Oxen.ai Blog
Welcome to the Oxen.ai blog 🐂
The team at Oxen.ai is dedicated to helping AI practictioners go from research to production. To help enable this, we host a research paper club on Fridays called ArXiv Dives, where we go over state of the art research and how you can apply it to your own work.
Take a look at our Arxiv Dives, Practical ML Dives as well as a treasure trove of content on how to go from raw datasets to production ready AI/ML systems. We cover everything from prompt engineering, fine-tuning, computer vision, natural language understanding, generative ai, data engineering, to best practices when versioning your data. So, dive in and explore – we're excited to share our journey and learnings with you 🚀

Can we fine-tune a small diffusion transformer (DiT) to generate OpenAI-level images by distilling off of OpenAI images? The end goal is to have a small, fast, cheap model that we ...


Welcome to a new series from the Oxen.ai Herd called Fine-Tuning Fridays! Each week we will take an open source model and put it head to head against a closed source foundation mod...

Fine-tuning Fridays is a series from the Oxen.ai Herd where each week we do a deep dive into a model and put it head to head against the competition. We will be giving you practica...
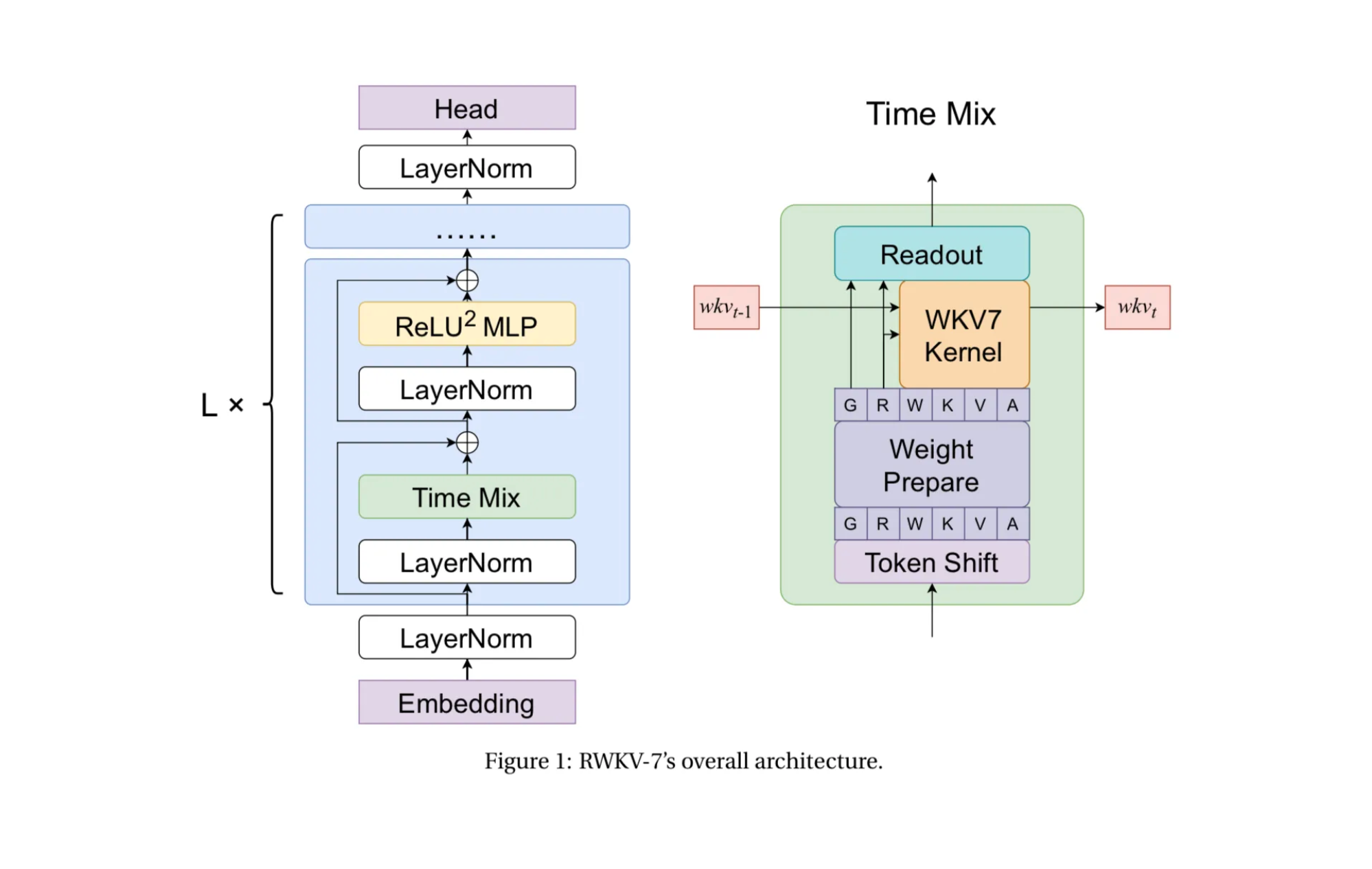
In this special Arxiv Dive, we're joined by Eugene Cheah - author, lead in RWKV org, CEO of Featherless AI, to discuss the development process and key decisions behind these models...
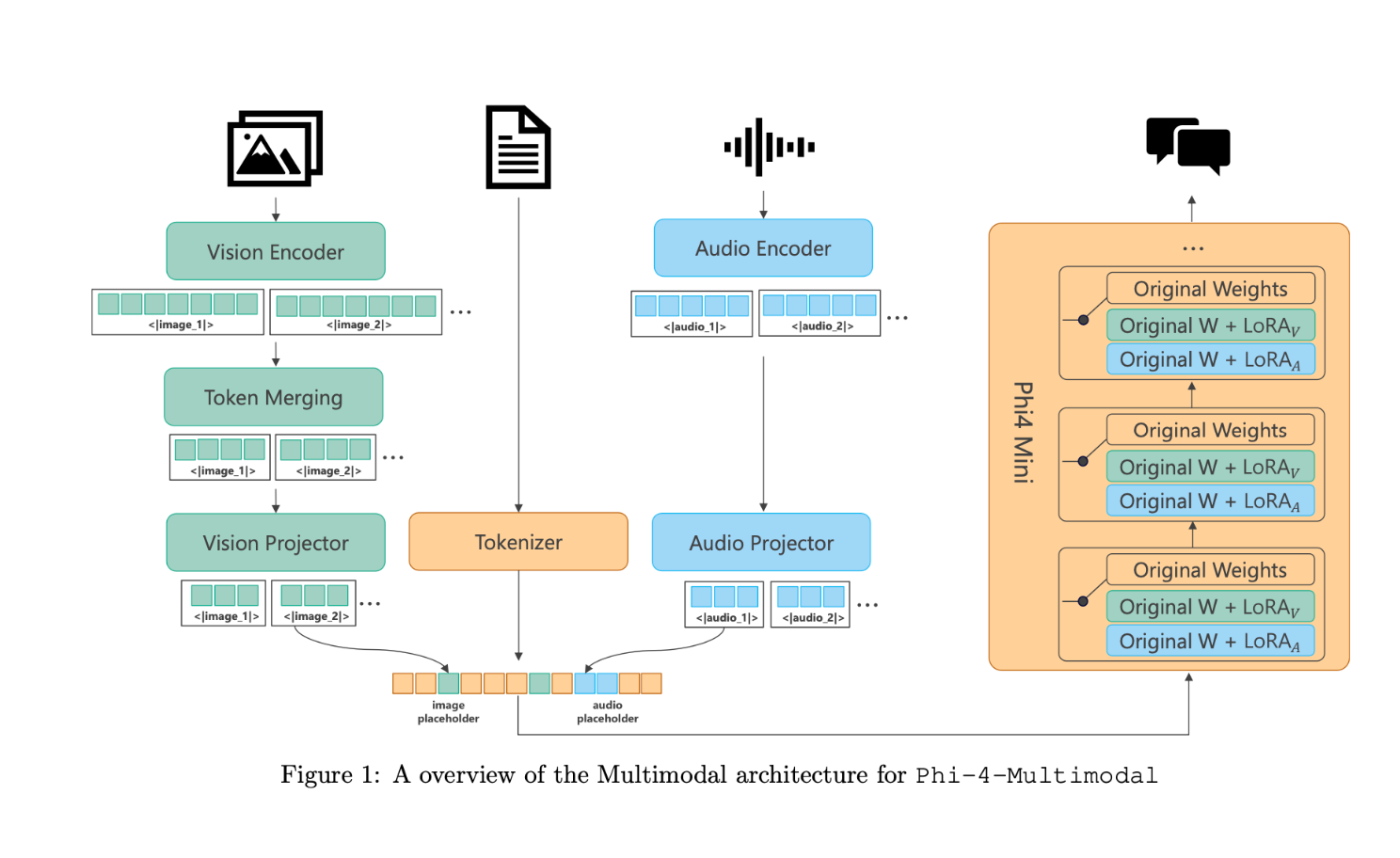
Phi-4 extends the existing Phi model’s capabilities by adding vision and audio all in the same model. This means you can do everything from understand images, generate code, recogn...

Group Relative Policy Optimization (GRPO) has proven to be a useful algorithm for training LLMs to reason and improve on benchmarks. DeepSeek-R1 showed that you can bootstrap a mod...
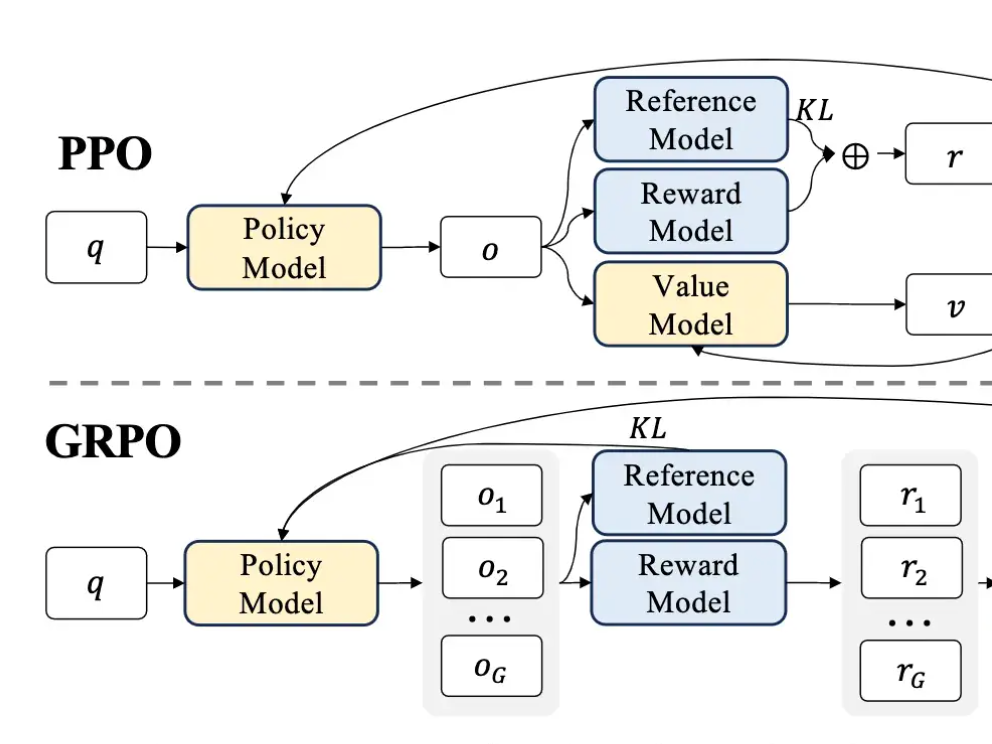
Last week on Arxiv Dives we dug into research behind DeepSeek-R1, and uncovered that one of the techniques they use in the their training pipeline is called Group Relative Policy O...

Since the release of DeepSeek-R1, Group Relative Policy Optimization (GRPO) has become the talk of the town for Reinforcement Learning in Large Language Models due to its effective...
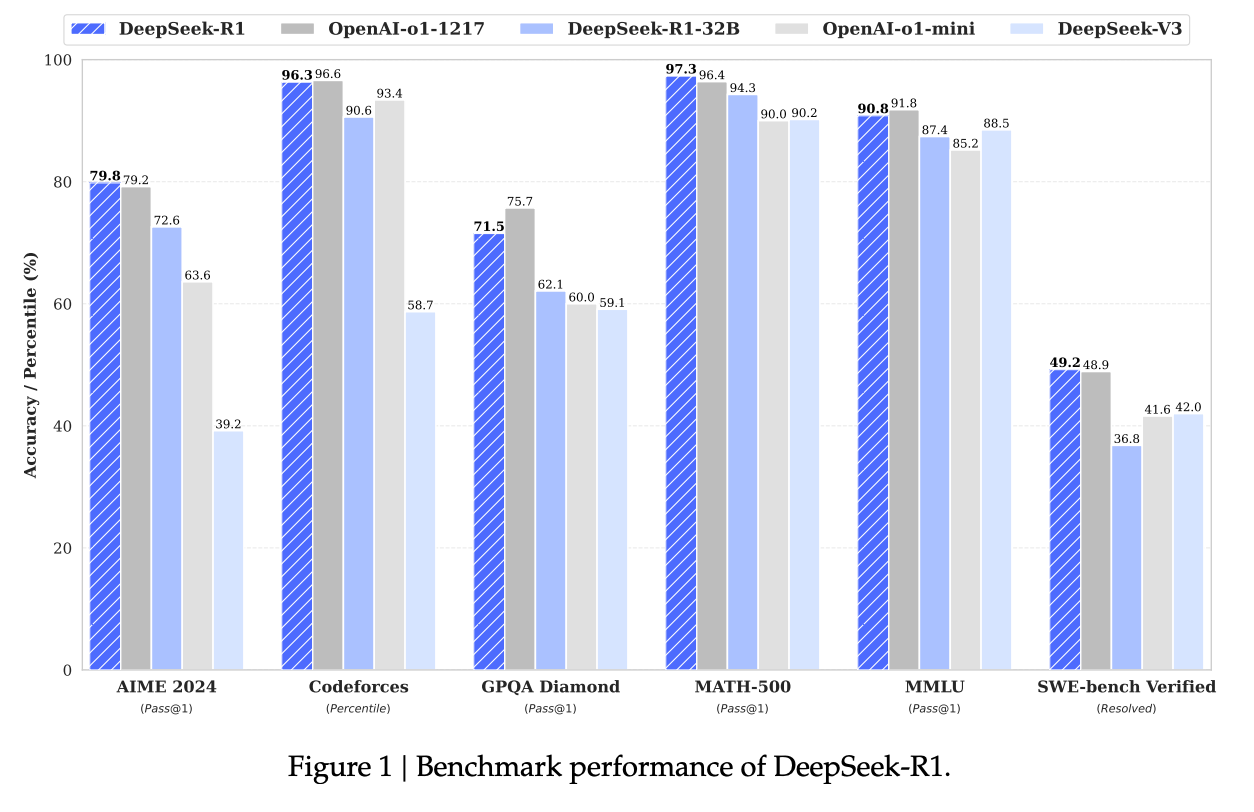
In January 2025, DeepSeek took a shot directly at OpenAI by releasing a suite of models that “Rival OpenAI’s o1.” From their website: In the spirit of Arxiv Dives we are going to...

DeepSeek-R1 is a big step forward in the open model ecosystem for AI with their latest model competing with OpenAI's o1 on a variety of metrics. There is a lot of hype, and a lot o...