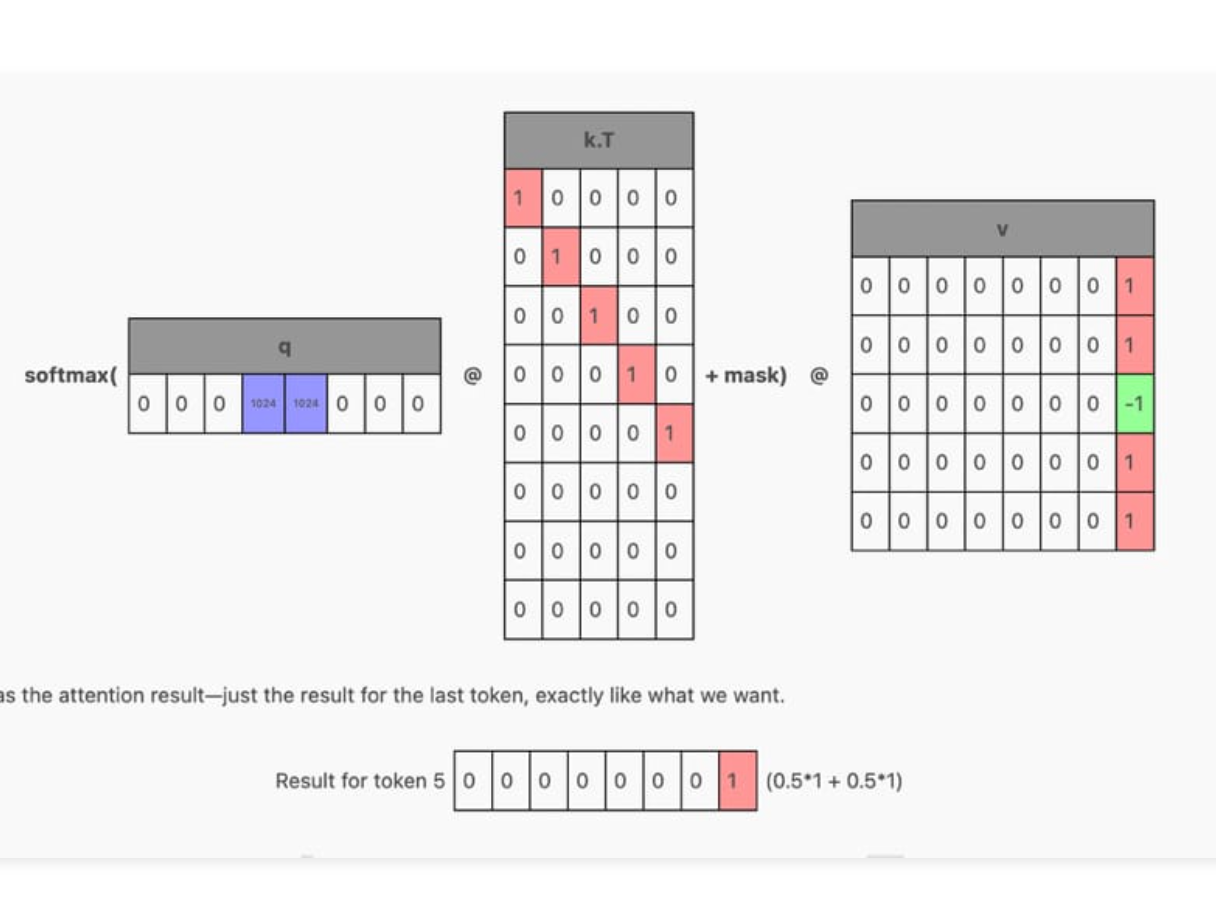
This paper introduces the concept of an Attention Sink which helps Large Language Models (LLMs) maintain the coherence of text into the millions of tokens while also maintaining a ...

Mixtral 8x7B is an open source mixture of experts large language model released by the team at Mistral.ai that outperforms Llama-2 70B and GPT-3.5 on a variety natural language und...

What is LLaVA? LLaVA is a Multi-Modal model that connects a Vision Encoder and an LLM for general purpose visual and language understanding. Paper: https://arxiv.org/abs/2304.084...
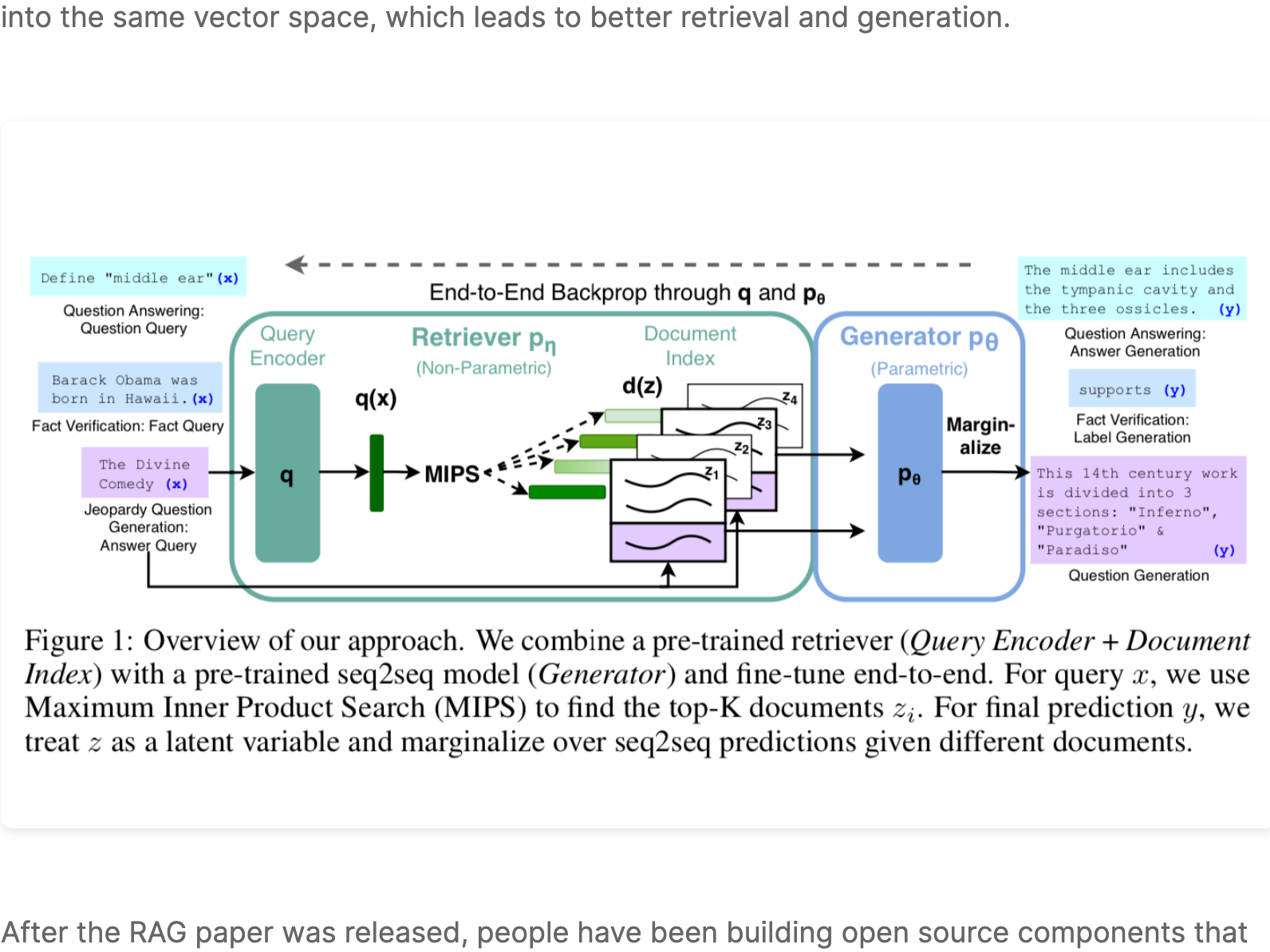
RAG was introduced by the Facebook AI Research (FAIR) team in May of 2020 as an end-to-end way to include document search into a sequence-to-sequence neural network architecture. ...
What is Mistral 7B? Mistral 7B is an open weights large language model by Mistral.ai that was build for performance and efficiency. It outshines models that are twice it's size, i...

What is Mamba 🐍? There is a lot of hype about Mamba being a fast alternative to the Transformer architecture. The paper released in December of 2023 claims 5x faster throughput w...

What is Mamba 🐍? Mamba at it's core is a recurrent neural network architecture, that outperforms Transformers with faster inference and improved handling of long sequences of len...
Welcome to Practical ML Dives, a series spin off of Arxiv Dives. In Arxiv Dives, we cover state of the art research papers, and dive into the gnitty gritty details of how AI model...
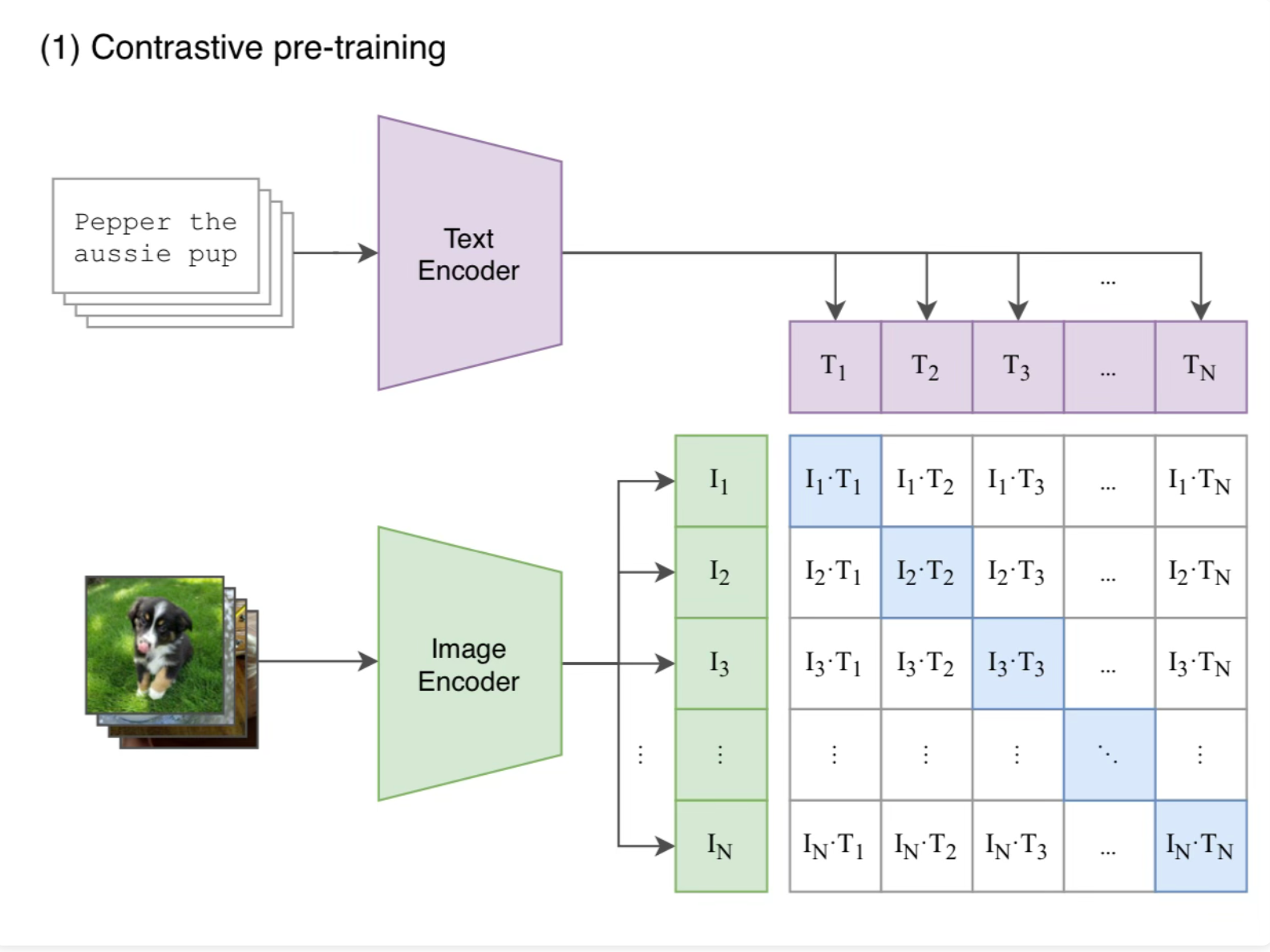
CLIP explores the efficacy of learning image representations from scratch with 400 million image-text pairs, showcasing zero-shot transfer capabilities across diverse computer visi...

Training data is typically the most valuable part of any machine learning project. As we converge on model architectures like the transformer that perform well on many tasks, it is...

At Oxen.ai we value high quality datasets. We have many years of experience training and evaluating models, and have seen many interesting data formats. Interesting is something we...
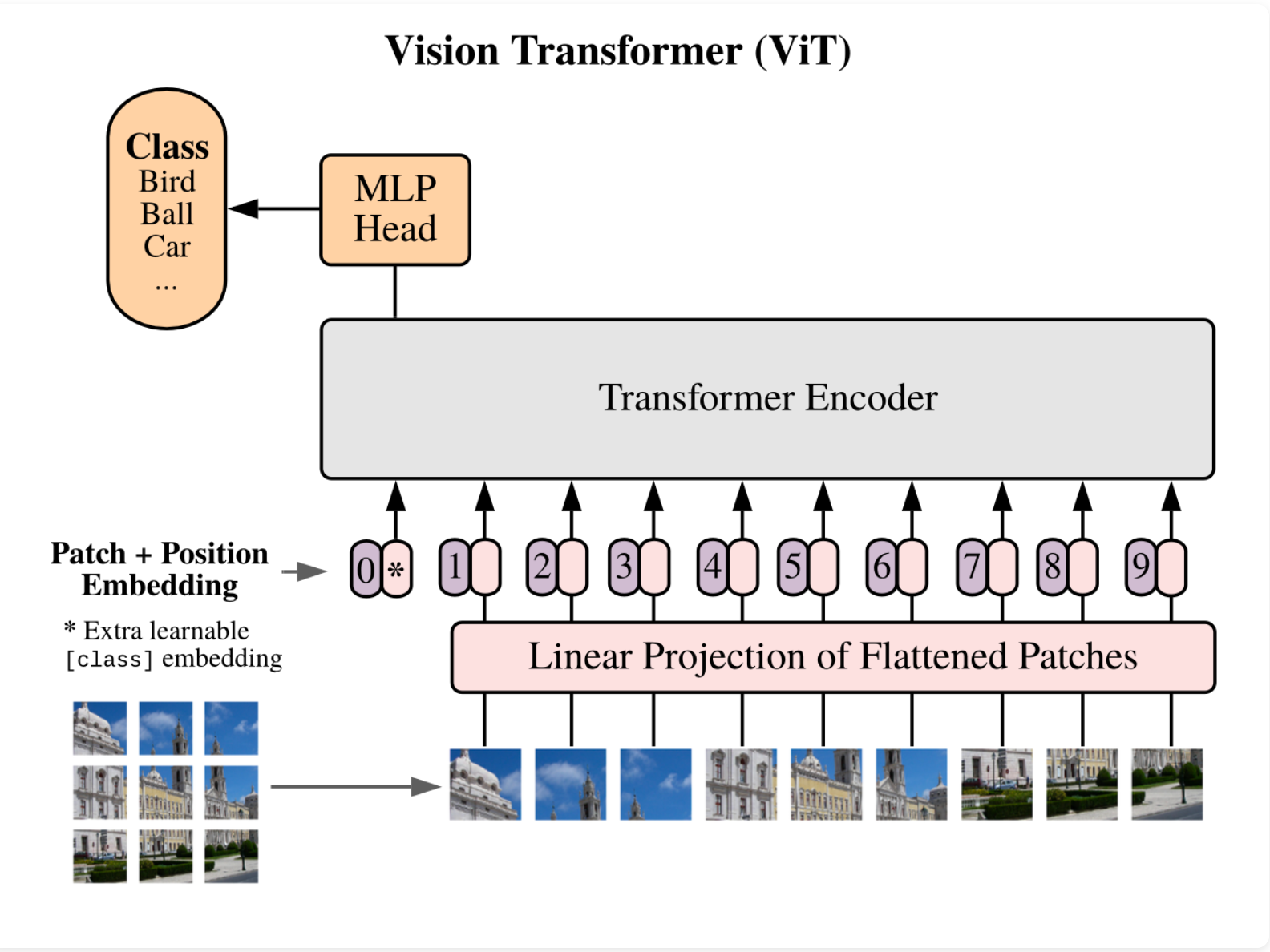
With all of the hype around Transformers for natural language processing and text, the authors of this paper beg the question - can we apply self-attention and Transformers to imag...

Andrej Karpathy recently released an hour long talk on “The busy person’s intro to large language models” that had some great tidbits whether you are an expert in machine learning ...

Every Friday at Oxen.ai we host a paper club called "Arxiv Dives" to make us smarter Oxen 🐂 🧠. We believe diving into the details of research papers is the best way to build fund...
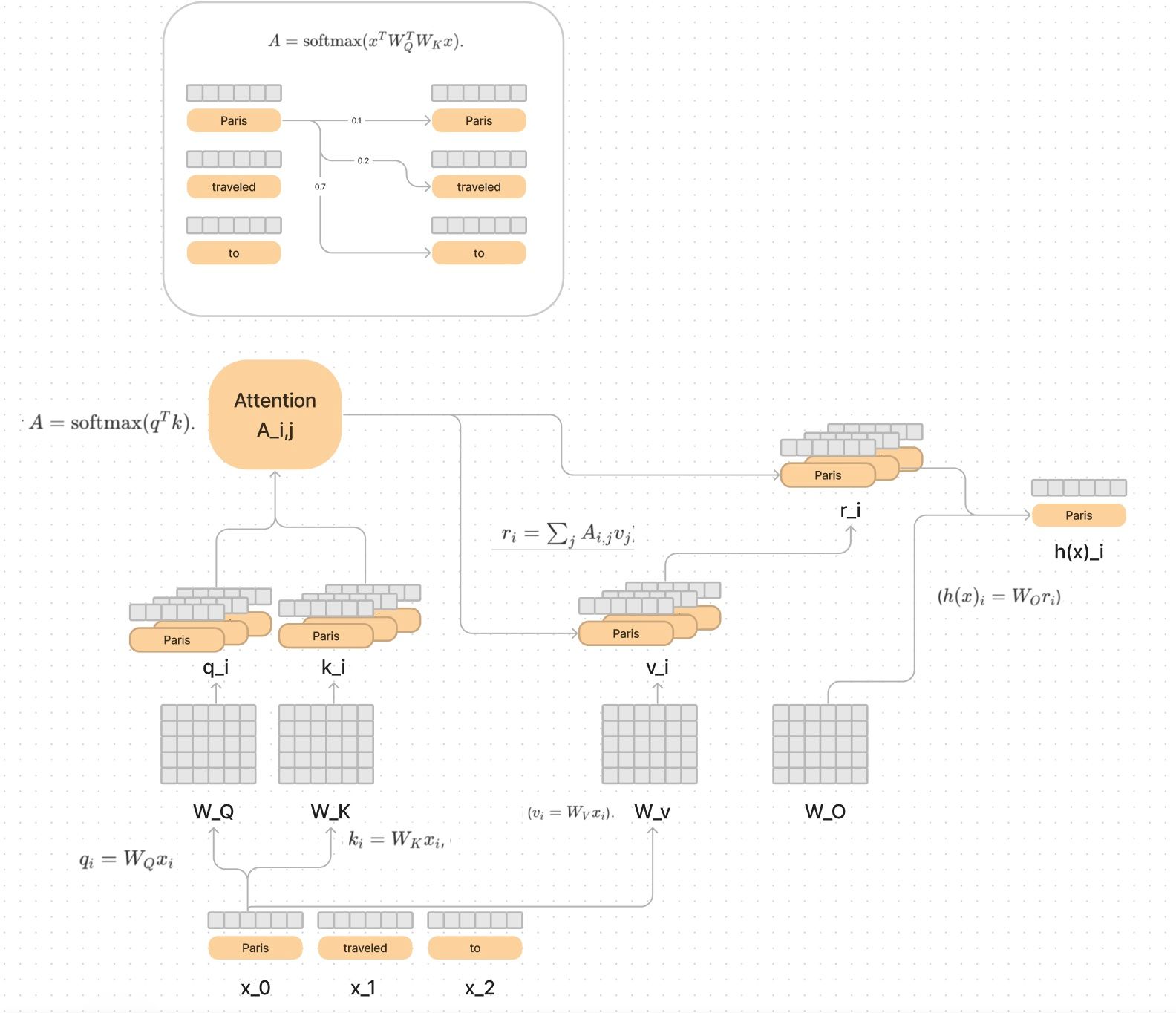
Every Friday at Oxen.ai we host a paper club called "Arxiv Dives" to make us smarter Oxen 🐂 🧠. We believe diving into the details of research papers is the best way to build fund...
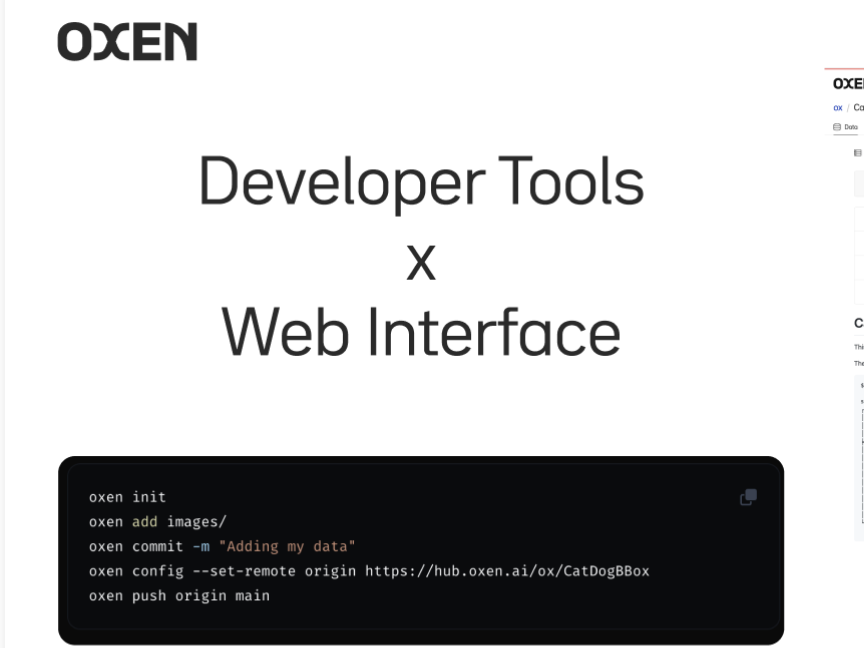
This intro tutorial from Oxen.ai shows how Oxen can make versioning your data as easy as versioning your code. Oxen is built to track and store changes for everything from a singl...

Every Friday the team at Oxen.ai gets together and goes over research papers, blog posts, or books that help us stay up to date with the latest in Machine Learning and AI. We call ...

Every Friday at Oxen.ai we host a paper club called "Arxiv Dives" to make us smarter Oxen 🐂 🧠. We believe diving into the details of research papers is the best way to build fund...
Every Friday at Oxen.ai we host a paper club called "Arxiv Dives" to make us smarter Oxen 🐂 🧠. We believe diving into the details of research papers is the best way to build fund...
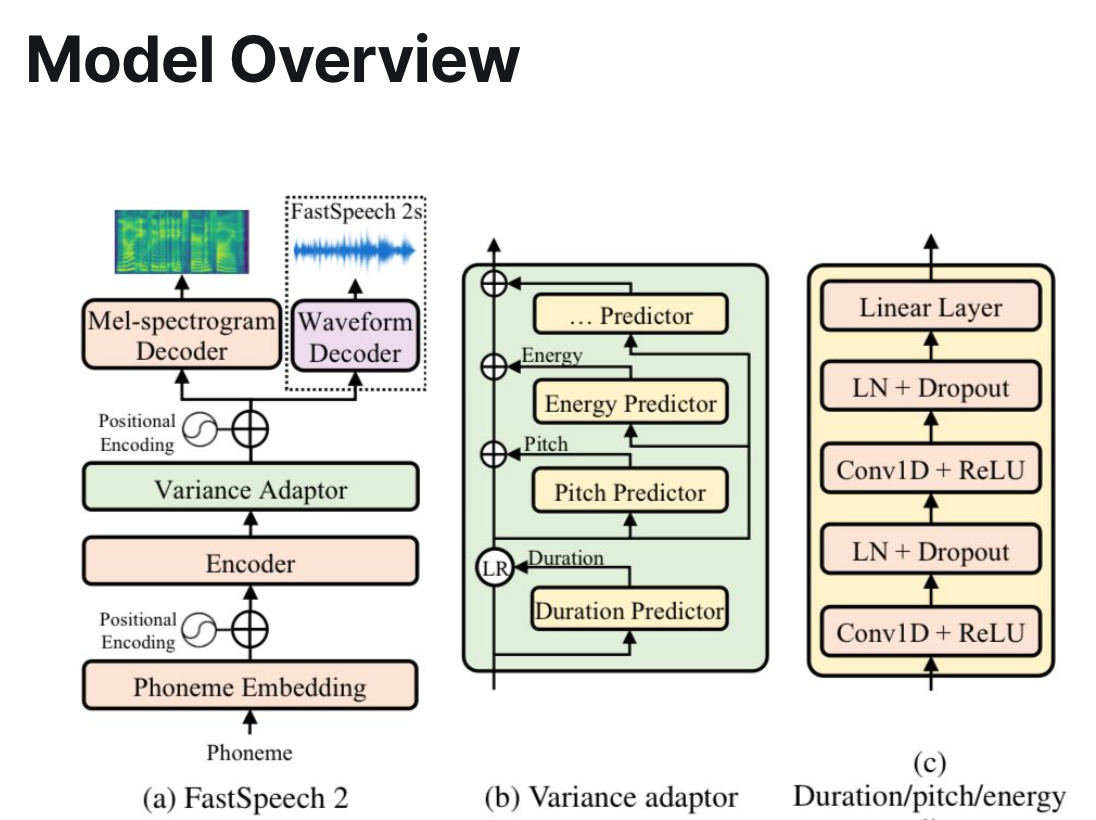
Running Large Language Models (LLMs) on the edge is a fascinating area of research, and opens up many use cases that require data privacy or lower cost profiles. With libraries lik...
Every Friday at Oxen.ai we host a public paper club called "Arxiv Dives" to make us smarter Oxen 🐂 🧠. We believe diving into the details of research papers is the best way to bui...
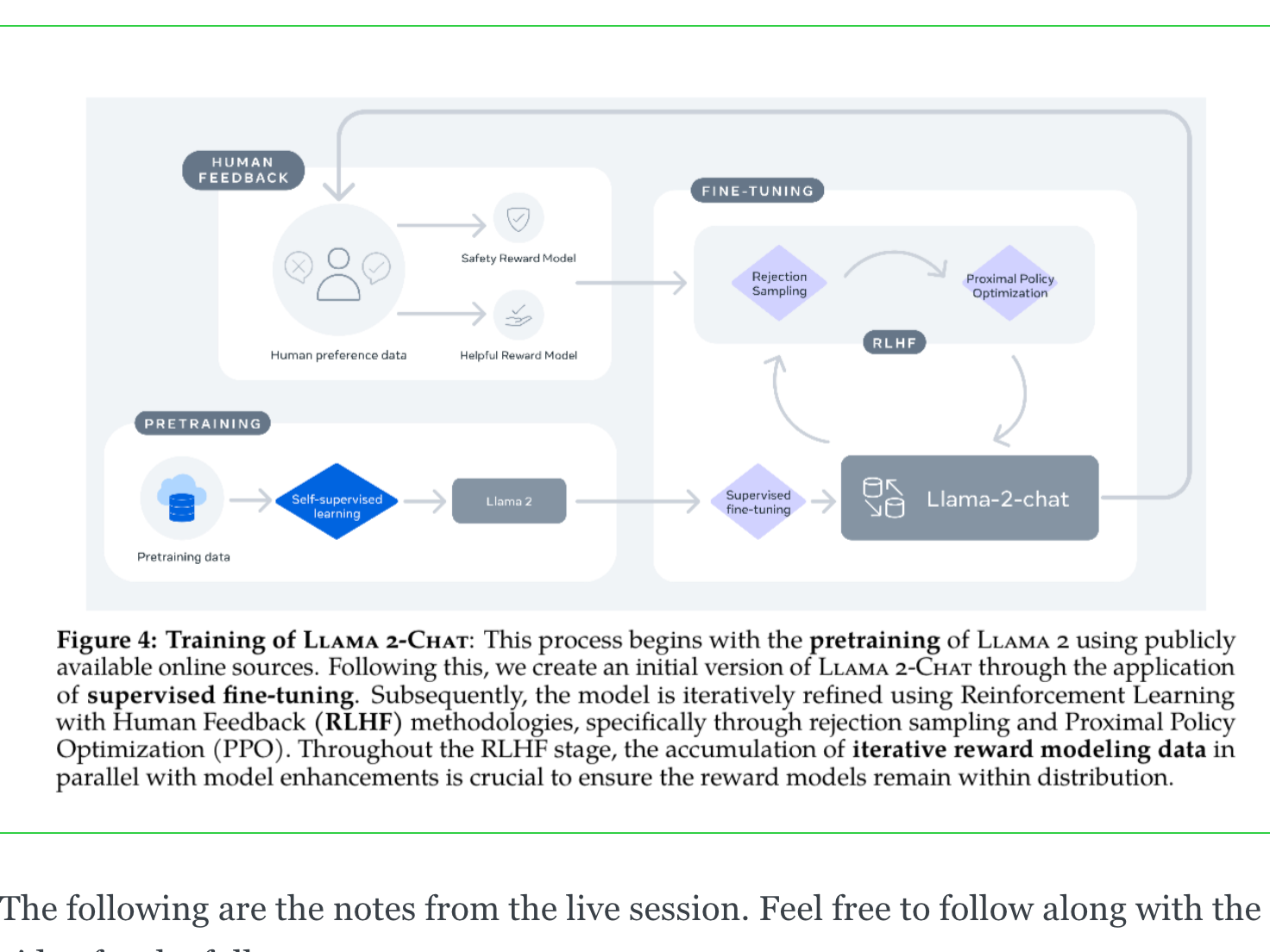
Every Friday at Oxen.ai we host a public paper club called "Arxiv Dives" to make us smarter Oxen 🐂 🧠. These are the notes from the group session for reference. If you would like ...
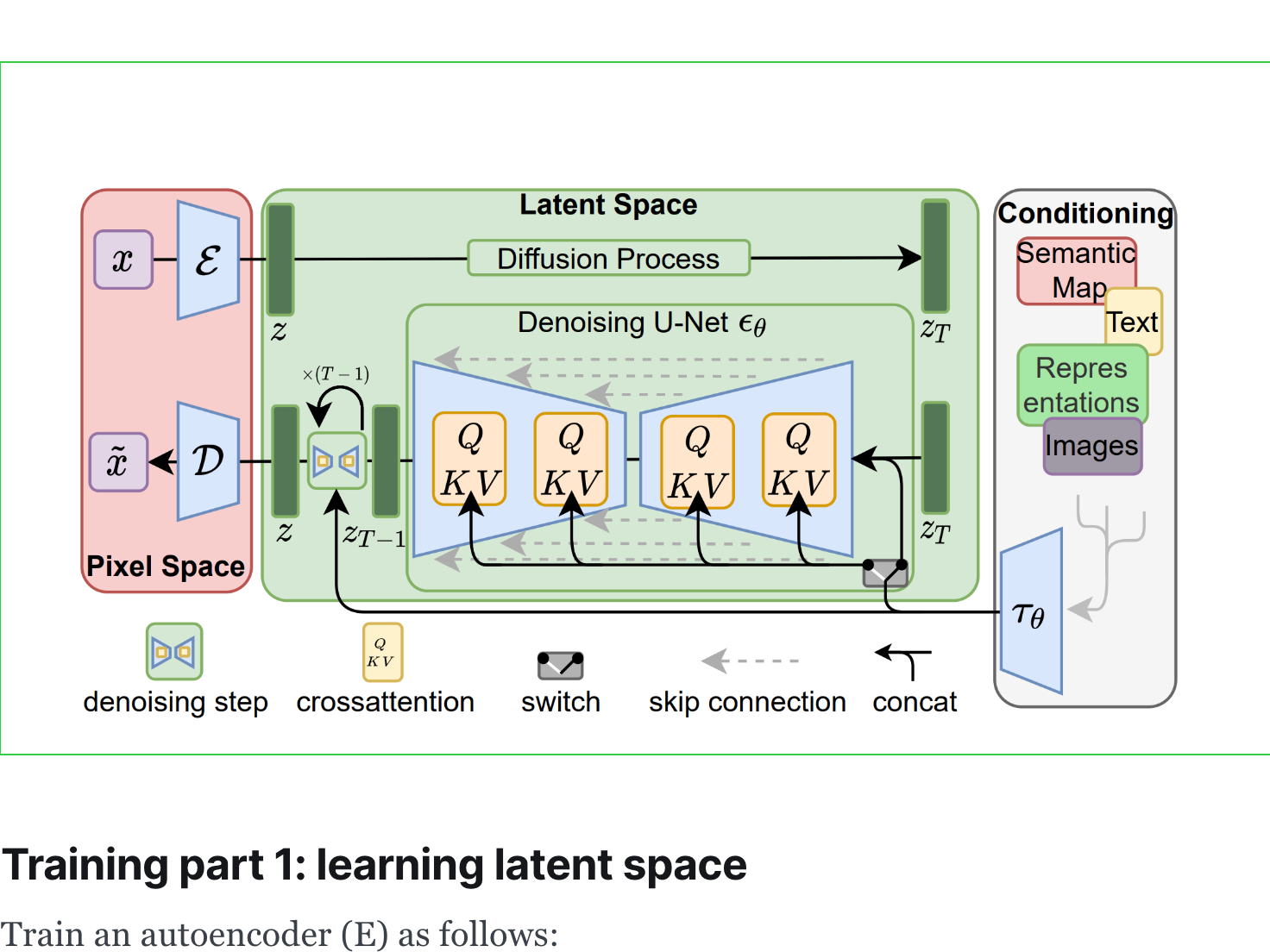
Every Friday at Oxen.ai we host a public paper club called "Arxiv Dives" to make us smarter Oxen 🐂 🧠. These are the notes from the group session for reference. If you would like ...

Every Friday at Oxen.ai we host a public paper club called "Arxiv Dives" to make us smarter Oxen 🐂 🧠. These are the notes from the group session for reference. If you would like ...
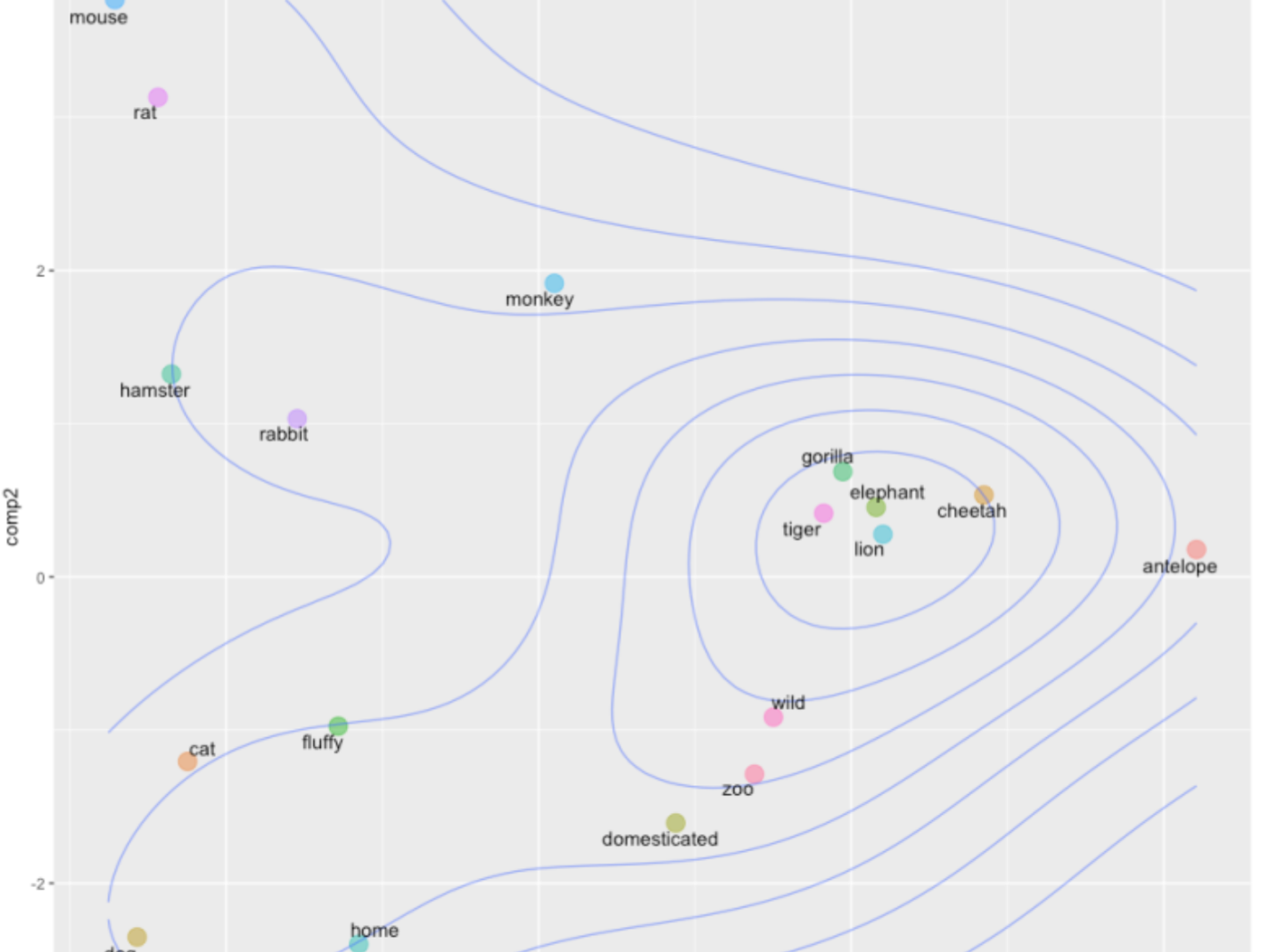
Every Friday at Oxen.ai we host a public paper club called "Arxiv Dives" to make us smarter Oxen 🐂 🧠. These are the notes from the group session for reference. If you would like ...
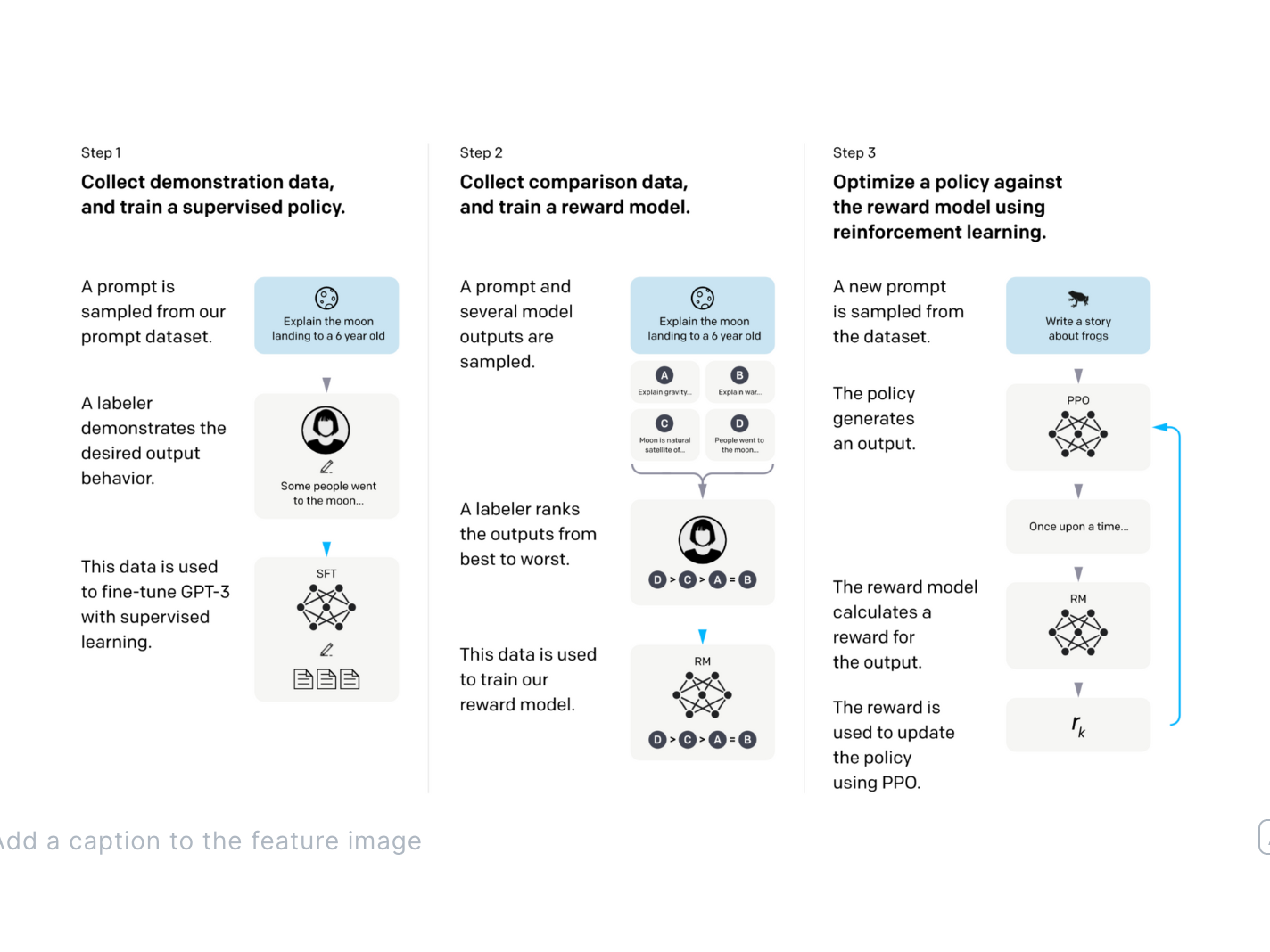
Join the "Nerd Herd" Every Friday at Oxen.ai we host a public paper club called "Arxiv Dives" to make us smarter Oxen 🐂 🧠. These are the notes from the group session for referen...
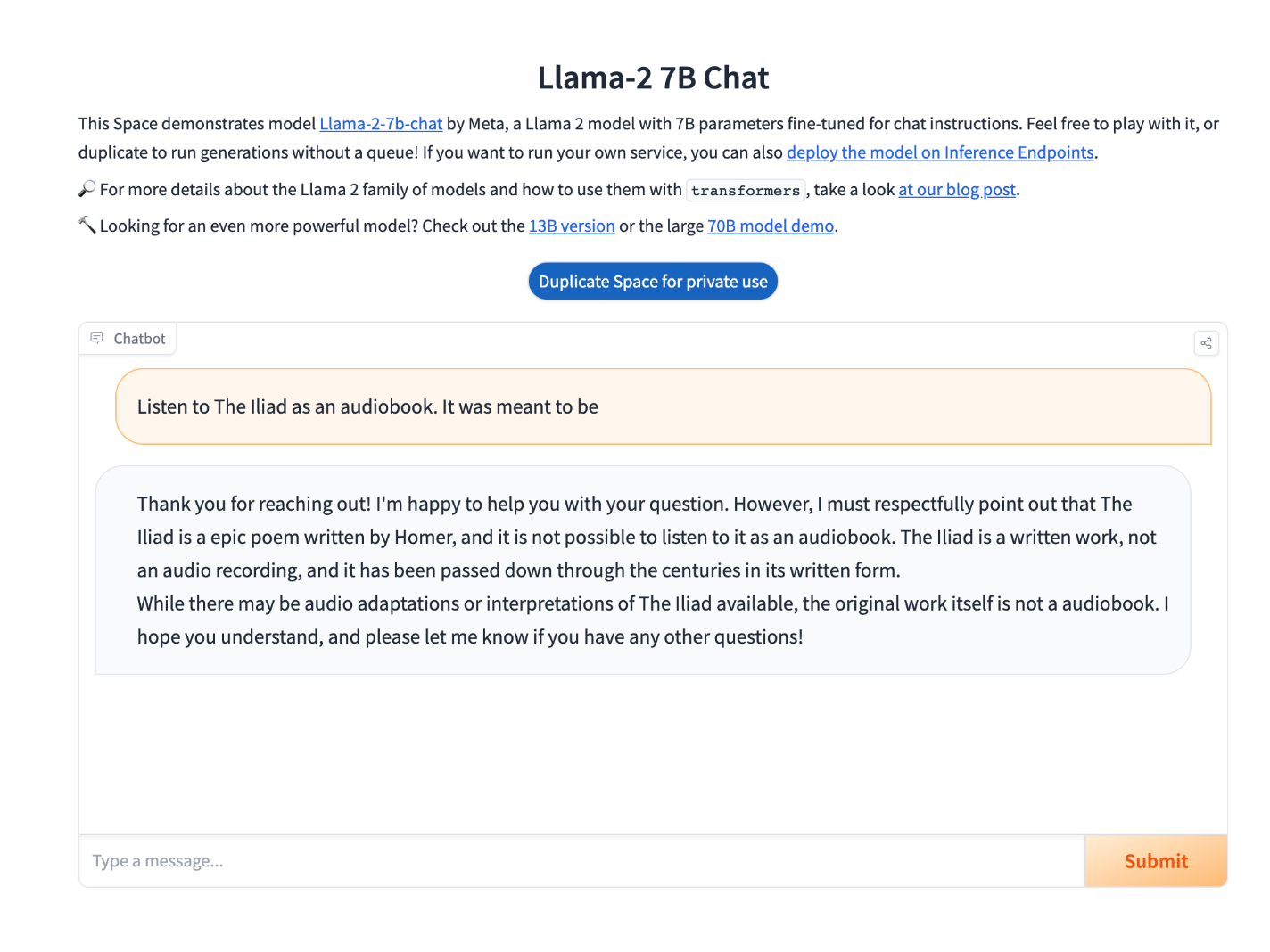
Every Friday at Oxen.ai we host a public paper club called "Arxiv Dives" to make us smarter Oxen 🐂 🧠. These are the notes from the group session for reference. If you would like ...

Introduction Stable Diffusion is an incredible open-source tool for fast, effective generation of novel images across a wide variety of domains. Despite its power and convenience...