Oxen.ai Blog
Welcome to the Oxen.ai blog 🐂
The team at Oxen.ai is dedicated to helping AI practictioners go from research to production. To help enable this, we host a research paper club on Fridays called ArXiv Dives, where we go over state of the art research and how you can apply it to your own work.
Take a look at our Arxiv Dives, Practical ML Dives as well as a treasure trove of content on how to go from raw datasets to production ready AI/ML systems. We cover everything from prompt engineering, fine-tuning, computer vision, natural language understanding, generative ai, data engineering, to best practices when versioning your data. So, dive in and explore – we're excited to share our journey and learnings with you 🚀
Fine-tuning Diffusion Models such as Stable Diffusion, FLUX.1-dev, or Qwen-Image can give you a lot of bang for your buck. Base models may not be trained on a certain concept or st...


Group Relative Policy Optimization (GRPO) has proven to be a useful algorithm for training LLMs to reason and improve on benchmarks. DeepSeek-R1 showed that you can bootstrap a mod...

Since the release of DeepSeek-R1, Group Relative Policy Optimization (GRPO) has become the talk of the town for Reinforcement Learning in Large Language Models due to its effective...
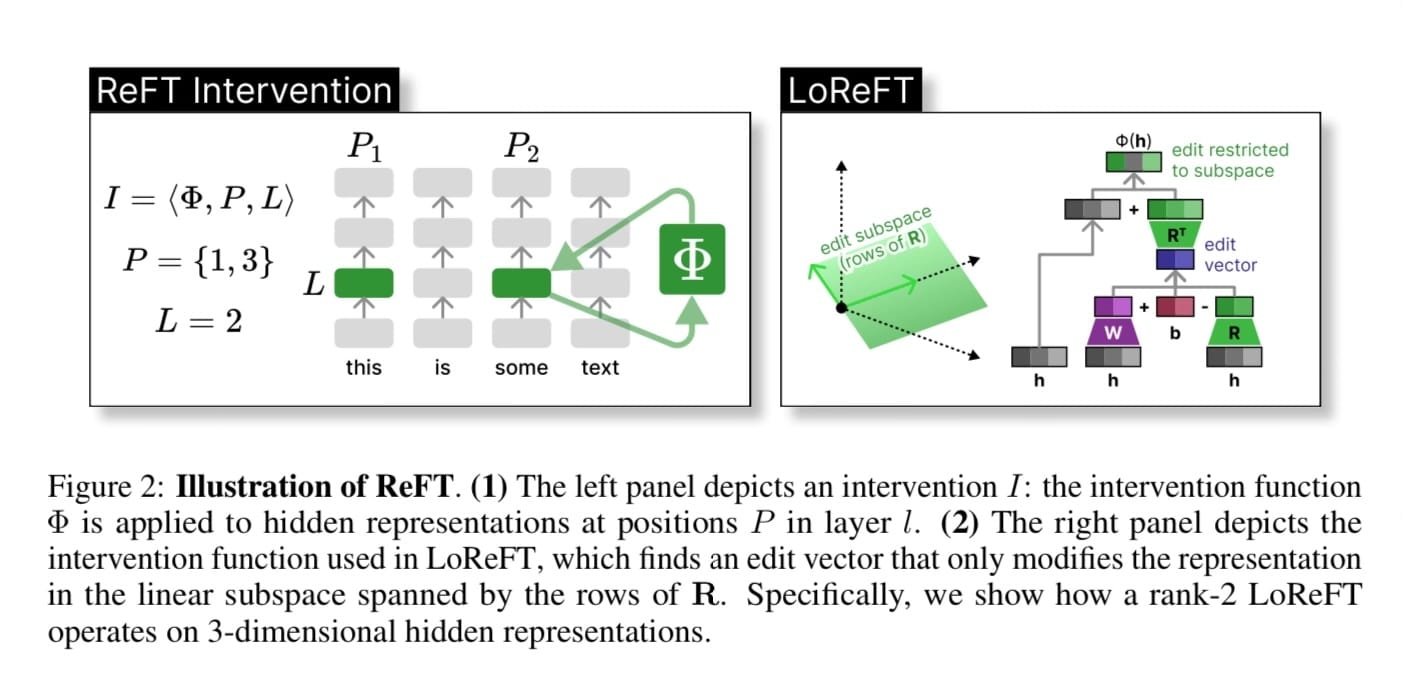
ArXiv Dives is a series of live meetups that take place on Fridays with the Oxen.ai community. We believe that it is not only important to read the papers, but dive into the code t...
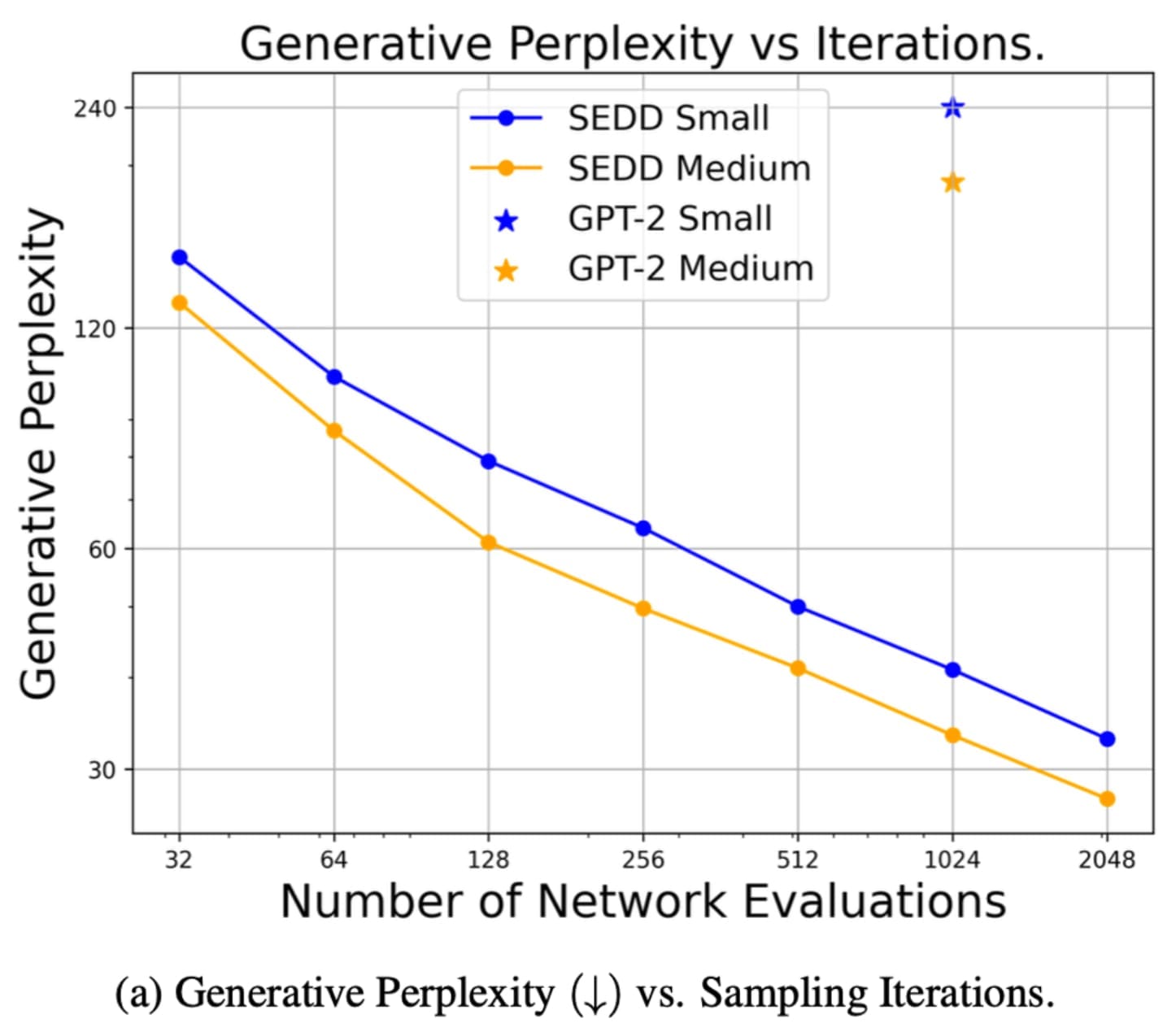
This is part two of a series on Diffusion for Text with Score Entropy Discrete Diffusion (SEDD) models. Today we will be diving into the code for diffusion models for text, and see...

Diffusion models have been popular for computer vision tasks. Recently models such as Sora show how you can apply Diffusion + Transformers to generate state of the art videos with ...
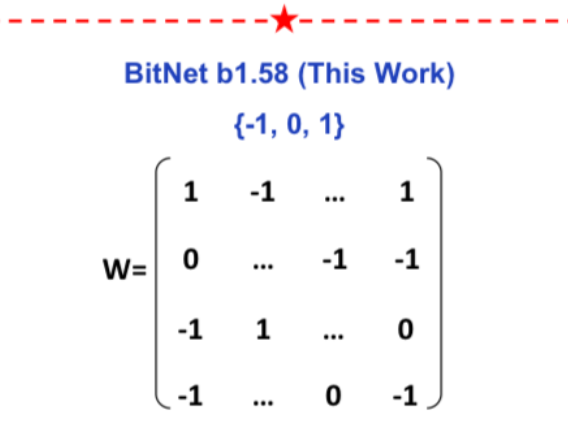
This paper presents BitNet b1.58 where every weight in a Transformer can be represented as a {-1, 0, 1} instead of a floating point number. The model matches full precision transfo...
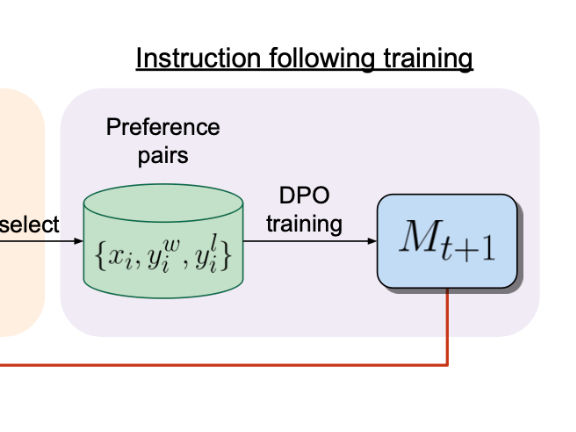
About a month ago we went over the "Self-Rewarding Language Models" paper by the team at Meta AI with the Oxen.ai Community. The paper felt very approachable and reproducible, so w...
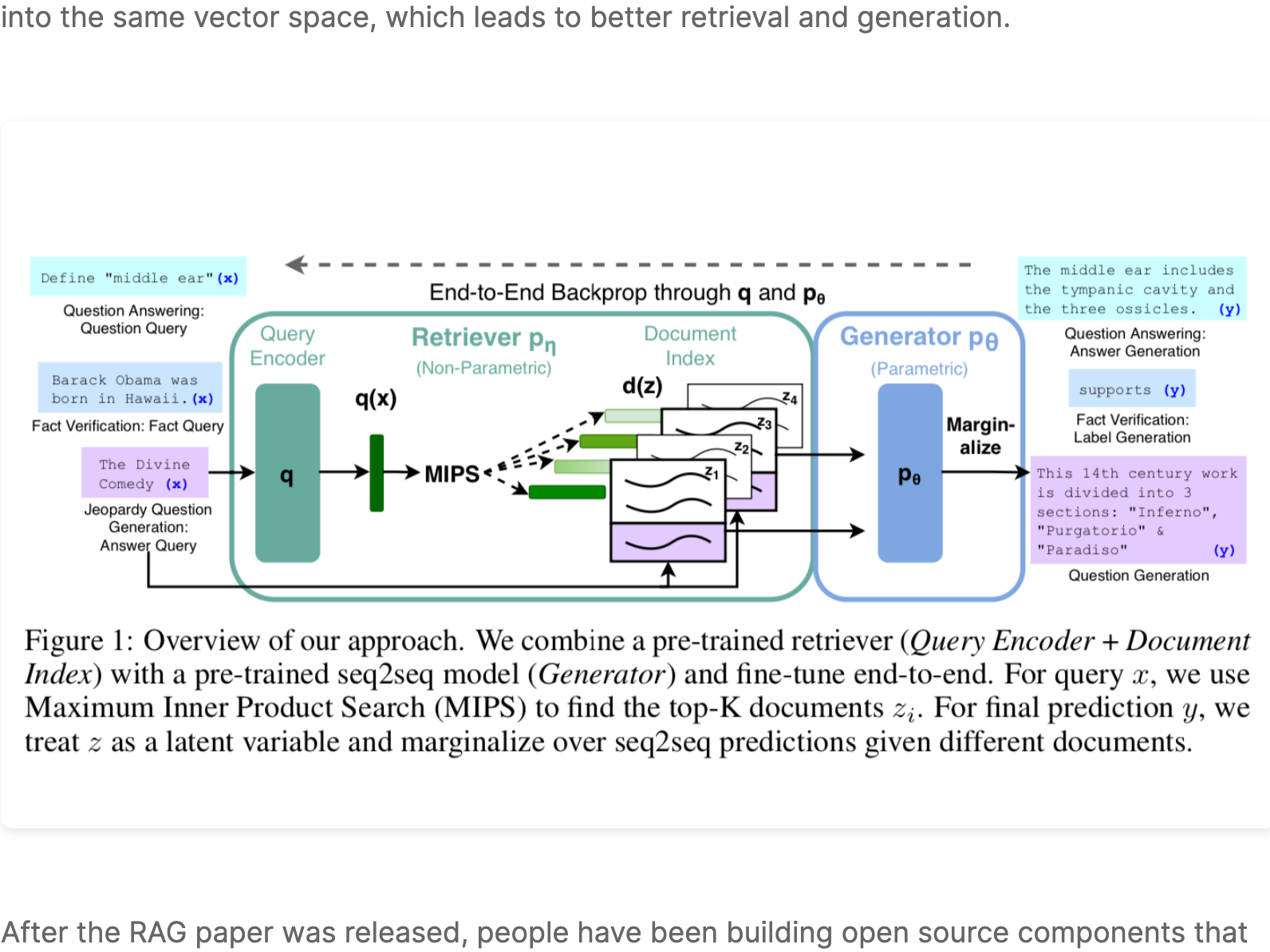
RAG was introduced by the Facebook AI Research (FAIR) team in May of 2020 as an end-to-end way to include document search into a sequence-to-sequence neural network architecture. ...

What is Mamba 🐍? There is a lot of hype about Mamba being a fast alternative to the Transformer architecture. The paper released in December of 2023 claims 5x faster throughput w...